推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]
1.前言:召回排序流程策略算法简介
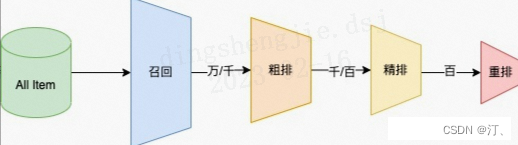
推荐可分为以下四个流程,分别是召回、粗排、精排以及重排:
- 召回是源头,在某种意义上决定着整个推荐的天花板;
- 粗排是初筛,一般不会上复杂模型;
- 精排是整个推荐环节的重中之重,在特征和模型上都会做的比较复杂;
- 重排,一般是做打散或满足业务运营的特定强插需求,同样不会使用复杂模型;
召回层:召回解决的是从海量候选item中召回千级别的item问题
- 统计类,热度,LBS;
- 协同过滤类,UserCF、ItemCF;
- U2T2I,如基于user tag召回;
- I2I类,如Embedding(Word2Vec、FastText),GraphEmbedding(Node2Vec、DeepWalk、EGES);
- U2I类,如DSSM、YouTube DNN、Sentence Bert;
模型类:模型类的模式是将用户和item分别映射到一个向量空间,然后用向量召回,这类有itemcf,usercf,embedding(word2vec),Graph embedding(node2vec等),DNN(如DSSM双塔召回,YouTubeDNN等),RNN(预测下一个点击的item得到用户emb和item emb);向量检索可以用Annoy(基于LSH),Faiss(基于矢量量化)。此外还见过用逻辑回归搞个预估模型,把权重大的交叉特征拿出来构建索引做召回
排序策略,learning to rank 流程三大模式(pointwise、pairwise、listwise),主要是特征工程和CTR模型预估;
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
- 常见的特征挖掘(user、item、context,以及相互交叉);
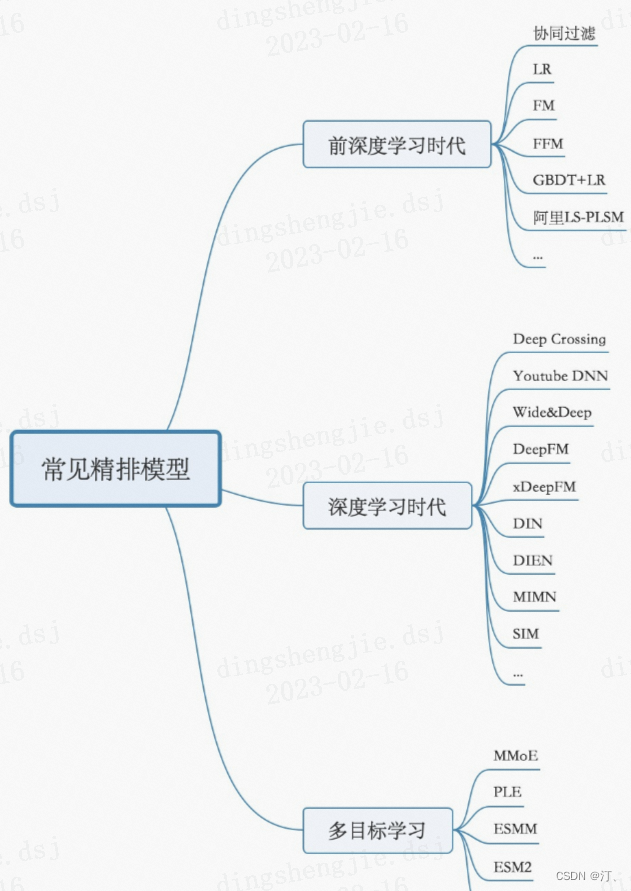
- 精排层:精排解决的是从千级别item到几十这个级别的问题
- CTR预估:lr,gbdt,fm及其变种(fm是一个工程团队不太强又对算法精度有一定要求时比较好的选择),widedeep,deepfm,NCF各种交叉,DIN,BERT,RNN
- 多目标:MOE,MMOE,MTL(多任务学习)
- 打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等
