顺序、随机IO和Java多种读写文件性能对比
概述
对于磁盘的读写分为两种模式,顺序IO和随机IO。 随机IO存在一个寻址的过程,所以效率比较低。而顺序IO,相当于有一个物理索引,在读取的时候不需要寻找地址,效率很高。
基本流程
总体结构
我们编写的用户程序读写文件时必须经过的OS和硬件交互的内存模型
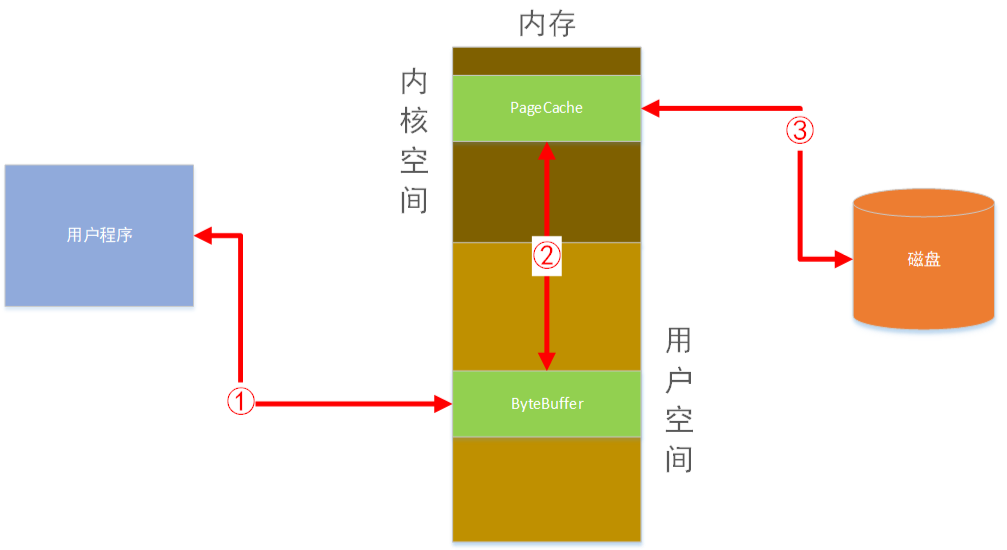
读文件
用户程序通过编程语言提供的读取文件api发起对某个文件读取。此时程序切换到内核态,用户程序处于阻塞状态。由于读取的内容还不在内核缓冲区中,导致触发OS缺页中断异常。然后由OS负责发起对磁盘文件的数据读取。读取到数据后,先存放在OS内核的主存空间,叫PageCache。然后OS再将数据拷贝一份至用户进程空间的主存ByteBuffer中。此时程序由内核态切换至用户态继续运行程序。程序将ByteBuffer中的内容读取到本地变量中,即完成文件数据读取工作。
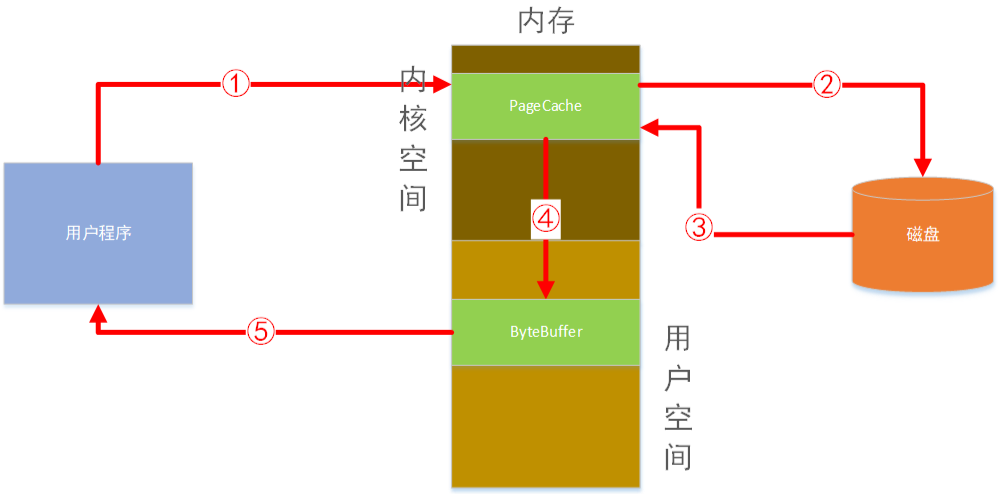
写文件
用户程序通过编程语言提供的写入文件api发起对某个文件写入磁盘。此时程序切换到内核态用户程序处于阻塞状态,由OS负责发起对磁盘文件的数据写入。用户写入数据后,并不是直接写到磁盘的,而是先写到ByteBuffer中,然后再提交到PageCache中。最后由操作系统决定何时写入磁盘。数据写入PageCache中后,此时程序由内核态切换至用户态继续运行。
用户程序将数据写入内核的PageCache缓冲区后,即认为写入成功了。程序由内核态切换回用于态,可以继续后续的工作了。PageCache中的数据最终写入磁盘是由操作系统异步提交至磁盘的。一般是定时或PageCache满了的时候写入。如果用户程序通过调用flush方法强制写入,则操作系统也会服从这个命令。立即将数据写入磁盘然后由内核态切换回用户态继续运行程序。但是这样做会损失性能,但可以确切的知道数据是否已经写入磁盘了。
详细流程
读文件
// 一次读多个字节
byte[] tempbytes = new byte[100];
int byteread = 0;
in = new FileInputStream(fileName);//①
ReadFromFile.showAvailableBytes(in);
// 读入多个字节到字节数组中,byteread为一次读入的字节数
while ((byteread = in.read(tempbytes)) != -1) { //②
System.out.write(tempbytes, 0, byteread);
