Hive的基本知识与操作
Hive的基本知识与操作
Hive的基本概念
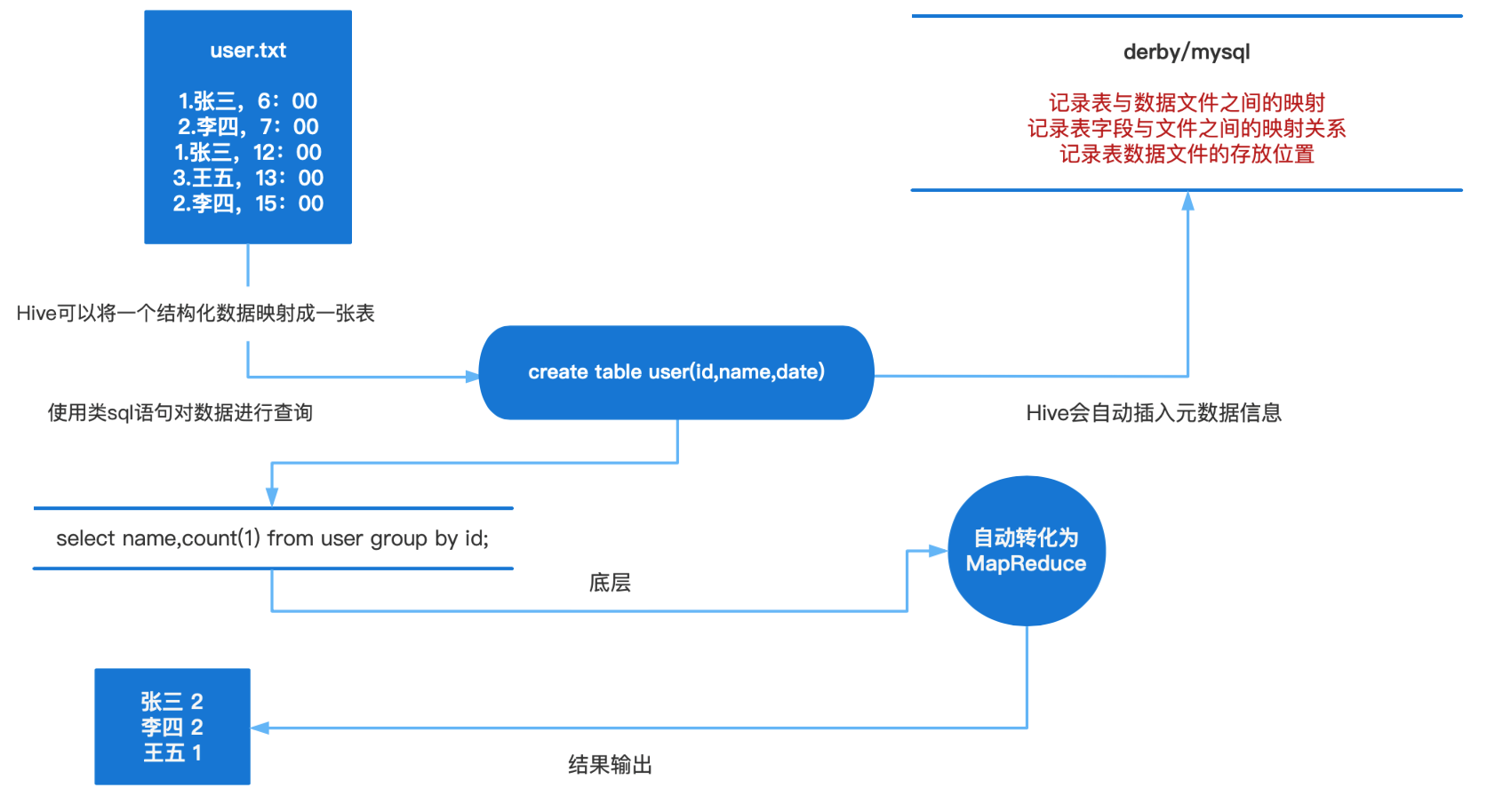
Hive本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更近一步说hive就是一个MapReduce客户端。
为什么使用Hive?
