这么强?!Erda MySQL Migrator:持续集成的数据库版本控制
为什么要进行数据库版本控制?
现代软件工程逐渐向持续集成、持续交付演进,软件一次性交付了事的场景逐渐无法满足复杂多变的业务需求,“如何高效地进行软件版本控制”成为我们面临的挑战。同时,软件也不是仅仅部署到某一套环境中,而是需要部署到开发、测试、生产以及更多的客户环境中,“如何一套代码适应不同的环境”也成为我们要思考的问题。
一套软件的副本要部署在不同的环境(图源:Flyway)
代码版本管理工具(Git、SVN 等)和托管平台(Github、Erda DevOps Platform 等)让我们能有效地进行代码版本管理。越来越丰富的 CI/CD 工具让我们能定义可重复的构建和持续集成流程,发布和部署变得简单清晰。
“基础设施即代码”的思想,让我们可以用代码定义基础设施,从而抹平了各个环境的差异。
可以说,在软件侧我们应对这些挑战已经得心应手。
但是绝大多数项目都至少包含两个重要部分:业务软件,以及业务软件所使用的数据库——许多项目数据库侧的版本控制仍面临乱局:
- 很多项目的数据库版本控制仍依赖于“人肉维护”,需要开发者手动执行 SQL;
- 环境一多,几乎没人搞得清某个环境上数据库是什么状态了;
- database migrations 脚本没有统一管理,遗失错漏时有发生;
- 不确定脚本的状态是否应用,也许在这个环境应用了但在另个环境却没有应用;
- 脚本里有一行破坏性代码,执行了后将一个表字段删除了,数据无法恢复,只能“从删库到跑路”;
- ……
为了应对这样的乱局,我们需要数据库版本控制工具。
数据库版本控制,即 Database Migration,它能帮你:
- 管理数据库的定义和迁移历程
- 在任意时刻和环境从头创建数据库至指定的版本
- 以确定性的、安全的方式执行迁移
- 清楚任意环境数据库处于什么状态
从而让数据库与软件的版本管理同步起来,软件版本始终能对应正确的数据库版本,同时提高安全性、降低维护成本。
Erda 如何实践数据库版本控制
Erda 是基于多云架构的一站式企业数字化平台,为企业提供 DevOps、微服务治理、多云管理以及快数据管理等云厂商无绑定的 IT 服务。Erda 既可以私有化交付,也提供了 SaaS 化云平台 Erda Cloud,以及开源的社区版。
当你正在阅读这篇文章时,有无数来自不同组织的应用程序正在 Erda Cloud 或 Erda 私有化平台的流水线上完成以构建和部署为核心的 CI/CD 流程,无数的代码,以这种持续而自动化的方式转化成服务实例。
Erda 平台不但接管了这些组织的应用程序的集成、交付,Erda 项目自身的集成也是托管在 Erda DevOps 平台的。Erda 自身的持续集成和丰富的交付场景要求它能进行安全、高效、可持续的数据库版本控制,托管在 Erda 上的应用程序也要求 Erda 提供一套完整的数据库版本控制方案。
Erda 项目使用 Erda MySQL Migrator 作为数据库版本控制工具,它被广泛应用于 CI/CD 流程和命令行工具中。
基本原理
第一次使用 Erda MySQL Migrator 进行数据库版本控制时会在数据库中新建一个名为 schema_migration_history 的表,如下如所示:

schema_migration_history 表的基本结构(部分主要字段)
Erda MySQL Migrator 每次执行 database migration 时,会对比文件系统中的 migrations 脚本和 schema_migration_history 表中的执行记录,标记出增量的部分。在一系列审查后,Erda MySQL Migrator 将增量的部分应用到目标 database 中。成功应用的脚本被记录在案。
Erda MySQL Migrator 命令行工具
erda-cli 工具的构建与安装
erda-cli 是 erda 项目命令行工具,它集成了 Erda 平台安装、Erda 拓展管理以及开发脚手架。其中 erda-cli migrate 命令集成了数据库版本控制全部功能。
从 erda 仓库 拉取代码到本地,切换到 master 分支,执行以下命令可以编译erda-cli :
% make prepare-cli
% make cli
注意编译前应确保当前环境已安装 docker。编译成功后项目目录下生成了一个 bin/erda-cli 可执行文件。
使用 erda-cli migrate 进行数据库版本迁移
Erda MySQL Migrator 要求按 modules/scripts 两级目录组织数据库版本迁移脚本,以 erda 仓库为例:
.erda/migrations
├── apim
│ ├── 20210528-apim-base.sql
│ ├── 20210709-01-add-api-example.py
│ └── requirements.txt
... ...
