CTR预估系列模型漫谈
FM
FM的主要内容
了解fm模型之前,需要先说一下lr带入一下场景。lr作为早期ctr预估里面的模型,其速度上有着无可比拟的优势,而偏偏ctr场景下伴随着有大量的离散特征,高维稀疏特征,这个很适合lr的场景。
lr整个模型可以被描述为一个公式:
\]
lr的特点就是简单高效速度快可解释性强,但是他有什么问题呢?lr需要依赖大量的人工特征,所以后面伴随lr适合离散特征的特点,facebook出了一版模型就是通过gbdt+lr的策略,数据过一遍gbdt拿到叶子节点的index作为特征丢到lr里面,这是题外话了。我们做特征的时候,做一些特征组合往往是有效的,比如说点击量和购买量,把这两个特征相除得到一个转化率的特征往往能够提升模型预测购买与否的精度,那么能否将特征组合的能力体现在模型层面呢?于是就出现了lr模型的改进:加入组合特征
\]
将任意两个特征进行组合,可以将这个组合出的特征看作一个新特征,融入线性模型中。而组合特征的权重可以用来表示,和一阶特征权重一样,这个组合特征权重在训练阶段学习获得。其实这种二阶特征组合的使用方式,和多项式核SVM是等价的。虽然这个模型看上去貌似解决了二阶特征组合问题了,但是它有个潜在的问题:它对组合特征建模,泛化能力比较弱,尤其是在大规模稀疏特征存在的场景下,这个毛病尤其突出,因为当我被组合的两个特征不同时存在,意思就是大家都是0的时候,那么这样组合导致的该组合项的权重就是0,这样是没有意义的,而恰好,ctr场景下,大规模稀疏特征带来的这种问题很多。这时候,fm就上场了,为了解决刚刚说到的这个问题,fm为每个特征引入了辅助向量:
\]
其中\(k\)是一个超参数,自己指定,代表这个隐向量的维度。FM对于每个特征,学习一个大小为\(k\)的一维向量,于是,两个特征 \(x_i\)和 \(x_j\)的特征组合的权重值,通过特征对应的向量 \(v_i\) 和 \(v_j\)的内积 \(<v_i,v_j>\)来表示

所以最后我们的fm模型可以表示为上图的形式,其主要贡献就是引入了辅助向量的概念。