- 粗排层:本质上跟精排类似,只是特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排
重排层:重排层解决的是展示列表总体最优,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)
展示层:
- 推荐理由:统计规则、行为规则、抽取式(一般从评论和内容中抽取)、生成式;排序可以用汤普森采样(简单有效),融合到精排模型排等等
- 首图优选:CNN抽特征,汤普森采样
探索与利用:随机策略(简单有效),汤普森采样,bandit,强化学习(Q-Learning、DQN)等
产品层:交互式推荐、分tab、多种类型物料融合
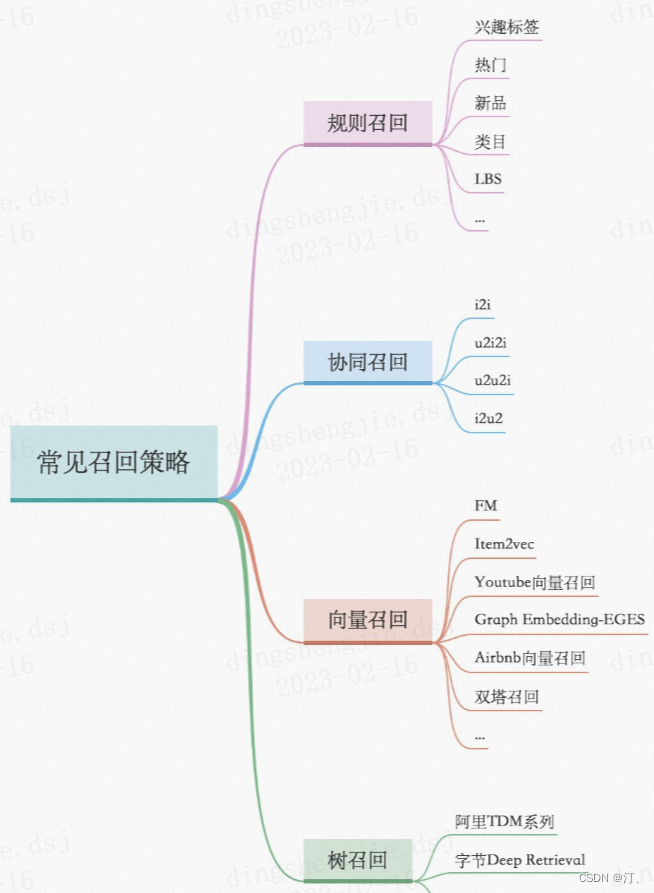
2.召回算法简介
召回区分主路和旁路,主路的作用是个性化+向上管理,而旁路的作用是查缺补漏
推荐系统的前几个操作可能就决定了整个系统的走向,在初期一定要三思而后行
做自媒体,打广告,漏斗的入口有多大很重要。
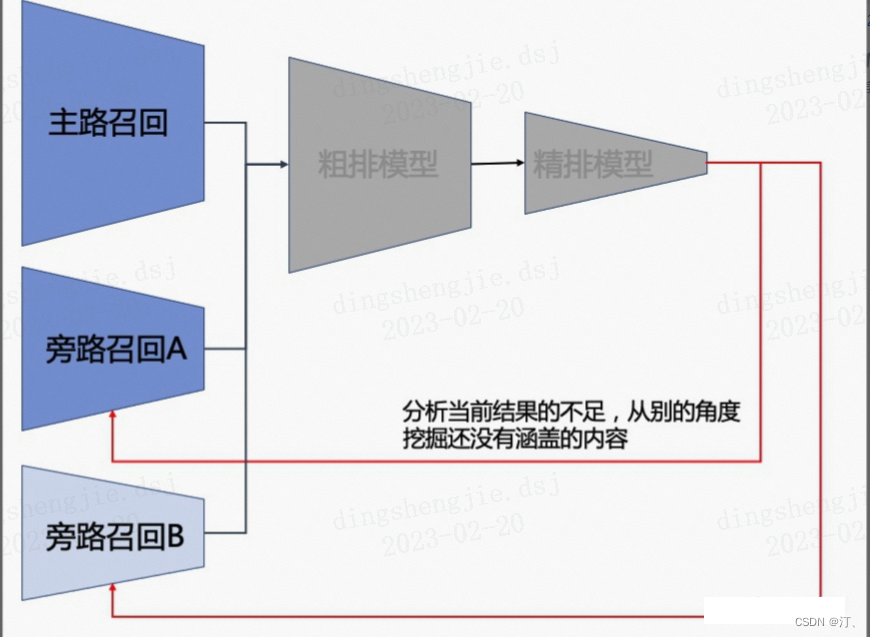
召回这里稍微有些复杂,因为召回是多路的。首先我们要解释主路和旁路的差别,主路的意义和粗排类似,可以看作是一个入口更大,但模型更加简单的粗排。主路的意义是为粗排分担压力。但是旁路却不是这样的,旁路出现的时机往往是当主路存在某种机制上的问题,而单靠现在的这个模型很难解决的时候。举个例子,主路召回学的不错,但是它可能由于某种原因,特别讨厌影视剧片段这一类内容,导致了这类视频无法上升到粗排上。那这样的话整个系统推不出影视剧片段就是一个问题。从多路召回的角度来讲,我们可能需要单加一路专门召回影视剧的,并且规定:主路召回只能出3000个,这一路新加的固定出500个,两边合并起来进入到粗排中去。这个栗子,是出现旁路的一个动机。
2.1 召回路径介绍
推荐系统中的i2i、u2i、u2i2i、u2u2i、u2tag2i,都是指推荐系统的召回路径。
第一种召回,是非个性化的。比如对于新用户,我们要确保用最高质量的视频把他们留住,那么我们可以划一个“精品池”出来,根据他们的某种热度排序,作为一路召回。做法就是新用户的每次请求我们都把这些精品池的内容当做结果送给粗排。这样的召回做起来最容易,用sql就可以搞定。
第二种召回,是i2i,i指的是item,严格意义上应该叫u2i2i。指的是用用户的历史item,来找相似的item。比如说我们把用户过去点过赞的视频拿出来,去找画面上,BGM上,或者用户行为结构上相似的视频。等于说我们就认为用户还会喜欢看同样类型的视频。这种召回,既可以从内容上建立相似关系(利用深度学习),也可以用现在比较火的graph来构建关系。这种召回负担也比较小,图像上谁和谁相似完全可以离线计算,甚至都不会随着时间变化。
