《Python深度学习》《卷积神经网络的可视化》精读
对于大多数深度学习模型,模型学到的表示都难以用人类可以理解的方式提取和呈现。但对于卷积神经网络来说,我们可以很容易第提取模型学习到的表示形式,并以此加深对卷积神经网络模型运作原理的理解。
这篇文章的内容参考了《python深度学习》的《卷积神经网络可视化》的内容,可以说是对其中内容的提炼,代码书中都有,其他博客有很多都提供了,因此我尽可能不把代码放进来,而是把内容关注在概念上。
这里主要介绍三种可视化形式:
- 可视化卷积神经网络的中间输出
- 可视化卷积神经网络的过滤器(或者说可视化卷积神经网络过滤器所匹配的图像)
- 可视化图像中类激活的热力图
可视化卷积神经网络的中间输出
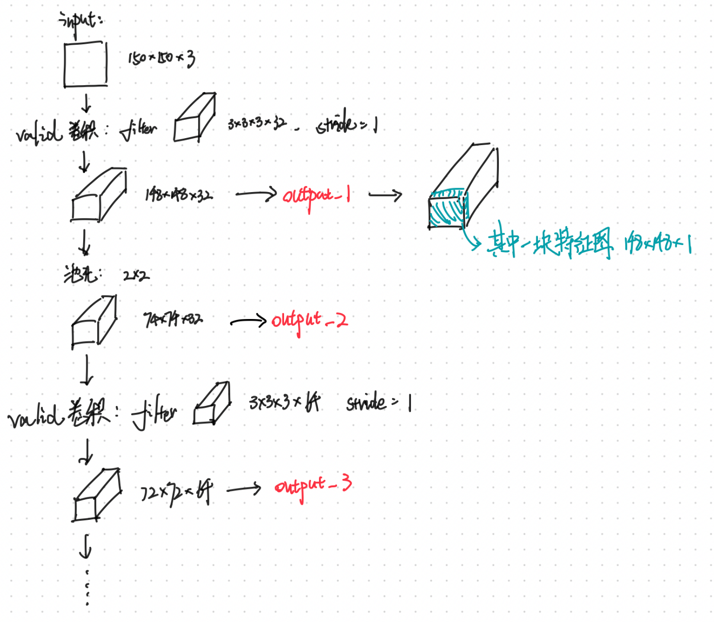
首先导入一个训练好的简单卷积神经网络模型,该模型主要用于猫狗图像的二分类,模型的结构如下所示。

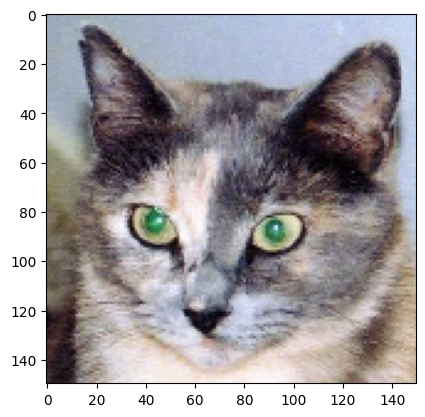