├── cmdb
│ ├── 20210528-cmdb-base.sql
│ ├── 20210610-addIssueSubscriber.sql
│ ├── 20210702-updateMbox.sql
│ └── 20210708-add-manageconfig.sql
└── config.yml
└── 20200528-tmc-base.sql
erda 项目将数据库迁移脚本放在 .erda/migrations 目录下,目录下一层级是按模块名(微服务名)命名的脚本目录,其各自下辖本模块所有脚本。与脚本目录同级的,还有一个 config.yml 的文件,它是 Erda MySQL Migration 规约配置文件,它描述了 migrations 脚本所需遵循的规约。
脚本目录下按文件名字符序排列着 migrations 脚本,目前支持 SQL 脚本和 Python 脚本。如果目录下存在 Python 脚本,则需要用 requirements.txt 来描述 Python 脚本的依赖。
进入 migrations 脚本所在目录 .erda/migrations,执行 erda-cli migrate :
% erda-cli migrate --mysql-host localhost \
--mysql-username root \
--mysql-password 123456789 \
--sandbox-port 3307 \
--database erda
INFO[0000] Erda Migrator is working
INFO[0000] DO ERDA MYSQL LINT....
INFO[0000] OK
INFO[0000] DO FILE NAMING LINT....
INFO[0000] OK
INFO[0000] DO ALTER PERMISSION LINT....
INFO[0000] OK
INFO[0000] DO INSTALLED CHANGES LINT....
INFO[0000] OK
INFO[0000] COPY CURRENT DATABASE STRUCTURE TO SANDBOX....
INFO[0014] OK
INFO[0014] DO MIGRATION IN SANDBOX....
INFO[0014] OK
INFO[0014] DO MIGRATION....
INFO[0014] module=apim
... ...
INFO[0014] module=cmdb
INFO[0014] OK
INFO[0014] Erda MySQL Migrate Success !
执行 erda-cli migrate 命令
从执行日志可以看到,命令行执行一系列检查以及沙盒预演后,成功应用了本次 database migration。我们可以登录数据库查看到脚本的应用情况。
mysql> SELECT service_name, filename FROM schema_migration_history;
+---------------+-------------------------------------------+
| service_name | filename |
+---------------+-------------------------------------------+
| apim | 20210528-apim-base.sql |
| apim | 20210709-01-add-api-example.py |
... ... ... ... ... ...
| cmdb | 20210528-cmdb-base.sql |
| cmdb | 20210610-addIssueSubscriber.sql |
| cmdb | 20210702-updateMbox.sql |
| cmdb | 20210708-add-manageconfig.sql |
+---------------+-------------------------------------------+
登录 MySQl Server 查看脚本应用情况
基于 Python 脚本的 data migration
从上一节我们看到,脚本目录中混合着 SQL 脚本和 Python 脚本,migrator 对它们一致地执行。Erda MySQL Migrator 在设计之初就决定了单脚本化的 migration,即一个脚本表示一次 migration 过程。大部分 database migration 都可以很好地用 SQL 脚本表达,但仍有些包含复杂逻辑的 data migration 用 SQL 表达则会比较困难。对这类包含复杂业务逻辑的 data migration,Erda MySQL Migrator 支持开发者使用 Python 脚本。
erda-cli 提供了一个命令行 erda-cli migrate mkpy 来帮助开发者创建一个基础的 Python 脚本。执行:
% erda-cli migrate mkpy --module my_module --name myfeature.py --tables blog,author,info
命令生成如下脚本:
"""
Generated by Erda Migrator.
Please implement the function entry, and add it to the list entries.