}
首先通过位置①的代码发起一个open的系统调用,程序由用户态切换到内核态。操作系统通过文件全路径名在文件目录中找到目标文件名对应的文件iNode标识ID,然后用这个iNode标识ID在iNode索引文件找到目标文件iNode节点数据并加载到内核空间中。这个iNode节点包含了文件的各种属性(创建时间,大小以及磁盘块空间占用信息等等)。然后再由内核态切换回用户态,这样程序就获得了操作这个文件的文件描述。接下来就可以正式开始读取文件内容了。
然后再通位置②,循环数次获取固定大小的数据。通过发起read系统调用,操作系统通过文件iNode文件属性中的磁盘块空间占用信息得到文件起始位的磁盘物理地址。再从磁盘中将要取得数据拷贝到PageCache内核缓冲区。然后将数据拷贝至用户进程空间。程序由内核态切换回用户态,从而可以读取到数据,并放入上面代码中的临时变量tempbytes中。
操作系统通过iNode节点中的磁盘块占用信息去定位磁盘文件数据。其细节如下
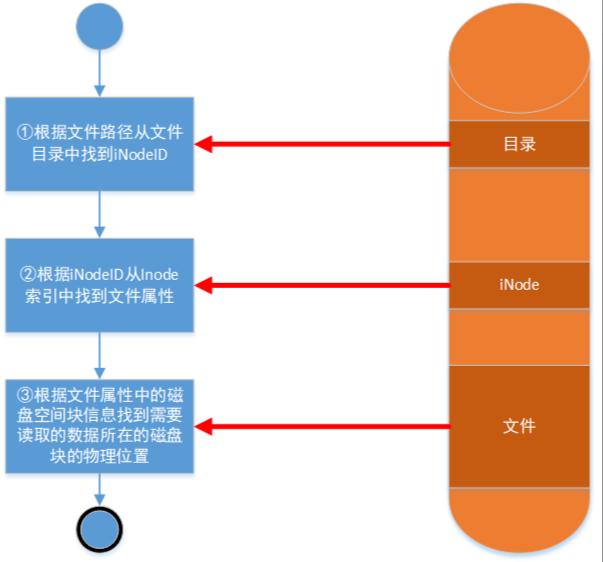
- ①根据文件路径从文件目录中找到iNode ID。
用户读取一个文件,首先需要调用OS中文件系统的open方法。该方法会返回一个文件描述符给用户程序。OS首先根据用户传过来的文件全路径名在目录索引数据结构中找到文件对应的iNode标识ID。目录数据是存在于磁盘上的,在OS初始化时就会加载到内存中,由于目录数据结构并不会很庞大,一次性加载驻留到内存也不是不可以或者部分加载,等需要的时候在从磁盘上调度进内存也可以。根据文件路径在目录中查找效率应该是很高的,因为目录本身就是一棵树,应该也是类似数据库的树形索引结构。所以它的查找算法时间复杂度就是O(logN)。具体细节我暂时还没弄清楚,这不是重点。
iNode就是文件属性索引数据了。磁盘格式化时OS就会把磁盘分区成iNode区和数据区。iNode节点就包含了文件的一些属性信息,比如文件大小、创建修改时间、作者等等。其中最重要的是还存有整个文件数据在磁盘上的分布情况(文件占用了哪些磁盘块)。
- ②根据iNode ID从Inode索引中找到文件属性。
得到iNode标识的ID后,就可以去iNode数据中查找到对应的文件属性了,并加载到内存,方便后续读写文件时快速获得磁盘定位。iNode数据结构应该类似哈希结构了,key就是iNode标识ID,value就是具体某个文件的属性数据对象了。所以它的算法时间复杂度就是O(1)。具体细节我暂时还没弄清楚,这不是重点。
我们系统中的文件它的文件属性(iNode)和它的数据正文是分开存储的。文件属性中有文件数据所在磁盘块的位置信息。
