Kubernetes理论知识
一、k8s概念
Kubernetes(k8s)是跨主机集群的自动部署、扩展以及运行应用程序容器的开源平台,这些操作包括部署,调度和节点集群间扩展。
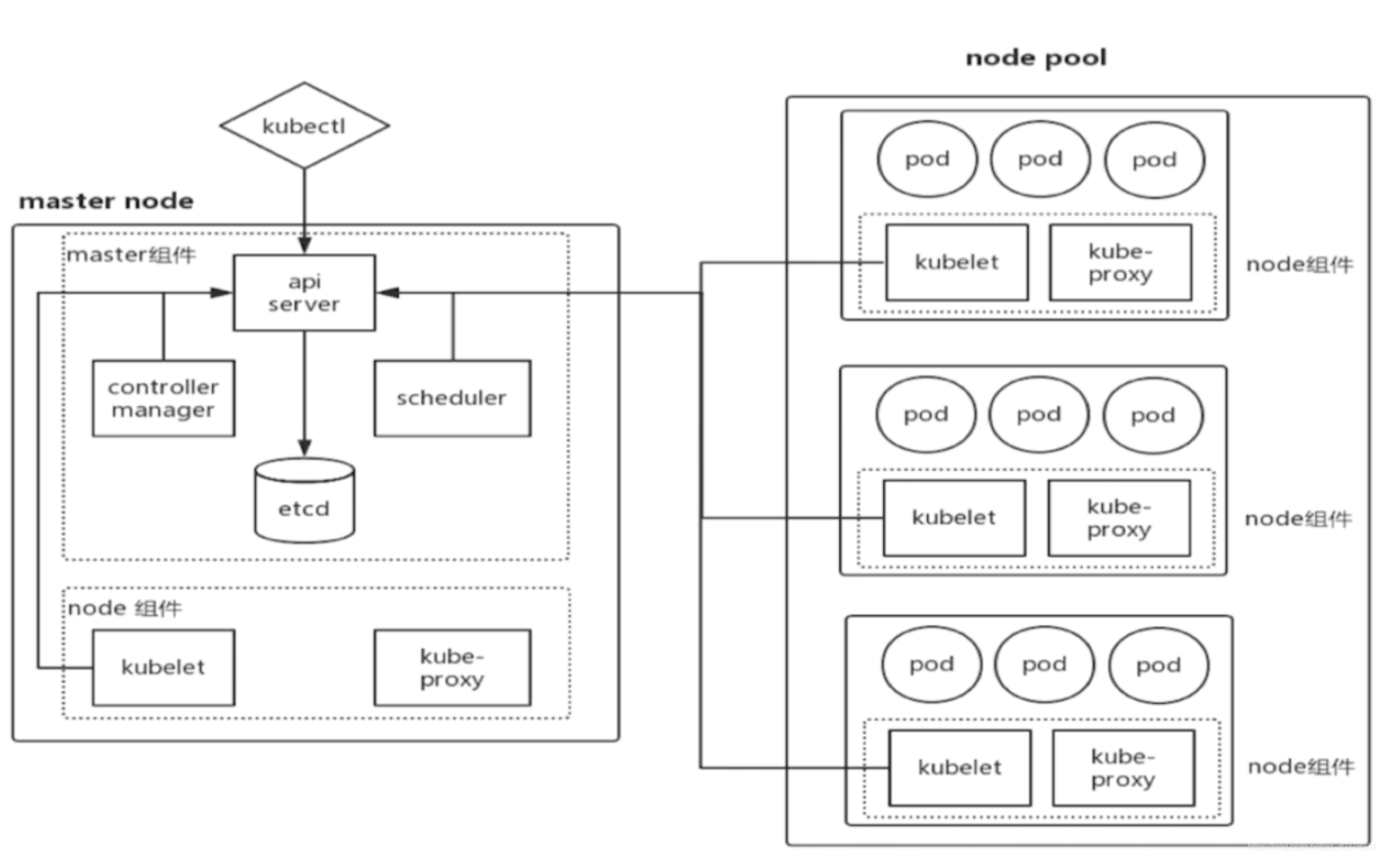
- master node:主节点
Master 是 Cluster 的大脑,它的主要职责是调度,集群中一般是多个master,实现高可用。
API Server:集群统一入口,以restful风格进行操作,同时交给etcd存储(是唯一能访问etcd的组件);提供认证、授权、访问控制、API注册和发现等机制,可以通过kubectl命令行工具,dashboard可视化面板,或者sdk等访问
Controller-Manager:K8S里所有资源对象的自动化控制中心,处理集群中常规后台任务,一个资源对应一个控制器,同时监控集群的状态,确保实际状态和最终状态一致
Scheduler:负责资源调度(Pod调度)的进程,通过API Server的Watch接口监听新建Pod副本信息,并通过调度算法为该Pod选择一个最合适的Node
etcd:K8S里的所有资源对象以及状态的数据都被保存在etcd中
- node:计算节点
Node 的职责是运行容器应用。Node 由 Master 管理,Node 负责监控并汇报容器的状态,并根据 Master 的要求管理容器的生命周期。Node 运行在 Linux 操作系统,可以是物理机或者是虚拟机。
kubelet:与Master节点协作,是主节点的代理,负责Pod对应容器的创建,启动,停止等任务。默认情况下Kubelet会向Master注册自己。Kubelet定期向主节点点汇报加入集群的Node的各类信息。
kube-proxy:实现Kubernetes Service的通信与负载均衡机制的重要组件
Pod:kubernetes中的核心组件,可以理解是一个容器,装的是 docker、rocket或者其他容器技术创建的容器,也就是用来封装容器的一个容器
Docker Engine:Docker引擎,负责本机的容器创建和管理工作
默认情况下,Kubelet会向Master注册自己,一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的信息(例如机器的CPU和内存情况以及有哪些Pod在运行等),这样Master就可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上报信息时,会被Master判定为失败,Node的状态被标记为不可用,随后Master会触发工作负载转移的自动流程
- Storage node:存储节点
不是必须的,但集群中一般有,用来搭建分布式存储集群,然后给k8s集群使用