然后下面是用于实验的图片,我们将把这张图片作为输入传入到神经网络,并获取到8个中间层的特征图输出:
大概过程可以用下图表述:
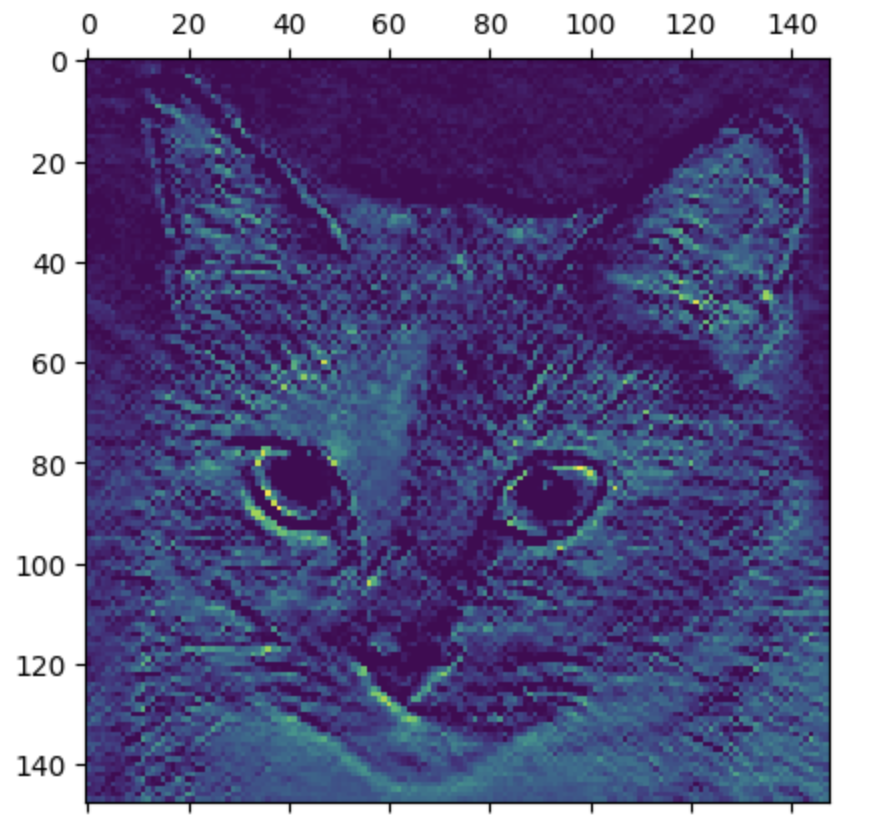
我们先关注第一个中间层的第一张特征图。
第一层能够获取到32张 148*148 的矩阵,把其中第一个矩阵作为图片格式输出一下,能够得到下图表示,可以发现第一张特征图主要是关注猫的面部特征。(绿色越深的位置表示了特征图提取特征的位置)
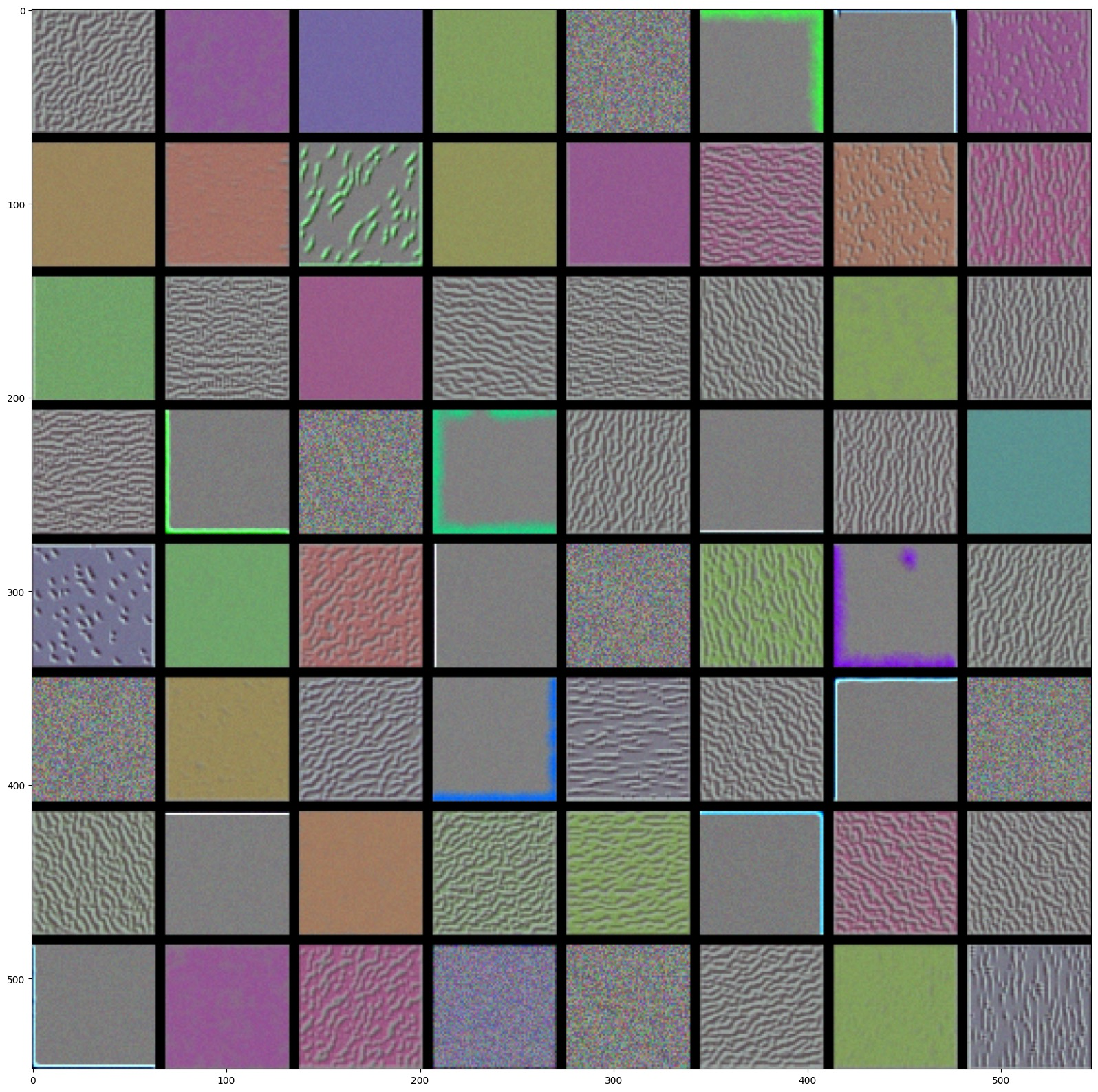
然后我们把八个层的所有特征图都输出一遍:


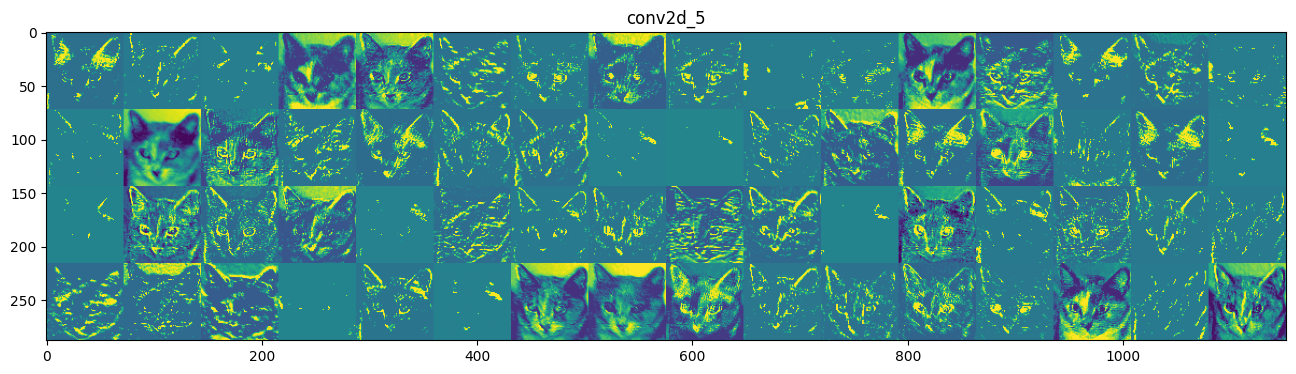

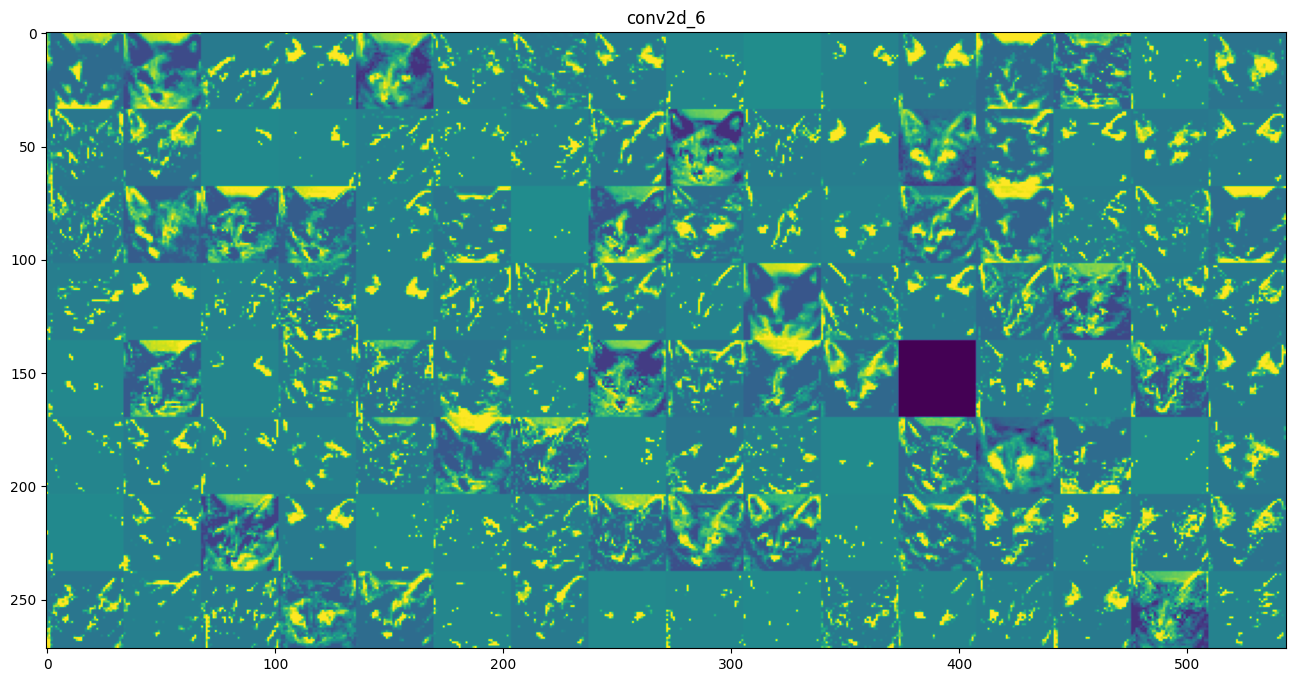

最后得出结论:
- 在卷积神经网络的第一层,特征图几乎保留了原始图像的所有信息,除了个别图片只提取了猫的某个部位(比如第二排第一个的特征几乎只提取了猫耳朵的信息)
