GPT-3介绍
参考:https://en.wikipedia.org/wiki/GPT-3
Generative Pre-trained Transformer 3(GPT-3)是一个自回归语言模型,于2020年发布,它使用深度学习生成类人文本。给定初始文本作为提示,它将生成继续提示的文本。
该架构是一个仅解码器的转换器网络,具有2048个token长度的上下文,然后具有1750亿个参数的空前大小,需要800GB的存储空间。模型使用生成性预训练进行训练;它被训练为基于先前的令牌来预测下一个令牌是什么。该模型在许多任务上展示了强大的零射击和少射击学习。[2] 作者描述了在GPT-n中如何通过“在未标记文本的不同语料库上生成语言模型的预训练,然后对每个特定任务进行区分性微调”的过程来提高自然语言处理(NLP)中的语言理解性能。这消除了对人的监督和时间密集型手动标记的需求。[2]
它是GPT系列中的第三代语言预测模型,是由位于旧金山的人工智能研究实验室OpenAI创建的GPT-2的继承者。[3] GPT-3于2020年5月推出,截至2020年7月处于测试阶段,[4]是预训练语言表示的自然语言处理(NLP)系统趋势的一部分。[1]
GPT-3生成的文本质量非常高,很难确定它是否由人类编写,这既有好处,也有风险。[5] 31位OpenAI研究人员和工程师于2020年5月28日发表了介绍GPT-3的原始论文。在他们的论文中,他们警告GPT-3的潜在危险,并呼吁进行研究以减轻风险。[1]: 34 澳大利亚哲学家大卫·查默斯(David Chalmers)将GPT-3描述为“有史以来最有趣、最重要的人工智能系统之一”。[6]《纽约时报》2022年4月的一篇评论称,GPT-3的能力是能够以相当于人类的流畅度写出原创散文。[7]
微软于2020年9月22日宣布,已授权“独家”使用GPT-3;其他人仍然可以使用公共API接收输出,但只有Microsoft可以访问GPT-3的基础模型。[8]
根据《经济学人》的说法,改进的算法、强大的计算机和数字化数据的增加推动了机器学习的革命,2010年代的新技术导致了“任务的快速改进”,包括操纵语言。[9] 软件模型是通过使用数千或数百万个“结构……松散地基于大脑的神经结构”中的示例来学习的。[9] 自然语言处理(NLP)中使用的一种架构是基于深度学习模型的神经网络,该模型于2017年首次引入Transformer。[10] GPT-n模型是基于Transformer的深度学习神经网络架构。有许多NLP系统能够处理、挖掘、组织、连接和对比文本输入,以及正确回答问题。[11]
2018年6月11日,OpenAI研究人员和工程师发布了他们关于生成模型的原始论文,语言模型人工智能系统可以通过数据集使用大量多样的文本语料库进行预训练,这一过程被称为生成预训练(GP)。[2] 作者描述了在GPT-n中如何通过“在未标记文本的不同语料库上生成语言模型的预训练,然后对每个特定任务进行区分性微调”的过程来提高自然语言处理(NLP)中的语言理解性能。这消除了对人的监督和时间密集型手动标记的需求。[2]
2020年2月,微软推出了图灵自然语言生成(T-NLG),该模型被称为“有史以来以170亿个参数发布的最大语言模型”。[12]在各种任务(包括总结文本和回答问题)中,它的表现优于任何其他语言模型。
