初识urllib与requests
urllib与requests
一、urllib的学习
学习目标
了解urllib的基本使用
1、urllib介绍
除了requests模块可以发送请求之外, urllib模块也可以实现请求的发送,只是操作方法略有不同!
urllib在python中分为urllib和urllib2,在python3中为urllib
下面以python3的urllib为例进行讲解
2、urllib的基本方法介绍
2.1 urllib.Request
构造简单请求
import urllib
#构造请求
request = urllib.request.Request("http://www.baidu.com")
#发送请求获取响应
response = urllib.request.urlopen(request)
传入headers参数
import urllib
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
传入data参数 实现发送post请求(示例)
import urllib.request
import urllib.parse
import json url = 'http://www.xinfadi.com.cn/getCat.html' headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.0 Safari/605.1.15', }
data = {
'prodCatid': 1187
}
# 使用post方式
# 需要
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url, data=data, headers=headers)
res = urllib.request.urlopen(req)
print(res.getcode())
print(res.geturl())
data = json.loads(res.read().decode('utf-8'))
print(data)
2.2 response.read()
获取响应的html字符串,bytes类型
#发送请求
response = urllib.request.urlopen("http://www.baidu.com")
#获取响应
response.read()
3、urllib请求百度首页的完整例子
import urllib
import json
url = 'http://www.baidu.com'
#构造headers
headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"}
#构造请求
request = urllib.request.Request(url, headers = headers)
#发送请求
response = urllib.request.urlopen(request)
#获取html字符串
html_str = response.read().decode('utf-8')
print(html_str)
4、小结
- urllib.request中实现了构造请求和发送请求的方法
- urllib.request.Request(url,headers,data)能够构造请求
- urllib.request.urlopen能够接受request请求或者url地址发送请求,获取响应
- response.read()能够实现获取响应中的bytes字符串
requests模块的入门使用
一、requests模块的入门使用
学习目标:
- 了解 requests模块的介绍
- 掌握 requests的基本使用
- 掌握 response常见的属性
- 掌握 requests.text和content的区别
- 掌握 解决网页的解码问题
- 掌握 requests模块发送带headers的请求
- 掌握 requests模块发送带参数的get请求和携带表单的post请求
1、为什么要重点学习requests模块,而不是urllib
- 企业中用的最多的就是requests
- requests的底层实现就是urllib
- requests在python2 和python3中通用,方法完全一样
- requests简单易用
2、requests的作用与安装
作用:发送网络请求,返回响应数据
安装:pip install requests
你如果--upgrade更新了requests 你的urllib3这个库会更新 pip install -U "urllib3<1.25"
3、requests模块发送简单的get请求、获取响应
需求:通过requests向百度首页发送请求,获取小说网站的数据
import requests
# 目标url
url = 'https://www.readnovel.com/category'
# 向目标url发送get请求
response = requests.get(url)
# 打印响应内容
print(response.text)
response的常用属性:
response.text响应体 str类型response.encoding从HTTP header中猜测的响应内容的编码方式respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.cookies响应的cookie(经过了set-cookie动作)response.url获取访问的urlresponse.json()获取json数据 得到内容为字典 (如果接口响应体的格式是json格式时)response.ok如果status_code小于200,response.ok返回True。
如果status_code大于200,response.ok返回False。
思考:text是response的属性还是方法呢?