第三种召回是u2i,即纯粹从user和item的关系出发。我们所说的双塔就是一个典型的u2i。在用户请求过来的时候,计算出user的embedding,然后去一个实现存好的item embedding的空间,寻找最相似的一批拿出来。由于要实时计算user特征,它的负担要大于前面两者,但这种召回个性化程度最高,实践中效果也是非常好的。
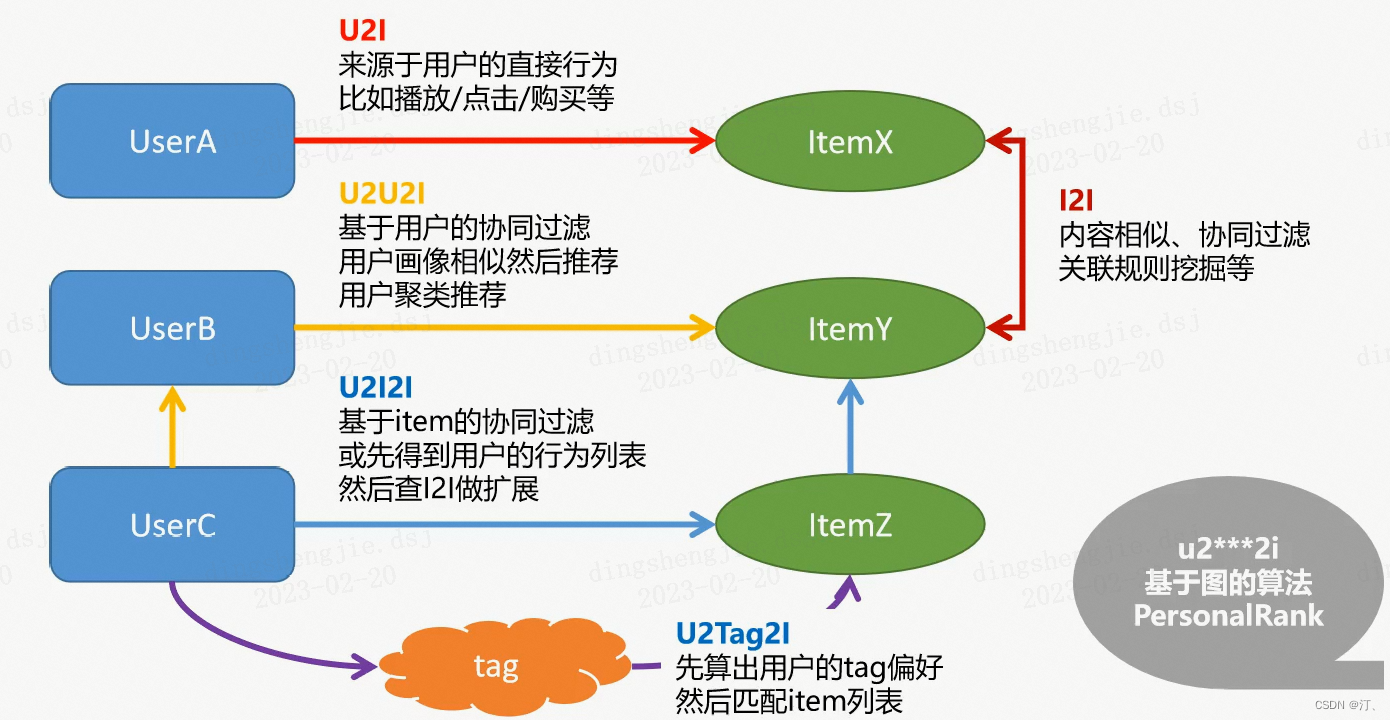
通过上图理解什么是召回路径:
- u、i、tag是指图中的节点
- 2是指图中的线(关系)
i2i:指从一个物品到达另外一个物品,item 到 item
- 应用:头条,在下方列出相似的、相关的文章;
- 算法:
- 内容相似,eg:文章的相似,取标题的关键字,内容相似
- 协同过滤
- 关联规则挖掘等
- 两个物品被同时看的可能性很大,当一个物品被查看,就给他推荐另一个物品
u2i:指从一个用户到达一个物品,user 到item
- 一般指用户的直接行为,比如播放、点击、购买等;
- 用户查看了一个物品,就会再次给它推荐这个物品
- 结合i2i一起使用,就是用户查看以合物品,就会给他推荐另一个相似的物品,就是u2i2i路径;
u2i2i:从一个用户,通过一个物品,到达另一个物品
- 用户查看了一个耳机(u2i),找出和这个耳机相似或者相关的产品(i2i)并推荐给用户
- 对路径的使用,已经从一条线变成两条线
- 方法:就是把两种算法结合起来,先得到u2i的数据,再利用i2i的数据进行扩展,就可以从第一个节点,越过一个节点,到达第三个节点,实现推荐
- 中间的桥梁是item
u2u2i:从一个用户,到达另一个用户,到达一个物品
- 先计算u2u:两种方法
- 一是:取用户的性别、年龄、职业等人工属性的信息,计算相似性,得到u2u;
- 一是:从行为数据中进行挖掘,比如看的内容和视频大部分很相似,就可以看作一类人;
- 也可以使用聚类的方法进行u2u计算
- u2u一般用在社交里,比如微博、Facebook,推荐感兴趣的人
- userB和UserC相似,如果userB查看了某个商品,就把这个商品推荐给userC;
- 中间的桥梁是user
u2tag2i:中间节点是Tag标签,而不是 u 或者 i
京东,豆瓣,物品的标签非常丰富、非常详细;比如统计一个用户历史查看过的书籍,就可以计算标签偏好的向量:标签+喜欢的强度。