Kubemetes也运行在每个Node上的kube-proxy进程其实就是一个智能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡与会话保持机制。但Kubernetes发明了一种很巧妙又影响深远的设计:Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个虚拟IP被称为ClusterIP。这样一来,每个服务就变成了具备唯一IP地址的“通信节点”,服务调用就变成了最基础的TCP网络通信问题。
二、核心组件
Pod
- pod 是一个虚拟化分组, 有自己的 IP 地址和主机名 hostname,利用 namespace 进行资源隔离,相当于一台独立沙箱环境;
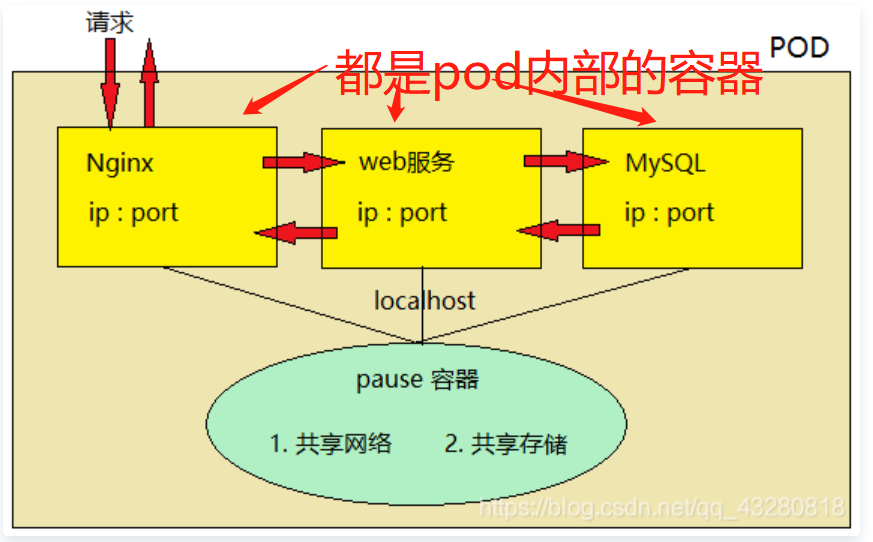
- pod 相当于一台独立主机,内部可以封装一个或多个用户业务容器(通常是一组相关的容器),同一个Pod里的容器共享同一个网络命名空间,可以使用localhost互相通信,相当于主机内本地访问
- 每个Pod都有一个特殊的被称为“根容器”的Pause容器,此容器与引入业务无关并且不易死亡,且以它的状态代表整个容器组的状态
- pod 内部容器创建之前,必须先创建 pause 容器。pause 有两个作用:共享网络和共享存储(Volume:支持NFS、分布式等多种存储方式)。
- 每个服务容器共享 pause 存储,不需要自己存储数据,都交给 pause维护。
- pause 也相当于这三个容器的网卡,因此他们之间的访问可以通过 localhost 方式访问,相当于访问本地服务一样,性能非常高(就像本地几台虚拟机之间可以 ping 通)
Pod有两种类型:普通的Pod及静态Pod(Static Pod)。后者并没被存放在K8S的etcd存储里,而是被存放在某个具体的Node上的一个具体文件中,并且只在此Node上启动、运行。而普通的Pod一旦被创建,就会被放入etcd中存储,随后会被K8S的Master调度到某个具体的Node上并进行绑定(Binding),随后该Pod被对应的Node上的kubelet进程实例化成一组相关的Docker容器并启动。在默认情况下,当Pod里的某个容器停止时,K8S会自动检测到这个问题并且重新启动这个Pod(重启Pod里的所有容器),如果Pod所在的Node宕机,就会将这个Node上的所有Pod重新调度到其他节点上
k8s 如果要进行扩容或缩容,只需要控制 pod 的数量即可。
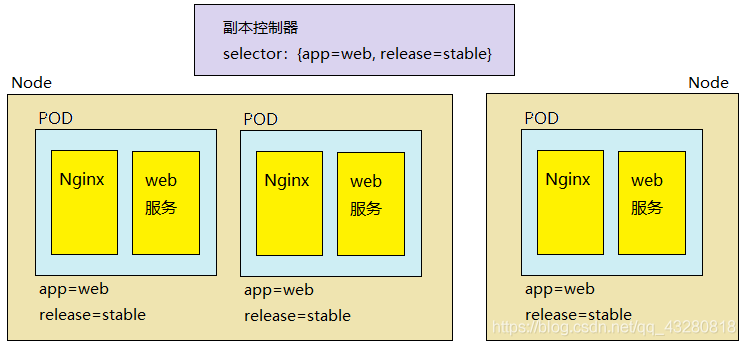
ReplicaSet
作用:管理控制 pod 副本(服务集群)的数量,以使其永远与预期设定的数量保持一致,kubectl edit rs frontend。
