强化学习调参技巧二:DDPG、TD3、SAC算法为例:
1.训练环境如何正确编写
强化学习里的 env.reset() env.step() 就是训练环境。其编写流程如下:
1.1 初始阶段:
先写一个简化版的训练环境。把任务难度降到最低,确保一定能正常训练。记录正常训练的智能体的分数,与随机动作、传统算法得到的分数做比较。
DRL算法的分数应该明显高于随机动作(随机执行动作)。DRL算法不应该低于传统算法的分数。如果没有传统算法,那么也需要自己写一个局部最优的算法
评估策略的性能: 大部分情况下,可以直接是对Reward Function 给出的reward 进行求和得到的每轮收益episode return作为策略评分。有时候可以需要直接拿策略的实际分数作为评分
需要保证这个简化版的代码:高效、简洁、可拓展
1.2 改进阶段:
让任务难度逐步提高,对训练环境env 进行缓慢的修改,时刻保存旧版本的代码同步微调 Reward Function,可以直接代入自己的人类视角,为某些行为添加正负奖励。注意奖励的平衡(有正有负)。注意不要为Reward Function 添加太多额外规则,时常回过头取消一些规则,避免过度矫正。
同步微调 DRL算法,只建议微调超参数,但不建议对算法核心进行修改。因为任务变困难了,所以需要调整超参数让训练变快。同时摸清楚在这个训练环境下,算法对哪几个超参数是敏感的。有时候为了节省时间,甚至可以为 off-policy 算法保存一些典型的 trajectory(不建议在最终验证阶段使用)。
每一次修改,都需要跑一下记录不同方法的分数,确保:随机动作 < 传统方法 < DRL算法。这样才能及时发现代码逻辑上的错误。要极力避免代码中出现复数个的错误,因为极难排查。
1.3 收尾阶段:
尝试慢慢删掉Reward Function 中一些比较复杂的东西,删不掉就算了。
选择高低两组超参数再跑一次,确认没有优化空间。
2. 超参数解释分析
2.1 off-policy算法中常见的超参数
- 网络宽度: network dimension number。DRL 全连接层的宽度(特征数量)
- 网络层数: network layer number。一个输入张量到输出需要乘上w的次数
- 随机失活: dropout
- 批归一化: batch normalization
- 记忆容量: 经验回放缓存 experimence replay buffer 的最大容量 max capacity
- 批次大小: batch size。使用优化器更新时,每次更新使用的数据数量
- 更新次数:update times。使用梯度下降更新网络的次数
- 折扣因子: discount factor、gamma
【网络宽度、网络层数】 越复杂的函数就需要越大容量的神经网络去拟合。在需要训练1e6步的任务中,我一般选择 宽度128、256,层数小于8的网络(请注意,乘以一个w算一层,一层LSTM等于2层)。使用ResNet等结构会有很小的提升。一般选择一个略微冗余的网络容量即可,把调整超参数的精力用在这上面不划算,我建议这些超参数都粗略地选择2的N次方,
因为:防止过度调参,超参数选择x+1 与 x-1并没有什么区别,但是 x与2x一定会有显著区别
2的N次方大小的数据,刚好能完整地放进CPU或GPU的硬件中进行计算,如Tensor Core
过大、过深的神经网络不适合DRL,
因为:深度学习可以在整个训练结束后再使用训练好的模型。
而强化学习需要在几秒钟的训练后马上使用刚训好的模型。
这导致DRL只能用比较浅的网络来保证快速拟合(10层以下)
并且强化学习的训练数据不如有监督学习那么稳定,无法划分出训练集测试集去避免过拟合,
因此DRL也不能用太宽的网络(超过1024),避免参数过度冗余导致过拟合
【dropout、批归一化】 她们在DL中得到广泛地使用,可惜不适合DRL。如果非要用,那么也要选择非常小的 dropout rate(0~0.2),而且要注意在使用的时候关掉dropout。我不用dropout。
好处:在数据不足的情况下缓解过拟合;像Noisy DQN那样去促进策略网络探索
坏处:影响DRL快速拟合的能力;略微增加训练时间
【批归一化】 经过大量实验,DRL绝对不能直接使用批归一化,如果非要用,那么就要修改Batch Normalization的动量项超参数。
【记忆容量】 经验回放缓存 experimence replay buffer 的最大容量 max capacity,如果超过容量限制,它就会删掉最早的记忆。在简单的任务中(训练步数小于1e6),对于探索能力强的DRL算法,通常在缓存被放满前就训练到收敛了,不需要删除任何记忆。然而,过大的记忆也会拖慢训练速度,我一般会先从默认值 2 ** 17 ~ 2 ** 20 开始尝试,如果环境的随机因素大,我会同步增加记忆容量 与 batch size、网络更新次数,直到逼近服务器的内存、显存上限(放在显存训练更快)
