Luffy项目:2、项目需求(2),项目库的创建,软件开发目录,Django配置文件介绍
Luffy项目
一、Luffy项目需求(2)
1、后台日志封装
需求:
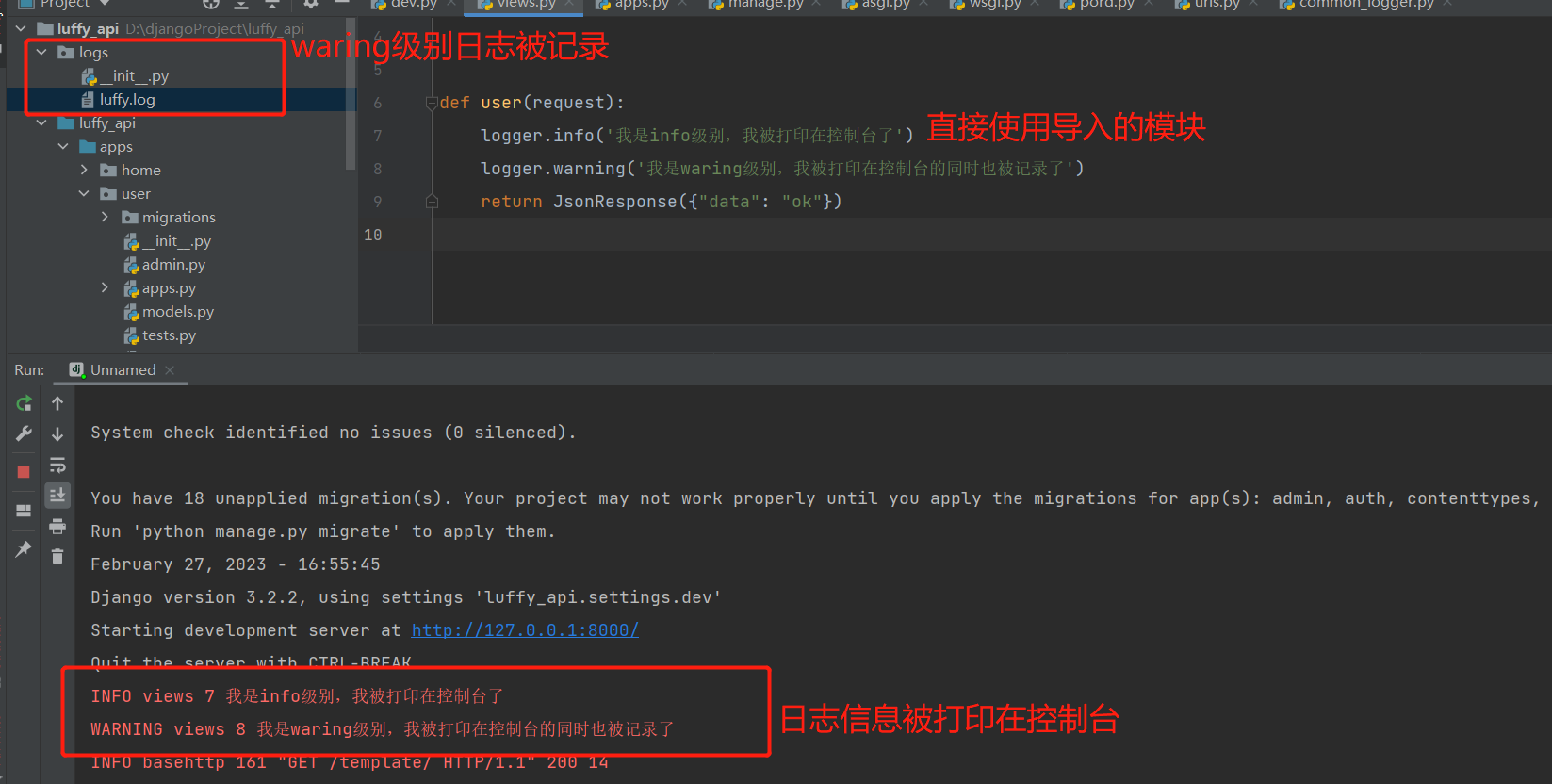
在项目目录下创建logs目录,用于记录项目日志
要求:
- 打印在控制台
- 记录在logs文件下的日志文件中
- 所有项目日志统一管理
操作步骤:
- 第一步:在项目配置文件中进行配置-----大字典
# 详情在下方大字典中查看
- 第二步:在utils文件下新建common_logger.py得到日志对象
import logging
logger = logging.getLogger('django')
- 第三步:在需要使用的地方直接导入使用
from utils.common_logger import logger
logger.info('info级别的日志')
logger.error('error级别的日志')
配置字典:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'verbose': {
'format': '%(levelname)s %(asctime)s %(module)s %(lineno)d %(message)s'
},
'simple': {
'format': '%(levelname)s %(module)s %(lineno)d %(message)s'
},
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': {
'console': {
# 实际开发建议使用WARNING
'level': 'INFO',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
'file': {
# 实际开发建议使用ERROR
'level': 'WARNING',
'class': 'logging.handlers.RotatingFileHandler',
# 日志位置,日志文件名,日志保存目录必须手动创建,注:这里的文件路径要注意BASE_DIR代表的是小luffyapi
'filename': os.path.join(os.path.dirname(BASE_DIR), "logs", "luffy.log"),
# 日志文件的最大值,这里我们设置300M
'maxBytes': 300 * 1024 * 1024,
# 日志文件的数量,设置最大日志数量为10
'backupCount': 10,
# 日志格式:详细格式
'formatter': 'verbose',
# 文件内容编码
'encoding': 'utf-8'
},
},
# 日志对象
'loggers': {
'django': {
'handlers': ['console', 'file'],
'propagate': True, # 是否让日志信息继续冒泡给其他的日志处理系统
},
}
}
2、全局异常处理、封装
需求:
当用户在使用项目的时候,可能会出现报错,如果不对报错进行处理,那么项目将会直接崩溃,针对这个问题应该对错误进行捕获,并返回统一的错误信息给用户,提高用户体验
要求:
本次项目使用的是drf框架,
- 对drf和项目的报错信息统一格式反馈给用户
操作步骤:
- 第一步:在utils文件下创建common_excepions.py
- 第二步:编写函数
详见下方代码
- 第四步:在项目配置文件中进行配置
REST_FRAMEWORK = {