如果直接使用hadoop的话,人员学习成本太高,项目要求周期太短,MapReduce实现复杂查询逻辑开发难度太大。如果使用hive的话,可以操作接口采用类SQL语法,提高开发能力,免去了写MapReduce,减少开发人员学习成本,功能扩展很方便(比如:开窗函数)。
Hive的特点:
1、可扩展性
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
2、延申性
Hive支持自定义函数,用户可以根据自己的需求来实现自己的函数
3、容错
即使节点出现错误,SQL仍然可以完成执行
Hive的优缺点:
优点:
1、操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)
2、避免了去写MapReduce,减少开发人员的学习成本
3、Hive的延迟性比较高,因此Hive常用于数据分析,适用于对实时性要求不高的场合
4、Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。(不断地开关JVM虚拟机)
5、Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
6、集群可自由扩展并且具有良好的容错性,节点出现问题SQL仍可以完成执行
缺点:
1、Hive的HQL表达能力有限
(1)迭代式算法无法表达 (反复调用,mr之间独立,只有一个map一个reduce,反复开关)
(2)数据挖掘方面不擅长
2、Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗 (hql根据模板转成mapreduce,不能像自己编写mapreduce一样精细,无法控制在map处理数据还是在reduce处理数据)
Hive应用场景
日志分析:大部分互联网公司使用hive进行日志分析,如百度、淘宝等。
统计一个网站一个时间段内的PV(页面浏览量)UV(统计一天内某站点的用户数)SKU ,SPU
Hive架构
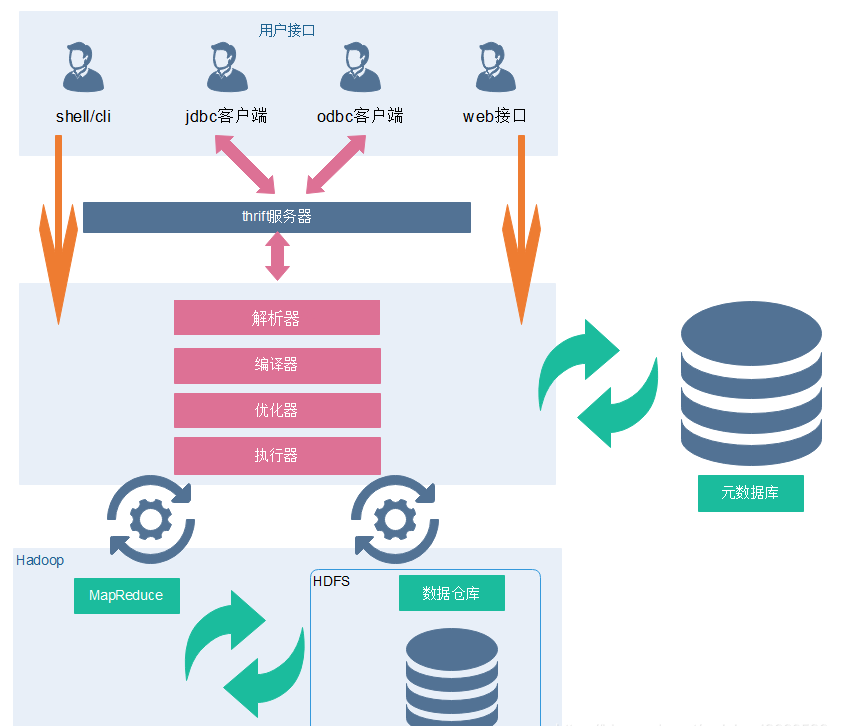
Client
Hive允许client连接的方式有三个CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问 hive)。JDBC访问时中间件Thrift软件框架,跨语言服务开发。DDL DQL DML,整体仿写一套SQL语句。
1)client–需要下载安装包
2)JDBC/ODBC 也可以连接到Hive
现在主流都在倡导第二种 HiveServer2/beeline
做基于用户名和密码安全的一个校验
3)Web Gui
hive给我们提供了一套简单的web页面
我们可以通过这套web页面访问hive 做的太简陋了
Metastore(元数据)
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是 外部表)、表的数据所在目录等。
一般需要借助于其他的数据载体(数据库)
主要用于存放数据库的建表语句等信息
推荐使用Mysql数据库存放数据
连接数据库需要提供:uri username password driver
sql语句是如何转化成MR任务的?