- ③根据文件属性中的磁盘空间块信息找到需要读取的数据所在的磁盘块的物理位置
文件属性也就是iNode节点这个数据结构,里面包含了文件正文数据在磁盘物理位置上的分布情况。磁盘读写都是以块为单位的。所以这个位置信息其实也就是一个指向磁盘块的物理地址指针。
理解认识
磁盘上文件存储数据结构是链表,每一块文件数据节点里有一个指针指向下一块数据节点。理解错误!
很多人都知道磁盘存储一个文件不可能是连续分配空间的。而是东一块西一块的存储在磁盘上的。就误以为这些分散的数据节点就像链表一样通过其中一个指针指向下一块数据节点。如下图所示。

怎么说呢?这种方案以前也是有一些文件系统实现过的方案,但是现在常见的磁盘文件系统都不再使用这种落后的方案。而是我前面提到的iNode节点方案。也就是说磁盘上存储的文件数据块就是纯数据,没有其他指针之类的额外信息。之所以我们能顺利定位这些数据块,都全靠iNode节点属性中磁盘块信息的指针。
append文件尾部追加方法是顺序写,也就是磁盘会分配连续的空间给文件存储。理解错误!
这种观点,包括网上和某些技术书籍里的作者都有这种观点。实际上是错误的。或许是他们根本没有细究文件存储底层OS和磁盘硬件的工作原理导致。我这里就重新总结纠正一下这种误导性观点。
前面说过,append系统调用是write的限制形式,即总是在文件末尾追加内容。看上去好像是说顺序写入文件数据,因为是在尾部追加啊!所以这样很容易误导大家以为这就是顺序写,即磁盘存储时分配连续的空间给到文件,减少了磁盘寻道时间。
事实上,磁盘从来都不会连续分配空间给哪个文件。这是我们现代文件系统的设计方案。前面介绍iNode知识时也给大家详细说明了。所以就不再赘述。我们用户程序写文件内容时,提交给OS的缓冲区PageCache后就返回了。实际这个内容存储在磁盘哪个位置是由OS决定的。OS会根据磁盘未分配空间索引表随机找一个空块把内容存储进去,然后更新文件iNode里的磁盘占用块索引数据。这样就完成了文件写入操作。所以append操作不是在磁盘上接着文件末尾内容所在块位置连续分配空间的。最多只能说逻辑上是顺序的。
mmap内存映射技术之所以快,是因为直接把磁盘文件映射到用户空间内存,不走内核态。理解错误
这也是一种常见的认知误区,实际上这个技术是操作系统给用户程序提供的一个系统调用函数。它把文件映射到OS内核缓冲区空间,同时共享给用户进程,也可以共享给多个用户进程。映射过程中不会产生实际的数据从磁盘真正调取动作,只有用户程序需要的时候才会调入部分数据。总之也是和普通文件读取一样按需调取。那么mmap技术为什么在读取数据时会比普通read操作快几个数量级呢?