用户就达到了tag的节点,而商品本身带有标签,这就可以互通,进行推荐
先算出用户的tag偏好,然后匹配item列表
这种方法的泛化性能比较好(推荐的内容不那么狭窄,比如喜欢科幻,那么会推荐科幻的所有内容)
今日头条就大量使用标签推荐
基于图的算法:u22i*
起始于U,结束于I,中间跨越很多的U、很多的I,可以在图中不停的游走
例如:PersonalRank,不限制一条还是两条线,在图中到处的游走,游走带着概率,可以达到很多的item;但是相比前面一条、两条边的路径,性能不是很好
2.2 多路召回融合排序
2.2.1 多路召回
推荐服务一般有多个环节(召回、粗排序、精排序),一般会使用多个召回策略,互相弥补不足,效果更好。比如说:
- 实时召回- U2I2I,
- 几秒之内根据行为更新推荐列表。
- 用U2I得到你实时的行为对象列表,再根据I2I得到可能喜欢的其他的物品
- 这个是实时召回,剩下3个是提前算好的
- 基于内容 - U2Tag2I
- 先算好用户的偏好tag,然后对tag计算相似度,获取可能感兴趣的item
- 矩阵分解 - U2I
- 先算好User和Item的tag矩阵,然后叉乘,给每个user推荐item
- 提前存储好进行推荐
- 聚类推荐 - U2U2I
- 根据用户信息对用户进行聚类,然后找到最相似的user,推荐最相似user喜欢的物品;或者找到聚类中大家喜欢的物品,进行推荐
写程序时,每个策略之间毫不相关,所以:
1、一般可以编写并发多线程同时执行
2、每一种策略输出结果,都有一个顺序,但最后要的结果只有一个列表,这就需要融合排序
2.2.2 融合排序
多种召回策略的内容,取TOPN合并成一个新的列表。这个新的列表,可以直接返回给前端,进行展示;也可以发给精排,进行排序。
精排模型非常耗时,所以召回的内容,会经过粗排之后,把少量的数据给精排进行排序
几种多路召回结果融合的方法
举个例子:几种召回策略返回的列表(Item-id,权重)分别为:
| 召回策略 | 返回列表 | ||
|---|---|---|---|
| 召回策略X | A:0.9 | B:0.8 | C:0.7 |
| 召回策略Y | B:0.6 | C:0.5 | D:0.4 |
| 召回策略Z | C:0.3 | D:0.2 | E:0.1 |
融合策略:
1、按顺序展示
- 比如说实时 > 购买数据召回 > 播放数据召回,则直接展示A、B、C、D、E
2、平均法
- 分母为召回策略个数,分子为权重加和
- C为(0.7+0.5+0.3)/3,B为(0.8+0.6)/3
3、加权平均