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完 成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
2) 编译器(Physical Plan):将AST编译生成逻辑执行计划。
3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。
数据处理
Hive的数据存储在HDFS中,计算由MapReduce完成。HDFS和MapReduce是源码级别上的整合,两者结合最佳。解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
Hive的三种交互方式
第一种交互方式
shell交互Hive,用命令hive启动一个hive的shell命令行,在命令行中输入sql或者命令来和Hive交互。
服务端启动metastore服务(后台启动):nohup hive --service metastore >/dev/null &
进入命令:hive
退出命令行:quit;
第二种交互方式
Hive启动为一个服务器,对外提供服务,其他机器可以通过客户端通过协议连接到服务器,来完成访问操作,这是生产环境用法最多的
服务端启动hiveserver2服务:
nohup hive --service metastore >/dev/null &
nohup hiveserver2 >/dev/null &
需要稍等一下,启动服务需要时间:
进入命令:1)先执行: beeline ,再执行: !connect jdbc:hive2://master:10000
2)或者直接执行: beeline -u jdbc:hive2://master:10000 -n root
退出命令行:!exit
第三种交互方式
使用 –e 参数来直接执行hql的语句
bin/hive -e "show databases;"
使用 –f 参数通过指定文本文件来执行hql的语句
特点:执行完sql后,回到linux命令行。
创建一个sql文件:vim hive.sql
里面写入要执行的sql命令
use myhive;
select * from test;
hive -f hive.sql
Hive元数据
Hive元数据库中一些重要的表结构及用途,方便Impala、SparkSQL、Hive等组件访问元数据库的理解。
1、存储Hive版本的元数据表(VERSION),该表比较简单,但很重要,如果这个表出现问题,根本进不来Hive-Cli。比如该表不存在,当启动Hive-Cli的时候,就会报错“Table 'hive.version' doesn't exist”
2、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
DBS:该表存储Hive中所有数据库的基本信息。
DATABASE_PARAMS:该表存储数据库的相关参数。
3、Hive表和视图相关的元数据表
主要有TBLS、TABLE_PARAMS、TBL_PRIVS,这三张表通过TBL_ID关联。
TBLS:该表中存储Hive表,视图,索引表的基本信息。
TABLE_PARAMS:该表存储表/视图的属性信息。
TBL_PRIVS:该表存储表/视图的授权信息。
4、Hive文件存储信息相关的元数据表
主要涉及SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中。
SDS:该表保存文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息。
SD_PARAMS: 该表存储Hive存储的属性信息。
SERDES:该表存储序列化使用的类信息。
SERDE_PARAMS:该表存储序列化的一些属性、格式信息,比如:行、列分隔符。
5、Hive表字段相关的元数据表
主要涉及COLUMNS_V2:该表存储表对应的字段信息。
Hive的基本操作
创建数据库
数据库在hdfs上的默认路径是/hive/warehouse/*.db
create database testdb;
避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
create database if not exists testdb;
创建数据库并指定位置
create database if not exists testdb location '/testdb.db';
修改数据库
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
alter database dept set dbproperties('createtime'='20220531');为数据库的DBPROPERTIES设置键值对属性值
查看数据库详细信息
显示数据库
show databases;
通过like过滤显示数据库
show datebases like '*t*';(这里是*,sql里是%)
查看数据库详情
desc database testdb;
切换数据库
use testdb;
删除数据库
最简写法
drop database testdb;
如果删除的数据库不存在,最好使用if exists判断数据库是否存在。否则会报错:FAILED: SemanticException [Error 10072]: Database does not exist: db_hive
drop database if exists testdb;
如果数据库不为空,使用cascade命令进行强制删除。报错信息如下FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database db_hive is not empty. One or more tables exist.)
