百度飞桨(PaddlePaddle)- 张量(Tensor)
飞桨 使用张量(Tensor) 来表示神经网络中传递的数据,Tensor 可以理解为多维数组,类似于 Numpy 数组(ndarray) 的概念。与 Numpy 数组相比,Tensor 除了支持运行在 CPU 上,还支持运行在 GPU 及各种 AI 芯片上,以实现计算加速;此外,飞桨基于 Tensor,实现了深度学习所必须的反向传播功能和多种多样的组网算子,从而可更快捷地实现深度学习组网与训练等功能。
Tensor 必须形如矩形,即在任何一个维度上,元素的数量必须相等,否则会抛出异常
Tensor 的创建
指定数据创建
import paddle
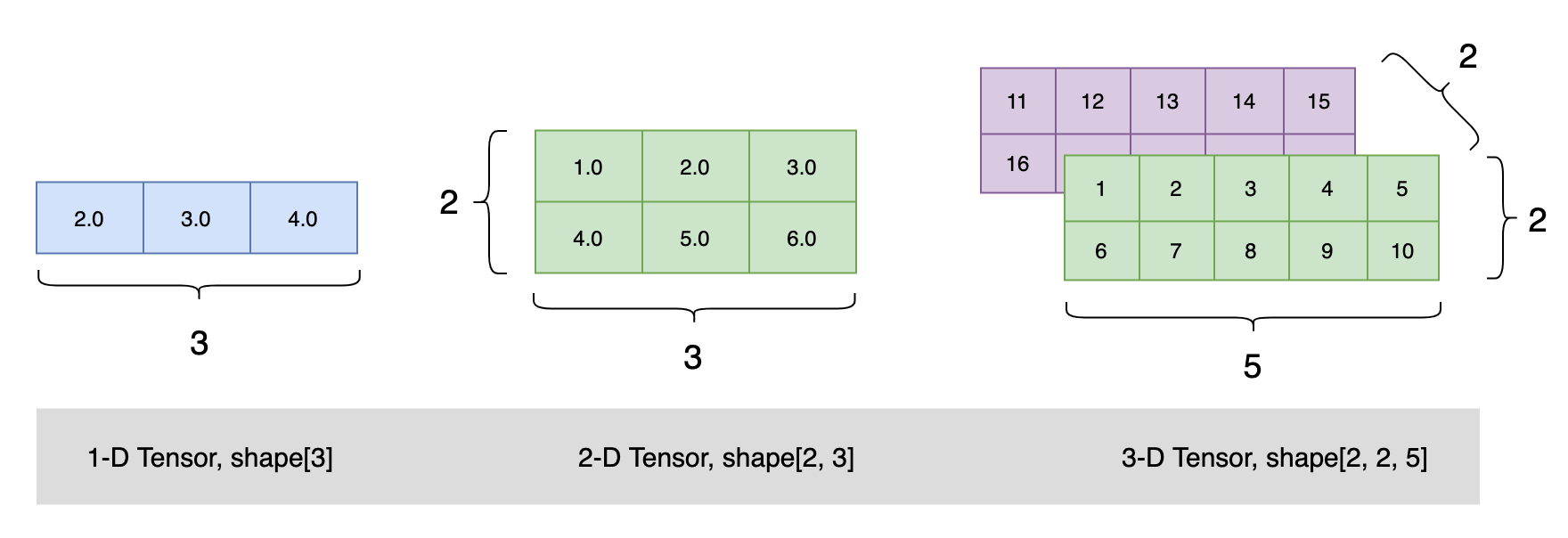
# 创建类似向量(vector)的 1 维 Tensor:
ndim_1_Tensor = paddle.to_tensor([2.0, 3.0, 4.0])
print(ndim_1_Tensor)
# 创建类似矩阵(matrix)的 2 维 Tensor:
ndim_2_Tensor = paddle.to_tensor([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]])
print(ndim_2_Tensor)
# 创建 3 维 Tensor:
ndim_3_Tensor = paddle.to_tensor([[[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10]],
[[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]]])
print(ndim_3_Tensor)
输出
"D:\Program Files\Python38\python.exe" D:/OpenSource/PaddlePaddle/Tensor.py
Tensor(shape=[3], dtype=float32, place=Place(cpu), stop_gradient=True,
[2., 3., 4.])