上面我们讲述了普通读写操作的内存模型。用户程序要读取到磁盘上的数据。要经历4次内核态切换以及2次数据拷贝操作。那么mmap技术由于是和用户进程共享内核缓冲区,所以少了一次拷贝操作(数据从内核缓冲区到用户进程缓冲区)。从而大大提高了性能。
mmap内存映射技术写文件快是因为顺序写磁盘。理解错误!
上面的问题基本已经让我们理解了mmap技术的内存模型。同样的,我们写文件时,由于也少了一次数据从用户缓冲区到内核缓冲区的拷贝操作。使得我们的写效率非常的高。并不是很多人认为的数据直达磁盘,中间不经过内核态切换,并且连续在磁盘上分配空间写入。这些理解都是错误的。
随机读写文件比顺序读写文件慢,是因为磁盘移动磁头来回随机移动导致。理解错误!
这也是一种常见的误区。我看过很多文章都是这样认为的。其实所有的写操作在硬件磁盘层面上都是随机写。这是由现代操作系统的文件系统设计方案决定的。我们用户程序写入数据提交给OS缓冲区之后,就与我们没关系了。操作系统决定何时写入磁盘中的某个空闲块。所有的文件都不是连续分配的,都是以块为单位分散存储在磁盘上。原因也很简单,系统运行一段时间后,我们对文件的增删改会导致磁盘上数据无法连续,非常的分散。
当然OS提交PageCache中的写入数据时,也有一定的优化机制。它会让本次需要提交给磁盘的数据规划好磁头调度的策略,让写入成本最小化。这就是磁盘调度算法中的电梯算法了。这里就不深入讲解了。
至于读文件,顺序读也只是逻辑上的顺序,也就是按照当前文件的相对偏移量顺序读取,并非磁盘上连续空间读取。即便是seek系统调用方法随机定位读,理论上效率也是差不多的。都是使用iNode的磁盘占用块索引文件快速定位物理块。
测试对比
FileWriter和FileRead的封装类
package cn.itxs.filedemo;
import java.io.*;
public class RWHelper {
public static void fileWrite(String filePath, String content) {
File file = new File(filePath);
//创建FileWriter对象
FileWriter writer = null;
try {
//如果文件不存在,创建文件
if (!file.exists())
file.createNewFile();
writer = new FileWriter(file);
writer.write(content);//写入内容
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void fileRead(String filePath) {
File file = new File(filePath);
if (file.exists()) {
try {
//创建FileReader对象,读取文件中的内容
FileReader reader = new FileReader(file);
char[] ch = new char[1];
while (reader.read(ch) != -1) {
System.out.print(ch);
}
reader.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
FileOutputStream和FileInputStream封装类
package cn.itxs.filedemo;
import java.io.*;
import java.nio.charset.StandardCharsets;
public class StreamRWHelper {
public static void fileWrite(String filePath, String content) {
FileOutputStream outputStream = null;
try {
File file = new File(filePath);
boolean isCreate = file.createNewFile();//创建文件
if (isCreate) {
outputStream = new FileOutputStream(file);//形参里面可追加true参数,表示在原有文件末尾追加信息
outputStream.write(content.getBytes());
}else {
outputStream = new FileOutputStream(file,true);//表示在原有文件末尾追加信息
outputStream.write(content.getBytes());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void fileRead(String filePath) {
File file = new File(filePath);
if (file.exists()) {
try {
//创建FileInputStream对象,读取文件内容
FileInputStream fis = new FileInputStream(file);
byte[] bys = new byte[1024];
while (fis.read(bys, 0, bys.length) != -1) {
//将字节数组转换为字符串
System.out.print(new String(bys, StandardCharsets.UTF_8));
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
/**
* 文件合并
*/
// public static void mergeFile(List<String> inputPaths, String outputPath) throws FileNotFoundException {
//
// Vector<InputStream> inputStream = new Vector<InputStream>();
//
// if (CollectionUtils.isEmpty(inputPaths)) {
// throw new LogicException("合并文件路径不能为空");
// }
//
// for (String inputPath : inputPaths) {
