联邦学习:按混合分布划分Non-IID样本
我们在博文《联邦学习:按病态独立同分布划分Non-IID样本》中学习了联邦学习开山论文[1]中按照病态独立同分布(Pathological Non-IID)划分样本。 在上一篇博文《联邦学习:按Dirichlet分布划分Non-IID样本》中我们也已经提到了按照Dirichlet分布划分联邦学习Non-IID数据集的一种算法。下面让我们来看按Dirichlet分布划分数据集的另外一种变种,即按混合分布划分Non-IID样本,该方法为论文[2]中首次提出。
该论文提出了一个重要的假设,那就是虽然联邦学习每个client的数据是Non-IID,但我们假设它们都来自一个混合分布(混合成分个数为超参数可调):
\]
形象化的展示图片如下:

有了这个假设,那我们相当于假定了每个client数据间的一种相似性,这种相似性类似于从Non-IID中找出潜藏的IID成分。
接下来我们来看这个划分算法的函数如何设计。除了常规Dirichlet划分算法所要求的n_clients、n_classes、\(\alpha\)等, 它还有一个专门的n_clusters参数,表示混合成分个数。我们来看函数原型:
def split_dataset_by_labels(dataset, n_classes, n_clients, n_clusters, alpha, frac, seed=1234):
我们解释一下函数的参数,这里dataset是torch.utils.Dataset类型的数据集,n_classes表示数据集里样本分类数,n_clusters是簇的个数(后面会解释其含义,如果设置为-1,则就默认n_clusters=n_classes,相当于每个client各为一个簇,即放弃了混合分布假设),alpha 用于控制clients之间的数据diversity(多样性),frac是使用数据集的比例(默认是1,即使用全部数据),seed是传入的随机数种子。该函数返回一个由n_client个client所需的样本索引组成的列表组成的列表client_idcs。
接下来我们看这个函数的内容。这个函数的内容可以概括为:先将所有类别分组为n_clusters个簇;再对每个簇c,将样本划分给不同的clients(每个client的样本数量按照dirichlet分布来确定)。
首先,我们判断n_clusters的数量,如果为-1,则默认每一个cluster对应一个数据class:
if n_clusters == -1:
n_clusters = n_classes
然后将打乱后的标签集合\(\{0,1,...,n\_classes-1\}\)分为n_clusters个独立同分布的簇。
all_labels = list(range(n_classes))
np.random.shuffle(all_labels)
def iid_divide(l, g):
"""
将列表`l`分为`g`个独立同分布的group(其实就是直接划分)
每个group都有 `int(len(l)/g)` 或者 `int(len(l)/g)+1` 个元素
返回由不同的groups组成的列表
"""
num_elems = len(l)
group_size = int(len(l) / g)
num_big_groups = num_elems - g * group_size
num_small_groups = g - num_big_groups
glist = []
for i in range(num_small_groups):
glist.append(l[group_size * i: group_size * (i + 1)])
bi = group_size * num_small_groups
group_size += 1
for i in range(num_big_groups):
glist.append(l[bi + group_size * i:bi + group_size * (i + 1)])
return glist
clusters_labels = iid_divide(all_labels, n_clusters)
然后再建立根据上面划分为簇的标签(clusters_labels)建立key为label, value为簇id(group_idx)的字典,
label2cluster = dict() # maps label to its cluster
for group_idx, labels in enumerate(clusters_labels):
for label in labels:
label2cluster[label] = group_idx
接着获取数据集的索引
data_idcs = list(range(len(dataset)))
之后,我们
# 记录每个cluster大小的向量
clusters_sizes = np.zeros(n_clusters, dtype=int)
# 存储每个cluster对应的数据索引
clusters = {k: [] for k in range(n_clusters)}
for idx in data_idcs:
_, label = dataset[idx]
# 由样本数据的label先找到其cluster的id
group_id = label2cluster[label]
# 再将对应cluster的大小+1
clusters_sizes[group_id] += 1
# 将样本索引加入其cluster对应的列表中
clusters[group_id].append(idx)