注意:删除ReplicaSet,不会影响该ReplicaSet已经创建好的Pod。在逻辑上Pod副本和ReplicaSet是解耦和的!创建ReplicaSet时,需要指定Pod模板(用来创建Pod副本的模板)和Label(RC需要监控的Pod标签)。
例如:replicas = 3 (创建 3 个副本,这是提前设置好的)
当副本设置为 3 时,副本控制器将会永远保证副本数量为 3。因此当有 pod 服务宕机时(如上面第 3 个 pod),那副本控制器会立马重新创建一个新的 pod,就能够保证副本数量一直为预先设定好的 3 个。

ReplicaSet 和 ReplicationController 的区别
ReplicaSet 和 ReplicationController (RC)都是副本控制器,其中:
- 相同点:都有前面 2.1 节所描述的功能
- 不同点:标签选择器的功能不同。ReplicaSet 可以使用标签选择器(Lable Selector)进行 单选 和 复合选择;而 ReplicationController 只支持 单选操作。
- 可见 ReplicaSet 功能更齐全,所以在新版的 k8s 中,建议使用 ReplicaSet 作为副本控制器,不再使用 ReplicationController
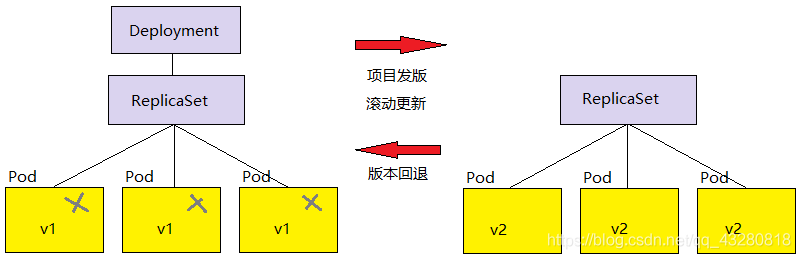
Deployment
ReplicaSet 副本控制器可以永久保持 pod 副本的数量,但是项目的需求在不断的迭代、
单独的 ReplicaSet 是不支持滚动更新的,Deployment 对象支持滚动更新,通常和 ReplicaSet 一起使用。
需要滚动更新时的步骤:
- Deployment 建立新的 Replicaset
- Replicaset 重新建立新的 pod
所以它们之间是有层次关系的,Deployment 管 Replicaset,Replicaset 维护 pod。在更新时删除的是旧的 pod,老版本的 ReplicaSet 是不会删除的,所以在需要时还可以回退以前的状态。
通过Deployment对象,你可以做到以下事情:
- 创建ReplicaSet和Pod
- 暂停和继续Deployment
- 滚动升级(不停止旧服务的状态下升级)和回滚应用(将应用回滚到之前的版本)
- 方式一:修改yaml文件,然后
kubectl apply - 方式二:使用
kubectl edit deploy修改镜像版本
- 方式一:修改yaml文件,然后
- 平滑地扩容和缩容
- 方式一:修改yaml文件,然后kubectl apply
- 方式二:使用kubectl edit deploy修改副本数
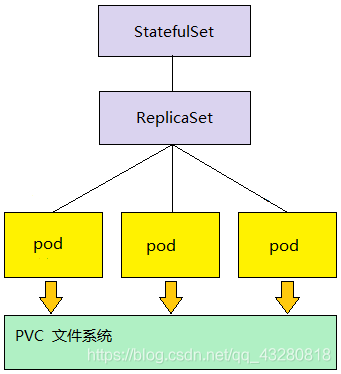
StatefulSet
如果要部署 MySQL(有状态服务) 使用容器化部署,会存在什么问题?