"""
import django.db.models
class Blog(django.db.models.Model):
name = models.CharField(max_length=100)
tagline = models.TextField()
class Meta:
db_table = "blog"
class Author(django.db.models.Model):
name = models.CharField(max_length=200)
email = models.EmailField()
class Meta:
db_table = "author"
class Info(django.db.models.Model):
blog = models.ForeignKey(Blog, on_delete=models.CASCADE)
headline = models.CharField(max_length=255)
body_text = models.TextField()
pub_date = models.DateField()
mod_date = models.DateField()
authors = models.ManyToManyField(Author)
number_of_comments = models.IntegerField()
number_of_pingbacks = models.IntegerField()
rating = models.IntegerField()
class Meta:
db_table = "info"
def entry():
"""
please implement this and add it to the list entries
"""
pass
entries: [callable] = [
entry,
]
该脚本可以分为四个部分:
- import 导入必要的包。脚本中采用继承了 django.db.models.Model 的类来定义库表,因此需要导入 django.db.model 库。开发者可以根据实际情况导入自己所需的包,但由于单脚本提交的原则,脚本中不应当导入本地其他文件。
- 模型定义。脚本中
class Blog、class Author和class Entry是命令行工具为开发者生成的模型类。开发者可以使用命令行参数--tables指定要生成哪些模型定义,以便在开发中引用它们。注意,生成这些模型定义类时并没有连接数据库,而是根据文件系统下过往的 migration 所表达的 Schema 生成。生成的模型定义只表示了表结构而不包含表关系,如“一对一”、“一对多”、“多对多”等。如果开发者要使用关联查询,应当编辑模型,自行完成模型关系的描述。Django ORM 的模型关系仅表示逻辑层面的关系,与数据库物理层的关系无关。 - entry 函数。命令行为开发者生成了一个名为
entry的函数,但是没有任何函数体,开发者需要自行实现该函数体以进行 data migration。 - entries,一个以函数为元素的列表,是程序执行的入口。开发者要将实现 data migration 的业务函数放到这里,只有 entries 中列举的函数才会被执行。
从以上脚本结构可以看到,我们选用的 Django ORM 来描述模型和进行 CRUD 操作。
为什么采用 Django ORM 呢?
因为 Django 是 Python 语言里最流行的 web 框架之一,Django ORM 也是 Python 中最流行的 ORM 之一,其设计完善、易用、便于二次开发,且有详尽的文档、丰富的学习材料以及活跃的社区。无论是 Go 开发者还是 Java 开发者,都能在掌握一定的 Python 基础后快速上手该 ORM。我们通过两个简单的例子来了解下如何利用 Django ORM 来进行 CRUD 操作。
示例 1 创建一条新记录。
# 示例 1
# 创建一条记录
def create_a_blog():
blog = Blog()
blog.name = "this is my first blog"
blog.tagline = "this is looong text"
blog.save()
Django ORM 创建一条记录十分简单,引用模型类的实例,填写字段的值,调用 save()方法即可。
示例 2 删除所有标题中包含 "Lennon" 的 Blog 条目。
Django 提供了一种强大而直观的方式来“追踪”查询中的关系,在幕后自动处理 SQL JOIN 关系。它允许你跨模型使用关联字段名,字段名由双下划线分割,直到拿到想要的字段。
# 示例 2
# 删除所有标题中含有 'Lennon' 的 Blog 条目:
def delete_blogs_with_headline_lennon():
Blog.objects.filter(info__headline__contains='Lennon').delete()
最后,别忘了将这两个函数放到 entries 列表中,不然它们不会被执行。
entries: [callable] = [
create_a_blog,
delete_blogs_with_headline_lennon,
]
可以看到,编写基于 Python 的 data migration 是十分方便的。erda-cli migrate mkpy 命令行为开发者生成了模型定义,引用模型类及其实例可以便捷地操作数据变更,开发只须关心编写函数中的业务逻辑。
想要进一步了解 Django ORM 的使用请查看文档:
在 CI/CD 时进行数据库版本控制
每日凌晨,Erda 上的一条流水线静静启动,erda 仓库的主干分支代码都会被集成、构建、部署到集成测试环境。开发者一早打开电脑,登录集成测试环境的 Erda 平台验证昨日集成的新 feature 是否正确,发现昨天新合并的 migrations 也一并应用到了集成测试环境。这是怎么做到的呢 ?