// InputStream in = new FileInputStream(new File(inputPath));
// inputStream.add(in);
// }
//
// //构造一个合并流
// SequenceInputStream stream = new SequenceInputStream(inputStream.elements());
// BufferedOutputStream bos = null;
// try {
// bos = new BufferedOutputStream(
// new FileOutputStream(outputPath));
//
// byte[] bytes = new byte[10240];
// int len = -1;
// while((len=stream.read(bytes))!=-1){
// bos.write(bytes,0,len);
// bos.flush();
// }
// log.info("文件合并完成!");
// } catch (IOException e) {
// e.printStackTrace();
// }finally {
// try {
// if (null != bos ) {
// bos.close();
// }
// stream.close();
// } catch (IOException ignored) {
// }
// }
// }
}
BufferedWriter和BufferedReader封装类
package cn.itxs.filedemo;
import java.io.*;
public class BuffredRWHelper {
public static void fileWrite(String filePath, String content) {
File file = new File(filePath);
//创建FileWriter对象
BufferedWriter writer = null;
try {
//如果文件不存在,创建文件
if (!file.exists())
file.createNewFile();
writer = new BufferedWriter(new FileWriter(file));
writer.write(content);//写入内容
writer.flush();
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void fileRead(String filePath) {
File file = new File(filePath);
if (file.exists()) {
try {
//创建FileReader对象,读取文件中的内容
BufferedReader reader = new BufferedReader(new FileReader(file));
String line;
while ((line = reader.readLine()) != null) {
System.out.print(line);
}
reader.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
MappedByteBuffer读写封装类
package cn.itxs.filedemo;
import java.io.File;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class BigFileHelper {
public static long fileWrite(String filePath, String content, int index) {
File file = new File(filePath);
RandomAccessFile randomAccessTargetFile;
MappedByteBuffer map;
try {
randomAccessTargetFile = new RandomAccessFile(file, "rw");
FileChannel targetFileChannel = randomAccessTargetFile.getChannel();
map = targetFileChannel.map(FileChannel.MapMode.READ_WRITE, 0, (long) 1024 * 1024 * 240);
/**
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(content.length());
byteBuffer.put(content.getBytes());
byteBuffer.flip();
while (byteBuffer.hasRemaining()) {
targetFileChannel.write(byteBuffer);
}
//MappedByteBuffer再次获取内存中的内容,获取到的内容是woshihaoren
byte[] bytes = new byte[content.length()];
map.get(bytes);
System.out.println(new String(bytes));
**/
map.position(index);
map.put(content.getBytes());
return map.position();
} catch (IOException e) {
e.printStackTrace();
} finally {
}
return 0L;
}
// String woshihaoren = "woshihaoren";
// try (RandomAccessFile f = new RandomAccessFile("D:\\a.txt", "rw")) {
// FileChannel fc = f.getChannel();
// // 创建一个MappedByteBuffer,此时MappedByteBuffer获取到的内容都是空
// MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, woshihaoren.length());