Tensor(shape=[2, 3], dtype=float32, place=Place(cpu), stop_gradient=True,
[[1., 2., 3.],
[4., 5., 6.]])
Tensor(shape=[2, 2, 5], dtype=int64, place=Place(cpu), stop_gradient=True,
[[[1 , 2 , 3 , 4 , 5 ],
[6 , 7 , 8 , 9 , 10]],
[[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20]]])
Process finished with exit code 0
指定形状创建
paddle.zeros([m, n]) # 创建数据全为 0,形状为 [m, n] 的 Tensor
paddle.ones([m, n]) # 创建数据全为 1,形状为 [m, n] 的 Tensor
paddle.full([m, n], 10) # 创建数据全为 10,形状为 [m, n] 的 Tensor
paddle.ones([2,3])
输出
Tensor(shape=[2, 3], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[1., 1., 1.],
[1., 1., 1.]])
指定区间创建
如果要在指定区间内创建 Tensor,可以使用paddle.arange、 paddle.linspace 实现。
paddle.arange(start, end, step) # 创建以步长 step 均匀分隔区间[start, end)的 Tensor
paddle.linspace(start, stop, num) # 创建以元素个数 num 均匀分隔区间[start, stop)的 Tensor
paddle.arange(start=1, end=5, step=1)
输出
Tensor(shape=[4], dtype=int64, place=Place(gpu:0), stop_gradient=True,
[1, 2, 3, 4])
指定图像、文本数据创建
在常见深度学习任务中,数据样本可能是图片(image)、文本(text)、语音(audio)等多种类型,在送入神经网络训练或推理前,这些数据和对应的标签均需要创建为 Tensor。以下是图像场景和 NLP 场景中手动转换 Tensor 方法的介绍。
- 对于图像场景,可使用 paddle.vision.transforms.ToTensor 直接将 PIL.Image 格式的数据转为 Tensor,使用 paddle.to_tensor 将图像的标签(Label,通常是 Python 或 Numpy 格式的数据)转为 Tensor。
- 对于文本场景,需将文本数据解码为数字后,再通过 paddle.to_tensor 转为 Tensor。不同文本任务标签形式不一样,有的任务标签也是文本,有的则是数字,均需最终通过 paddle.to_tensor 转为 Tensor。
下面以图像场景为例介绍,以下示例代码中将随机生成的图片转换为 Tensor。
import numpy as np
from PIL import Image
import paddle.vision.transforms as T
import paddle.vision.transforms.functional as F
fake_img = Image.fromarray((np.random.rand(224, 224, 3) * 255.).astype(np.uint8)) # 创建随机图片
transform = T.ToTensor()
tensor = transform(fake_img) # 使用 ToTensor()将图片转换为 Tensor
print(tensor)
自动创建 Tensor 的功能介绍
除了手动创建 Tensor 外,实际在飞桨框架中有一些 API 封装了 Tensor 创建的操作,从而无需用户手动创建 Tensor。例如 paddle.io.DataLoader 能够基于原始 Dataset,返回读取 Dataset 数据的迭代器,迭代器返回的数据中的每个元素都是一个 Tensor。另外在一些高层 API,如 paddle.Model.fit 、paddle.Model.predict ,如果传入的数据不是 Tensor,会自动转为 Tensor 再进行模型训练或推理。
paddle.Model.fit、paddle.Model.predict 等高层 API 支持传入 Dataset 或 DataLoader,如果传入的是 Dataset,那么会用 DataLoader 封装转为 Tensor 数据;如果传入的是 DataLoader,则直接从 DataLoader 迭代读取 Tensor 数据送入模型训练或推理。因此即使没有写将数据转为 Tensor 的代码,也能正常执行,提升了编程效率和容错性。
以下示例代码中,分别打印了原始数据集的数据,和送入 DataLoader 后返回的数据,可以看到数据结构由 Python list 转为了 Tensor。
import paddle
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print(test_dataset[0][1]) # 打印原始数据集的第一个数据的 label
loader = paddle.io.DataLoader(test_dataset)
for data in enumerate(loader):
x, label = data[1]
print(label) # 打印由 DataLoader 返回的迭代器中的第一个数据的 label
break
Tensor 的属性
在前文中,可以看到打印 Tensor 时有 shape、dtype、place 等信息,这些都是 Tensor 的重要属性,想要了解如何操作 Tensor 需要对其属性有一定了解,接下来分别展开介绍 Tensor 的属性相关概念。
Tensor(shape=[3], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[2., 3., 4.])