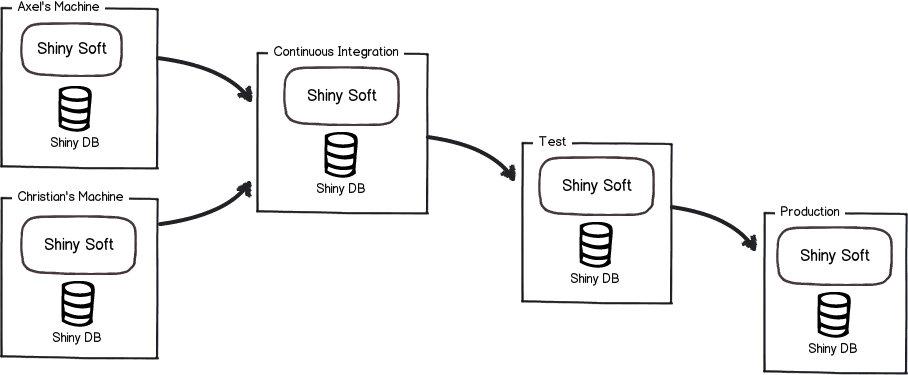
Erda 每日自动化集成流水线(部分步骤)
原来这条流水线每日凌晨拉取 erda 仓库主干分支代码 -> 构建应用 -> 将构建产物制成部署制品 -> 在集成测试环境执行 Erda MySQL 数据迁移 -> 将制品部署到集成测试环境。流水线中的 Erda MySQL 数据迁移 节点是集成了 Erda MySQL Migrator 全部功能的 Action,是 Erda MySQL Migrator 在 Erda CI/CD 流水线中的应用。
Erda MySQL Migrator 除了可以作为 Action 编排在流水线中,还可以脱离 Erda 平台作为命令行工具单独使用。
Erda MySQL Migrator 其他特性
规约检查
成熟的团队一般都会制定代码开发规约。Erda MySQL Migrator 支持开发者团队通过配置规约文件,来约定 SQL 脚本规范,如启用和禁用特定的 SQL 语句、约束表名与字段名格式、约束字段类型等。
比如要求 id 字段必须是 varchar(36) 或 char(36),可以添加如下配置:
- name: ColumnTypeLinter
meta:
columnName: id
types:
- type: varchar
flen: 36
- type: char
flen: 36
比如要求表名必须以 "erda_" 开头,可以添加如下配置:
- name: TableNameLinter
alias: "TableNameLinter: 以 erda_ 开头仅包含小写英文字母数字下划线"
white:
committedAt:
- "<20220215" ## 此处表示对提交时间早于2022年2月5日的文件不作此条规约要求
meta:
patterns:
- "^erda_[a-z0-9_]{1,59}"
关于如何编写规约配置文件的更新信息见链接:
https://github.com/erda-project/erda-actions/tree/master/actions/erda-mysql-migration/1.0-57#规约配置
使用命令行工具进行规约检查
erda-cli migrate lint 命令可以检查指定目录下所有脚本的 SQL 语句是否符合规约。开发者在编写 migration 时用该命令来预先检查,避免提交不合规了不合规的脚本。
例如开发者在 SQL 脚本中编写了如下语句:
alter table dice_api_assets add column col_name varchar(255);
执行规约检查:
% erda-cli migrate lint
2021/07/19 17:39:43 Erda MySQL Lint the input file or directory: .
apim/20210715-01-feature.sql:
dice_api_assets:
- 'missing necessary column definition option: COMMENT'
- 'missing necessary column definition option: NOT NULL'
apim/20210715-01-feature.sql [lints]
apim/20210715-01-feature.sql:1: missing necessary column definition option: COMMENT:
~~~> alter table dice_api_assets add column col_name varchar(255);
apim/20210715-01-feature.sql:1: missing necessary column definition option: NOT NULL:
~~~> alter table dice_api_assets add column col_name varchar(255);
使用命令行工具进行本地规约检查
可以看到命令行返回了检查报告,指出了某个文件中存在不合规的语句,并指出了具体的文件、行号、错误原因等信息。上面示例中指出了这条语句有两条不合规处:一是新增列时,应当有列注释,此处缺失;二是新增的列应当是 NOT NULL 的,此处没有指定。
使用 CI 工具进行规约检查
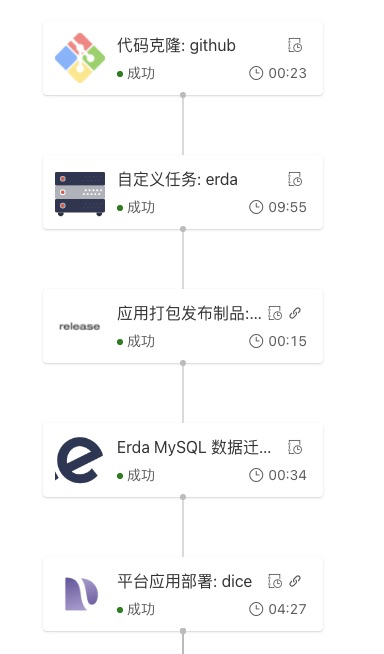