这本质上是在对特征进行embedding化表征,和目前非常常见的各种实体embedding本质思想是一脉相承的,但是很明显在FM这么做的年代(2010年),还没有现在能看到的各种眼花缭乱的embedding的形式与概念。所以FM作为特征embedding,可以看作当前深度学习里各种embedding方法的老前辈。
具体的这个辅助向量的样子如下
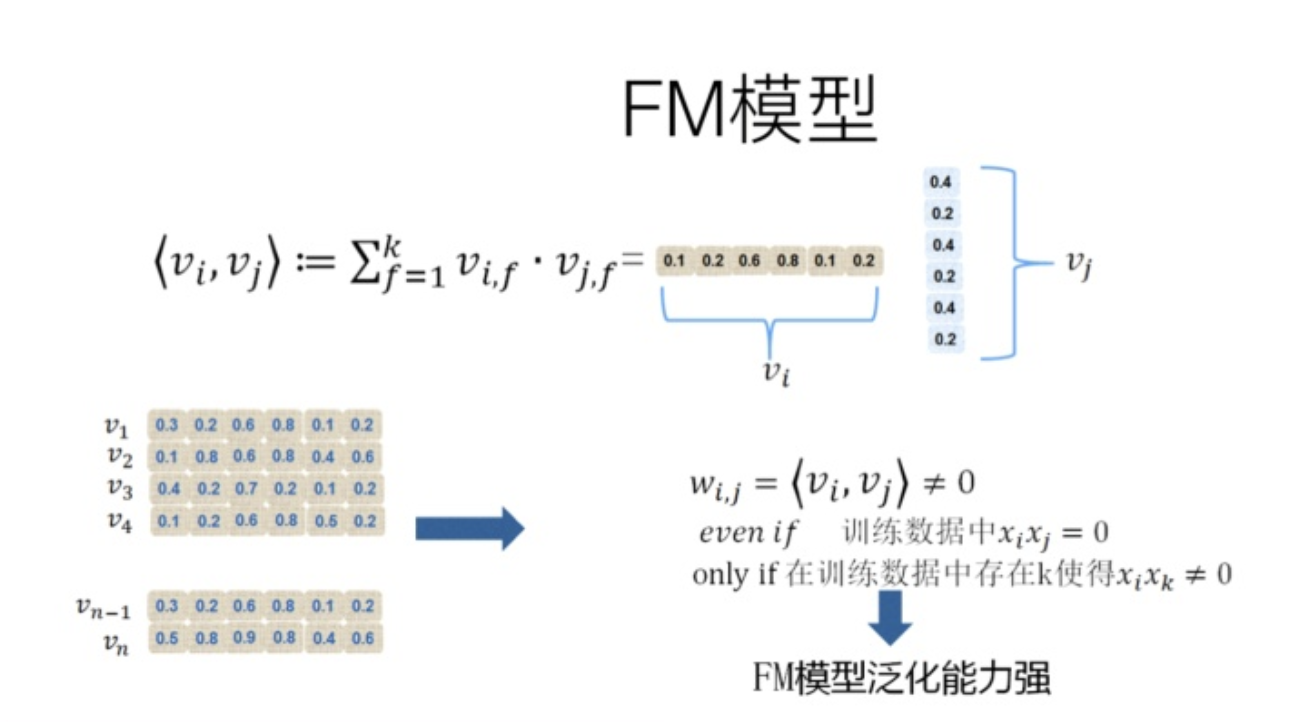
FM的这种特征embedding模式,在大规模稀疏特征应用环境下比较好用?为什么说它的泛化能力强呢?因为即使在训练数据里两个特征并未同时在训练实例里见到过,意味着 一起出现的次数为0,如果换做SVM的模式,是无法学会这个特征组合的权重的。但是因为FM是学习单个特征的embedding,并不依赖某个特定的特征组合是否出现过,所以只要某个特征和其它任意特征组合出现过,那么就可以学习自己对应的embedding向量。于是,尽管 这个特征组合没有看到过,但是在预测的时候,如果看到这个新的特征组合,因为被组合的两个特征都能学会自己对应的embedding,所以可以通过内积算出这个新特征组合的权重。这是为何说FM模型泛化能力强的根本原因。
其实本质上,这也是目前很多花样的embedding的最核心特点,就是从0/1这种二值硬核匹配,切换为向量软匹配,使得原先匹配不上的,现在能在一定程度上算密切程度了,具备很好的泛化性能。
化简的FM
如果按上述做法训练模型的话,其时间复杂度是很高的,大概是到\(O(kn^2)\)的一个程度,主要时间都消耗在做fm的过程上,那么化简一下:
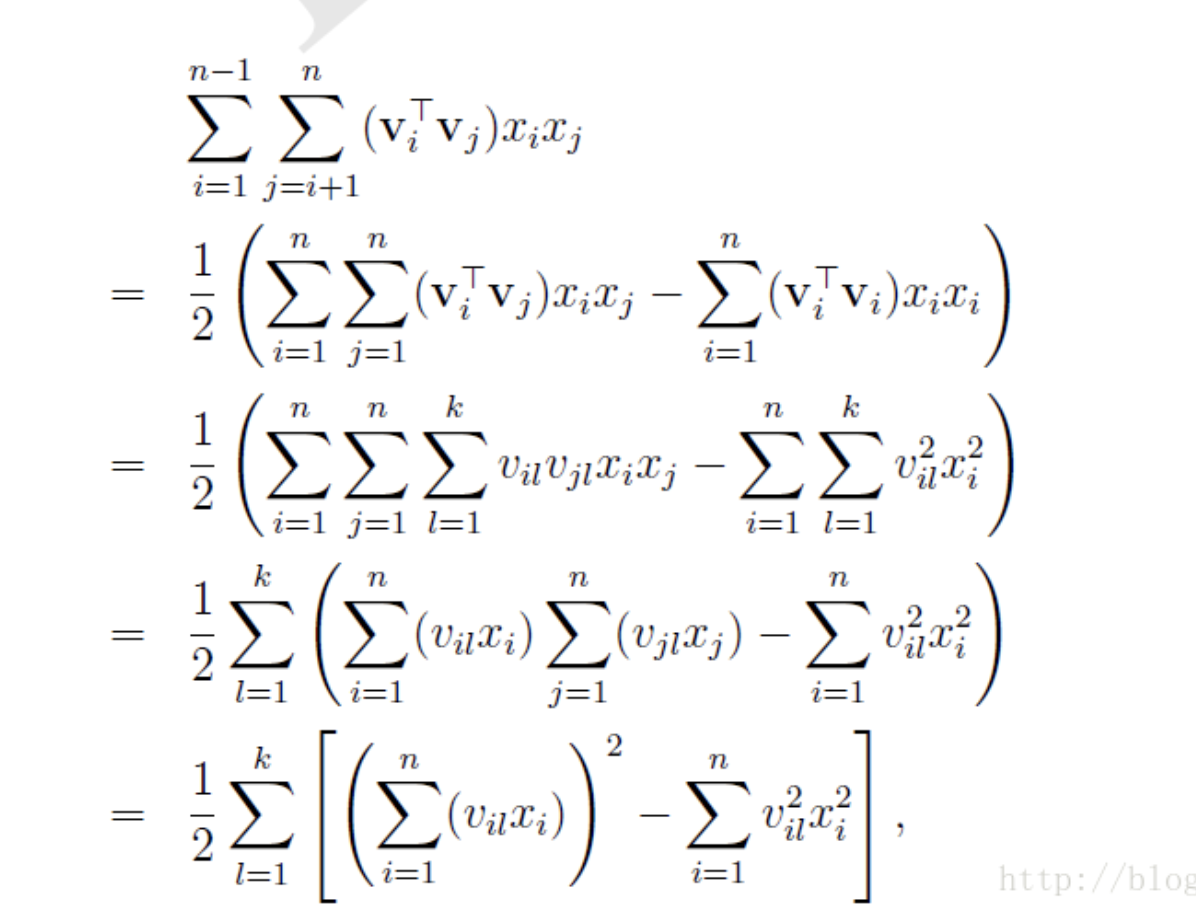
对于倒数第二步,其实\(i\)和\(j\)都是一样的,带入就会发现啊可以合并成一个平方项
就可以将这部分转化为 和的平方-平方的和 的形式
在DeepFM实现的过程中,一般都不显示写出隐向量\(V\),就是这里的\(v_{i,l}\),我们之间用embedding后的值来表示它们,毕竟通常的embedding本质上也是一个单层的MLP,其输入\(x\)和权重\(w\)就可以表示
FM中的\(v*x\).
DeepFM
说到deepfm,其核心就是将deep和fm相融合。DeepFM模型包含FM和DNN两部分,FM模型可以抽取low-order特征,DNN可以抽取high-order特征