2020年5月28日,OpenAI的31名工程师和研究人员在一份arXiv预印本中描述了GPT-3的开发,GPT-3是第三代“最先进的语言模型”。[1] [5]该团队将GPT-3的容量比其前身GPT-2增加了两个数量级,[14]使GPT-3成为迄今为止最大的非稀疏语言模型。(在稀疏模型中,它的许多参数都设置为一个常量,因此即使有更多的总参数,也没有多少有意义的信息。)[1]: 14 [3] 由于GPT-3在结构上与它的前辈相似,[1]其更高的精度归因于它的容量增加和参数数量增加。[15] GPT-3的容量是当时已知的第二大NLP模型微软的图灵NLG的十倍。[5]
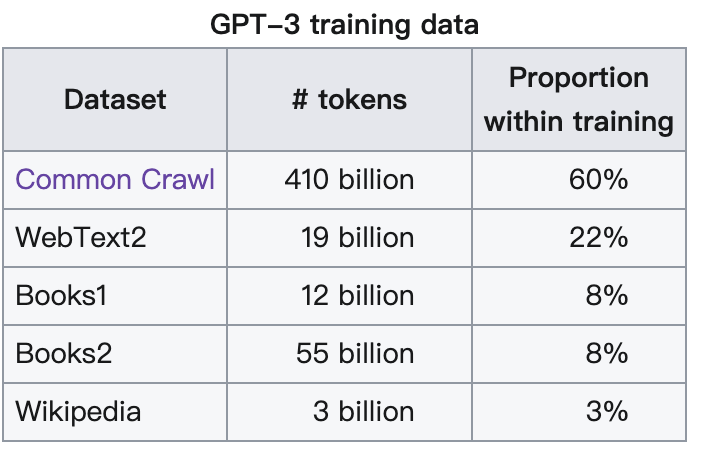
GPT-3的加权预训练数据集的60%来自由4100亿字节对编码令牌组成的过滤版Common Crawl。[1]: 9 其他来源包括WebText2的190亿代币,占加权总数的22%,Books1的120亿代币,8%,Books2的550亿代币,以及维基百科的30亿代币,3%。[1]: 9 GPT-3接受了数千亿单词的训练,还能够使用CSS、JSX和Python等进行编码。[4]
由于GPT-3的训练数据包罗万象,它不需要针对不同的语言任务进行进一步训练。[4] 训练数据偶尔包含有毒语言,GPT-3偶尔会因模仿其训练数据而生成有毒语言。华盛顿大学的一项研究发现,GPT-3产生的有毒语言的毒性水平与GPT-2和CTRL的类似自然语言处理模型相当。OpenAI已经实施了几种策略来限制GPT-3生成的有毒语言的数量。因此,GPT-3产生的有毒语言比其前身GPT-1少,尽管与完全基于维基百科数据训练的语言模型CTRL Wiki相比,GPT-1产生了更多的世代和更高的有毒语言毒性。[16]
2020年6月11日,OpenAI宣布,用户可以请求访问其用户友好的GPT-3API(“机器学习工具集”),以帮助OpenAI“探索这项新技术的优势和局限”。[17] [18]邀请函描述了该API如何具有通用的“文本输入、文本输出”接口,可以完成几乎“任何英语任务”,而不是通常的单一用例。[17] 根据一位用户的说法,GPT-3在编写“惊人连贯的文本”时“出奇地好”,只需几个简单的提示。[19] 在最初的实验中,80名美国受试者被要求判断200个单词的短文是由人类还是GPT-3撰写的。参与者在52%的时间里判断正确,只比随机猜测稍微好一点。[1]
2021 11月18日,OpenAI宣布实施了足够的保障措施,可以不受限制地访问其API。[20] OpenAI为开发者提供了一个内容调节工具,帮助他们遵守OpenAI的内容政策。[21]2022年1月27日,OpenAI宣布其最新的GPT-3语言模型(统称为InstructionGPT)现在是其API上使用的默认语言模型。根据OpenAI的说法,InstructGPT通过更好地遵循指令,生成更少的虚构事实,并生成更少的有毒内容,从而生成更符合用户意图的内容。[22]
由于GPT-3可以“生成人类评估人员难以区分人类撰写的文章的新闻文章”,因此GPT-3具有“促进语言模型的有益和有害应用的潜力”[1]: 34 在2020年5月28日的论文中,研究人员详细描述了GPT-3的潜在“有害影响”[5],其中包括“错误信息、垃圾邮件、网络钓鱼、滥用法律和政府程序、欺诈性学术论文写作和社会工程借口”。[1] 作者们提请注意这些危险,呼吁对风险缓解进行研究。[1][23]: 34
GPT-3能够执行零炮、少炮和单炮学习。[1]
2022年6月,Almira Osmanovic Thunström写道,GPT-3是一篇关于其自身的文章的主要作者,他们已将其提交出版[24],并在等待完成审查时进行了预发布。[25]