- 容器都是有生命周期的,一旦宕机数据就很可能丢失
- pod 也有生命周期的,用 pod 部署时把 pod 集群副本重启以后也可能会出现数据丢失
因此对 k8s 来说,不能使用 Deployment 部署有状态的服务。通常情况下,Deployment 被用来部署无状态服务。
然后 StatefulSet 就是为了解决有状态服务使用容器化部署的一个问题。
- 有状态服务
- 有实时的数据需要存储
- 在有状态服务集群中,如果把某一个服务抽离出来,一段时间后再加入回集群网络,此后集群网络会无法使用
- 无状态服务
- 没有实时的数据需要存储
- 在无状态服务集群中,如果把某一个服务抽离出去,一段时间后再加入回集群网络,对集群服务无任何影响,因为它们不需要做交互,不需要数据同步等等。
- 有状态服务
StatefulSet 的部署模型和 Deployment 的很相似。
比如下图,借助 PVC文件系统(一般是分布式集群存储系统)来存储的实时数据,因此下图就是一个有状态服务的部署。
在 pod 宕机之后重新建立 pod 时,StatefulSet 通过保证 hostname 不发生变化来保证数据不丢失。因此新的 pod 就可以通过之前的 hostname 来关联(找到) 之前存储的数据
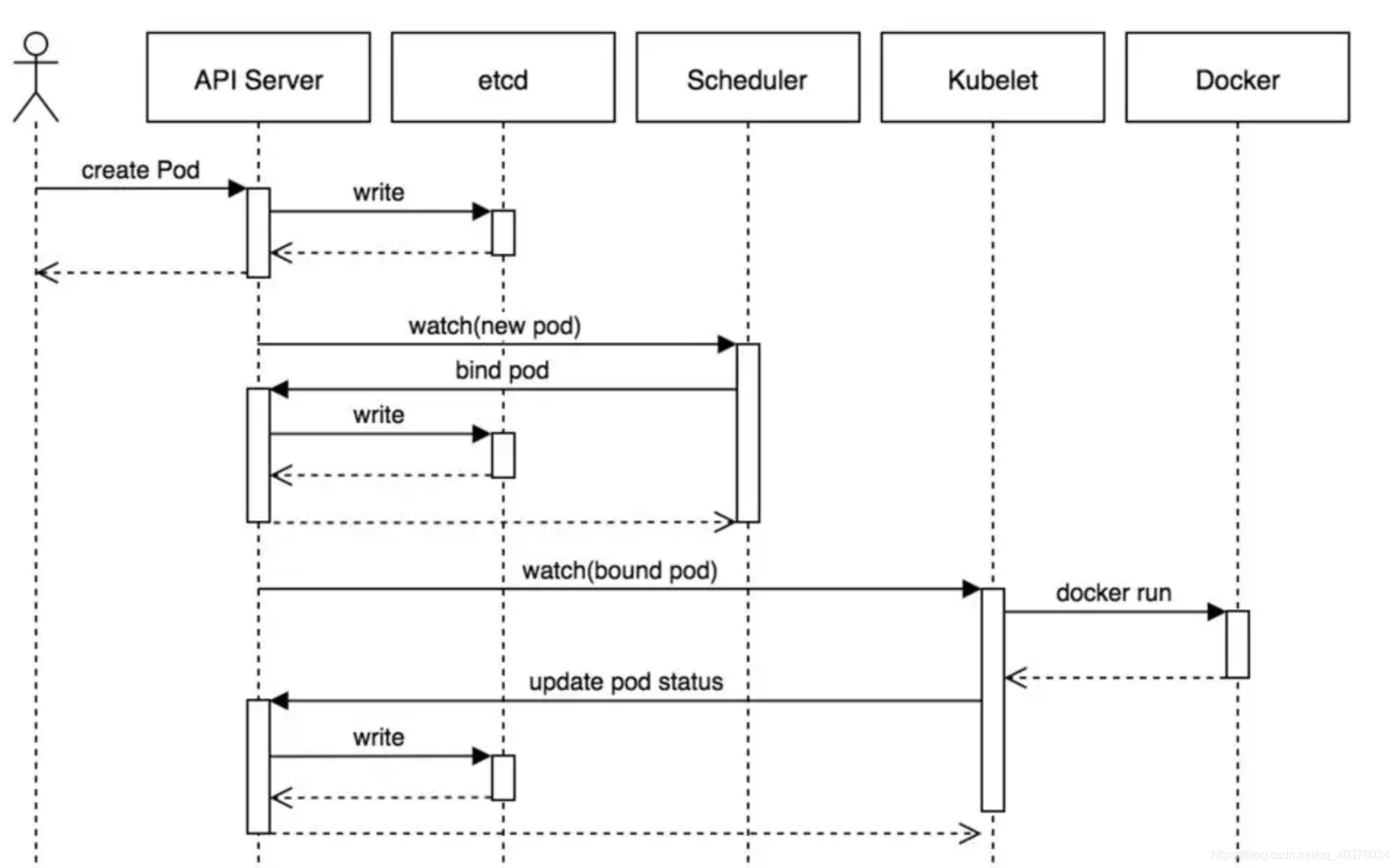
三、pod的创建过程
- 用户提交或者用Kubectl命令向API Server发送一个创建Pod的请求,可以通过API Server的REST API
- API Server处理用户请求,创建ReplicaSet,并将此请求的pod创建信息存储在etcd中
- Controller Manager会接受到一个通知,发现现在的集群状态和预期的状态不一致,根据配置信息将要创建的资源对象(pod)放到等待队列中
- Schedule通过API Server的watch机制,查看到等待队列中有新的Pod,尝试为Pod绑定Node
- Schedule进行预选调度和优选调度计算,找到最“闲”的且符合调度条件的node(例node2)。
- apiserver拿到调度结果(分配到node2),最后将pod.node=node2信息在etcd数据库中更新pod创建信息