- 比如三种策略自己指定权重为0.4、0.3、0.3,则B的权重为(0.40.8 + 0.60.3 + 0*0.2)/ (0.4+0.3+0.2),这个方法有个问题就是,每个策略的权重是自己设置的,并不准确,所以,有动态加权法
4、动态加权法
- 计算XYZ三种召回策略的CTR,作为每天更新的动态加权
- 只考虑了点击率,并不全面
- 每种召回源CTR计算方法:
- 展现日志-带召回源:X,Y,Z,X,Y,Z
- 点击日志-带召回源:点击X
- 则每种召回的CTR = 点击数/展现数
5、机器学习权重法
- 逻辑回归LR分类模型预先离线算好各种召回的权重,然后做加权召回
- 考虑更多的特征以及环境因素,会更准确
以上融合排序的方法,成本逐渐增大,效果依次变好,按照成本进行选择
3.推荐场景中召回模型的演化过程
3.1 传统方法:基于协同过滤
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
3.2 单 Embedding 向量召回
3.2.1 Youtube DNN 召回
3.2.2 双塔模型召回
3.2 多 Embedding 向量召回-用户多兴趣表达
3.2.1 Multi-Interest Network with Dynamic Routing 模型
3.3 Graph Embedding
3.3.1 阿里 Graph Embedding with Side information
传统的 graph embedding 过程如下图:
3.3.2 GraphSAGE:Inductive representation learning on large graphs
3.4 结合用户长期和短期兴趣建模
3.4.2 Next Item Recommendation with Self-Attention
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
3.5 TDM 深度树匹配召回
TDM 是为大规模推荐系统设计的、能够承载任意先进模型 ( 也就是可以通过任何深度学习推荐模型来训练树 ) 来高效检索用户兴趣的推荐算法解决方案。TDM 基于树结构,提出了一套对用户兴趣度量进行层次化建模与检索的方法论,使得系统能直接利高级深度学习模型在全库范围内检索用户兴趣。其基本原理是使用树结构对全库 item 进行索引,然后训练深度模型以支持树上的逐层检索,从而将大规模推荐中全库检索的复杂度由 O(n) ( n 为所有 item 的量级 ) 下降至 O(log n)。
3.5.1 树结构
3.5.2 怎么基于树来实现高效的检索?