Tensor 的形状(shape)
(1)形状的介绍
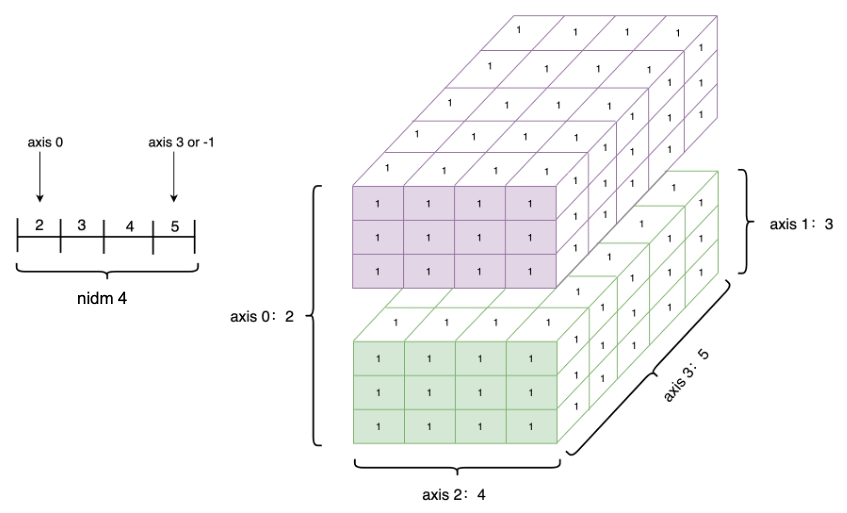
形状是 Tensor 的一个重要的基础属性,可以通过 Tensor.shape 查看一个 Tensor 的形状,以下为相关概念:
- shape:描述了 Tensor 每个维度上元素的数量。
- ndim: Tensor 的维度数量,例如向量的维度为 1,矩阵的维度为 2,Tensor 可以有任意数量的维度。
- axis 或者 dimension:Tensor 的轴,即某个特定的维度。
- size:Tensor 中全部元素的个数。
创建 1 个四维 Tensor ,并通过图形来直观表达以上几个概念之间的关系:
ndim_4_Tensor = paddle.ones([2, 3, 4, 5])
print("Data Type of every element:", ndim_4_Tensor.dtype)
print("Number of dimensions:", ndim_4_Tensor.ndim)
print("Shape of Tensor:", ndim_4_Tensor.shape)
print("Elements number along axis 0 of Tensor:", ndim_4_Tensor.shape[0])
print("Elements number along the last axis of Tensor:", ndim_4_Tensor.shape[-1])
(2)重置 Tensor 形状(Reshape) 的方法
重新设置 Tensor 的 shape 在深度学习任务中比较常见,如一些计算类 API 会对输入数据有特定的形状要求,这时可通过 paddle.reshape 接口来改变 Tensor 的 shape,但并不改变 Tensor 的 size 和其中的元素数据。
以下示例代码中,创建 1 个 shape=[3] 的一维 Tensor,使用 reshape 功能将该 Tensor 重置为 shape=[1, 3] 的二维 Tensor。这种做法经常用在把一维的标签(label)数据扩展为二维,由于飞桨框架中神经网络通常需要传入一个 batch 的数据进行计算,因此可将数据增加一个 batch 维,方便后面的数据计算。
ndim_1_Tensor = paddle.to_tensor([1, 2, 3])
print("the shape of ndim_1_Tensor:", ndim_1_Tensor.shape)
reshape_Tensor = paddle.reshape(ndim_1_Tensor, [1, 3])
print("After reshape:", reshape_Tensor.shape)
在指定新的 shape 时存在一些技巧:
- -1 表示这个维度的值是从 Tensor 的元素总数和剩余维度自动推断出来的。因此,有且只有一个维度可以被设置为 -1。
- 0 表示该维度的元素数量与原值相同,因此 shape 中 0 的索引值必须小于 Tensor 的维度(索引值从 0 开始计,如第 1 维的索引值是 0,第二维的索引值是 1)。
origin:[3, 2, 5] reshape:[3, 10] actual: [3, 10] # 直接指定目标 shape
origin:[3, 2, 5] reshape:[-1] actual: [30] # 转换为 1 维,维度根据元素总数推断出来是 3*2*5=30
origin:[3, 2, 5] reshape:[-1, 5] actual: [6, 5] # 转换为 2 维,固定一个维度 5,另一个维度根据元素总数推断出来是 30÷5=6
origin:[3, 2, 5] reshape:[0, -1] actual: [3, 6] # reshape:[0, -1]中 0 的索引值为 0,按照规则,转换后第 0 维的元素数量与原始 Tensor 第 0 维的元素数量相同,为 3;第 1 维的元素数量根据元素总值计算得出为 30÷3=10。
origin:[3, 2] reshape:[3, 1, 0] error: # reshape:[3, 1, 0]中 0 的索引值为 2,但原 Tensor 只有 2 维,无法找到与第 3 维对应的元素数量,因此出错。
(3)原位(Inplace)操作和非原位操作的区别