开发者自行使用命令行工具自检是合规检查的第一道关卡。在提交的代码合并到 erda 仓库主干分支前,PR 触发的 CI 流程会利用命令行工具检查 migrations 合规性则是第二道关卡。当提交包含不合规的 SQL 的 PR 时,CI 就会失败:
Github CI:Erda MySQL Lint 失败提示
使用 Erda MySQL Migration Lint Action 进行规约检查
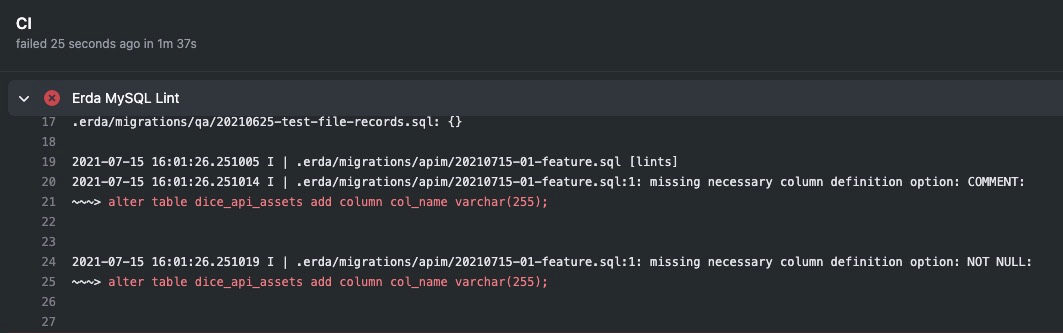
对于托管在 Erda DevOps 平台的项目,可以使用 Erda MySQL Migration Lint Action 进行规约检查。前文中的 Erda MySQL 数据迁移 Action 已经包含了规约检查功能,所以从功能上来说,Erda MySQL Migration Lint Action 可以看做 Erda MySQL 数据迁移 Action 的一部分。下图是使用 Erda MySQL Migration Lint Action 编排的流水线检查脚本合规性的示例。
使用 Erda MySQL Migration Lint Action 编排流水线检查脚本合规性
示例中该 Action 失败,打开 Action 日志可以查看具体失败原因。
沙盒与 Dryrun
引入沙盒是为了在将 migrations 应用到目标数据库前进行一次模拟预演,期望将问题的发现提前,防止将问题 migration 应用到了目标数据库中。对 Erda 这样的有丰富的交付场景的项目而言,在 migrate 前先进行一道预演是十分有意义的。这是 Erda MySQL Migrator 根据自身实际设计的,是 Flyway 等工具所不具备的。
Erda MySQL Migrator 可以配置仅在沙盒中而不在真实的 MySQL Server 中执行执行 migration,从而达到 Dryrun 的目的。
文件篡改检查与修订机制
Erda MySQL Migrator 不允许篡改已应用过的文件。之所以这样设计是因为一旦修改了已应用过的脚本,那么代码与真实数据库状态就不一致了。如果要修改表结构,应当增量地提交新的 migrations。这是一种常见的做法,Flyway 等工具也会对已执行的文件进行检查。
但实际生产中,“绝不修改过往文件”这种理想状态很难达到,Erda MySQL Migrator 提供了一种修订机制。当用户想修改一个文件名为“some-feature.sql”过往文件时,他应该修改该文件,并提交一个名为“patch-some-feature.sql”的包含了修改内容的文件到 .patch 目录中。
日志收集
Erda MySQL Migrator 在 debug 模式下,会打印所有执行执行过程和 SQL 的标准输出。除此之外,它还可以将纯 SQL 输出到指定目录的日志文件中。
获取工具
erda-cli 下载地址
Mac
http://erda-release.oss-cn-hangzhou.aliyuncs.com/cli/mac/erda-cli
Linux
http://erda-release.oss-cn-hangzhou.aliyuncs.com/cli/linux/erda-cli
注意:以上 erda-cli 仅用于 amd64 平台,其他平台请按文中介绍的安装方式自行构建。
源码地址
Erda MySQL MIgrator Action 源码地址
https://github.com/erda-project/erda-actions/tree/master/actions/erda-mysql-migration/1.0-57
这么强?!Erda MySQL Migrator:持续集成的数据库版本控制的更多相关文章
- 持续集成环境Jenkins的搭建和使用
这几天试着搭了个持续集成环境,我使用的是Jenkins,它的前身是Hadson,由于被Oracle收购了,所以换个名字继续开源,这个有点像MySQL. 持续集成总是跟敏捷开发什么的搞在一起,显得非常高 ...
- 入门系列之在Ubuntu上安装Drone持续集成环境
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由小铁匠米兰的v 发表于云+社区专栏 介绍 Drone是一个流行的持续集成和交付平台.它集成了许多流行的版本控制存储库服务,如GitHu ...