3.5.3 兴趣建模
4.当前业界的主流召回算法综述
4.1 Youtube DNN
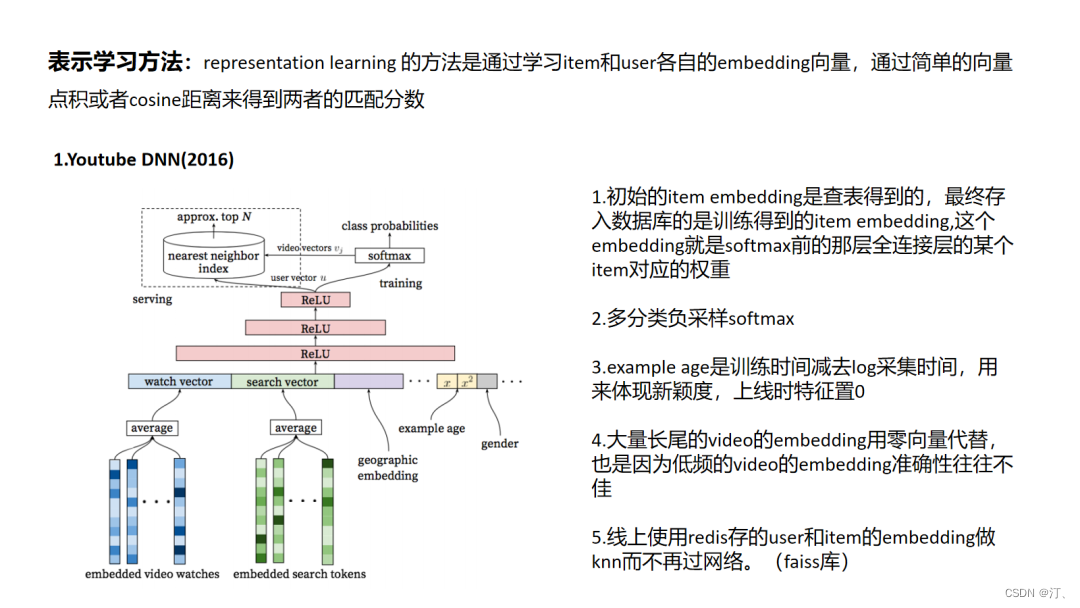
当前的主流方法的通用思路就是对于use和item的embedding的学习, 这也被称为表示学习; YoutbeDNN是经典的将深度学习模型引入推荐系统中,可以看到网络模型并不复杂,但是文中有很多工程上的技巧,比如说 word2vec对 video 和 search token做embedding后做为video初始embedding,对模型训练中训练时间和采集日志时间之间“position bias”的处理,以及对大规模多分类问题的负采样softmax。
4.2 DeepMF
4.3 DSSM
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
4.4.Item2vec
4.5.Airbnb Embedding
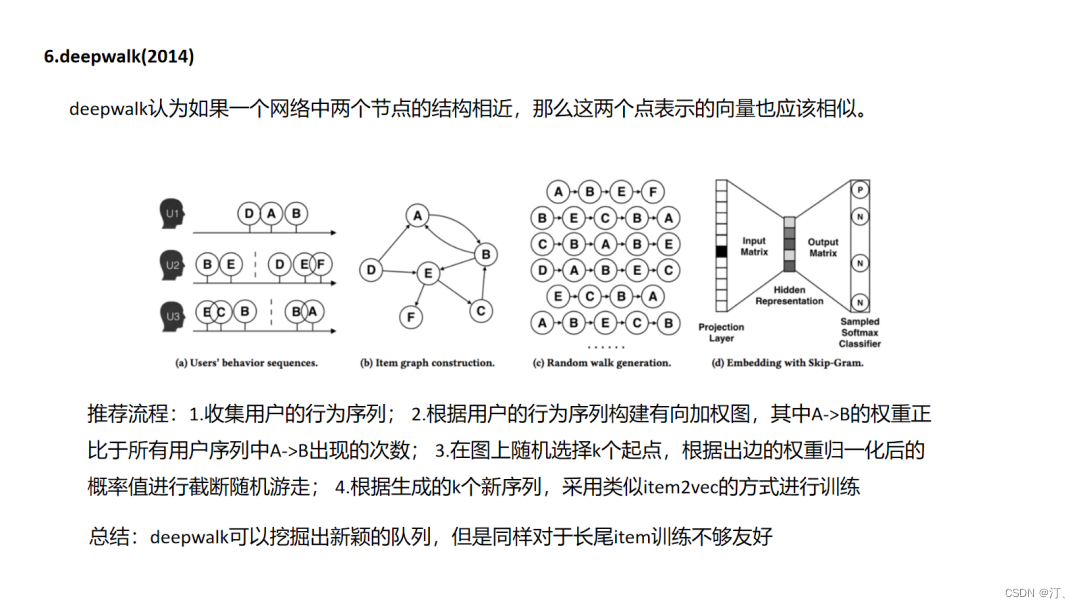
4.6.DeepWalk
4.7 Node2Vec
4.8.EGES
4.9.LINE
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
4.10.SDNE
4.11.GraphSAGE
4.12 MIND
4.13.SDM
4.14.DeepFM
4.15.NCF
4.16.TDM
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
参考推荐:
关于图相关学习推荐参考
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
更多内容参考:https://blog.csdn.net/sinat_39620217/article/details/129119611
推荐系统[二]:召回算法超详细讲解[召回模型演化过程、召回模型主流常见算法(DeepMF_TDM_Airbnb Embedding_Item2vec等)、召回路径简介、多路召回融合]的更多相关文章
