xml转voc数据集(含分享数据集)
数据集的链接:行人检测数据集voc数据集(100张)
原始图片和.xml数据目录结构如下:
.
└── data
├── 003002_0.jpg
├── 003002_0.xml
├── 003002_1.jpg
├── 003002_1.xml
├── 003008_1.jpg
├── 003008_1.xml
└── .......
└── xml2voc2007.py
- data目录下就是你的数据集原始图片,加上标注的.xml文件。
- xml2voc2007.py源码放到这篇文章的最后边。
在labelme2coco.py文件的目录下,打开命令行执行:
python xml2voc2007.py --input_dir data --output_dir VOCdevkit
- --input_dir:指定data文件夹,默认输入为xml2voc2007.py同级目录下的data文件夹。
- --output_dir:指定你的输出文件夹,默认输出为xml2voc2007.py同级目录下的VOCdevkit文件夹(没有的话就会创建)。
执行结果如下图:
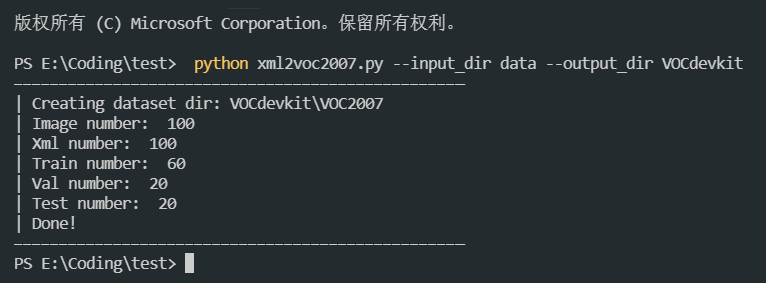
生成的voc数据集目录结构如下:
.
└── VOCdevkit
└── VOC2007
├── Annotations
│ ├── 003002_0.xml
│ ├── 003002_1.xml
│ ├── 003008_1.xml
│ └── .......
├── ImageSets
│ └── Main
│ ├── test.txt
│ ├── train.txt
│ ├── trainval.txt
│ └── val.txt
└── JPEGImages
├── 003002_0.jpg
├── 003002_1.jpg
├── 003008_1.jpg
└──.......
如果想调整训练集验证集的比例,可以在labelme2coco.py源码中搜索 percent_trainval (训练集和验证集在总数中的占比),percent_train,(训练集在percent_trainval中的占比)
xml2voc2007.py源码:
# 命令行执行: python xml2voc2007.py --input_dir data --output_dir VOCdevkit
import argparse
import glob
import os
import random
import os.path as osp
import sys
import shutil
percent_train = 0.9
# 主程序执行
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("--input_dir", default="data", help="input annotated directory")
parser.add_argument("--output_dir", default="VOCdevkit", help="output dataset directory")
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
print("| Creating dataset dir:", osp.join(args.output_dir, "VOC2007"))
# 创建保存的文件夹
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "Annotations")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "Annotations"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "ImageSets", "Main"))
if not os.path.exists(osp.join(args.output_dir, "VOC2007", "JPEGImages")):
os.makedirs(osp.join(args.output_dir, "VOC2007", "JPEGImages"))
# 获取目录下所有的.jpg文件列表
total_img = glob.glob(osp.join(args.input_dir, "*.jpg"))
print('| Image number: ', len(total_img))
# 获取目录下所有的joson文件列表
total_xml = glob.glob(osp.join(args.input_dir, "*.xml"))
print('| Xml number: ', len(total_xml))
num_total = len(total_xml)
data_list = range(num_total)
num_tr = int(num_total * percent_train)
num_train = random.sample(data_list, num_tr)
print('| Train number: ', num_tr)
print('| Val number: ', num_total - num_tr)
file_train = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "train.txt"), 'w')
file_val = open(
osp.join(args.output_dir, "VOC2007", "ImageSets", "Main", "val.txt"), 'w')
for i in data_list:
name = total_xml[i][:-4] + '\n'
if i in num_train:
file_train.write(name[5:])
else:
file_val.write(name[5:])
file_train.close()
file_val.close()
if os.path.exists(args.input_dir):
# root 所指的是当前正在遍历的这个文件夹的本身的地址
# dirs 是一个 list,内容是该文件夹中所有的目录的名字(不包括子目录)
# files 同样是 list, 内容是该文件夹中所有的文件(不包括子目录)
for root, dirs, files in os.walk(args.input_dir):
for file in files:
src_file = osp.join(root, file)
if src_file.endswith(".jpg"):
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "JPEGImages"))
else:
shutil.copy(src_file, osp.join(args.output_dir, "VOC2007", "Annotations"))
print('| Done!')
if __name__ == "__main__":
print("—" * 50)
main()
print("—" * 50)
xml转voc数据集(含分享数据集)的更多相关文章
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- 机器学习数据集,主数据集不能通过,人脸数据集介绍,从r包中获取数据集,中国河流数据集
机器学习数据集,主数据集不能通过,人脸数据集介绍,从r包中获取数据集,中国河流数据集 选自Microsoft www.tz365.Cn 作者:Lee Scott 机器之心编译 参与:李亚洲.吴攀. ...