- 一般来说名词,往往都是对象的属性,对应的动词是对象的方法
3.1 response.text 和response.content的区别
response.text- 类型:str
- 解码类型: requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 如何修改编码方式:
response.encoding="gbk/UTF-8"
response.content- 类型:bytes
- 解码类型: 没有指定
- 如何修改编码方式:
response.content.deocde("utf8")
获取网页源码的通用方式:
response.content.decode()response.content.decode("UTF-8")response.text
以上三种方法从前往后尝试,能够100%的解决所有网页解码的问题
所以:更推荐使用response.content.deocde()的方式获取响应的html页面
3.2 练习:把网络上的图片保存到本地
我们来把
www.baidu.com的图片保存到本地
思考:
- 以什么方式打开文件
- 保存什么格式的内容
分析:
- 图片的url: https://www.baidu.com/img/bd_logo1.png
- 利用requests模块发送请求获取响应
- 以2进制写入的方式打开文件,并将response响应的二进制内容写入
{kind=link}
import requests
# 图片的url
url = 'https://www.baidu.com/img/bd_logo1.png'
# 响应本身就是一个图片,并且是二进制类型
response = requests.get(url)
# print(response.content)
# 以二进制+写入的方式打开文件
with open('baidu.png', 'wb') as f:
# 写入response.content bytes二进制类型
f.write(response.content)
4、发送带header的请求
我们先写一个获取百度首页的代码
import requests
url = 'https://www.baidu.com'
response = requests.get(url)
print(response.content)
# 打印响应对应请求的请求头信息
print(response.request.headers)
4.1 思考
对比浏览器上百度首页的网页源码和代码中的百度首页的源码,有什么不同?
代码中的百度首页的源码非常少,为什么?
4.2 为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
4.3 header的形式:字典
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
4.4 用法
requests.get(url, headers=headers)
4.5 完整的代码
import requests
url = 'https://www.baidu.com'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 在请求头中带上User-Agent,模拟浏览器发送请求
response = requests.get(url, headers=headers)
# print(response.content)
# 打印请求头信息
print(response.request.headers)
5、发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
5.1 什么叫做请求参数:
例1: http://www.webkaka.com/tutorial/server/2015/021013/
例2:https://www.baidu.com/s?wd=python&a=c
例1中没有请求参数!例2中?后边的就是请求参数
5.2 请求参数的形式:字典
kw = {'wd':'长城'}
5.3 请求参数的用法
requests.get(url,params=kw)
5.4 关于参数的注意点
在url地址中, 很多参数是没有用的,比如百度搜索的url地址,其中参数只有一个字段有用,其他的都可以删除 如何确定那些请求参数有用或者没用:挨个尝试! 对应的,在后续的爬虫中,越到很多参数的url地址,都可以尝试删除参数
5.5 两种方式:发送带参数的请求
对
http://www.zishazx.com/product?page=1&size_id=0&volum_id=0&price_id=0&category_id=1001&prize_id=0&pug_id=0发起请求可以使用requests.get(url, params=kw)的方式# 方式一:利用params参数发送带参数的请求
import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 这是目标url
# url = 'http://www.zishazx.com/product?page=1&size_id=0&volum_id=0&price_id=0&category_id=1001&prize_id=0&pug_id=0' # 最后有没有问号结果都一样
url = 'http://www.zishazx.com/product?' # 请求参数是一个字典 即wd=python
kw = {
"page": "1",
"size_id": "0",
"volum_id": "0",
"price_id": "0",
"category_id": "1001",
"prize_id": "0",
"pug_id": "0"
} # 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw) # 当有多个请求参数时,requests接收的params参数为多个键值对的字典,比如 '?page=1&size_id=0&volum_id=0&price_id=0&category_id=1001&prize_id=0&pug_id=0'-->
{
"page": "1",
"size_id": "0",
"volum_id": "0",
"price_id": "0",
"category_id": "1001",
"prize_id": "0",
"pug_id": "0"
}
print(response.text)
也可以直接对
http://www.zishazx.com/product?page=1&size_id=0&volum_id=0&price_id=0&category_id=1001&prize_id=0&pug_id=0完整的url直接发送请求,不使用params参数# 方式二:直接发送带参数的url的请求
import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} url = 'http://www.zishazx.com/product?page=1&size_id=0&volum_id=0&price_id=0&category_id=1001&prize_id=0&pug_id=0'
#
# kw = {
"page": "1",
"size_id": "0",
"volum_id": "0",
"price_id": "0",
"category_id": "1001",
"prize_id": "0",
"pug_id": "0"
} # url中包含了请求参数,所以此时无需params
response = requests.get(url, headers=headers)
6、小结
- requests模块的介绍:能够帮助我们发起请求获取响应
- requests的基本使用:
requests.get(url) - 以及response常见的属性:
response.text响应体 str类型respones.content响应体 bytes类型response.status_code响应状态码response.request.headers响应对应的请求头response.headers响应头response.request._cookies响应对应请求的cookieresponse.cookies响应的cookie(经过了set-cookie动作)
- 掌握 requests.text和content的区别:text返回str类型,content返回bytes类型
- 掌握 解决网页的解码问题:
response.content.decode()response.content.decode("UTF-8")response.text
- 掌握 requests模块发送带headers的请求:
requests.get(url, headers={}) - 掌握 requests模块发送带参数的get请求:
requests.get(url, params={})
二、requests模块的深入使用
学习目标:
- 能够应用requests发送post请求的方法
- 能够应用requests模块使用代理的方法
- 了解代理ip的分类
1、使用requests发送POST请求
思考:哪些地方我们会用到POST请求?
