Machine Learning 学习笔记 03 最小二乘法、极大似然法、交叉熵
损失函数
神经网络里的标准和人脑标准相比较 相差多少的定量表达。
最小二乘法
首先要搞明白两个概率模型是怎么比较的。有三种思路,最小二乘法、极大似然估计,交叉熵
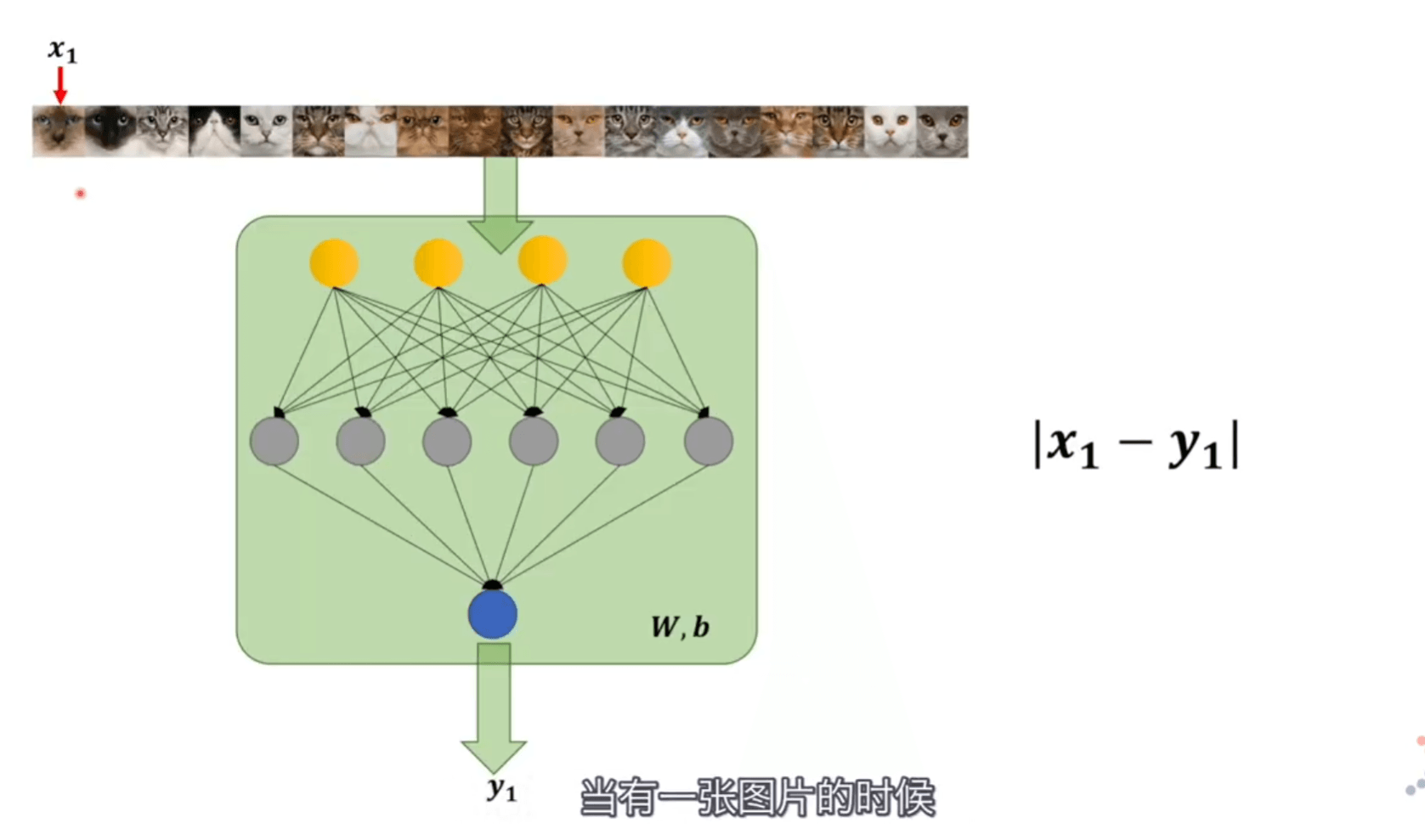
当一张图片人脑判断的结果是 \(x1\),神经网络判断的结果是 \(y1\),直接把它们相减 \(\left|x_{1}-y_{1}\right|\) 就是他们相差的范围。我们将多张图片都拿过来判断加起来,当最终值最小的时候,\(\min \sum_{i=1}^{n}\left|x_{i}-y_{i}\right|\) 就可以认定两个模型近似。
但是绝对值在定义域内不是全程可导的,所以可以求平方 \(\min \sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}\)