- mnist数据集下载——mnist数据集提供百度网盘下载地址
mnist数据集是由深度学习大神 LeCun等人制作完成的数据集,mnist数据集也常认为是深度学习的“ Hello World!”. 官网:http://yann.lecun.com/exdb/mn ...
- 【Python图像特征的音乐序列生成】关于数据集的分享和样例数据
数据集还在制作中,样例数据如下: 我将一条数据作为一行,X是ID,O代表了情感向量,S是速度,是一个很关键的参数,K是调式,M是节拍,L是基本拍.后面是ABC格式的序列,通过embedding化这些音 ...
- 数据集 —— ground truth 数据集
1. matlab 自带含 ground truth 数据集 %% 加载停车标志数据到内存: data = load('stopSignsAndCars.mat', 'stopSignsAndCars ...
- R语言重要数据集分析研究—— 数据集本身的分析技巧
数据集本身的分析技巧 作者:王立敏 文章来源:网络 1.数据集 数据集,又称为资料集.数据集合或资料集合,是一种由数据所组成的集合. Data set(或dat ...
- 将TUM数据集的RGB-D数据集转化为klg格式
1.在github上下载代码png_to_klg git clone https://github.com/HTLife/png_to_klg 2.将png_to_klg目录下的associate.p ...
- XML的相关基础知识分享
XML和Json是两种最常用的在网络中数据传输的数据序列化格式,随着时代的变迁,XML序列化用于网络传输也逐渐被Json取代,前几天,单位系统集成开发对接接口时,发现大部分都用的WebService技 ...
- XML的相关基础知识分享(二)
前面我们讲了一下XML相关的基础知识(一),下面我们在加深一下,看一下XML高级方面. 一.命名空间 1.命名冲突 XML命名空间提供避免元素冲突的方法. 命名冲突:在XML中,元素名称是由开发者定义 ...
- 【猫狗数据集】pytorch训练猫狗数据集之创建数据集
猫狗数据集的分为训练集25000张,在训练集中猫和狗的图像是混在一起的,pytorch读取数据集有两种方式,第一种方式是将不同类别的图片放于其对应的类文件夹中,另一种是实现读取数据集类,该类继承tor ...
随机推荐
- Android系统瘦身
文件格式: Windows常见的文件系统是FAT16.FAT32,NTFS,在Windows环境提供了分区格式转换工具,可以在DOC环境下 使用 Convert命令(Convert e:/fs:nt ...
- [笔记]git pull vs git pull --rebase
git pull vs git pull -rebase 背景 最近在实际开发过程,之前一直使用git pull 去更新该分支的代码,之前认为一旦pull 操作产生新的节点是对合并操作的一个记录,但是 ...
- 基于恒玄WT250芯片的蓝牙辅听耳机方案调试总结
前记 在蓝牙辅听领域卷了几年之后.各种型号的蓝牙辅听器都做过.这次,客户需要一款性价比超高的蓝牙辅听器.经过成本以及功能考量的筛选.最终定下来使用wt250来做一款低成本的蓝牙辅听器. 硬件部分 wt ...
- 基于Apollo3-Blue-MCU的智能手表方案源码解析
一 方案简介 1.简介 Apollo3 Blue Wireless SoC是一款超低功耗无线mcu芯片,它的运行功耗降至6μA/ MHz以下.该器件采用ARM Cortex M4F内核,运行频率高达9 ...
- sqlplus清屏方法
cmd中使用:host cls 或 clear screen或 clear scre或clea scr
- vue开发小技巧
这里分享几个我使用到的vue开发小技巧 一.状态共享 使用Vue进行开发时,随着项目的复杂化,组件个数也逐渐增加,此时我们就面临着一个问题--多组件状态共享.当然有人会说使用Vuex来解决啊,但是如果 ...
- 记录--九个超级好用的 Javascript 技巧
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 在实际的开发工作过程中,积累了一些常见又超级好用的 Javascript 技巧和代码片段,包括整理的其他大神的 JS 使用技巧,今天 ...
- vue核心基础-过渡动画
第一种方法:引入类名 .v-enter{ opacity: 0; } .v-enter-to{ opacity: 1; } .v-leave{ opacity: 1; } .v-leave-to{ o ...
- 【论文项目复现1】漏洞检测项目复现_VulDeeLocator
复现环境 Ubuntu 20.04 CPU: 32G GPU: 11G 2080ti Source2slice: clang-6.0 + llvm + dg (dg: https://github.c ...
- elasticsearch 增删查改
#分词验证 POST _analyze { "analyzer":"ik_max_word", "text":"elasticse ...