【批次大小、更新次数】 一般我会选择与网络宽度相同、或略大的批次大小batch size。我一般从128、256 开始尝试这些2的N次方。在off-policy中,每往Replay 更新几个数据,就对应地更新几次网络,这样做简单,但效果一般。(深度学习里)更优秀的更新方法是:根据Replay中数据数量,成比例地修改更新次数。Don't Decay the Learning Rate, Increase the Batch Size. ICLR. 2018 。,经过验证,DRL也适用。
【折扣因子】 discount factor、discount-rate parameter 或者叫 gamma 。0.99
2.2 on-policy算法中常见的超参数
同策略(A3C、PPO、PPO+GAE)与异策略(DQN、DDPG、TD3、SAC)的主要差异是:
异策略off-policy:ReplayBuffer内可以存放“由不同策略”收集得到的数据用于更新网络
同策略on-policy:ReplayBuffer内只能存放“由相同策略”收集得到的数据用于更新网络
因此以下超参数有不同的选择方法:记忆容量:经验回放缓存 experimence replay buffer 的最大容量 max capacity
批次大小:batch size。使用优化器更新时,每次更新使用的数据数量
更新次数:update times。使用梯度下降更新网络的次数
【记忆容量】 on-policy 算法每轮更新后都需要删除“用过的数据”,所以on-policy的记忆容量应该大于等于【单轮更新的采样步数】,随机因素更多的任务需要更大的单层采样步数才能获得更多的 轨迹 trajectory,才能有足够的数据去表达环境与策略的互动关系。详见下面PPO算法的【单轮更新的采样步数】
【批次大小】 on-policy 算法比off-policy更像深度学习,它可以采用稍大一点的学习率(2e-4)。因为【单轮更新的采样步数】更大,所以它也需要搭配更大的batch size(29 ~ 212)。如果内存显存足够,我建议使用更大的batch size,我发现一些很难调的任务,在很大的batch size(2 ** 14) 面前更容易获得单调上升的学习曲线(训练慢但是及其稳定,多GPU分布式)。请自行取舍。
【更新次数】 一般我们不直接设置更新次数,而是通过【单轮更新的采样步数】、【批次大小】和【数据重用次数】一同算出【更新次数】,详见下面PPO算法的【数据重用次数】
3. TD3特有的超参数
- 探索噪声方差 exploration noise std
- 策略噪声方差 policy noise std
- 延迟更新频率 delay update frequency
如果你擅长调参,那么可以可以考虑TD3算法。如果你的算法的最优策略通常是边界值,那么你首选的算法就是TD3----最佳策略总在动作边界
【TD3的探索方式】 让其很容易在探索「边界动作」:
- 策略网络输出张量,经过激活函数 tanh 调整到 (-1, +1)
- 为动作添加一个clip过的高斯噪声,噪声大小由人类指定
- 对动作再进行一次clip操作,调整到 (-1, +1)
好处: 一些任务的最优策略本就存在存在大量边界动作,TD3可以很快学得很快。
坏处: 边界动作都是 -1或 +1,这会降低策略的多样性,网络需要在多样性好数据上训练才不容易过拟合。对于clip 到正负1之间的action,过大的噪声方差会产生大量边界动作 。
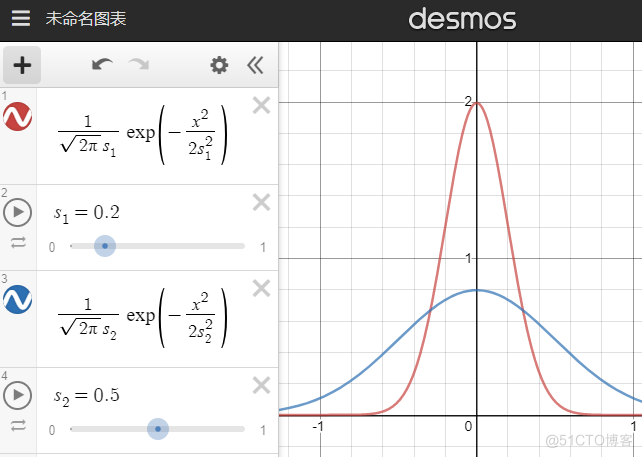
【探索噪声方差 exploration noise std】 就是上图中的s。需要先尝试小的噪声方差(如0.05),然后逐渐加大。大的噪声方差刻意多探索边界值,特定任务下能让探索更快。且高噪声下训练出来的智能体更robust(稳健、耐操)。
请注意:过大的噪声方差(大于上图蓝线的0.5)并不会让探索动作接近随机动作,而是让探索动作更接近单一的边界动作。此外,过大的噪声会影响智能体性能,导致她不容易探索到某些state。
因此,合适的探索噪声方差只能慢慢试出来,TD3适合愿意调参的人使用。在做出错误动作后容易挽回的环境,可以直接尝试较大的噪声。
我们也可以模仿 epslion-Greedy,设置一个使用随机动作的概率,或者每间隔几步探索就不添加噪声,甚至也在TD3中使用探索衰减。这些操作都会增加超参数的数量,慎用。