// // 将字符串写入
// ByteBuffer byteBuffer = ByteBuffer.allocateDirect(woshihaoren.length());
// byteBuffer.put(woshihaoren.getBytes());
// byteBuffer.flip();
// while (byteBuffer.hasRemaining()) {
// fc.write(byteBuffer);
// }
//
// // MappedByteBuffer再次获取内存中的内容,获取到的内容是woshihaoren
// byte[] bytes = new byte[woshihaoren.length()];
// mbb.get(bytes);
// System.out.println(new String(bytes));
// } catch (Exception e) {
// e.printStackTrace();
// }
public static String fileRead(String filePath, long index) {
File file = new File(filePath);
RandomAccessFile randomAccessTargetFile;
MappedByteBuffer map;
try {
randomAccessTargetFile = new RandomAccessFile(file, "rw");
FileChannel targetFileChannel = randomAccessTargetFile.getChannel();
map = targetFileChannel.map(FileChannel.MapMode.READ_WRITE, 0, index);
byte[] byteArr = new byte[10 * 1024];
map.get(byteArr, 0, (int) index);
return new String(byteArr);
} catch (IOException e) {
e.printStackTrace();
} finally {
}
return "";
}
}
测试类
package cn.itxs.filedemo;
import java.util.Random;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
long start = System.currentTimeMillis();
System.out.println("start:"+start);
int count = Integer.parseInt(args[1]);
for (int i = 0; i < count; i++) {
System.out.println("file start:"+System.currentTimeMillis());
if (Integer.parseInt(args[0]) == 1) {
String bigFileName = args[2] + i + ".txt";
BigFileHelper.fileWrite(bigFileName,getFixStr(2000000),0);
}else if (Integer.parseInt(args[0]) == 2){
String commonFileName = args[2] + i + ".txt";
RWHelper.fileWrite(commonFileName,getFixStr(2000000));
}else {
System.exit(0);
}
System.out.println("file end:"+System.currentTimeMillis());
}
long end = System.currentTimeMillis();
System.out.println("end:"+end + ",time:" + (end-start));
}
public static String getRandomNumStr(long n) {
Random random = new Random();
StringBuilder randomStr = new StringBuilder();
for (long i = 0; i < n; i++) {
randomStr.append(random.nextInt(10));
}
return randomStr.toString();
}
public static String getFixStr(long n) {
Random random = new Random();
StringBuilder randomStr = new StringBuilder();
for (long i = 0; i < n; i++) {
randomStr.append("aaaasdfaaaaaaayyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyfffffaaaaaaaaaaaaaaasdfsdfsdfsdfsdfdafsdf");
}
return randomStr.toString();
}
}
普通写文件IO情况
内存映射写文件IO情况
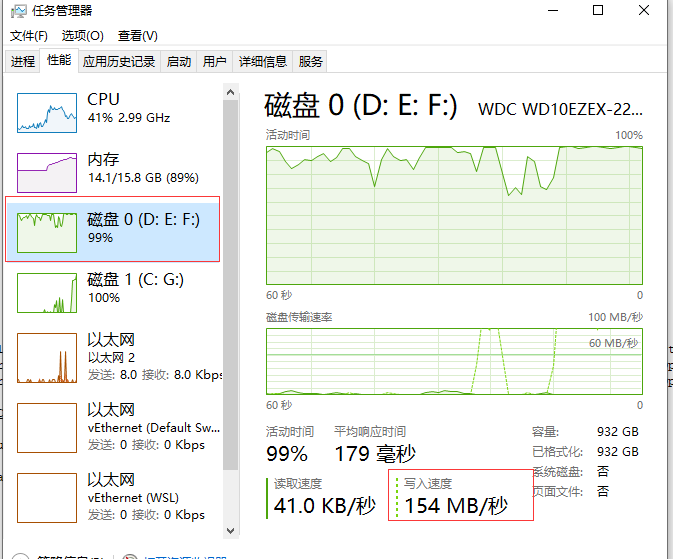
测试共100个230M文件约22G数据,普通写文件共耗时321726毫秒约332秒,内存映射共耗时129924毫秒约130秒,估计和磁盘类型有关。10个2.2G文件普通写文件16秒,内存映射10秒。
顺序、随机IO和Java多种读写文件性能对比的更多相关文章
- java StringBuffer读写文件
java StringBuffer读写文件 StringBuffer的优势 较String:String每更新一次就会new一个新的对象出来,更新次数上去之后,内存开销太大.而StringBuffer ...
- JAVA多线程读写文件范例
在写之前先声明,本文是基于之前在博客园网站上检索到的一份JAVA多线程读写文件的示例,我在写自己的程序时是在那位作者写的基础上做了改良,但已不记得原文的地址.如果有知情者,烦请帖出地址,我在此文上加入 ...