# 将每个cluster对应的样本索引列表打乱
for _, cluster in clusters.items():
rng.shuffle(cluster)
接着,我们按照Dirichlet分布设置每一个cluster的样本个数。
# 记录来自每个cluster的client的样本数量
clients_counts = np.zeros((n_clusters, n_clients), dtype=np.int64)
# 遍历每一个cluster
for cluster_id in range(n_clusters):
# 对每个cluster中的每个client赋予一个满足dirichlet分布的权重
weights = np.random.dirichlet(alpha=alpha * np.ones(n_clients))
# np.random.multinomial 表示投掷骰子clusters_sizes[cluster_id]次,落在各client上的权重依次是weights
# 该函数返回落在各client上各多少次,也就对应着各client应该分得的样本数
clients_counts[cluster_id] = np.random.multinomial(clusters_sizes[cluster_id], weights)
# 对每一个cluster上的每一个client的计数次数进行前缀(累加)求和,
# 相当于最终返回的是每一个cluster中按照client进行划分的样本分界点下标
clients_counts = np.cumsum(clients_counts, axis=1)
然后,我们根据每一个cluster中的每一个client分得的样本情况(我们已经得到了每一个cluster中按照client进行划分的样本分界点下标),合并归纳得到每一个client中分得的样本情况。
def split_list_by_idcs(l, idcs):
"""
将列表`l` 划分为长度为 `len(idcs)` 的子列表
第`i`个子列表从下标 `idcs[i]` 到下标`idcs[i+1]`
(从下标0到下标`idcs[0]`的子列表另算)
返回一个由多个子列表组成的列表
"""
res = []
current_index = 0
for index in idcs:
res.append(l[current_index: index])
current_index = index
return res
clients_idcs = [[] for _ in range(n_clients)]
for cluster_id in range(n_clusters):
# cluster_split为一个cluster中按照client划分好的样本
cluster_split = split_list_by_idcs(clusters[cluster_id], clients_counts[cluster_id])
# 将每一个client的样本累加上去
for client_id, idcs in enumerate(cluster_split):
clients_idcs[client_id] += idcs
最后,我们返回每个client对应的样本索引:
return clients_idcs
接下来我们在EMNIST数据集上调用该函数进行测试,并进行可视化呈现。我们设client数量\(N=10\),Dirichlet概率分布的参数向量\(\bm{\alpha}\)满足\(\alpha_i=0.4,\space i=1,2,...N\), 混合成分个数为3:
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
if __name__ == "__main__":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1
N_COMPONENTS = 3
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# 注意每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = split_dataset_by_labels(train_data, num_cls, N_CLIENTS, N_COMPONENTS, DIRICHLET_ALPHA)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
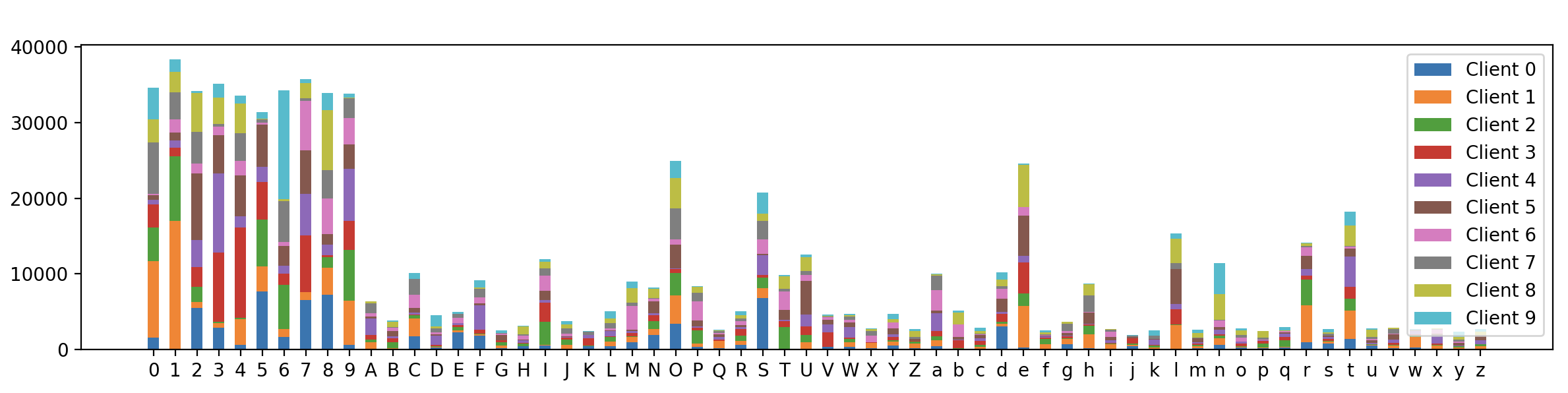
最终的可视化结果如下:

可以看到,62个类别标签在不同client上的分布虽然不同,但相对下面的完全基于Dirichlet的样本划分算法,每个client之间的数据分布显得更加相似,这证明我们的混合分布样本划分算法是有效的。
参考
[1] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
[2] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
联邦学习:按混合分布划分Non-IID样本的更多相关文章
- 联邦学习:按Dirichlet分布划分Non-IID样本
我们在<Python中的随机采样和概率分布(二)>介绍了如何用Python现有的库对一个概率分布进行采样,其中的dirichlet分布大家一定不会感到陌生.该分布的概率密度函数为 \[P( ...