飞桨框架的 API 有原位(Inplace)操作和非原位操作之分,原位操作即在原 Tensor 上保存操作结果,输出 Tensor 将与输入 Tensor 共享数据,并且没有 Tensor 数据拷贝的过程。非原位操作则不会修改原 Tensor,而是返回一个新的 Tensor。通过 API 名称区分两者,如 paddle.reshape 是非原位操作,paddle.reshape_ 是原位操作。
Tensor 的数据类型(dtype)
(1)指定数据类型的介绍
Tensor 的数据类型 dtype 可以通过 Tensor.dtype 查看,支持类型包括:bool、float16、float32、float64、uint8、int8、int16、int32、int64、complex64、complex128。
同一 Tensor 中所有元素的数据类型均相同,通常通过如下方式指定:
(2)修改数据类型的方法
飞桨框架提供了paddle.cast 接口来改变 Tensor 的 dtype:
float32_Tensor = paddle.to_tensor(1.0)
float64_Tensor = paddle.cast(float32_Tensor, dtype='float64')
print("Tensor after cast to float64:", float64_Tensor.dtype)
int64_Tensor = paddle.cast(float32_Tensor, dtype='int64')
print("Tensor after cast to int64:", int64_Tensor.dtype)
Tensor 的设备位置(place)
Tensor 的名称(name)
Tensor 的 stop_gradient 属性
Tensor 的操作
索引和切片
索引或切片的第一个值对应第 0 维,第二个值对应第 1 维,依次类推,如果某个维度上未指定索引,则默认为 :
Python Numpy 切片
import paddle
# 创建 3 维 Tensor:
ndim_3_Tensor = paddle.to_tensor([[[[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]],
[[21, 22, 23, 24, 25],
[26, 27, 28, 29, 30],
[31, 32, 33, 34, 35]]],
[[[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]],
[[29, 22, 23, 24, 25],
[26, 57, 28, 29, 30],
[31, 32, 33, 34, 59]]]])
print("Origin Tensor:", ndim_3_Tensor.ndim)
print("Tensor Shape:", ndim_3_Tensor.shape) # [2, 2, 3, 5]
print("Slice:", ndim_3_Tensor[1, 1, 2, 4].numpy()) # 对应 shape
print("First row:", ndim_3_Tensor[0].numpy())
print("First row:", ndim_3_Tensor[1, 1, 2, 4].numpy())
print("First column:", ndim_3_Tensor[:, 0].numpy())
print("Last column:", ndim_3_Tensor[:, -1].numpy())
print("All element:", ndim_3_Tensor[:].numpy())
print("First row and second column:", ndim_3_Tensor[1, 0].numpy())
运算
Tensor 的广播机制
飞桨 Tensor 的广播机制
Python NumPy 广播(Broadcast)
百度飞桨(PaddlePaddle)- 张量(Tensor)的更多相关文章
- 提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件
提速1000倍,预测延迟少于1ms,百度飞桨发布基于ERNIE的语义理解开发套件 11月5日,在『WAVE Summit+』2019 深度学习开发者秋季峰会上,百度对外发布基于 ERNIE 的语义理解 ...
- 树莓派4B安装 百度飞桨paddlelite 做视频检测 (一、环境安装)
前言: 当前准备重新在树莓派4B8G 上面搭载训练模型进行识别检测,训练采用了百度飞桨的PaddleX再也不用为训练部署环境各种报错发愁了,推荐大家使用. 关于在树莓派4B上面paddlelite的文 ...