GPT-3.5
2022年3月15日,OpenAI在其API中提供了GPT-3和Codex的新版本,并以“text-davinci-003”和“code-davinci-002”的名称提供了编辑和插入功能。[26]这些模型被描述为比以前的版本更强大,并在2021 6月之前的数据上进行了培训。[27]2022年11月30日,OpenAI开始将这些模型称为“GPT-3.5”系列[28],并发布了ChatGPT,该模型与GPT-3.5系列中的模型进行了微调。[29]
应用
GPT-3,特别是Codex模型,是GitHub Copilot的基础,这是一种代码完成和生成软件,可用于各种代码编辑器和IDE。[30][31]
GPT-3在某些Microsoft产品中用于将传统语言转换为正式的计算机代码。[32][33]
GPT-3已在CodexDB[34]中用于生成SQL处理的查询特定代码。
Jason Rohrer在一个名为“12月项目”的复古主题聊天机器人项目中使用了GPT-3,该项目可以在线访问,并允许用户使用GPT-3技术与多个AI对话。[35]
GPT-3被《卫报》用来写一篇关于人工智能对人类无害的文章。它得到了一些想法,并发表了八篇不同的文章,最终合并成一篇文章。[36]
GPT-3被用于AI地下城,它生成基于文本的冒险游戏。后来,在OpenAI改变了其关于生成内容的政策后,它被一种竞争模式所取代。[37][38]
GPT-3用于Copy.ai,这是一款面向营销人员和企业主的ai文案应用程序。[39]
GPT-3用于Jasper.ai,这是一个旨在帮助营销人员和文案编辑的内容生成器。[40][41]
GPT-3用于Hypotense AI,这是一款内容创建应用程序,并与他们自己的专有技术相结合,用于为营销人员和企业撰写真实内容。[42]
2022年德雷克塞尔大学的一项研究表明,基于GPT-3的系统可以用于筛查阿尔茨海默病的早期症状。[43][44]
GPT-3介绍的更多相关文章
- eMMC基础技术9:分区管理
[转]http://www.wowotech.net/basic_tech/emmc_partitions.html 0.前言 eMMC 标准中,将内部的 Flash Memory 划分为 4 类区域 ...
- eMMC之分区管理、总线协议和工作模式【转】
本文转载自:https://blog.csdn.net/u013686019/article/details/66472291 一.eMMC 简介 eMMC 是 embedded MultiMedia ...
- BIOS与UEFI、MBR和GPT介绍
操作步骤: UEFI是取代传统BIOS的,全称“统一的可扩展固件接口”.MBR则是传统的分区表类型,最大的缺点则是不支持容量大于2T的硬盘.GPT则弥补了MBR这个缺点,最大支持18EB的硬盘,是基于 ...
- Linux 磁盘介绍(磁盘、分区、MBR、GPT)
原文:https://www.linuxidc.com/Linux/2013-06/85717.htm 1. CHS(Cylinder-Head-Sector): was an early metho ...
- UEFI+GPT引导基础篇(一):什么是GPT,什么是UEFI?
其实关于UEFI的几篇文章很早就写下了,只是自己读了一遍感觉很不满意,就决定重写.目的是想用最简单直白的语言把内容写出来,让每个人都能轻松读懂.当然,如果你已经对这些内容有了很深的理解的话,这篇文章除 ...