- Jenkins+Maven+SVN快速搭建持续集成环境
http://www.cnblogs.com/sunzhenchao/archive/2013/01/30/2883289.htmlhttp://blog.csdn.net/pein_zero/art ...
- (转载)持续集成(第二版)[来自:Martin Fowler]
转载自:iTech的博客 持续集成(第二版) 作者:Martin Fowler 译者:雷镇 持续集成 是一种软件开发实践.在持续集成中,团队成员频繁集成他们的工作成果,一般每人每天至少集成一次,也可以 ...
- 使用 flow.ci 实现 Android 自动化测试与持续集成
在上篇文章--如何实现 Android 应用的持续部署中,我们使用的是 flow.ci + Github + fir.im 实现 Android 应用的持续部署.对于 Android 开发者,他们可能 ...
- flow.ci + Github + Slack 一步步搭建 Python 自动化持续集成
理想的程序员必须懒惰,永远追随自动化法则.Automating shapes smarter future. 在一个 Python 项目的开发过程中可能会做的事情:编译.手动或自动化测试.部署环境配置 ...
- 基于 flow.ci 实现 PHP 项目自动化持续集成
高效程序员的习惯之一--让开发流程自动化.Automating shapes smarter future. 这是一个关于如何快速实现 PHP 项目自动化持续集成的快速指导.无论你是否使用过持续集成, ...
- 3 分钟轻松搭建 Ruby 项目自动化持续集成
任何事情超过 90 秒就应该自动化,这是程序员的终极打开方式.Automating shapes smarter future. 这是一篇关于 Ruby 项目持续集成的快速指导教程,教大家如何使用 f ...
- 8 步搭建 Node.js + MongoDB 项目的自动化持续集成
任何事情超过 90 秒就应该自动化,这是程序员的终极打开方式.Automating shapes smarter future. 这篇文章中,我们通过创建一个 Node.js + MongoDB 项目 ...
随机推荐
- Django/SQL server 配置实现(附下载安装)
连接方案1: conn = pymssql.connect(host='127.0.0.1', port=1433, user='sa', password='password', database= ...
- 详解 Java 17 中新推出的密封类
Java 17推出的新特性Sealed Classes经历了2个Preview版本(JDK 15中的JEP 360.JDK 16中的JEP 397),最终定稿于JDK 17中的JEP 409.Seal ...
- [C++STL] 迭代器 iterator 的使用
定义 迭代器是一种检查容器内元素并遍历元素的数据类型,表现的像指针. 基本声明方式 容器::iterator it = v.begin();//例:vector<int>::iterato ...
- 记一次IIS网站启动不了的问题排查
今天清理了下机器中的IIS网站,将很久不用的网站都删除. 因为需要删除的比较多,正在使用的很少,就将网站全部删除了,然后准备重新添加需要用的. 在添加了网站后,点击启动按钮,发现网站启动不了,因为网站 ...
- 微信小程序开发 记录
采坑了 微信小程序--TabBar不出现的一种原因 学习微信小程序中,遇到底部的TabBar不出现的问题.经过多番尝试,终于解决问题.在此记录问题产生的原因和对策.下面先描述错误现象,接着指出错误原因 ...
- 羿网通WT2100网络测试仪端口开关功能应用案例
端口开关是羿网通WT2100具备的一项全局性的功能,使用客户端软件Packlark连接WT2100后无需进入具体功能即可使用.该功能是通过控制设备上的以太网开关实现快速.便捷地切换网口通断状态的目标, ...
- syc-day2
第1题:mod注意负数. 第2题:dp 第3题:构造(奇偶性) 第4题:线段树
- MySQL - 锁的分类
MySQL - 锁的分类 1. 加锁机制 乐观锁 悲观锁 2. 兼容性 共享锁 排他锁 3. 锁粒度 表锁 页锁 行锁 4. 锁模式 记录锁(record-lock) 间隙锁(gap-lock) ne ...
- nginx 部署前端资源的最佳方案
前言 最近刚来一个运维小伙伴,做线上环境的部署的时候,前端更新资源后,总是需要清缓存才能看到个更新后的结果.客户那边也反馈更新了功能,看不到. 方案 前端小伙伴应该都知道浏览器的缓存策略,协商缓存和强 ...
- Linux文本搜索及截取操作
Linux文本搜索及截取操作 cat 查看 grep 搜索 awk 截取 查看dna-server.xml 文件的内容 [root@localhost servers]# cat cwag9002/w ...