'EXCEPTION_HANDLER': 'utils.common_exceptions.exception_handler',
}
函数代码:
from rest_framework.views import exception_handler as drf_exception_handler
from utils.common_logger import logger
from rest_framework.response import Response
def exception_handler(exc, context):
# 获取request
request = context.get('request')
# 获取登录用户
user = request.user
if not user:
user = '匿名用户'
# 获取用户ip
user_ip = request.META.get('REMOTE_ADDR')
# 获取出错的视图函数
view = context.get('view')
# 获取路由地址
url_path = request.get_full_path()
# response(有:drf错误/无:项目错误)
response = drf_exception_handler(exc, context)
if response:
# 将错误信息记录
logger.warning('异常来源:【drf】,异常信息:【%s】' % str(exc))
# 将错误信息进行处理返回给前端
res = Response({'code': 998, 'msg': request.data.get('detail', '系统异常,请联系管理员')})
else:
# 记录错误信息
logger.error('错误来源:【系统内部】,用户:【%s】,ip地址:【%s】,访问地址:【%s】,执行视图函数:【%s】,错误详情:【%s】'
% (user, user_ip, url_path, str(view), str(exc)))
# 统一处理错误信息
res = Response({'code': 999, 'msg': '系统异常,请联系管理员'})
return res

3、封装Response对象
需求:
在后期编写视图函数需要将接口信息返回给前端时,每次都需要反复的编写接口信息,很多数据都是重复的,封装新的responce,重复的接口信息不需要反复编写
要求:
封装新的response对象
- 反馈数据时,不需要反复的编写code、msg类的数据
# 本身drf有Response,但是咱们公司规定,前端收到的格式都是固定的
-{code:100,msg:提示,data:{}/[]}
-{code:100,msg:提示,token:asdfasd,user:lqz}
# 对Response进行封装,封装后,code,msg可以不传,不传就用默认的
操作步骤:
- 第一步:在uitls文件下新建common_response.py
- 第二步:封装新的response对象(APIresponse)
详细代码如下
- 第三步:需要反馈数据时,只需要返回自己封装的对象
函数代码:
from rest_framework.response import Response
class ApiResponse(Response):
def __init__(self, code=100, msg='成功', status=None, headers=None, **kwargs):
data = {'code': code, 'msg': msg}
if kwargs:
data.update(**kwargs)
