1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料
1.5.5 HDFS读写解析
1.5.5.1 HDFS读数据流程
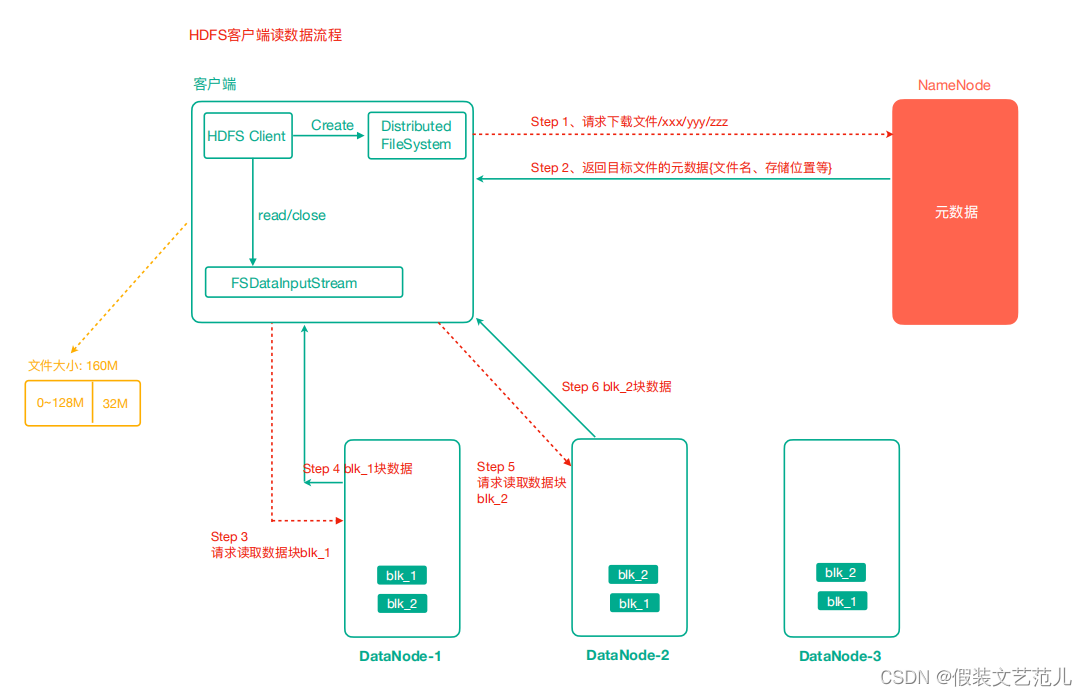
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据, 找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
1.5.5.2 HDFS写数据流程
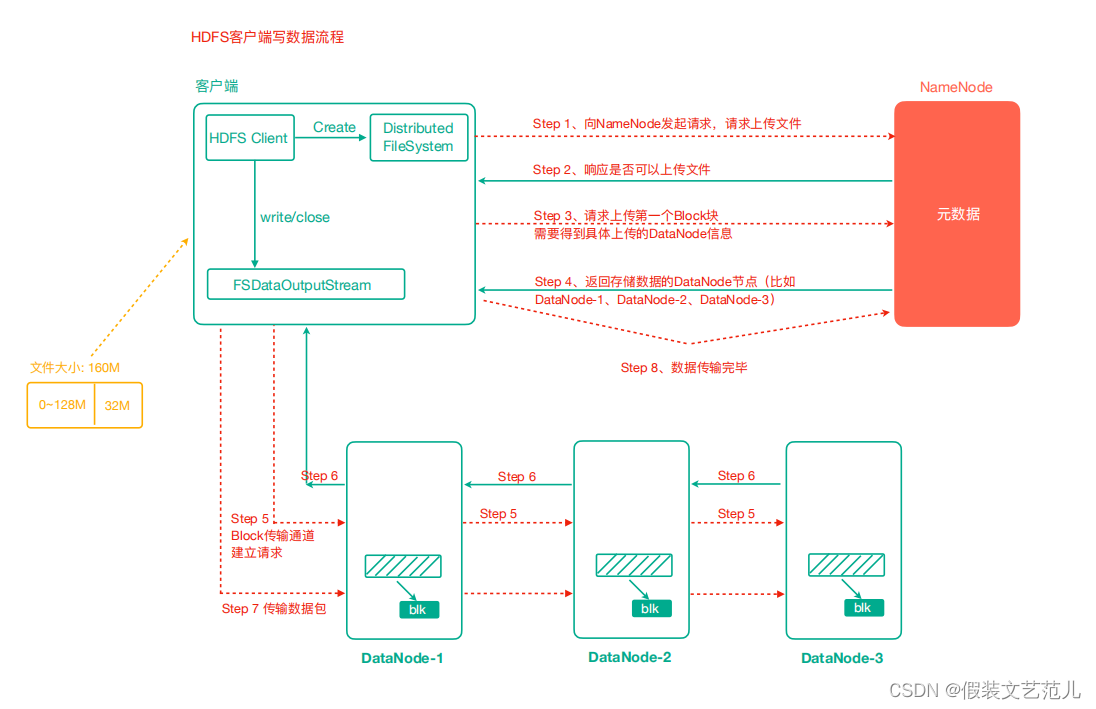
客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
NameNode返回是否可以上传。
客户端请求第一个 Block上传到哪几个DataNode服务器上。
NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
dn1、dn2、dn3逐级应答客户端。
客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行 3-7步)。
验证Packet代码
@Test
public void testUploadPacket() throws IOException {
//1 准备读取本地文件的输入流
final FileInputStream in = new FileInputStream(new File("e:/lagou.txt"));
//2 准备好写出数据到hdfs的输出流
final FSDataOutputStream out = fs.create(new Path("/lagou.txt"), new Progressable() {
public void progress () { //这个progress方法就是每传输64KB(packet)就会执行一次,
System.out.println("&");
}
});
//3 实现流拷贝
IOUtils.copyBytes(in, out, configuration); //默认关闭流选项是true,所以会自动 关闭
//4 关流 可以再次关闭也可以不关了
}
1.5.5 HDFS读写解析-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习笔记之Hadoop(二):HDFS文件系统
文章目录 一 HDFS概念 1.1 概念 1.2 组成 1.3 HDFS 文件块大小 二 HFDS命令行操作 三 HDFS客户端操作 3.1 eclipse环境准备 3.1.1 jar包准备 3.2 ...
- 大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一: package it.dawn.HDFSPra; import java.io.BufferedReader; import java.io.FileInputStream ...
- 大数据学习-2 认识Hadoop