- node2上的kubelet通过watch机制从apiserver获取etcd数据库信息,监听到kube-scheduler产生的Pod绑定事件后获取对应的Pod清单
- kubelet调用Docker(或者其他容器技术)创建容器
- 调用node2本机中的Docker根据kubelet需求初始化volume、分配IP、下载image镜像,创建容器并启动服务,并把容器的状态汇报给kubelet
- kubelet将Pod状态更新到apiserver,apiserver将状态信息写到etcd中
- 在这期间,Control Manager同时会根据K8S的mainfiles文件执行replicaset Pod的数量来保证指定的Pod副本数。而其他的组件,比如Scheduler负责Pod绑定的调度,从而完成整个Pod的创建
- 预选调度:一般根据资源对象的配置信息进行筛选。例如NodeSelector、HostSelector和节点亲和性等。
- 优选调度:根据资源对象需要的资源和node节点资源的使用情况,为每个节点打分,然后选出最优的节点创建资源对象(pod)
四、安装
k8s第二回之k8s集群的安装 - IT人生--MarkGuo - 博客园 (cnblogs.com)
五、k8s命令
Kubernetes理论知识的更多相关文章
- js中函数的一些理论知识
函数的一些理论知识 1. 函数: 执行一个明确的动作并提供一个返回值的独立代码块.同时函数也是javascript中的一级公民(就是函数和其它变量一样). 2.函数的 ...
- 用VC进行COM编程所必须掌握的理论知识
一.为什么要用COM 软件工程发展到今天,从一开始的结构化编程,到面向对象编程,再到现在的COM编程,目标只有一个,就是希望软件能象积方块一样是累起来的,是组装起来的,而不是一点点编出来的.结构化编程 ...
- 图形学理论知识 BRDF 双向反射分布函数(Bidirectional Reflectance Distribution Function)
图形学理论知识 BRDF 双向反射分布函数 Bidirectional Reflectance Distribution Function BRDF理论 BRDF表示的是双向反射分布函数(Bidire ...