- 人工鱼群算法超详细解析附带JAVA代码
01 前言 本着学习的心态,还是想把这个算法写一写,给大家科普一下的吧. 02 人工鱼群算法 2.1 定义 人工鱼群算法为山东大学副教授李晓磊2002年从鱼找寻食物的现象中表现的种种移动寻觅特点中得到 ...
- Elasticsearch BM25相关度算法超详细解释
Photo by Pixabay from Pexels 前言:日常在使用Elasticsearch的搜索业务中多少会出现几次 "为什么这个Doc分数要比那个要稍微低一点?".&q ...
- 干货 | 10分钟带你掌握branch and price(分支定价)算法超详细原理解析
00 前言 相信大家对branch and price的神秘之处也非常好奇了.今天我们一起来揭秘该算法原理过程.不过,在此之前,请大家确保自己的branch and bound和column gene ...
- 最小生成树详细讲解(一看就懂!) & kruskal算法
0.前言 因为本人太蒟了 我现在连NOIP的初赛都在胆战心惊 并且我甚至连最小生成树都没有学过 所以这一篇博客一定是最详细的QAQ 哈哈 请您认真看完如果有疏漏之处敬请留言指正 感谢! Thanks♪ ...
- 万字长文,以代码的思想去详细讲解yolov3算法的实现原理和训练过程,Visdrone数据集实战训练
以代码的思想去详细讲解yolov3算法的实现原理和训练过程,并教使用visdrone2019数据集和自己制作数据集两种方式去训练自己的pytorch搭建的yolov3模型,吐血整理万字长文,纯属干货 ...
- 【分类问题中模型的性能度量(一)】错误率、精度、查准率、查全率、F1详细讲解
文章目录 1.错误率与精度 2.查准率.查全率与F1 2.1 查准率.查全率 2.2 P-R曲线(P.R到F1的思维过渡) 2.3 F1度量 2.4 扩展 性能度量是用来衡量模型泛化能力的评价标准,错 ...