一.什么是Hadoop? Hadoop可以简单的理解为一个数据存储和数据分析分布式系统.随着互联网的普及产生的数据是非常的庞大的,那么我们怎么去处理这么大量的数据呢?传统的单一计算机肯定是完成不了的, ...
随机推荐
- Django命令
(venv) E:\Py_CODE\myapp>python manage.py --help Type 'manage.py help <subcommand>' for help ...
- JuiceFS 在 Elasticsearch/ClickHouse 温冷数据存储中的实践
企业数据越存越多,存储容量与查询性能.以及存储成本之间的矛盾对于技术团队来说是个普遍难题.这个难题在 Elasticsearch 与 ClickHouse 这两个场景中尤为突出,为了应对不同热度数据对 ...
- LeetCode - 数组遍历
1. 485. 最大连续 1 的个数 1.1 分析题意 首先:我们求的是连续的1的个数,所以我们不能也没必要对数组进行排序: 其次:只要求求出最大连续1的个数,并不要求具体的区间数目,所以我们只需要用 ...
- .NET 开源项目推荐之 直播控制台解决方案 Macro Deck
流媒体是一个吸引数亿万玩家的严肃行业. 最受欢迎的游戏锦标赛的转播获得了数百万的观看次数,从商业角度来看,这也使游戏行业变得有趣.在直播圈有个很受欢迎的直播控制台程序Macro Deck, 它是基于A ...
- Node.js躬行记(24)——低代码
低代码开发平台(LCDP)是无需编码(0代码)或通过少量代码就可以快速生成应用程序的开发平台.让具有不同经验水平的开发人员可以通过图形化的用户界面,通过拖拽组件和模型驱动的逻辑来创建网页和移动应用程序 ...
- 6.pygame-搭建主程序
职责明确 新建plane_main.py 封装主游戏类 创建游戏对象 启动游戏 新建plane_sprites.py 封装游戏中所有需要使用的精灵子类 提供游戏的相关工具 #plane_sprit ...
- <五>掌握左值引用和初识右值引用
1:C++的引用,引用和指针的区别? 1:从汇编指令角度上看,引用和指针没有区别,引用也是通过地址指针的方式访问指向的内存 int &b=a ; 是需要将a的内存地址取出并存下来, b=20; ...
- 驱动开发:内核LDE64引擎计算汇编长度
本章开始LyShark将介绍如何在内核中实现InlineHook挂钩这门技术,内核挂钩的第一步需要实现一个动态计算汇编指令长度的功能,该功能可以使用LDE64这个反汇编引擎,该引擎小巧简单可以直接在驱 ...
- 编辑距离(Minimum Edit Distance)
编辑距离(Minimum Edit Distance,MED),也叫 Levenshtein Distance.他的含义是计算字符串a转换为字符串b的最少单字符编辑次数.编辑操作有:插入.删除.替换( ...
- python中while循环
# 1. print('1.我在学python 输出5遍') print('我在学python'*5) print('我在学python\n'*5) # 只能做单一重复 不能做线性 # 2.while ...