就这是最小二乘法,但是只用它判断两个概率模型差别有多少,去作为损失函数会比较困难。所以引入极大似然估计
极大似然估计
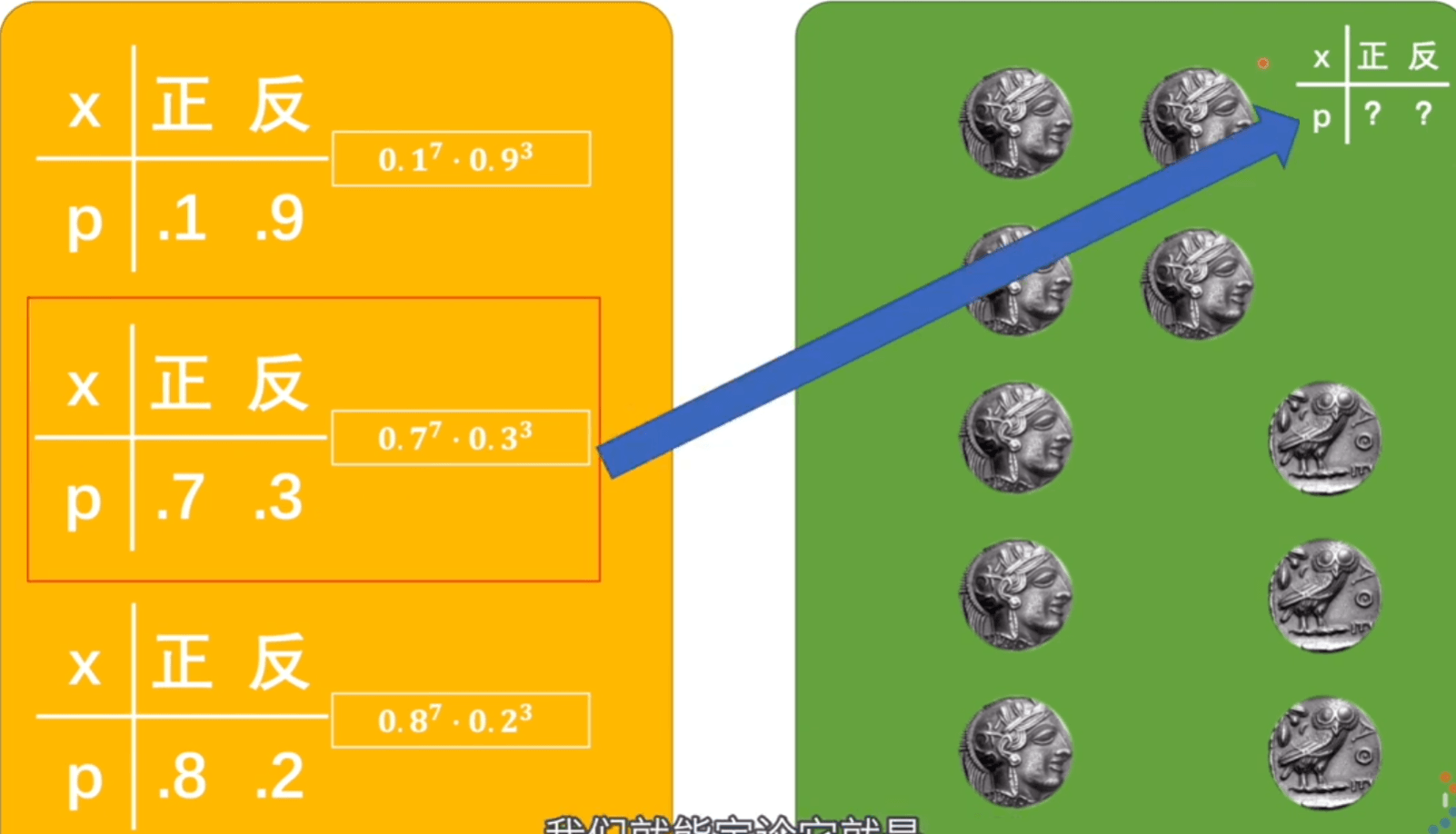
似然值是真实的情况已经发生,我们假设它有很多模型,在这个概率模型下,发生这种情况的可能性就叫似然值。
挑出似然值最大的,那可能性也就越高,此时的概率模型应该是与标准模型最接近的。
\(\theta\) 是抛硬币的概率模型,\(W,b\) 是神经网络的概率模型。前者结果是硬币是正还是反,后者结果是图片到底是不是猫。
在神经网络是这样的参数下,输入的照片如果是猫概率是多少、如果不是猫概率是多少,所有图片判断后,相乘得到的值就是似然值。取到极大似然值就是最接近的值。
但在训练的时候 \(W、b\) 无论输入什么样的照片都是固定的值,如果我们都用猫的照片来确定的话标签都是\(1\),那就没有办法进行训练,理论可行却没有操作性。