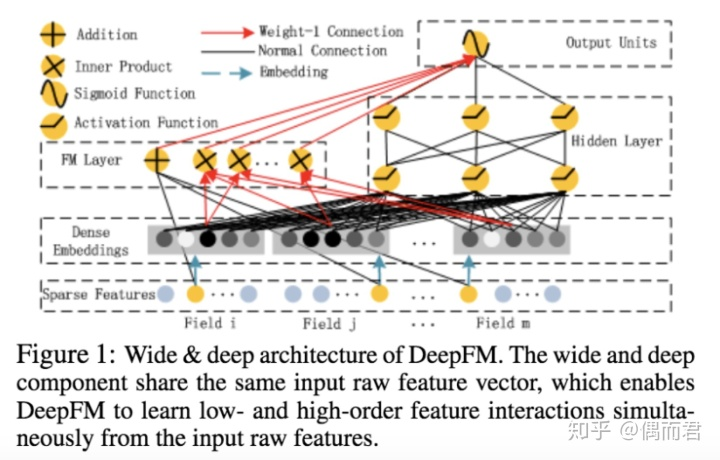
为了同时利用low-order和high-order特征,DeepFM包含FM和DNN两部分,两部分共享输入特征。对于特征i,标量wi是其1阶特征的权重,该特征和其他特征的交互影响用隐向量Vi来表示。Vi输入到FM模型获得特征的2阶表示,输入到DNN模型得到high-order高阶特征。模型联合训练,结果可表示为:
\]
的形式,deep就是一个dnn,而fm部分就是上面说到的fm模型。相比于原始的fm,deepfm会把离散的特征embedding到低维度,再分别输入fm和dnn拿到各自的输出,结合后得到最终的输出。embedding的时候,其实特征会被分成多个fileds。比如说类别特征,我们可以把他做one-hot出来得到更多的维度,这个特征包含的这些维度就是一个filed,比如说性别[0,1], 年龄段one-hot等
CTR预估系列模型漫谈的更多相关文章
- 计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践
计算广告CTR预估系列(七)--Facebook经典模型LR+GBDT理论与实践 2018年06月13日 16:38:11 轻春 阅读数 6004更多 分类专栏: 机器学习 机器学习荐货情报局 版 ...
- (读论文)推荐系统之ctr预估-DeepFM模型解析
今天第二篇(最近更新的都是Deep模型,传统的线性模型会后面找个时间更新的哈).本篇介绍华为的DeepFM模型 (2017年),此模型在 Wide&Deep 的基础上进行改进,成功解决了一些问 ...
- CTR预估经典模型总结
计算广告领域中数据特点: 1 正负样本不平衡 2 大量id类特征,高维,多领域(一个类别型特征就是一个field,比如上面的Weekday.Gender.City这是三个field),稀疏 ...
- (读论文)推荐系统之ctr预估-NFM模型解析
本系列的第六篇,一起读论文~ 本人才疏学浅,不足之处欢迎大家指出和交流. 今天要分享的是另一个Deep模型NFM(串行结构).NFM也是用FM+DNN来对问题建模的,相比于之前提到的Wide& ...