【策略噪声方差 policy noise std】 确定了探索噪声后,策略噪声只需要比探索噪声稍大(1~2倍)。TD3对策略噪声的解释是“计算Q值时,因为相似的动作的Q值也是相似的,所以TD3也为动作加一个噪声,这能使Q值函数更加光滑,提高训练稳定性 我们还能多使用几个添加噪声的动作,甚至使用加权重要性采样去算出更稳定的Q值期望。在确定策略梯度算法里的这种“在计算Q值时,为动作加noise的操作”,让TD3变得有点像随机策略梯度。无论是否有clip,策略噪声方差最大也不该超过0.5。
【延迟更新频率 delay update frequency】 TD3认为:引入目标网络进行 soft update 就是为了提高训练稳定性,那么既然 network 不够稳定,那么我们应该延迟更新目标网络 target network,即多更新几次 network,然后再更新一次target network。从这个想法再拓展出去,我们甚至可以模仿TTUR的思想做得更细致一点,针对双层优化问题我们能做:
环境随机因素多,则需要尝试更大的延迟更新频率,可尝试的值有 1~8,默认值为2
提供策略梯度的critic可以多更新几次,再更新一次actor,可尝试的值有 1~4<
提供策略梯度的critic可以设计更大的学习率,例如让critic的学习率是actor 的1~10倍
由于critic 需要处理比 actor 更多的数据,因此建议让critic网络的宽度略大于actor
4. SAC特有的超参数
尽管下面列举了4个超参数,但是后三个超参数可以直接使用默认值(默认值只会有限地影响训练速度),第一个超参数甚至可以直接通过计算选择出来,不需要调整。
- reward scale 按比例调整奖励
- alpha 温度系数 或 target entropy 目标 策略熵
- learning rate of alpha 温度系数 alpha 的学习率
- initialization of alpha 温度系数 alpha 的初始值
SAC有极少的超参数,甚至这些超参数可以在训练开始前就凭经验确定。
 任何存在多个loss相加的目标函数,一定需要调整系数 lambda,例如SAC算法、共享了actor critic 网络的A3C或PPO,使用了辅助任务的PPG。我们需要确定好各个 lambda 的比例。SAC的第二篇论文加入了自动调整 温度系数 alpha 的机制,处于lambda2位置的温度alpha 已经用于自动调整策略熵了,所以我们只能修改lambda1。
任何存在多个loss相加的目标函数,一定需要调整系数 lambda,例如SAC算法、共享了actor critic 网络的A3C或PPO,使用了辅助任务的PPG。我们需要确定好各个 lambda 的比例。SAC的第二篇论文加入了自动调整 温度系数 alpha 的机制,处于lambda2位置的温度alpha 已经用于自动调整策略熵了,所以我们只能修改lambda1。
reward scaling 是指直接让reward 乘以一个常数k (reward scale),在不破坏reward function 的前提下调整reward值,从而间接调整Q值到合适的大小。 修改reward scale,相当于修改lambda1,从而让可以让 reward项 和 entropy项 它们传递的梯度大小接近。与其他超参数不同,只要我们知晓训练环境的累计收益范围,我们就能在训练前,直接随意地选定一个reward scaling的值,让累计收益的范围落在 -1000~1000以内即可,不需要精细调整:
【温度系数、目标策略熵】 Temperature parameters (alpha)、target 'policy entropy'。SAC的第二篇论文加入了自动调整 温度系数 alpha 的机制:通过自动调整温度系数,做到让策略的熵维持在目标熵的附近(不让alpha过大而影响优化,也不让alpha过小而影响探索)
策略熵的默认值是 动作的个数 的负log,详见SAC的第二篇论文 section 5 Automating Entropy Adjustment for Maximum Entropy 。SAC对这个超参数不敏感,一般不需要修改。有时候策略的熵太大将导致智能体无法探索到某些有优势的state,此时需要将目标熵调小。
【温度系数 alpha 的学习率】 learning rate of alpha 温度系数alpha 最好使用 log 形式进行优化,因为alpha是表示倍数的正数。一般地,温度系数的学习率和网络参数的学习率保持一致(一般都是1e-4)。当环境随机因素过大,导致每个batch 算出来的策略熵 log_prob 不够稳定时,我们需要调小温度系数的学习率。