drop database if exists testdb cascade;
Hive的数据类型
基础数据类型
| 类型 | Java数据类型 | 描述 |
|---|---|---|
| TINYINT | byte | 8位有符号整型。取值范围:-128~127。 |
| SMALLINT | short | 16位有符号整型。取值范围:-32768~32767。 |
| INT | int | 32位有符号整型。取值范围:-2 31 ~2 31 -1。 |
| BIGINT | long | 64位有符号整型。取值范围:-2 63 +1~2 63 -1。 |
| BINARY | 二进制数据类型,目前长度限制为8MB。 | |
| FLOAT | float | 32位二进制浮点型。 |
| DOUBLE | double | 64位二进制浮点型。 |
| DECIMAL(precision,scale) | 10进制精确数字类型。precision:表示最多可以表示多少位的数字。取值范围:1 <= precision <= 38。scale:表示小数部分的位数。取值范围: 0 <= scale <= 38。如果不指定以上两个参数,则默认为decimal(10,0)。 | |
| VARCHAR(n) | 变长字符类型,n为长度。取值范围:1~65535。 | |
| CHAR(n) | 固定长度字符类型,n为长度。最大取值255。长度不足则会填充空格,但空格不参与比较。 | |
| STRING | string | 字符串类型,目前长度限制为8MB。 |
| DATE | 日期类型,格式为yyyy-mm-dd。取值范围:0000-01-01~9999-12-31。 |
|
| DATETIME | 日期时间类型。取值范围:0000-01-01 00:00:00.000~9999-12-31 23.59:59.999,精确到毫秒。 | |
| TIMESTAMP | 与时区无关的时间戳类型。取值范围:0000-01-01 00:00:00.000000000~9999-12-31 23.59:59.999999999,精确到纳秒。说明 对于部分时区相关的函数,例如cast(as string),要求TIMESTAMP按照与当前时区相符的方式来展现。 | |
| BOOLEAN | boolean | BOOLEAN类型。取值:True、False。 |
复杂的数据类型
| 类型 | 定义方法 | 构造方法 |
|---|---|---|
| ARRAY | array<int>``array<struct<a:int, b:string>> |
array(1, 2, 3)``array(array(1, 2), array(3, 4)) |
| MAP | map<string, string>``map<smallint, array<string>> |
map(“k1”, “v1”, “k2”, “v2”)``map(1S, array(‘a’, ‘b’), 2S, array(‘x’, ‘y’)) |
| STRUCT | struct<x:int, y:int>struct<field1:bigint, field2:array<int>, field3:map<int, int>> named_struct(‘x’, 1, ‘y’, 2)named_struct(‘field1’, 100L, ‘field2’, array(1, 2), ‘field3’, map(1, 100, 2, 200)) |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。还有一个uniontype< 所有类型,所有类型… > 。
数组:array< 所有类型 >;
Map < 基本数据类型,所有数据类型 >;
struct < 名:所有类型[注释] >;
uniontype< 所有类型,所有类型… >
Hive的文件格式
Hive没有专门的数据文件格式,常见的有以下几种:
TEXTFILE:Hive默认文件存储格式
SEQUENCEFILE
AVRO
RCFILE:列文件格式,能够很好的压缩和快速查询性能
ORCFILE:很高的压缩比,能很大程度的节省存储和计算资源,但它在读写时候需要消耗额外的CPU资源来压缩和解压缩
PARQUET
Hive的表操作
创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
字段解释说明:
- CREATE TABLE
创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- EXTERNAL
关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
创建内部表时,会将数据移动到数据仓库指向的路径(默认位置);
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变。在
删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
- COMMENT:
为表和列添加注释。
- PARTITIONED BY
创建分区表
- CLUSTERED BY
创建分桶表
- SORTED BY
不常用
- ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义SerDe或者使用自带的SerDe。
如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。
在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
- STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。
如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
- LOCATION :
指定表在HDFS上的存储位置。
- LIKE
允许用户复制现有的表结构,但是不复制数据。
默认建表方式
create table students
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; // 必选,指定列分隔符
指定location
create table students2
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/input1'; // 指定Hive表的数据的存储位置,一般在数据已经上传到HDFS,想要直接使用,会指定Location,通常Locaion会跟外部表一起使用,内部表一般使用默认的location
指定存储格式
create table students3
(
id bigint,
name string,
age int,
gender string,
clazz string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS rcfile; // 指定储存格式为rcfile
如果不指定,默认为textfile,注意:除textfile以外,其他的存储格式的数据都不能直接加载,需要使用从表加载的方式。
创建表并加载另一张表的所有信息
create table students4 as select * from students2;