super().__init__(data=data, status=status, headers=headers)

二、Luffy项目数据库创建
1、创建用户数据库
# 创建luffy数据库
# 之前项目操作数据库,都是使用root用户,root用户权限太高了,在公司里,一般不会给你root用户权限
# 如果开发人员是root权限,数据安全性就很差
# 开发人员,专门创建一个用户,用户只对当前项目的库有操作权限
# 创建一个luffy库,创建luffy用户,luffy用户只对luffy库有操作权限
"""
1.管理员连接数据库
>: mysql -uroot -proot
2.创建数据库
>: create database luffy default charset=utf8;
3.查看用户
>: select user,host from mysql.user;
只有root用户,要创建luffy用户
# 5.7往后的版本
>: select user,host,authentication_string from mysql.user;
"""
#创建路飞用户,授予luffy库所有权限
"""
设置权限账号密码
# 授权账号命令:grant 权限(create, update) on 库.表 to '账号'@'host' identified by '密码'
1.配置任意ip都可以连入数据库的账户
>: grant all privileges on luffy.* to 'luffy'@'%' identified by 'Luffy123?';
2.由于数据库版本的问题,可能本地还连接不上,就给本地用户单独配置
>: grant all privileges on luffy.* to 'luffy'@'localhost' identified by 'Luffy123?';
3.刷新一下权限
>: flush privileges;
只能操作luffy数据库的账户
账号:luffy
密码:Luffy123?
"""
2、使用项目链接数据库
前置条件:
# 项目操作mysql,需要安装模块
-pymysql
-mysqlDB
-mysqlclient
-历史:原来py2上有个操作mysql的模块叫mysqlDB,但到py3,没有支持py3,django默认使用这个模块去连接mysql,默认使用-mysqlDB连接,-mysqlDB不支持py3,运行报错
-我们使用pymysql,作为连接mysql的数据库模块,但是需要加代码
imprort pymysql
pymysql.install_as_mysqldb() # 猴子补丁
-django 2.2.2以后,还使用pymysql,需要改djagno源代码
-统一使用mysqlclient来作为操作mysql的底层库
-基于py2的mysqldb,在py3上重新了,但是名字改成了mysqlclient
-使用mysqlclient,只需要安装这个模块,不需要再写任何代码,直接用即可
-但是:mysqlclient 这个模块,不好装
-win 一般人品好,人品好,pip install mysqlclient
-人品不好,装不了,centos部署项目,后面会讲centos上如何装
# mysqlclient
pip install mysqlclient
###### 配置文件修改,连接mysql,使用路飞用户
# 用户名密码写死在代码中了,保证安全
name = os.environ.get('LUFFY_NAME', 'luffy')
password = os.environ.get('LUFFY_PASSWORD', 'Luffy123?')