- 随着层数的加深,特征图变得越来越模糊抽象。图像变得模糊是因为我们对原图像进行了最大池化,丢掉了一些几乎无用的像素点。特征图因此也开始关注更加局部的特征,比如尖耳朵、圆脑袋、五官的分布位置等。
可视化卷积神经网络的过滤器
以深度卷积神经网络模型VGG16为例,第7个卷积层有256个3*3*3的过滤器,每个过滤器都应该存在一个最佳匹配的图像,或者说像素特征。
这里说明一下为什么选择VGG16,我自己尝试过采用自建的模型进行可视化,但由于自建模型卷积层数较低,而较低层的卷积核表述的信息很多都是颜色图像和一些简单纹理,并不是一个好的例子,因此采用较深的VGG16
我们可以通过梯度上升的方式来计算出近似最佳匹配的图像矩阵。整个计算过程如下图表述:

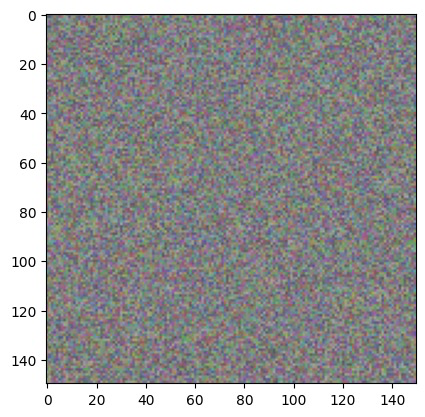
可以看一下初始点位X0的图像表示:
我们先关注一下第一个卷积核经过40次梯度下降所匹配的输入图像特征:
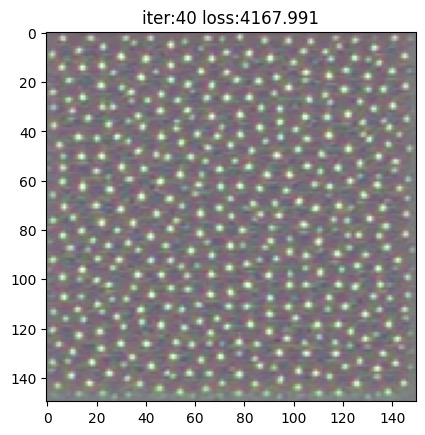
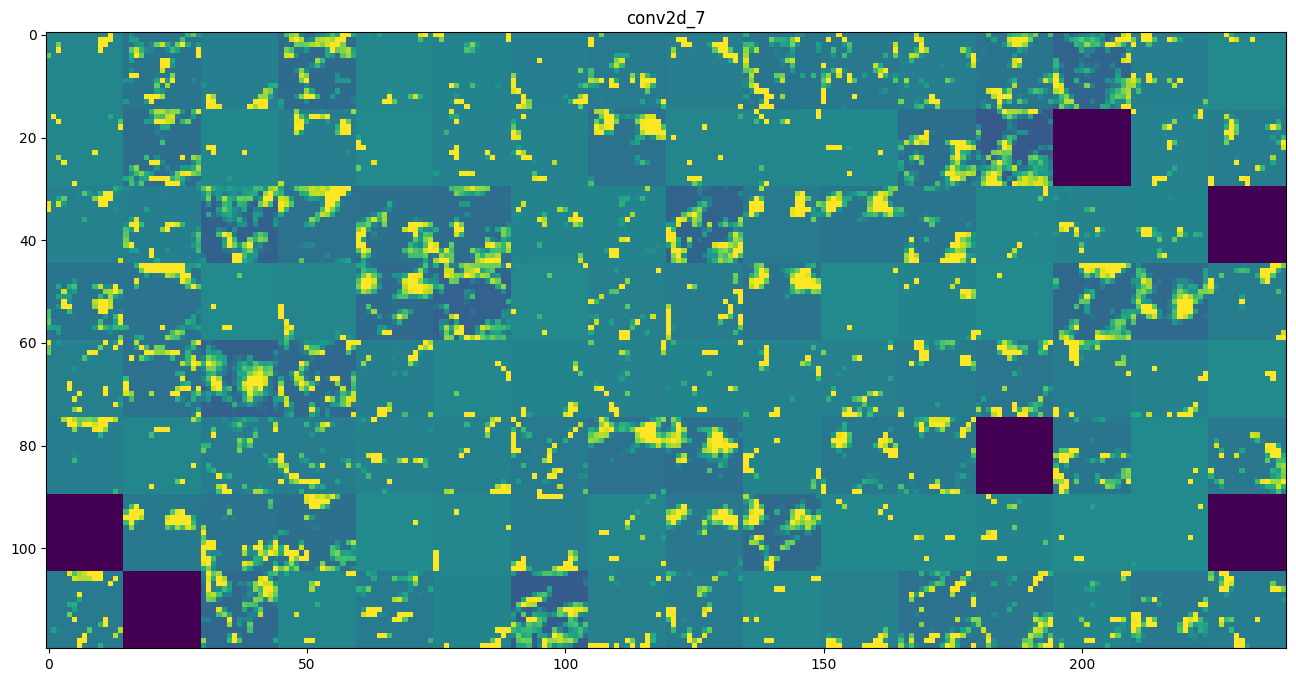
似乎 block3_conv1 的第一个卷积核响应的特征是波卡尔点图案,我们再分别输出三个卷积块的前60个卷积核所匹配的输入图像:
block1_conv1
block2_conv1
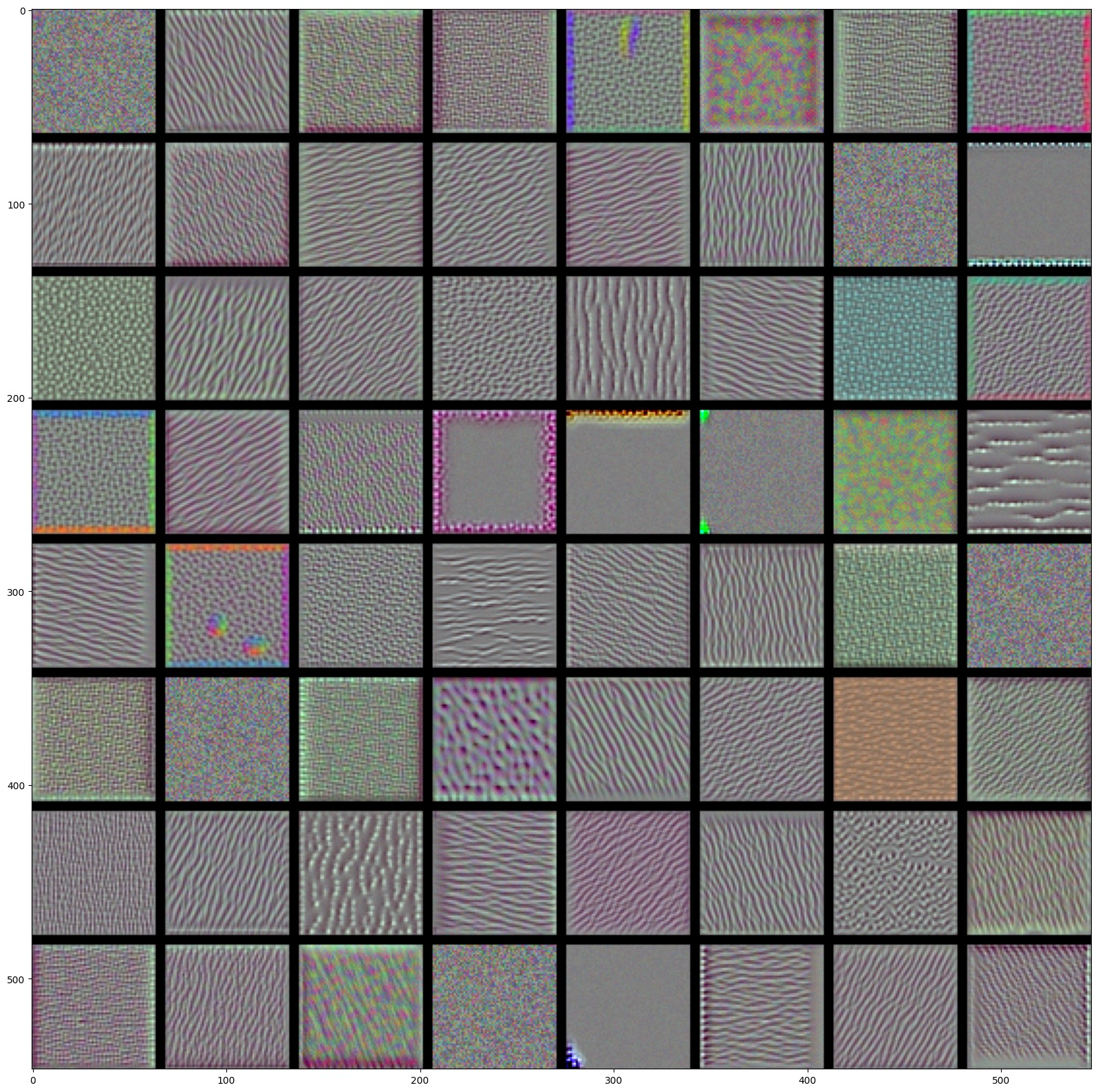
block3_conv1
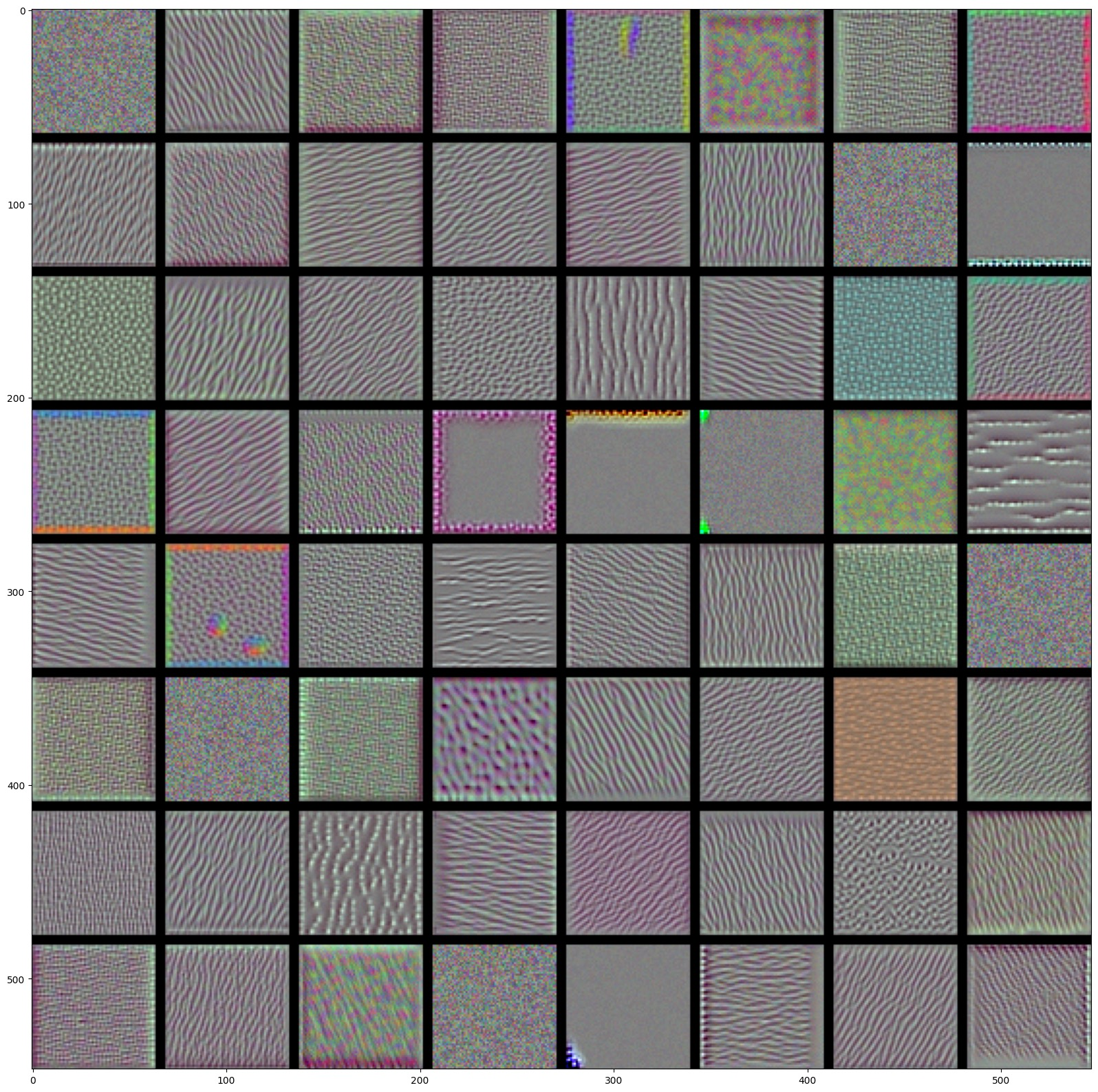
block4_conv1

可以发现随着层数加深,过滤器所匹配的图像变得越来越复杂,表述的形状也越来越精细。
模型的第一层和第二层大多包含一些简单的方向边缘和颜色以及一些纹理,到了第三层,纹理变得更加精细丰富,而第四层则表示了类似于自然图像中的纹理:羽毛、眼睛、树叶等。
可视化类激活的热力图