- TestNG学习-001-基础理论知识
此 文主要讲述用 TestNG 的基础理论知识,TestNG 的特定,编写测试过程三步骤,与 JUnit4+ 的差异,以此使亲对 TestNG 测试框架能够有一个简单的认知. 希望能对初学 TestN ...
- [转] DDD领域驱动设计(三) 之 理论知识收集汇总
最近一直在学习领域驱动设计(DDD)的理论知识,从网上搜集了一些个人认为比较有价值的东西,贴出来和大家分享一下: 我一直觉得不要盲目相信权威,比如不能一谈起领域驱动设计,就一定认为国外的那个Eric ...
- Winsock网络编程笔记(4)----基本的理论知识
前面的笔记记录了Winsock的入门编程,领略了Winsock编程的乐趣..但这并不能算是掌握了Winsock,加深理论知识的理解才会让后续学习更加得心应手..因此,这篇笔记将记录一些有关Winsoc ...
- Android初级教程对大量数据的做分页处理理论知识
有时候要加载的数据上千条时,页面加载数据就会很慢(数据加载也属于耗时操作).因此就要考虑分页甚至分批显示.先介绍一些分页的理论知识.对于具体用在哪里,会在后续博客中更新. 分页信息 1,一共多少条数据 ...
- Android初级教程理论知识(第四章内容提供器)
之前第三章理论知识写到过数据库.数据库是在程序内部自己访问自己.而内容提供器是访问别的程序数据的,即跨程序共享数据.对访问的数据也无非就是CRUD. 内容提供者 应用的数据库是不允许其他应用访问的 内 ...
- 关于mpi的理论知识以及编写程序来实现数据积分中的梯形积分法。
几乎所有人的第一个程序是从“hello,world”程序开始学习的 #include "mpi.h" #include <stdio.h> int main(int a ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
随机推荐
- HNOI2019 最小圈
\(\text{Problem}\) 对于一张有向图,要你求图中最小圈的平均值最小是多少,即若一个圈经过 \(k\) 个节点,那么一个圈的平均值为圈上 \(k\) 条边权的和除以 \(k\),现要求其 ...
- 推荐系统[八]算法实践总结V1:淘宝逛逛and阿里飞猪个性化推荐:召回算法实践总结【冷启动召回、复购召回、用户行为召回等算法实战】
0.前言:召回排序流程策略算法简介 推荐可分为以下四个流程,分别是召回.粗排.精排以及重排: 召回是源头,在某种意义上决定着整个推荐的天花板: 粗排是初筛,一般不会上复杂模型: 精排是整个推荐环节的重 ...
- 分布式任务调度平台XXL-JOB安装
安装xxl-job-admin 1.拉取镜像 #拉取镜像 docker pull xuxueli/xxl-job-admin:2.3.0 #新建挂载目录 mkdir /usr/local/xxl-jo ...
- NSDT可编程3D场景
推荐:将 NSDT场景编辑器 加入你的3D开发工具链. NSDT编辑器简化了WebGL 3D应用的开发,完全兼容Three.JS生态.本文介绍如何在自己的应用中嵌入使用NSDT编辑器搭建的3D场景,并 ...
- 简述cpu、gpu、fpga和asic四种人工智能芯片的性能
https://fastonetech.com/newszblog/post/25570.html 简述cpu.gpu.fpga和asic四种人工智能芯片的性能FPGA(Field Programma ...
- 【C++复习】同名函数判断条件(重载,隐藏,覆盖)
1.重载 以下条件要全部满足: 函数名相同 以下条件满足其1: 函数形参数目不同 函数形参类型不同 注意: 不看返回值 调用形式要不同 //下面两个函数不能重载 fun(int a,int b){} ...
- html+css+js思维导图
- Vue ref属性
ref属性 1.被用来给元素或子组件注册引用信息(id的替代者) 2.应用在html标签上获取的是真实DOM元素: 应用在组件标签上是组件实例对象 vc 3.使用方法: (1)打标识:<h1 r ...
- VScode中文乱码问题
参考链接 https://blog.csdn.net/weixin_40040107/article/details/103721554?utm_medium=distribute.pc_releva ...
- Python算法教程_中文版书籍 程序员必备 免费下载
Python算法教程_中文版免费下载地址 提取码:55kh 内容简介 · · · · · · 本书用Python语言来讲解算法的分析和设计.本书主要关注经典的算法,但同时会为读者理解基本算法问题和解 ...