- C++语言堆栈的详细讲解
本文主要向大家介绍了C++语言堆栈的详细讲解,通过具体的内容向大家展示,希望对大家学习C++语言有所帮助. 一.预备知识—程序的内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1.栈区 ...
- 详细讲解nodejs中使用socket的私聊的方式
详细讲解nodejs中使用socket的私聊的方式 在上一次我使用nodejs+express+socketio+mysql搭建聊天室,这基本上就是从socket.io的官网上的一份教程式复制学习,然 ...
- HighCharts学习笔记(二)HighCharts结构及详细配置
HighCharts结构及详细配置: 一.HighCharts整体结构: 通过查看API文档我们知道HighCharts结构如下:(API文档在文章后面提供下载) var chart = new Hi ...
- 第2章 rsync(二):inotify+rsync详细说明和sersync
本文目录: inotify+rsync 1.1 安装inotify-tools 1.2 inotifywait命令以及事件分析 1.3 inotify应该装在哪里 1.4 inotify+rsync示 ...
随机推荐
- vscode 更新后重启恢复旧版
vscode的自动更新自动安装在C:\Users\admin\AppData\Local\,如果之前的vscode不在默认位置,就会更新出两个版本,如果还用了固定在开始屏幕或者任务栏,则一直在打开旧版 ...
- python仿写js算法二
前言 之前写过一篇用python 仿写 js 算法,当时以为大部分语法都已经能很好的在python找到对应的语法结构,直到前几天我用 python 仿写了 慕课网解析视频加密的算法,我发现很多之前没遇 ...
- go-dongle 0.2.0 版本发布了,一个轻量级、语义化的 golang 编码解码、加密解密库
dongle 是一个轻量级.语义化.对开发者友好的 Golang 编码解码和加密解密库 Dongle 已被 awesome-go 收录, 如果您觉得不错,请给个 star 吧 github.com/g ...
- 「Docker学习系列教程」9-Docker容器数据卷介绍
通过前面8篇文章的学习,我们已经学会了docker的安装.docker常用的命令已经docker镜像修改后提交的远程镜像仓库及提交到公司的私服仓库中.接下来,我们再来学学Docker另外一个重要的东西 ...
- JAVA中的注解可以继承吗?
前言 注解想必大家都用过,也叫元数据,是一种代码级别的注释,可以对类或者方法等元素做标记说明,比如Spring框架中的@Service,@Component等.那么今天我想问大家的是类被继承了,注解能 ...
- 命令指定IP端口号
tcping命令是针对tcp监控的,也可以看到ping值,即使源地址禁ping也可以通过tcping来监控服务器网络状态,除了简单的ping之外,tcping最大的一个特点就是可以指定端口. 将下载好 ...
- NeurIPS 2022:基于语义聚合的对比式自监督学习方法
摘要:该论文将同一图像不同视角图像块内的语义一致的图像区域视为正样本对,语义不同的图像区域视为负样本对. 本文分享自华为云社区<[NeurIPS 2022]基于语义聚合的对比式自监督学习方法&g ...
- 回顾Vue计算属性VS其他语法有感
回顾Vue计算属性VS其他语法有感 重新回顾官方教程中的到计算属性和侦听器,发觉获益良多,主要就是两点: 计算属性和其他语法的比较 计算属性.侦听属性.方法.模板变量的使用 计算属性和其他语法的比较 ...
- 字符编码:Unicode & UTF-16 & UTF-8
ASCII码 使用一个字节(8位),对128个字符进行编码: 最高位始终为0: 码数范围为0000_0000(0x00)到0111_1111(0x7F): Unicode 开始的编码设计 使用两个字节 ...
- MasaFramework -- i18n (国际化)
概念 作为一个普通开发者, 我们负责的项目的使用群体大多数是本国的人民, 但不可避免的也有一些做外贸的业务或者给外企做的项目, 这个时候就要求我们的项目有服务全球客户的能力, 而一个支持国际化能力的框 ...