但是我们还可以利用条件,训练神经网络的时候既可以得到 \(x_{i}\) 也可以得到 \(y_{i}\), \(y_{i}\) 的输出结果依赖 \(W,b\) 。每次输入照片不一样,\(y_{i}\) 的结果也就不一样。
\(x_{i}\) 的取值是 \(0、1\) ,符合二项伯努利分布,概率分布表达式为
\(x=1\) 就是图片为猫的概率。而 \(p\) 就是 \(y_{i}\) (神经网络认定是猫的概率),将其带入替换 $ P\left(x_{i} \mid y_{i}\right)$
我们更喜欢连加,在前面加 \(log\) ,并化简
所以,求极大似然值,就是求如下公式

复习一下对数
- $\log _{a}(1)=0 $
- $ \log _{a}(a)=1 $
- \(负数与零无对数\)
- \(\log _{a} b * \log _{b} a=1\)
- $ \log _{a}(M N)=\log _{a} M+\log _{a} N $
- $\log _{a}(M / N)=\log _{a} M-\log _{a} N $
- $ \log _{a} M^{n}=n \log _{a} M(\mathrm{M}, \mathrm{N} \in \mathrm{R}) $
- $ \log _{a^{n}} M=\frac{1}{n} \log _{a} M $
- $a^{\log _{a} b}=b $
交叉熵
要想直接比较两个模型,前提是两个模型类型是同一种,否则就不能公度。概率模型如果想要被统一衡量,我们需要引入熵(一个系统里的混乱程度)。
信息量
我们想获取信息量的函数,就要进行定义。并找寻能让体系自洽的公式。
将上面的第四条公式带入第三条得到如下第二条。为了使信息量定义能让体系自洽,我们给定定义 \(log\),这样符合相乘变相加的形式。
为了符合我们最直观的感觉,因为概率越小,信息量越大。而 \(log\) 函数单调递增,我们转换方向。