# 拓展:有的公司,直接有个配置中心---》服务--》只用来存放配置文件
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'luffy',
'USER': name,
'PASSWORD': password,
'HOST': '127.0.0.1',
'PORT': 3306
}
}
2、User模块用户表
注意事项:
# 你决定使用auth表扩写,项目一定不要先迁移,先建好用户表再迁移
已经迁移完了,再想用auth的user表
-删库,删迁移文件所有app
-删admin和auth的迁移文件
操作代码:
# 配置继承auth表
AUTH_USER_MODEL = 'user.User'
# 用户表使用auth表扩写 pip install Pillow
class User(AbstractUser):
# 扩写手机号和头像字段
mobile = models.CharField(max_length=11, unique=True)
# 需要pillow包的支持
icon = models.ImageField(upload_to='icon', default='icon/default.png')
class Meta:
db_table = 'luffy_user'
verbose_name = '用户表'
verbose_name_plural = verbose_name
def __str__(self):
return self.username
3、开启media访问
配置文件:
# 配置文件加入
MEDIA_URL = '/media/'
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')
路由设置:
from django.contrib import admin
from django.urls import path, re_path
from django.views.static import serve
from django.conf import settings
urlpatterns = [
path('admin/', admin.site.urls),
# media路由
path('media/<path:path>', serve, {'document_root': settings.MEDIA_ROOT}),
# re_path(r'^media/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT}),
]
三、软件开发模式
介绍:
在对于一个优秀的软件开发团队来说,有效的管理开发项目,可以增强开发人员之间的协作,节省整个软件项目的开发时间,因此软件开发经理或开发团队在项目启动前,要选择一种最适合手头项目的软件开发模式,使整个团队拥有更好的工作效率,而目前主要的软件开发模式大致可以分为四种,对于软件项目来讲不同的开发模式都有各自的特点,至于哪一种的方法最合适自己,那就要看软件开发经理如何选择了。
1、瀑布开发模式
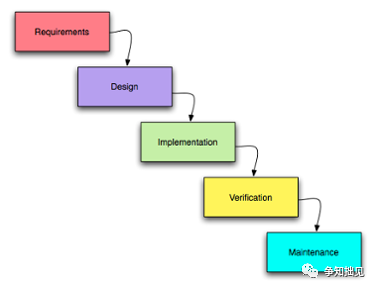
瀑布开发模式是一种传统的软件开发模式,瀑布法是一个刚性的线性模型,其中包括顺序阶段(需求,设计,实施,验证,维护),其中每一个阶段的目标性都很明确。而且在进入下一阶段之前,每个阶段目标必须100%地完成,但这种模式如果进行回溯修改时会比较麻烦。
但该方法的线性特性使其易于理解和管理。如果软件项目对稳定要求比较高,那可以选择这种开发模式。在使用瀑布开发模式时丰富的软件开发经验会比较有帮助。然而,由于刚性结构和严格的控制特点,通常会导致项目的开发时间比较慢、成本比较昂贵。
2、敏捷开发模式
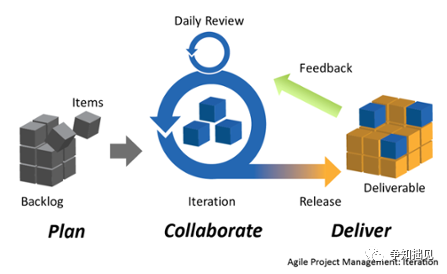
敏捷开发模式有许多不同的形式,包括:Scrum,Crystal,Extreme Programming(XP)和Feature-Driven Development(FDD)。它通过迭代开发,关注互动沟通等方法来降低软件开发过程中的风险,同时也可以减少在开发中的资源消耗。好处是通过早期发现和修复缺陷来提高开发的效率。但这种模式比较依赖用户的信息反馈,而且这种模式比较适用于小规模的软件开发公司,习惯于“瀑布法”的程序员,管理层和组织可能难以适应敏捷。
3、快速应用开发模式
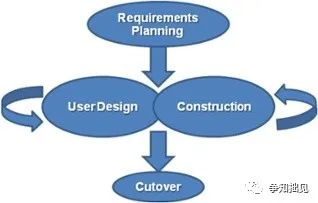
快速应用开发模式是一个比较精简的软件开发流程,可以以低投资成本生产高质量的软件。这种RAD流程可以使开发人员快速适应不断变化的市场需求。快速调整的能力可以帮助企业节省开发成本。快速应用程序开发模式分为四个阶段:需求规划,用户设计,构建和切换。重复用户设计和施工阶段,直到满足用户的所有要求。
RAD对于具有明确定义的业务目标及用户组的开发项目最有效,比较适用于一些中小型软件开发项目,或者是开发时间比较紧迫的软件项目。然而,它需要技术人员具有丰富开发经验,以及要非常了解用户的核心需求。
4、DevOps部署模式
DevOps部署模式增强了软件开发部门之间的协作,如开发,测试和运营。它着重于改进软件的上市时间,降低新版本的故障率,缩短BUG修复的交付时间,优先考虑最小的中断以及最大的可靠性等。
使用DevOps部署模式对提高客户满意度,提高产品质量,提高员工的生产力和效率得益(Efficiency Gain)等方面非常有用。但DevOps也有一些缺点:
有些客户不想持续更新他们的软件
一些行业在允许进入运营阶段之前,需要进行大量测试
不同部门使用的不同环境可能导致软件开发过程中一些问题不会显现出来
一些质量属性需要人为的相互作用,这会减慢软件的交付流程
四、Django配置文件介绍
from pathlib import Path
import sys
import os