- win8.1/win10 UEFI + GPT 安装(测试机型:华硕S56CM)
本教程简要介绍在UEFI 启动模式下在GPT分区表中,最简单的方法安装 Windows 10 x64 位系统.(并非傻瓜教程,安装者总要有一定的经验基础)下面先简单介绍一下UEFI和GTP. UEFI ...
- UEFI GPT
其实关于UEFI的几篇文章很早就写下了,只是自己读了一遍感觉很不满意,就决定重写.目的是想用最简单直白的语言把内容写出来,让每个人都能轻松读懂.当然,如果你已经对这些内容有了很深的理解的话,这篇文章除 ...
- BIOS+MBR模式 VS UEFI+GPT模式
EFI与MBR启动的区别 大硬盘和WIN8系统,让我们从传统的BIOS+MBR模式升级到UEFI+GPT模式,现在购买的主流电脑,都是预装WIN8系统,为了更好的支持2TB硬盘 ,更快速的启动win ...
- web前端之 HTML标签详细介绍
html标签的分类 点我查看完整的html标签介绍 在html中,标签一般分为块级标签和行内标签 块级标签:块元素一般都从新行开始,它可以容纳内联元素和其他块元素,常见块元素是段落标签"p& ...
- EFI/GPT探索(为何win7分区时创建100M隐藏分区)
EFI/GPT探索(为何win7分区时创建100M隐藏分区) 转自 http://blog.tomatoit.net/article.asp?id=348 EFI/GPT是新一代的固件/启动管理技术, ...
随机推荐
- Linux内存占用过高排查过程
1 查看服务器状态 系统是 CentOS Linux release 7.5.1804 (Core)使用top命令看了下系统的状态 系统的整体负载和cpu并不高,但是内存使用比较高(总8G使用了7.2 ...
- [转载]危险操作一追到底--Linux的历史记录
转自:https://zhuanlan.zhihu.com/p/524921170 危险操作一追到底--Linux的历史记录 KellanFan 为了更好的自己 概述 在Linux下使用his ...
- ABAP 拼接PDF
参考标准程序RSPO_TEST_MERGE_PDF_FILES*--合并PDF data: pdf_merger type ref to cl_rspo_pdf_merge. data: ex typ ...
- 解决Connecting to 127.0.0.1:8118... failed: Connection refused.
这里是代理问题的锅 $ env|grep -I proxy http_proxy=http://127.0.0.1:8118 ftp_proxy=http://127.0.0.1:8118 https ...
- vue学习笔记:组件
组件是Vue.js最强大的功能之一.组件可以扩展HTML元素,封装可重用的代码,说白了就是一组可以重复使用的模板.组件系统让我们可以用独立可复用的小组件来构建大型应用,几乎任意类型的应用的界面都可以抽 ...
- cisco ios 密码恢复
如果没有break键,使用仿真软件模仿一个break 密码恢复请执行以下步骤 1. 关闭或断开路由器电源 2.开启路由器.在通电后的前30秒内按下break键(或通过仿真程序发送一个间断序列),来中断 ...
- Rstudio 快捷键无法使用
今天突然发现我的R studio 很多快捷键不能使用,后面发现是因为Rstudio 的快捷键与MobaXterm的快捷键起冲突了,后面关掉MobaXterm后就恢复了,如果有类似的问题可以在自己电脑打 ...
- TypeScript - 属性的修饰符
class Person { /** * TS 可以再属性前增加属性的修饰符 * public 修饰的属性可以再任意位置访问(修改)默认值 * private 私有属性,私有属性只能在类内部进行访问和 ...
- Mybaties中的报错 Tag name expected解决
有些时候一些小小的报错可能会没有注意到,等到报错的时候才发现,一个小小的细节也是很重要的,毕竟我们是bug生产员 来看报错的代码 when round((UNIX_TIMESTAMP(DATE_ADD ...
- zzul1073_Java
import java.util.Scanner;/** * 限制解是正数,且脚数为偶数即可 */public class zzul1073 { public static void main(Str ...