看计算机里多少位数据,给计算机输入一个16位数据,输入之前随便取的值是 \(1/2^{16}\) 的概率 ,输入之后的概率直接变为了 \(1\) 。信息量就是 \(16\) 比特。
信息量可以理解为一个事件从原来不确定到确定它的难度有多大,信息量大,难度高。
熵不是衡量某个具体事件,而是整个系统的事件,一个系统的从不确定到确定难度有多大
它们都是衡量难度,单位也可以一样都是比特。
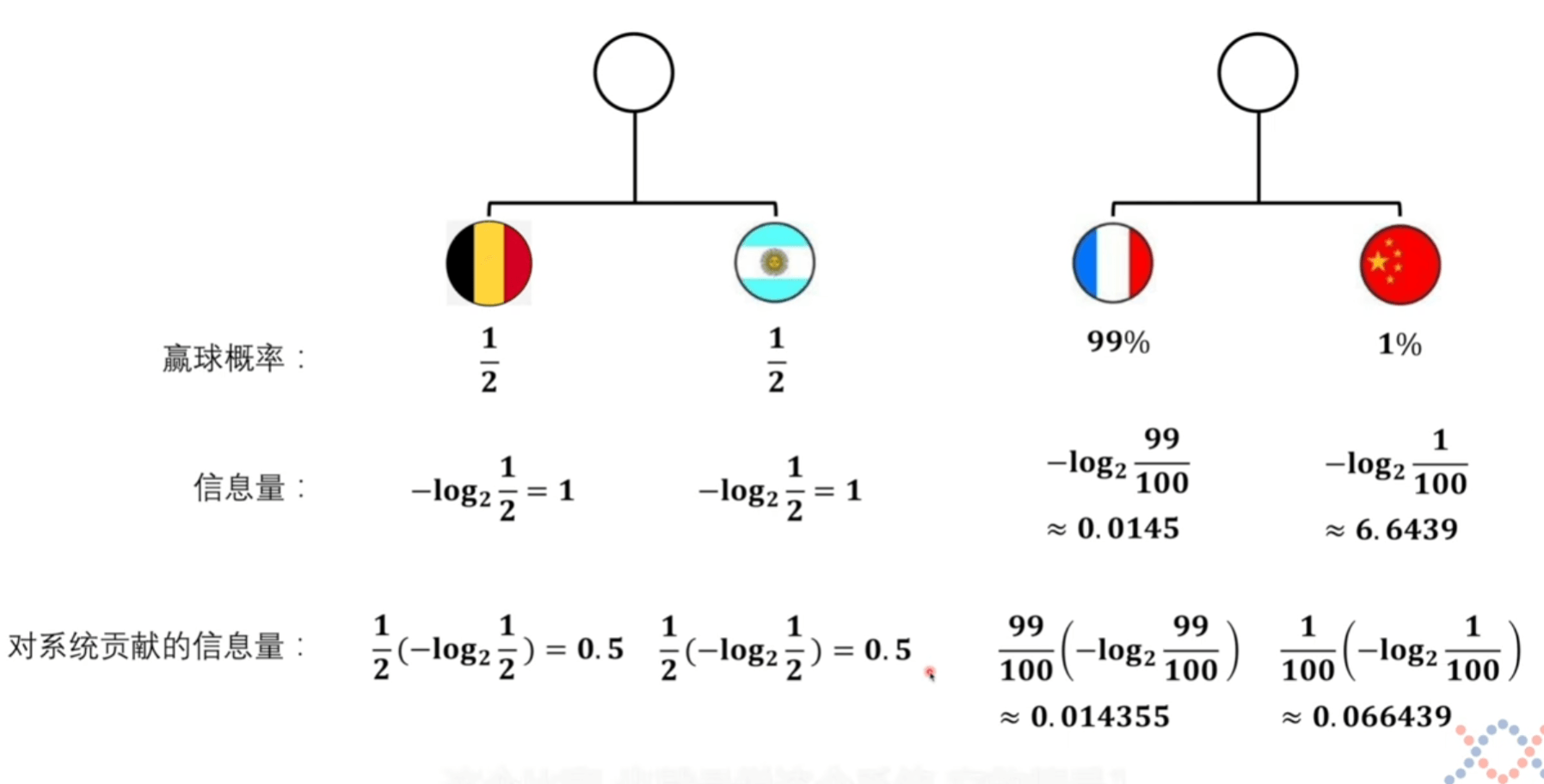
系统熵的定义
将上方对系统贡献的信息量可以看成是期望的计算。
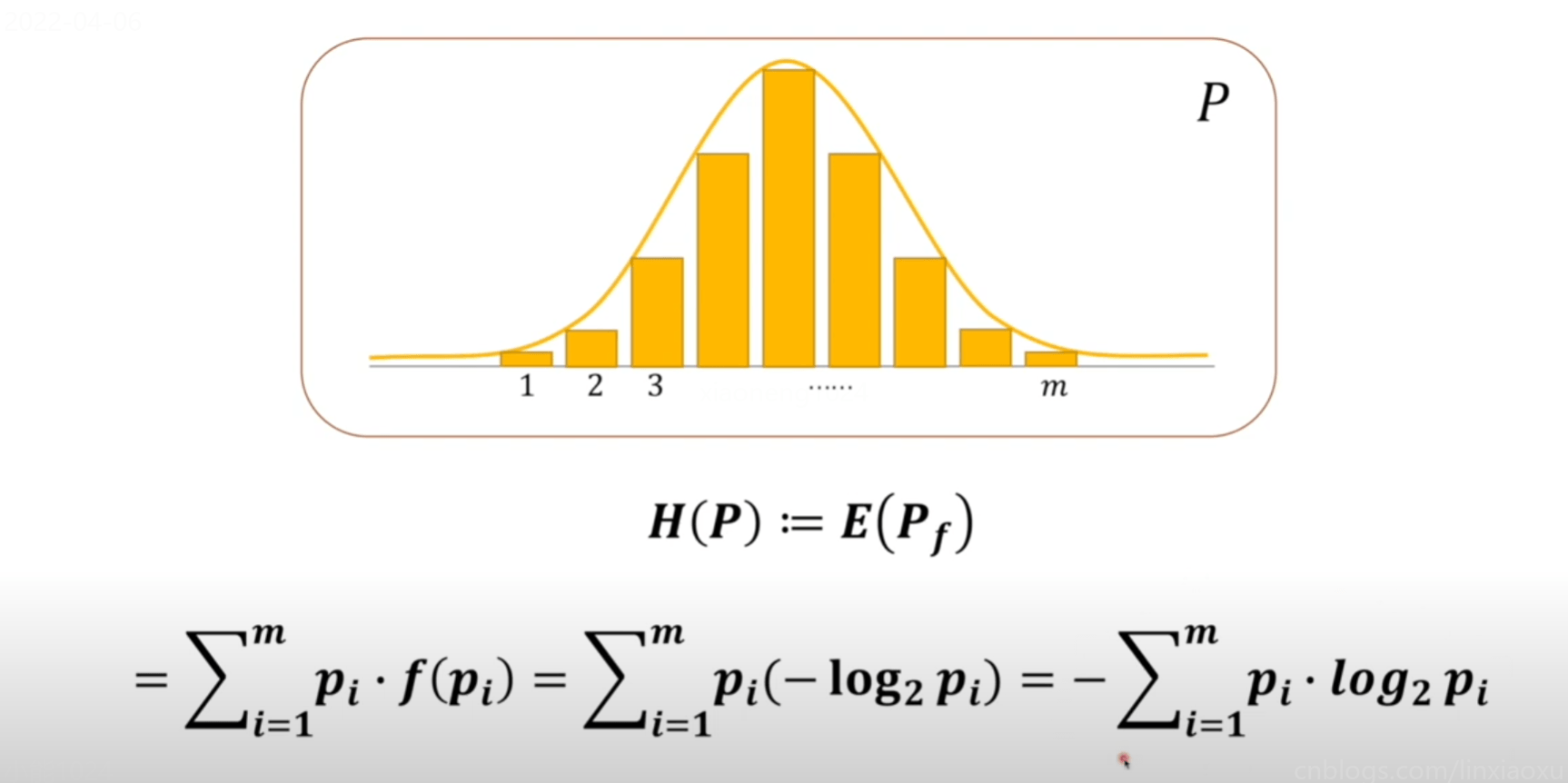
KL散度
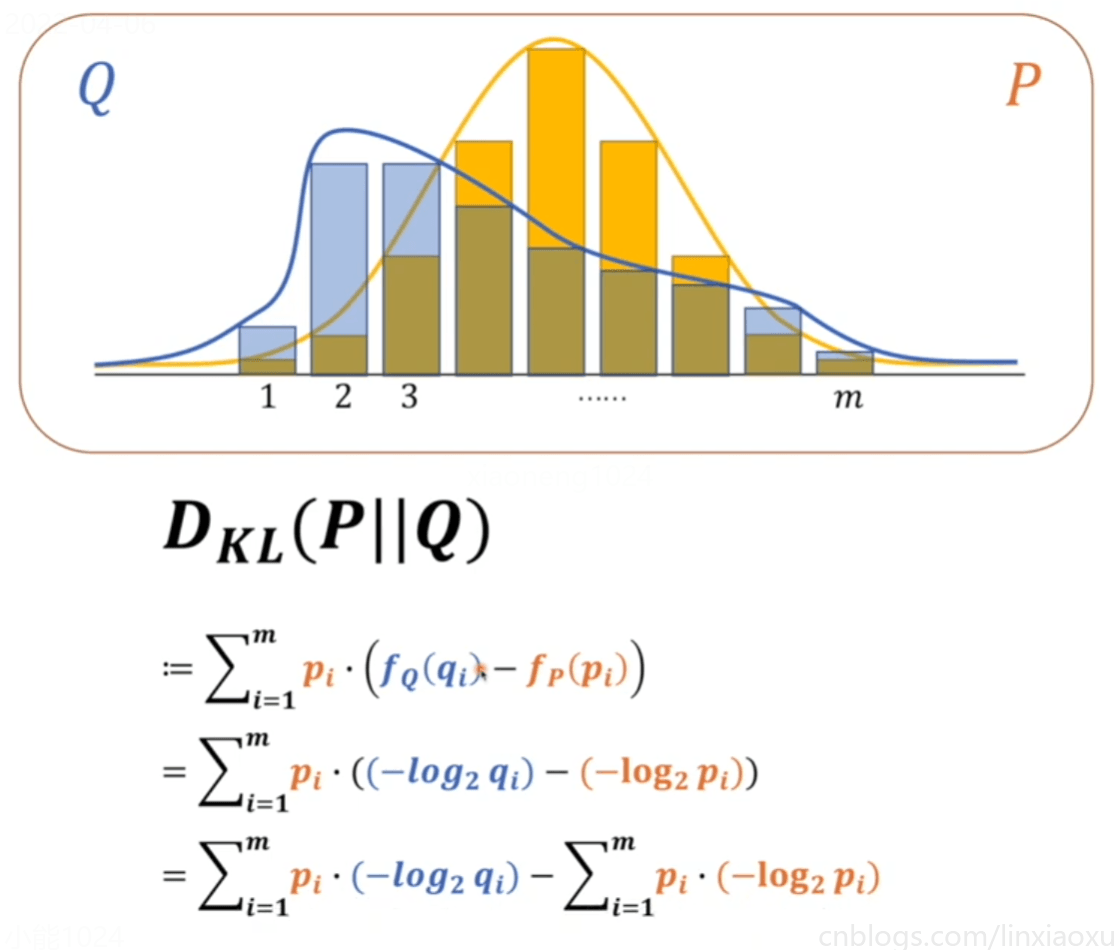

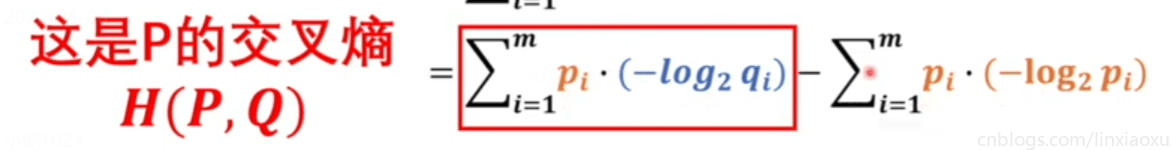
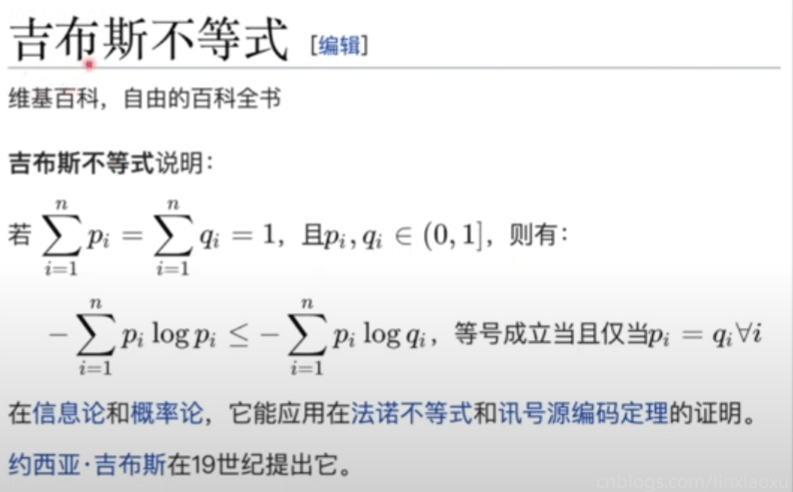