- Ubuntu 百度飞桨和 CUDA 的安装
Ubuntu 百度飞桨 和 CUDA 的安装 1.简介 本文主要是 Ubuntu 百度飞桨 和 CUDA 的安装 系统:Ubuntu 20.04 百度飞桨:2.2 为例 2.百度飞桨安装 访问百度飞桨 ...
- 百度飞桨数据处理 API 数据格式 HWC CHW 和 PIL 图像处理之间的关系
使用百度飞桨 API 例如:Resize Normalize,处理数据的时候. Resize:如果输入的图像是 PIL 读取的图像这个数据格式是 HWC ,Resize 就需要 HWC 格式的数据. ...
- 我做的百度飞桨PaddleOCR .NET调用库
我做的百度飞桨PaddleOCR .NET调用库 .NET Conf 2021中国我做了一次<.NET玩转计算机视觉OpenCV>的分享,其中提到了一个效果特别好的OCR识别引擎--百度飞 ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- 【一】ERNIE:飞桨开源开发套件,入门学习,看看行业顶尖持续学习语义理解框架,如何取得世界多个实战的SOTA效果?
参考文章: 深度剖析知识增强语义表示模型--ERNIE_财神Childe的博客-CSDN博客_ernie模型 ERNIE_ERNIE开源开发套件_飞桨 https://github.com/Pad ...
- tensorflow中张量(tensor)的属性——维数(阶)、形状和数据类型
tensorflow的命名来源于本身的运行原理,tensor(张量)意味着N维数组,flow(流)意味着基于数据流图的计算,所以tensorflow字面理解为张量从流图的一端流动到另一端的计算过程. ...
- 飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节.因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推 ...
- 张量 (tensor) 是什么?
对于大部分已经熟练的数学和物理工作者, 这实在是一个极为基础的问题. 但这个问题在我刚接触张量时也困扰了我很久. 张量的那么多定义, 究竟哪些是对的? (显然都是对的. ) 它们的关系是什么? 我尽可 ...
随机推荐
- 20181302编写myod.c 用myod XXX实现Linux下od -tx -tc XXX的功能
MyOD 一.任务详情 1 复习c文件处理内容 2 编写myod.c 用myod XXX实现Linux下od -tx -tc XXX的功能 3. main与其他分开,制作静态库和动态库 4. 编写Ma ...
- lua脚本概述
1.lua脚本非常简单,轻量级,易于c/c++调用 2. 协程 是什么,与线程有啥区别 ??
- 接口自动化之request几种常见请求及响应方法
request 的几种常见方法 1.request.get() 发送get请求 2.request.post() 发送post请求 3.request.delete() 发送delete请求 4.re ...
- scrcpy软件的使用
一.scrcpy软件介绍: scrcpy是通过adb调试的方式来将手机屏幕投到电脑上,并可以通过电脑控制您的Android设备.它可以通过USB连接,也可以通过Wifi连接(类似于隔空投屏),而且不需 ...
- Java 编程入门第一课:HelloWorld
在之前的文章中,壹哥带大家搭建出了 Java 的开发环境,配置了 JDK 环境变量,并且我们也熟悉了 dos 命令行的操作.那么从这篇文章开始,壹哥就开始带各位真正地学习 Java 代码该怎么写. - ...
- MyBatis 延迟加载代码详解
在我们的实际开发中,会面临各种各样的查询操作.如果单表查询能满足业务需求.尽量用单表查询,因为单表查询的效率比多表关联查询快. 那么当业务需求需要用到的数据来源于多张表的时候,单表查询无法解决,Myb ...
- 如何在 SpringBoot 项目中接入 ChartGPT
大家好,我是公子骏.最近体验了火爆全网的 ChartGPT,深刻体会了其强大的能力,这让我们程序猿对AI的未来突然有了广大的畅想空间. 我也在网上看到不少大牛通过 ChartGPT 来获取收益,就寻思 ...
- [ACM]Uva572-Oil Deposits-DFS应用
#include<iostream> #include<cstdio> #include<cstdlib> #include<cstring> usin ...
- Unity3D中的Attribute详解(五)
今天主要来讲一下Unity中带Menu的Attribute. 首先是AddComponentMenu.这是UnityEngine命名空间下的一个Attribute. 按照官方文档的说法,会在Compo ...
- Django笔记十四之统计总数、最新纪录和空值判断等功能
本篇笔记将介绍一些 Django 查询中统计总数.最新纪录和空值判断等功能. count in_bulk latest.earliest first.last exists contains.icon ...