【温度系数 alpha 的初始值】 initialization of alpha 温度系数的初始值可以随便设置,只要初始值不过于离奇,它都可以被自动调整为合适的值。一般偷懒地将初始值设置为 log(0) 其实过大了,这会延长SAC的预热时间,我一般设置成更小的数值,详见 The alpha loss calculating of SAC is different from other repo · Issue #10 · Yonv1943/ElegantRL 。
5. 自己模型训练调参记录(TD3)
5.1 模型环境参数
常规参数:
| 无人机初始位置 | 用户初始位置 | 无人机覆盖半径(米) | 最大关联数 | UAV飞行距离 |
|---|---|---|---|---|
| 【20,180】 | 【20,180】 | 【75,100】 | 【20,30】 | 【0,30】 |
| 时延记录: | ||||
| 前景(MB) | 0.125 | 0.5 | 1 | 1.25 |
| -- | -- | -- | -- | -- |
| 背景(MB) | 0.5 | 2 | 4 | 5 |
| local(ms) | 13 | 52 | 105 | --- |
| UAV(ms) | 47 | 29.4 | 39.7 | --- |
| coop(ms) | 44 | 29.6 | 38.2 | ---- |
| 超参数: | ||||
| ACTOR_LR | CRITIC_LR | BATCH_SIZE | GAMMA | TAU |
| -- | -- | -- | -- | -- |
| 【1e-4 ,1e-5】 | 【1e-3 ,1e-4】 | 【256,512】 | 0.99】 | 0.005 |
| EXPL_NOISE | policy_noise | noise_clip | policy_freq | hid_size |
| 0.1、0.05 | 0.2、0.1 | 0.5 | 【1,8】默认:2 | 【128,512】 |
目前采用组合有如下:
- ACTOR_LR = 1e-4 # Actor网络的 learning rate 学习率 1e-3
- CRITIC_LR = 1e-3 # Critic网络的 learning rate 1e-3
- EXPL_NOISE = 0.05 # 动作噪声方差
- self.hid_size=256
- self.hid1_size=128
- policy_noise=0.1,
- noise_clip=0.5,
- policy_freq=2
5.2 调参效果:
可以看到模型训练的稳定性和收敛效果越来越好,调多了你也就知道哪些超参数影响的大了
5.3 造成波动的原因,然后采用对应的解决方案:
- 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异过大。那么这是环境发生改变造成的:
-1. 每一轮训练都需要 env.reset(),然而,有时候重置环境会改变难度,这种情况下造成的波动无法消除。
-2. 有时候是因为DRL算法的泛化性不够好。此时我们需要调大相关参数增加探索,以训练出泛化性更好的策略。 - 如果在策略网络没有更新的情况下,Agent在环境中得到的分数差异较小。等到更新后,相邻两次的分数差异很大。那么这是环境发生改变造成的: 1. 把 learning rate 调小一点。2. 有时候是因为算法过度鼓励探索而导致的,调小相关参数即可。
强化学习调参技巧二:DDPG、TD3、SAC算法为例:的更多相关文章
- Deep learning网络调参技巧
参数初始化 下面几种方式,随便选一个,结果基本都差不多.但是一定要做.否则可能会减慢收敛速度,影响收敛结果,甚至造成Nan等一系列问题.n_in为网络的输入大小,n_out为网络的输出大小,n为n_i ...
- [转] TextCNN调参技巧
原文地址: https://plushunter.github.io/2018/02/26/%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 深度学习调参笔记(trick)
1. Adam 学习率0.00035真香: 2. SGD + Momentum 学习率应当找到合适区间,一般远大于Adam (取1,2,5,10这类数据): 3. 提前终止,防止过拟合; 4. Ens ...
- object detection api调参详解(兼SSD算法参数详解)
一.引言 使用谷歌提供的object detection api图像识别框架,我们可以很方便地重新训练一个预训练模型,用于自己的具体业务.以我所使用的ssd_mobilenet_v1预训练模型为例,训 ...