KL散度绝对是大于等于\(0\)的,当\(Q、P\)相等的时候等于\(0\),不相等的时候一定大于\(0\)
为了让\(Q、P\)两个模型接近,所以必须使交叉熵最小
交叉熵中 \(m\) 是两个概率模型里事件更多的那个,换成 \(n\) 是图片数量。
对\(m\)选择的解释:假如\(p\)的事件数量是\(m\),\(q\)的事件数量是\(n\),\(m>n\),那么写成\(∑\)求和,用较大的\(m\)做上标。就可以分解为,\(∑1到n+∑n+1到m\),那么对于\(q\)来说,因为\(q\)的数量只有\(n\),那么对应的\(q\)的部分\(∑n+1到m\)都等于\(0\)。
\(P\) 是基准,要被比较的概率模型,我们要比较的人脑模型,要么完全是猫要么不是猫。
\(x_{i}\) 有两种情况,而 \(y_{i}\) 只判断图片有多像猫,并没有去判断相反的这个猫有多不像猫,而公式里的 \(x_{i}\) 与 \(q_{i}\) 要对应起来,当 \(x_{i}\) 为 \(1\) ,要判断多像猫,当 \(x_{i}\) 为 \(0\) 的时候,要判断不像猫的概率。
最后我们推导出来,公式跟极大似然推导出来的是一样的。但是从物理角度去看两者是有很大不同的,只是形式上的一样。
- 极大似然法里的 \(log\) 使我们按习惯引入的,把连乘换成相加。而交叉熵的 \(log\) 是写在信息量定义里的,以 \(2\) 为底,计算出来的单位是比特,是有量纲的。
- 极大似然法求的是最大值,我们按习惯求最小值。而交叉熵负号是写在定义里的。
Machine Learning 学习笔记 03 最小二乘法、极大似然法、交叉熵的更多相关文章
- [Machine Learning]学习笔记-Logistic Regression
[Machine Learning]学习笔记-Logistic Regression 模型-二分类任务 Logistic regression,亦称logtic regression,翻译为" ...