- 【一周聚焦】 联邦学习 arxiv 2.16-3.10
这是一个新开的每周六定期更新栏目,将本周arxiv上新出的联邦学习等感兴趣方向的文章进行总结.与之前精读文章不同,本栏目只会简要总结其研究内容.解决方法与效果.这篇作为栏目首发,可能不止本周内容(毕竟 ...
- 联邦学习(Federated Learning)
联邦学习简介 联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是 ...
- Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践
腾讯 Angel PowerFL 联邦学习平台 联邦学习作为新一代人工智能基础技术,通过解决数据隐私与数据孤岛问题,重塑金融.医疗.城市安防等领域. 腾讯 Angel PowerFL 联邦学习平台构建 ...
- MindSpore联邦学习框架解决行业级难题
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<MindSpore联邦学习框架解决隐私合规下的数据孤岛问题>. 演讲嘉宾:华为MindSpore联邦学习工程 ...
- 【论文考古】联邦学习开山之作 Communication-Efficient Learning of Deep Networks from Decentralized Data
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, "Communication-Efficient Learni ...
- 联邦学习开源框架FATE助力腾讯神盾沙箱,携手打造数据安全合作生态
近日,微众银行联邦学习FATE开源社区迎来了两位新贡献者——来自腾讯的刘洋及秦姝琦,作为云计算安全领域的专家,两位为FATE构造了新的功能点,并在Github上提交修复了相关漏洞.(Github项目地 ...
- 联邦学习 Federated Learning 相关资料整理
本文链接:https://blog.csdn.net/Sinsa110/article/details/90697728代码微众银行+杨强教授团队的联邦学习FATE框架代码:https://githu ...
- 腾讯数据安全专家谈联邦学习开源项目FATE:通往隐私保护理想未来的桥梁
数据孤岛.数据隐私以及数据安全,是目前人工智能和云计算在大规模产业化应用过程中绕不开的“三座大山”. “联邦学习”作为新一代的人工智能算法,能在数据不出本地的情况下,实现共同建模,提升AI模型的效果, ...
随机推荐
- ApacheCN 人工智能知识树 v1.0
贡献者:飞龙 版本:v1.0 最近总是有人问我,把 ApacheCN 这些资料看完一遍要用多长时间,如果你一本书一本书看的话,的确要用很长时间.但我觉得这是非常麻烦的,因为每本书的内容大部分是重复的, ...
- Net6 DI源码分析Part5 在Kestrel内Di Scope生命周期是如何根据请求走的?
Net6 DI源码分析Part5 在Kestrel内Di Scope生命周期是如何根据请求走的? 在asp.net core中的DI生命周期有一个Scoped是根据请求走的,也就是说在处理一次请求时, ...
- Nacos极简教程
简介 Nacos是服务发现与注册,服务配置中心. Nacos 具有如下特性: 服务发现和服务健康监测:支持基于DNS和基于RPC的服务发现,支持对服务的实时的健康检查,阻止向不健康的主机或服务实例发送 ...
- bom-location
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- linux修改root用户登陆密码
如果不是以root用户登录的,请先切换到root用户下, 执行命令:su root 然后按提示输入root用户的密码. 英文系统: [root@localhost ~]# passwd Changin ...
- webfunny前端系统:如何解决警报设置触发常见问题
大家好,经常会有小伙伴在使用webfunny监控系统中,遇到无法触发警报的问题,其实都是一些配置上的疏漏,在这里给大家总结一下: PS:只要消息中心里有警报,则说明触发机制没有问题.其他方式没有触发, ...
- 私有化轻量级持续集成部署方案--02-Nginx网关服务
提示:本系列笔记全部存在于 Github, 可以直接在 Github 查看全部笔记 这一篇中使用 Nginx 部署网关中心,用来代理服务器中服务.网关中心有优点也有缺点,也可以不采用网关系统. 部署 ...
- C# 实例解释面向对象编程中的开闭原则
在面向对象编程中,SOLID 是五个设计原则的首字母缩写,旨在使软件设计更易于理解.灵活和可维护.这些原则是由美国软件工程师和讲师罗伯特·C·马丁(Robert Cecil Martin)提出的许多原 ...
- Solution -「国家集训队」「洛谷 P4451」整数的 lqp 拆分
\(\mathcal{Description}\) Link. 求 \[\sum_{m>0\\a_{1..m}>0\\a_1+\cdots+a_m=n}\prod_{i=1}^mf ...
- .NET 7 预览版 1 发布
宣布 .NET 7 预览版 1 Jeremy 2022 年 2 月 17 日 今天,我们很高兴地宣布 .NET 历史上的下一个里程碑.在庆祝社区和 20 年创新的同时,.NET 7 Preview 1 ...