可视化类激活的热力图能够在图像上标注特定的位置,以得知神经网络通过图像的哪个部分来进行决策。
比如下面这张热力图则表示神经网络对大象的分类中,是通过大象头部的特征进行了决策。

这种方式还可以用于调试神经网络的决策过程,比如神经网络分类出错了,可以通过这种方式去看看,神经网络是因关注了什么特征而导致了出错。
热力图显示的原理在书中解释的非常简略,这里我再进行一个详细的补充。

上述过程描述的是单张特征图的计算过程,但我们有512张特征图,因此整个过程还需要执行512次,拿到一个14*14*512的热力图处理后的特征图集合。
最终我们需要获取到一张14*14的热力图,因此我们对上述的14*14*512的特征图向量进行加权平均
这里简单放一下处理过程的代码:
# 拿到非洲象的后验概率输出,也就是Y
african_elephant_output = model.output[:, 386]
# 拿到最后一个卷积层的14*14*512特征图向量X
last_conv_layer = model.get_layer('block5_conv3')
# 求grads=dY/dX
grads = K.gradients(african_elephant_output, last_conv_layer.output)[0]
# 对grads进行加权平均
pooled_grads = K.mean(grads, axis=(0, 1, 2))
iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x])
# 分别对512层特征图都乘上对应grads的加权值
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
# 加权平均获取到14*14的热力图
heatmap = np.mean(conv_layer_output_value, axis=-1)
然后我们看一下处理之前的加权平均显示的feature_map:
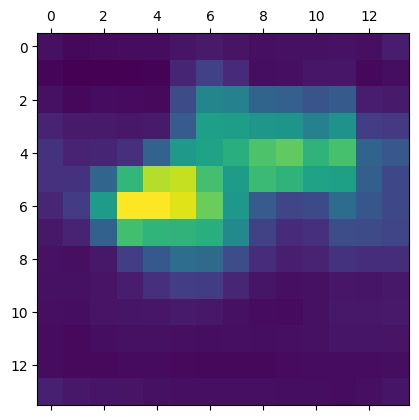
处理之后的heat_map
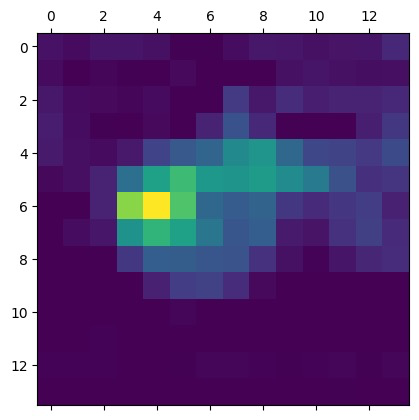
可以发现,颜色鲜艳的区域变得更少更集中。然后通过opencv把heat_map的格式套在原图上,就能够得到对应位置的热力图了。
《Python深度学习》《卷积神经网络的可视化》精读的更多相关文章
- 精读《V8 引擎 Lazy Parsing》
1. 引言 本周精读的文章是 V8 引擎 Lazy Parsing,看看 V8 引擎为了优化性能,做了怎样的尝试吧! 这篇文章介绍的优化技术叫 preparser,是通过跳过不必要函数编译的方式优化性 ...
- 深入浏览器工作原理和JS引擎(V8引擎为例)
浏览器工作原理和JS引擎 1.浏览器工作原理 在浏览器中输入查找内容,浏览器是怎样将页面加载出来的?以及JavaScript代码在浏览器中是如何被执行的? 大概流程可观察以下图: 首先,用户在浏览器搜 ...