- SAE java应用读写文件(TmpFS和Storage)-----绝世好代码
近期不少java用户都在提sae读写本地文件的问题,在这里结合TmpFS和Storage服务说说java应用应该如何读写文件TmpFS是一个供应用临时读写的路径,但请求过后将被销毁.出于安全考虑,sa ...
- SAE java应用读写文件(TmpFS和Storage)
近期不少java用户都在提sae读写本地文件的问题,在这里结合TmpFS和Storage服务说说java应用应该如何读写文件TmpFS是一个供应用临时读写的路径,但请求过后将被销毁.出于安全考虑,sa ...
- Java基础--读写文件
Java读写文件需要注意异常的处理,下面是一个例子 写文件 public class WriteFile { public static void write(String file, String ...
- 【java】读写文件
不要吐槽我为啥不写try,catch. 默认的相对路径是在工作空间的目录下. 如图 import java.io.*; import java.util.*; public class filerw ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Java IO和Java NIO在文件拷贝上的性能差异分析
1. 在JAVA传统的IO系统中,读取磁盘文件数据的过程如下: 以FileInputStream类为例,该类有一个read(byte b[])方法,byte b[]是我们要存储读取到用户空间的缓冲区 ...
- JAVA字节流(读写文件)
InputStream此抽象类是表示字节输入流的所有类的超类.需要定义 InputStream 的子类的应用程序必须始终提供返回下一个输入字节的方法. int available()返回此输入流方法的 ...
随机推荐
- c#修改密码后实现重新登录
C#中密码修改成功后,提示"密码修改成功,请重新登录.当用户一点确定的时候就跳到登录界面 直接重启程序就是了,在弹出个Messages.show("密码修改成功,请重新登录.&qu ...
- Context包源码解析(附面经)
Context包源码解析 Context就相当于一个树状结构 最后请回答一下这个问题:context包中的方法是线程安全吗? Context包中主要有一个接口和三个结构体 Context接口 type ...
- 分布式边缘容器项目 SuperEdge v0.7.0 版本来袭!
作者 SuperEdge 开发者团队,腾讯云容器中心TKE Edge团队 摘要 SuperEdge是基于原生Kubernetes的分布式边缘云容器管理系统,由腾讯云牵头,联合英特尔.VMware威睿. ...
- 『德不孤』Pytest框架 — 12、Pytest中Fixture装饰器(二)
目录 5.addfinalizer关键字 6.带返回值的Fixture 7.Fixture实现参数化 (1)params参数的使用 (2)进阶使用 8.@pytest.mark.usefixtures ...
- oop简易封装增删改查
//注意要先引入含有封装类的文件文件:如下: <?phpclass Db{ public $host='127.0.0.1'; public $user='root'; public $pass ...
- centos7 安装 nginx-1.18.0 并设置开机自启动
一.到官网下载nginx Mainline version: nginx主力版本,为开发版 Stable version: 稳定版,在生产环境中选择此版本进行安装 Legacy versions: ...
- Linux指令_入门基础
一.基础指令语法 1.ls指令: 用法1:#ls 含义:列出当前工作目录下的所有文件/文件夹的名称. 用法2:#ls 路径 含义:列出指定路径下的所有文件/文件夹的名称 用法3:#ls 选项 路径 含 ...
- java 实现装饰器设计模式
package com.gylhaut.base; /** * 装饰器 * 类与类之间的关系 * 1.依赖:形参(局部变量) * 2.关联:属性 * 聚合 属性 整体和部分 不一致的生命周期 人和手 ...
- Linux常用性能诊断命令详解
top top命令动态地监视进程活动与系统负载等信息. 使用示例: top 效果如下图: 以上命令输出视图中分为两个区域,一个统计信息区,一个进程信息区. 统计信息区: 第一行信息依次为:系统时间.运 ...
- Java基础——继承的特点
继承的优点: 1.提高了代码的复用性(多个类相同的成员可以放到一个类中) 2.提高了代码的维护性(如果要修改方法,只需要修改父类中的即可) 继承的缺点: 1.继承让类与类产生了关系,类的耦合性增强了, ...