# pathlib # 3.6 以后,处理文件路径的模块,原来是os,
BASE_DIR = Path(__file__).resolve().parent.parent
sys.path.append(os.path.join(BASE_DIR, 'apps'))
sys.path.insert(0, BASE_DIR)
# 项目密钥
SECRET_KEY = 'django-insecure-@3=-v&bd_o4hxy4)*v^r0y5d=27cg73)awt9zm1+v$2)$!kj6b'
# 开发模式,上线需要关闭
DEBUG = True
# 设置可以访问该服务器的地址 一般填入“*”
ALLOWED_HOSTS = []
# 注册app
INSTALLED_APPS = [
'django.contrib.admin', # django-admin
'django.contrib.auth', # django的auth模块
'django.contrib.contenttypes', # 存放表关系
'django.contrib.sessions', # sessions表
'django.contrib.messages', # messages:消息框架,flask讲闪现,是一样的东西
'django.contrib.staticfiles', # staticfiles:静态资源
'rest_framework',
'home',
'user'
]
# 中间件注册的地方
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware', # 安全相关中间件
'django.contrib.sessions.middleware.SessionMiddleware', # session相关中间件
'django.middleware.common.CommonMiddleware', # 处理路由带不带 / 问题
'django.middleware.csrf.CsrfViewMiddleware', # csrf 认证,生成csrf串
'django.contrib.auth.middleware.AuthenticationMiddleware', # 用户认证
'django.contrib.messages.middleware.MessageMiddleware', # 消息框架相关
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
# 总路由的存放地址
ROOT_URLCONF = 'luffy_api.urls'
# 模板文件(前后端分离用不到)
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [BASE_DIR / 'templates']
,
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
# 项目运行的配置---》项目上线运行,使用uwsgi 运行 application()
WSGI_APPLICATION = 'luffy_api.wsgi.application'
# 数据库相关,可填入多个数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
# 国际化相关配置
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_TZ = False
# 静态资源
STATIC_URL = 'static/'
# 修改了主键的字段属性(新版本)
DEFAULT_AUTO_FIELD = 'django.db.models.BigAutoField'
Luffy项目:2、项目需求(2),项目库的创建,软件开发目录,Django配置文件介绍的更多相关文章
- Python基础之模块:7、项目开发流程和项目需求分析及软件开发目录
一.项目开发流程 1.项目需求分析 明确项目具体功能: 明确到底要写什么东西,实现什么功能,在这个阶段的具体要询问项目经理和客户的需求 参与人员: 产品经理.架构师.开发经理 技术人员主要职责: 引导 ...
- 阶段5 3.微服务项目【学成在线】_day02 CMS前端开发_01-vuejs研究-vuejs介绍
1.vue.js是什么? Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计 为可以自底向上逐层应用.Vue 的核心库只关注视 ...
- 阶段5 3.微服务项目【学成在线】_day02 CMS前端开发_09-webpack研究-webpack介绍
使用vue.js开发大型应用需要使用webpack打包工具,本节研究webpack的使用方法. 1.3.1 webpack介绍 Webpack 是一个前端资源的打包工具,它可以将js.image.cs ...
- 研发团队管理:IT研发中项目和产品原来区别那么大,项目级的项目是项目,产品级的项目是产品!!!
前言 从事IT行业多年,一路从小杂兵成长为大团队Leader,对于研发整个体系比较清楚,其实大多人都经历过但是都忽略了的研发成本管控的一个关键的点就是研发过程中项目级和产品级的区别. 市场基本 ...
- 基于gulp编写的一个简单实用的前端开发环境好了,安装完Gulp后,接下来是你大展身手的时候了,在你自己的电脑上面随便哪个地方建一个目录,打开命令行,然后进入创建好的目录里面,开始撸代码,关于生成的json文件请点击这里https://docs.npmjs.com/files/package.json,打开的速度看你的网速了注意:以下是为了演示 ,我建的一个目录结构,你自己可以根据项目需求自己建目
自从Node.js出现以来,基于其的前端开发的工具框架也越来越多了,从Grunt到Gulp再到现在很火的WebPack,所有的这些新的东西的出现都极大的解放了我们在前端领域的开发,作为一个在前端领域里 ...