- [翻译] V8引擎的解析
原文:Parsing in V8 explained 本文档介绍了 V8 引擎是如何解析 JavaScript 源代码的,以及我们将改进它的计划. 动机 我们有个解析器和一个更快的预解析器(~2x), ...
- 一文搞懂V8引擎的垃圾回收
引言 作为目前最流行的JavaScript引擎,V8引擎从出现的那一刻起便广泛受到人们的关注,我们知道,JavaScript可以高效地运行在浏览器和Nodejs这两大宿主环境中,也是因为背后有强大的V ...
- Chrome V8引擎系列随笔 (1):Math.Random()函数概览
先让大家来看一幅图,这幅图是V8引擎4.7版本和4.9版本Math.Random()函数的值的分布图,我可以这么理解 .从下图中,也许你会认为这是个二维码?其实这幅图告诉我们一个道理,第二张图的点的分 ...
- (译)V8引擎介绍
V8是什么? V8是谷歌在德国研发中心开发的一个JavaScript引擎.开源并且用C++实现.可以用于运行于客户端和服务端的Javascript程序. V8设计的初衷是为了提高浏览器上JavaScr ...
- 浅谈Chrome V8引擎中的垃圾回收机制
垃圾回收器 JavaScript的垃圾回收器 JavaScript使用垃圾回收机制来自动管理内存.垃圾回收是一把双刃剑,其好处是可以大幅简化程序的内存管理代码,降低程序员的负担,减少因 长时间运转而带 ...
- V8引擎嵌入指南
如果已读过V8编程入门那你已经熟悉了如句柄(handle).作用域(scope)和上下文(context)之类的关键概念,以及如何将V8引擎作为一个独立的虚拟机来使用.本文将进一步讨论这些概念,并介绍 ...
- 浅谈V8引擎中的垃圾回收机制
最近在看<深入浅出nodejs>关于V8垃圾回收机制的章节,转自:http://blog.segmentfault.com/skyinlayer/1190000000440270 这篇文章 ...
- 深入出不来nodejs源码-V8引擎初探
原本打算是把node源码看得差不多了再去深入V8的,但是这两者基本上没办法分开讲. 与express是基于node的封装不同,node是基于V8的一个应用,源码内容已经渗透到V8层面,因此这章简述一下 ...
随机推荐
- kubernetes client-go功能介绍
原味地址 https://haiyux.cc/2023/02/26/k8s-client-go/ client-go是什么? client-go是Kubernetes官方提供的Go语言客户端库,用于与 ...
- 【译】.NET 7 中的性能改进(八)
原文 | Stephen Toub 翻译 | 郑子铭 Mono 到目前为止,我一直提到 "JIT"."GC "和 "运行时",但实际上在.N ...
- TensorFlow中的Variable 变量
简单运用 这节课我们学习如何在 Tensorflow 中使用 Variable . 在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的. 定义语法: s ...
- pdf导出 预览、直接打印、打印加预览
前台: var xueurl = "fileFormatController.do?getXbDetail_print&id=&codes=" + rowsData ...
- 一篇教会你写90%的shell脚本
原文链接 : https://zhuanlan.zhihu.com/p/264346586 shell是外壳的意思,就是操作系统的外壳.我们可以通过shell命令来操作和控制操作系统,比如Linux ...
- 微积分 I 笔记
1.1 集合 这一节复习了高中关于集合的基础知识 介绍了一些新的概念 笛卡尔积 (Cartesian Product) 集合 \(X\) 与 \(Y\) 的笛卡尔积 (直积) \(X \times Y ...
- tesseract-ocr 安装、语言库、使用 随记
前几日才听说ocr的图片识别功能.觉得很有意思.先体验一下. 地址: GitHub - tesseract-ocr/tesseract: Tesseract Open Source OCR Engin ...
- redis的windows下安装
转载https://www.runoob.com/redis/redis-install.html Redis 安装 Windows 下安装 下载地址:https://github.com/tpora ...
- 实验一 Python程序设计入门 20203412马畅若
课程:<Python程序设计>班级: 2034姓名: 马畅若学号:20203412实验教师:王志强实验日期:2021年4月13日必修/选修: 公选课 实验一 (一)实验内容 1.熟悉Pyt ...
- IEEE 802.66( WiMax)的衰亡
1.什么是WiMax WiMAX全称为,World Interoperability for Microwave Access,即全球微波接入互操作性,是一项基于IEEE 802.16标准的宽带无线接 ...