只建表,不需要加载数据,相当于建表语句一样
create table students5 like students;
复杂人员信息表创建
create table IF NOT EXISTS t_person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string ,city:string>
)
row format delimited fields terminated by ','
collection items terminated by '_'
map keys terminated by ':'
lines terminated by '\n';
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,beng bu_anhui
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,he fei_anhui
显示表
show tables;
show tables like 'u';
desc t_person;
desc formatted t_person;
加载数据
1、使用 Hadoop fs -put '本地数据地址' 'hive表对应的HDFS目录下'
load data inpath '/input1/students.txt' into table students;
将HDFS上的/input1目录下面的数据 移动至 students表对应的HDFS目录下,注意是 移动、移动、移动
2、将Linux本地目录下的文件 上传到 hive表对应HDFS 目录下 原文件不会被删除
load data local inpath '/usr/local/soft/data/students.txt' into table students;
3、覆盖加载overwrite
load data local inpath '/usr/local/soft/data/students.txt' overwrite into table students;
清空表
truncate table students;
插入表数据insert into table xxxx SQL语句 (没有as)
将 students表的数据插入到students2 这是复制 不是移动 students表中的表中的数据不会丢失
insert into table students2 select * from students;
覆盖插入
覆盖插入 把into 换成 overwrite
insert overwrite table students2 select * from students;
修改列
查询表结构
desc students2;
添加列
alter table students2 add columns (education string);
查询表结构
desc students2;
更新列
alter table stduents2 change education educationnew string;
删除表
drop table students2;
Hive内部表
创建好表的时候,HDFS会在当前表所属的库中创建一个文件夹
当load数据的时候,就会将数据文件存放到表对应的文件夹中
数据一旦被load,就不能被修改
删除表的时候,表对应的文件夹会被删除,同时数据也会被删除
默认建表的类型就是内部表
Hive外部表
外部表因为是指定其他的hdfs路径的数据加载到表中来,所以hive会认为自己不完全独占这份数据
删除hive表的时候,数据仍然保存在hdfs中,不会删除。
外部表关键字external
一般在公司中,使用外部表多一点,因为数据可以需要被多个程序使用,避免误删,通常外部表会结合location一起使用
外部表还可以将其他数据源中的数据 映射到 hive中,比如说:hbase,ElasticSearch......
设计外部表的初衷就是 让 表的元数据 与 数据 解耦
Hive导出数据
将表中的数据备份
- 将查询结果存放到本地
//创建存放数据的目录
mkdir -p /usr/local/soft/shujia
//导出查询结果的数据(导出到Node01上)
insert overwrite local directory '/usr/local/soft/shujia/person_data' select * from t_person;
- 按照指定的方式将数据输出到本地
-- 创建存放数据的目录
mkdir -p /usr/local/soft/shujia
-- 导出查询结果的数据
insert overwrite local directory '/usr/local/soft/shujia/person'
ROW FORMAT DELIMITED fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
lines terminated by '\n'
select * from t_person;
- 将查询结果输出到HDFS
-- 创建存放数据的目录
hdfs dfs -mkdir -p /shujia/bigdata17/copy
-- 导出查询结果的数据
insert overwrite local directory '/usr/local/soft/shujia/students_data2' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' select * from students
- 直接使用HDFS命令保存表对应的文件夹
// 创建存放数据的目录
hdfs dfs -mkdir -p /shujia/bigdata17/person
// 使用HDFS命令拷贝文件到其他目录
hdfs dfs -cp /hive/warehouse/t_person/* /shujia/bigdata17/person
将表结构和数据同时备份
将数据导出到HDFS
//创建存放数据的目录
hdfs dfs -mkdir -p /shujia/bigdata17/copy //导出查询结果的数据
export table t_person to '/shujia/bigdata17/copy';
删除表结构
drop table t_person;
恢复表结构和数据
import from '/shujia/bigdata17';
注意:时间不同步,会导致导入导出失败
Hive的基本知识与操作的更多相关文章
- Hive 这些基础知识,你忘记了吗?
Hive 其实是一个客户端,类似于navcat.plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能 ...
- Hive常用的SQL命令操作
Hive提供了很多的函数,可以在命令行下show functions罗列所有的函数,你会发现这些函数名与mysql的很相近,绝大多数相同的,可通过describe function functionN ...
- hive数据库的哪些函数操作是否走MR
平时我们用的HIVE 我们都知道 select * from table_name 不走MR 直接走HTTP hive 0.10.0为了执行效率考虑,简单的查询,就是只是select,不带count, ...