- [调参]CV炼丹技巧/经验
转自:https://www.zhihu.com/question/25097993 我和@杨军类似, 也是半路出家. 现在的工作内容主要就是使用CNN做CV任务. 干调参这种活也有两年时间了. 我的 ...
- 【新人赛】阿里云恶意程序检测 -- 实践记录11.10 - XGBoost学习 / 代码阅读、调参经验总结
XGBoost学习: 集成学习将多个弱学习器结合起来,优势互补,可以达到强学习器的效果.要想得到最好的集成效果,这些弱学习器应当"好而不同". 根据个体学习器的生成方法,集成学习方 ...
- 强化学习二:Markov Processes
一.前言 在第一章强化学习简介中,我们提到强化学习过程可以看做一系列的state.reward.action的组合.本章我们将要介绍马尔科夫决策过程(Markov Decision Processes ...
- xgboost&lightgbm调参指南
本文重点阐述了xgboost和lightgbm的主要参数和调参技巧,其理论部分可见集成学习,以下内容主要来自xgboost和LightGBM的官方文档. xgboost Xgboost参数主要分为三大 ...
- 01.CNN调参
转载:调参是个头疼的事情,Yann LeCun.Yoshua Bengio和Geoffrey Hinton这些大牛为什么能够跳出各种牛逼的网络? 下面一些推荐的书和文章:调参资料总结Neural Ne ...
随机推荐
- DophineSheduler上下游任务之间动态传参案例及易错点总结
作者简介 淡丹 数仓开发工程师 5年数仓开发经验,目前主要负责百得利MOBY新车业务 二手车业务及售后服务业务系统数仓建设 业务需求 在ETL任务之间调度时,我们有的时候会需要将上游的 ...
- [题解] LOJ 3300 洛谷 P6620 [省选联考 2020 A 卷] 组合数问题 数学,第二类斯特林数,下降幂
题目 题目里要求的是: \[\sum_{k=0}^n f(k) \times X^k \times \binom nk \] 这里面出现了给定的多项式,还有组合数,这种题目的套路就是先把给定的普通多项 ...
- 简书是如何把用户wo逼疯的
趁验证码还有一分钟时间,吐槽一下简书. 准备开始在简书写文章,遇到一些问题. 一.markdown的问题 1.不支持html 2....... 二.绑定手机--这是一个bug 我原来是使用邮箱注册的, ...
- 面向对象的照妖镜——UML类图绘制指南
1.前言 感受 在刚接触软件开发工作的时候,每次接到新需求,在分析需求后的第一件事情,就是火急火燎的打开数据库(DBMS),开始进行数据表的创建工作.然而这种方式,总是会让我在编码过程中出现实体类设计 ...
- KTV和泛型(3)
泛型除了KTV,还有一个让人比较疑惑的玩意,而且它就是用来表达疑惑的:? 虽然通过泛型已经达到我们想要的效果了,例如: List<String> list = new ArrayList& ...
- Codeforces 1682 D Circular Spanning Tree
题意 1-n排列,构成一个圆:1-n每个点有个值0或者1,0代表点的度为偶数,1代表点的度为计数:询问能否构成一棵树,树的连边在圆内不会相交,在圆边上可以相交,可以则输出方案. 提示 1. 首先考虑什 ...
- LcdTools如何通过PX01把EDP屏的EDID拷贝出来
PX01点EDP屏在上电过程会自动读取屏EDID,怎么把EDP EDID值拷贝出来呢? 在上电时序函数调用SetEdidRdShowEn(ON)指令开启EDID值读取显示功能.如下图 通过上述操作开机 ...
- 四、Pod 介绍
一.什么是 Pod Pod 是 kubernetes 集群中最小的部署和管理的基本单元,协同寻址,协同调度. Pod 是一个或多个容器的集合,是一个或一组服务(进程)的抽象集合. Pod 中可以 ...
- Ruoyi表单构建
Ruoyi表单构建通过拖动组件就能自动生成前端代码,很方便,所以本文简单通过上层函数源码来梳理一下大致流程,如有需要再自行仔细一行行分析底层代码. 组件拖动 实现组件拖动功能主要依赖第三方库:VueD ...
- POC、EXP、SRC概念厘清
「POC」 POC可以看成是一段验证的代码,就像是一个证据,能够证明漏洞的真实性,能证明漏洞的存在即可. https://zhuanlan.zhihu.com/p/26832890 「EXP」 ...