- Machine Learning 学习笔记
点击标题可转到相关博客. 博客专栏:机器学习 PDF 文档下载地址:Machine Learning 学习笔记 机器学习 scikit-learn 图谱 人脸表情识别常用的几个数据库 机器学习 F1- ...
- Coursera 机器学习 第6章(上) Advice for Applying Machine Learning 学习笔记
这章的内容对于设计分析假设性能有很大的帮助,如果运用的好,将会节省实验者大量时间. Machine Learning System Design6.1 Evaluating a Learning Al ...
- [Python & Machine Learning] 学习笔记之scikit-learn机器学习库
1. scikit-learn介绍 scikit-learn是Python的一个开源机器学习模块,它建立在NumPy,SciPy和matplotlib模块之上.值得一提的是,scikit-learn最 ...
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- machine learning学习笔记
看到Max Welling教授主页上有不少学习notes,收藏一下吧,其最近出版了一本书呢还,还没看过. http://www.ics.uci.edu/~welling/classnotes/clas ...
- Machine Learning 学习笔记 01 Typora、配置OSS、导论
Typora 安装与使用. Typora插件. OSS图床配置. 机器学习导论. 机器学习的基本思路. 机器学习实操的7个步骤
- [Machine Learning]学习笔记-线性回归
模型 假定有i组输入输出数据.输入变量可以用\(x^i\)表示,输出变量可以用\(y^i\)表示,一对\(\{x^i,y^i\}\)名为训练样本(training example),它们的集合则名为训 ...
- 吴恩达Machine Learning学习笔记(一)
机器学习的定义 A computer program is said to learn from experience E with respect to some class of tasks T ...
随机推荐
- Windows 7/8 64位系统 不能注册32位dll 文件的解决方案
这几天碰到一个问题,运行一个易语言开发的软件出现以下错误.我的系统是 Windows7 64 位 专业版.在系统盘 windows/system32 下查找 dm.dll.但是没有这个文件.于是我到 ...
- 3、Lambda表达式
Lambda表达式 Lambda表达式(lambda expression),是一种匿名函数,即没有函数名的函数. Lambda表达式不仅在C#中使用,在Java.Phtyon.C++ 中都有使用. ...
- java反射笔记(学习尚硅谷java基础教程)
反射一.概述:Reflection Reflection(反射)是被视为动态语言的关键,反射机制允许程序在执行期借助于Reflection API取得任何类的内部信息,并能直接操作任意对象的内部属性 ...
- grafana初级入门
grafana初级入门 预备知识 Metrics.Tracing和Logging的区别 监控.链路追踪及日志作为实时监测系统运行状况,这三个领域都有对应的工具和解决方案. Metrics 监控指标的定 ...
- MVCC多版本并发控制
MVCC多版本并发控制 爱情小傻蛋关注 82019.09.28 23:23:37字数 4,740阅读 91,421 前提概要 什么是MVCC 什么是当前读和快照读? 当前读,快照读和MVCC的关系 M ...
- leedcode算法分类
- Java锁之乐观锁、悲观锁、自旋锁
java锁分为三大类乐观锁.悲观锁.自旋锁 乐观锁:乐观锁是一种乐观思想,即认为读多写少,遇到并发写的可能性低,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别 ...
- @Qualifier 注解?
当有多个相同类型的bean却只有一个需要自动装配时,将@Qualifier 注解和@Autowire 注解结合使用以消除这种混淆,指定需要装配的确切的bean. Spring数据访问
- java的jsr303校验
因为是菜鸡,所以就还没有具体了解jsr303具体是什么 JSR是Java Specification Requests的缩写,意思是Java 规范提案.是指向JCP(Java Community Pr ...
- java-属性集properties+加载配置文件
简介 /* 使用properties集合存储数据,遍历取出properties集合中的数据 properties集合有一些操作字符串的特有方法 Object setProperty(String ke ...