- 【项目 · Wonderland】需求规格说明书 · 终版
[项目 · Wonderland]需求规格说明书 · 终版 Part 0 · 简 要 目 录 Part 1 · 流 程 / 分 工 Part 2 · 需 求 规 格 说 明 书 Part 1 · 流 ...
- Luffy之虚拟环境.项目搭建,目录日志等配置信息
1. 项目开发前 1.1 虚拟环境virtualenv 如果在一台电脑上, 想开发多个不同的项目, 需要用到同一个包的不同版本, 如果使用上面的命令, 在同一个目录下安装或者更新, 新版本会覆盖以前的 ...
- Luffy之前端项目部署搭建
1. 搭建前端项目 1.1 创建项目目录 cd 项目目录 vue init webpack lufei 根据需要在生成项目时,我们选择对应的选项, 效果: 根据上面的提示,我们已经把vue项目构建好了 ...
- iOS开发项目之一 [ 项目流程]
项目流程 *人员配置 *客户端(iOS工程师,Android工程师) *前端 h5 *后台人员(php,java,net) *提供接口(请求地址.请求参数,请求方式,接口文档) *UI UE * 效果 ...
- [转]3天搞定的小型B/S内部管理类软件定制开发项目【软件开发实战10步骤详解】
本文转自:http://www.cnblogs.com/jirigala/archive/2010/10/07/1845275.html 2010-10-07 21:39 by 通用C#系统架构, 5 ...
随机推荐
- 【SQL进阶】【REPLACE/TIMESTAMPDIFF/TRUNCATE】Day01:增删改操作
一.插入记录 1.插入多条记录 自己的答案: INSERT INTO exam_record(uid, exam_id, start_time, submit_time, score) VALUES ...
- JavaScript入门⑧-事件总结大全
JavaScript入门系列目录 JavaScript入门①-基础知识筑基 JavaScript入门②-函数(1)基础{浅出} JavaScript入门③-函数(2)原理{深入}执行上下文 JavaS ...
- linux系统部署微服务项目
**:如果使用阿里云linux服务器 1.设置容器镜像服务 在阿里云平台搜索 "容器镜像服务" 选择"CentOS" 安装/升级Docker客户端 配置镜像加速 ...
- Jmeter 之在linux中监控Memory、CPU、I/O资源等操作方法
在做性能测试时,单纯的只看响应时间.错误率.中间值远远不够的,有时需要监控服务cpu.内存等指标来判断影响性能的瓶颈在哪. 操作步骤: 一.Linux下配置jmeter环境 1.在linux环境下安装 ...
- vue 项目引入 echarts折线图
一.components文件下新建 lineCharts.vue <template> <div :class="className" :style=" ...
- JavaScript:如何知道一个变量的数据类型?:typeof
使用typeof去查看一个变量的数据类型,如下图所示,展示了JS的七大基础数据类型和对象: 这里有必要提一下: 函数也是一个对象,但是函数的特殊性,使得在使用typeof去判断其类型的时候,会输出fu ...
- 真实世界的人工智能应用落地——OpenAI篇 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 本文地址:https://www.showmeai.tech/artic ...
- Auto-Job任务调度框架
Auto-Job 任务调度框架 一.背景 生活中,业务上我们会碰到很多有关作业调度的场景,如每周五十二点发放优惠券.或者每天凌晨进行缓存预热.亦或每月定期从第三方系统抽数等等,Spring和java目 ...
- C语言函数值传递问题
C语言函数间值传递问题 错误示例 #include <stdio.h> int * pop() { int a[3]; // 定义的局部变量a[3]在调用完之后自动释放其空间 int i ...
- gRPC入门与实操(.NET篇)
为什么选择 gRPC 历史 长久以来,我们在前后端交互时使用WebApi + JSON方式,后端服务之间调用同样如此(或者更久远之前的WCF + XML方式).WebApi + JSON 是优选的,很 ...