- 计算广告之CTR预估-FNN模型解析
原论文:Deep learning over multi-field categorical data 地址:https://arxiv.org/pdf/1601.02376.pdf 一.问题由来 基 ...
- 主流CTR预估模型的演化及对比
https://zhuanlan.zhihu.com/p/35465875 学习和预测用户的反馈对于个性化推荐.信息检索和在线广告等领域都有着极其重要的作用.在这些领域,用户的反馈行为包括点击.收藏. ...
- CTR预估的常用方法
1.CTR CTR预估是对每次广告的点击情况做出预测,预测用户是点击还是不点击. CTR预估和很多因素相关,比如历史点击率.广告位置.时间.用户等. CTR预估模型就是综合考虑各种因素.特征,在大量历 ...
- 【转】- 从FM推演各深度CTR预估模型(附代码)
从FM推演各深度CTR预估模型(附代码) 2018年07月13日 15:04:34 阅读数:584 作者: 龙心尘 && 寒小阳 时间:2018年7月 出处: 龙心尘 寒小阳
- 闲聊DNN CTR预估模型
原文:http://www.52cs.org/?p=1046 闲聊DNN CTR预估模型 Written by b manongb 作者:Kintocai, 北京大学硕士, 现就职于腾讯. 伦敦大学张 ...
- 深度CTR预估模型中的特征自动组合机制演化简史 zz
众所周知,深度学习在计算机视觉.语音识别.自然语言处理等领域最先取得突破并成为主流方法.但是,深度学习为什么是在这些领域而不是其他领域最先成功呢?我想一个原因就是图像.语音.文本数据在空间和时间上具有 ...
随机推荐
- 图查询语言 nGQL 简明教程 vol.01 快速入门
本文旨在让新手快速了解 nGQL,掌握方向,之后可以脚踩在地上借助文档写出任何心中的 NebulaGraph 图查询. 视频 本教程的视频版在B站这里. 准备工作 在正式开始 nGQL 实操之前,记得 ...
- Advanced .Net Debugging 3:基本调试任务(上)
一.简介 这是我的<Advanced .Net Debugging>这个系列的第三篇文章.这个系列的每篇文章写的周期都要很长,因为每篇文章都是原书的一章内容(太长的就会分开写).再者说,原 ...
- WebView无法加载页面报错 net:ERR_CLEARTEXT_NOT_PERMITTED 还有webView加载网页后出现ERR_UNKNOWN_URL_SCHEME
根据网络安全配置- 从Android 9(API级别28)开始,默认情况下禁用明文支持.因此http的url均无法在webview中加载 还可以看看-https: //koz.io/android-m ...
- kafka 工作流程及文件存储机制
1.kafka的数据存储 文件存储格式: .log 和 .index Kafka 中消息是以 topic 进行分类的, 生产者生产消息,消费者消费消息,都是面向 topic的. topic ...
- python3 Crypto模块实例解析
一 模块简介 1.简介 python的Crypto模块是安全hash函数(例如SHA256 和RIPEMD160)以及各种主流的加解密算法的((AES, DES, RSA, ElGamal等)的集合. ...
- Android Studio虚拟机文件默认C盘转移其他盘
原文地址:Android Studio虚拟机文件默认C盘转移其他盘 - Stars-One的杂货小窝 某天发现,新创建的Android13模拟器,把我C盘搞得只剩下9G了,于是折腾了下,把模拟器相关文 ...
- day09-数据格式化&验证以及国际化
数据格式化&验证以及国际化 1.数据格式化 1.1基本介绍 说明:在我们提交数据(比如表单时),SpringMVC 是怎样对提交的数据进行转换和处理的 基本数据类型可以和字符串之间自动进行转换 ...
- day07-Java方法01
Java方法01 1.什么是方法? Java是语句的集合,它们在一起执行一个功能 方法是解决一类问题的步骤的有序集合 方法包含于类或者对象中 方法在程序中被创建,在其他地方被引用 设计方法的原则:方法 ...
- 【Unity渲染】一文看懂!Unity通用渲染管线URP介绍
一.Unity通用渲染管线(URP) Unity 的渲染管线包含内置渲染管线.SRP.URP和HDRP.自从Unity2019.3开始,Unity将轻量级渲染管线修改为了通用渲染管线,这是一种快速.可 ...
- 三维模型3DTile格式轻量化压缩在移动智能终端应用方面的重要性分析
三维模型3DTile格式轻量化压缩在移动智能终端应用方面的重要性分析 随着移动智能终端设备的不断发展和普及,如智能手机.平板电脑等,以及5G网络技术的推广应用,使得在这些设备上频繁使用三维地理空间数据 ...