- hive:数据库“行专列”操作---使用collect_set/collect_list/collect_all & row_number()over(partition by 分组字段 [order by 排序字段])
方案一:请参考<数据库“行专列”操作---使用row_number()over(partition by 分组字段 [order by 排序字段])>,该方案是sqlserver,orac ...
- hive元数据库表分析及操作
在安装Hive时,需要在hive-site.xml文件中配置元数据相关信息.与传统关系型数据库不同的是,hive表中的数据都是保存的HDFS上,也就是说hive中的数据库.表.分区等都可以在HDFS找 ...
- 大数据【五】Hive(部署;表操作;分区)
一 概述 就像我们所了解的sql一样,Hive也是一种数据仓库,不同的是hive是在hadoop大数据生态圈中所用.这篇博客我主要介绍Hive的简单表运用. Hive是Hadoop 大数据生态圈中的数 ...
- HIVE中的order by操作
hive中常见的高级查询包括:group by.Order by.join.distribute by.sort by.cluster by.Union all.今天我们来看看order by操作,O ...
- Hive(一)基础知识
一.Hive的基本概念 (安装的是Apache hive 1.2.1) 1.hive简介 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供类 SQ ...
- Hive命令行经常使用操作(数据库操作,表操作)
数据库操作 查看全部的数据库 hive> show databases ; 使用数据库default hive> use default; 查看数据库信息 hive > descri ...
随机推荐
- 命令行工具tabby--gi t仓库Token的使用
命令行工具tabby--git仓库Token的使用 欢迎关注H寻梦人公众号 前言 再见 Xshell !这款开源的终端工具逼格更高! 终端神器--Tabby Terminal electerm is ...
- bat-静默安装winrar并设置系统级环境变量
@echo off Setlocal enabledelayedexpansion @REM vscode中自动开启延迟环境变量扩展 echo 安装winrar "winrar v.5.71 ...
- 老掉牙的 synchronized 锁优化,一次给你讲清楚!
我们都知道 synchronized 关键字能实现线程安全,但是你知道这背后的原理是什么吗?今天我们就来讲一讲 synchronized 实现线程同步背后的原因,以及相关的锁优化策略吧. synchr ...
- centos系统管理高级篇
1 enable virtual box 控制 - 关机 可以通过虚拟机的关机按钮执行关机,而不是登陆centos再执行init 0 首先,安装acpid包 如果你的centos已经安装这个包,就省略 ...
- 数论之欧几里德gcd
序:这篇博客我最开始学的时候写的,后来又学了一遍,自我感觉这篇好像有问题,扩展欧几里得建议走这边 首先先说,欧几里德一共有俩,欧几里德和扩展欧几里德,前者非常简单,后者直接变态(因为我太菜) gcd ...
- 聊聊 C++ 大一统的初始化运算符 {}
一:背景 最近发现 C++ 中的类型初始化操作,没有 {} 运算符搞不定的,蛮有意思,今天我们就来逐一列一下各自的用法以及汇编展现,本来想分为 值类型 和 引用类型 两大块,但发现在 C++ 中没这种 ...
- 当mysql表从压缩表变成普通表会发生什么
前言 本文章做了把mysql表从压缩表过渡到普通表的实验过程,看看压缩表变成普通表会发生什么?本文针对mysql5.7和mysql8分别进行了实验. 1.什么是表压缩 在介绍压缩表变成普通表前,首先给 ...
- 研发效能生态完整图谱&DevOps工具选型必看
本文主要梳理了研发效能领域完整的方向图谱以及主流工具,其中对少部分工具也做了一些点评.看了之后,大家可以对研发效能这个领域有个整体认识,同时研发效能落地的时候也有对应的工具(黑话叫抓手)可以选择. 我 ...
- jdbc 03:注册驱动的方式
jdbc连接mysql时,注册驱动的方式 package com.examples.jdbc.o3_注册驱动方式; //mysql驱动所在的包 import com.mysql.jdbc.Driver ...
- CentOS7添加swap分区
买了个云主机,只有1G内存,跑爬虫经常内存不足,于是只能添加swap来缓解: 1.官方推荐的swap大小定义 2.使用dd命令在根下创建swapfile dd if=/dev/zero of=/swa ...