- 登录注册( POST 比 GET 更安全)
- 需要传输大文本内容的时候( POST 请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求
1.1 requests发送post请求语法:
用法:
response = requests.post("http://www.baidu.com/", data = data, headers=headers)
data 的形式:字典
1.2 POST请求练习
下面面我们通过新发地的例子看看post请求如何使用:
地址:http://www.xinfadi.com.cn/index.html
思路分析
- 抓包确定请求的url地址
- 确定请求的参数
- 确定返回数据的位置
- 模拟浏览器获取数据
import requests
import json headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
} url = "http://www.xinfadi.com.cn/getCat.html" data = {
"prodCatid": 1186
} res = requests.post(url, headers=headers, data=data)
# print(res.status_code) # 返回的是json字符串 需要在进行转换为字典
data = json.loads(response.content.decode('UTF-8'))
# print(type(data))
# print(data)
print(data['list'])
1.3 小结
在模拟登陆等场景,经常需要发送post请求,直接使用requests.post(url,data)即可
2、使用代理
2.1 为什么要使用代理
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
2.2 理解使用代理的过程
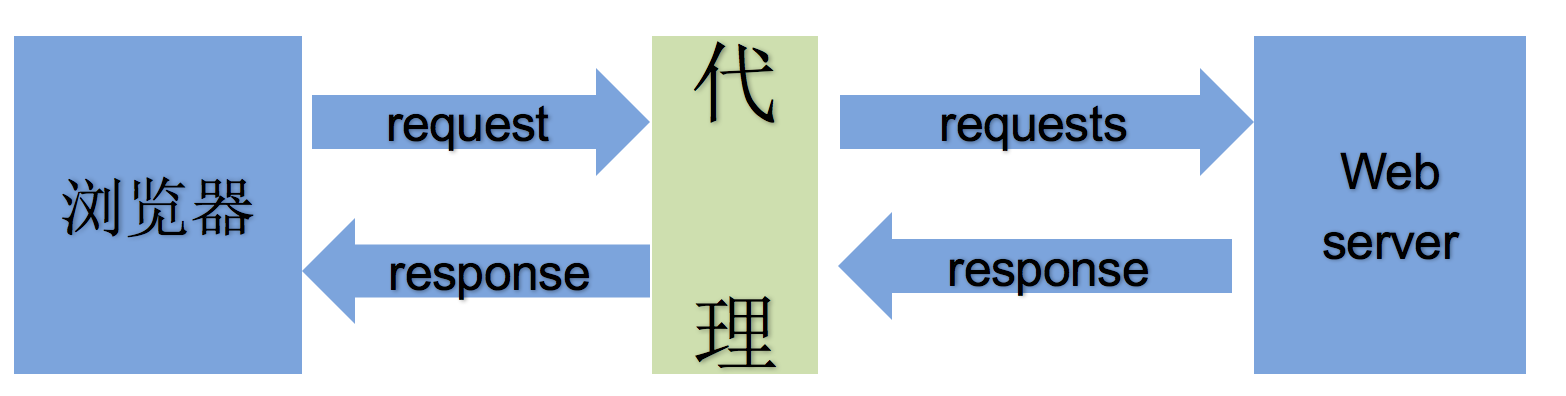
2.3 理解正向代理和反向代理的区别
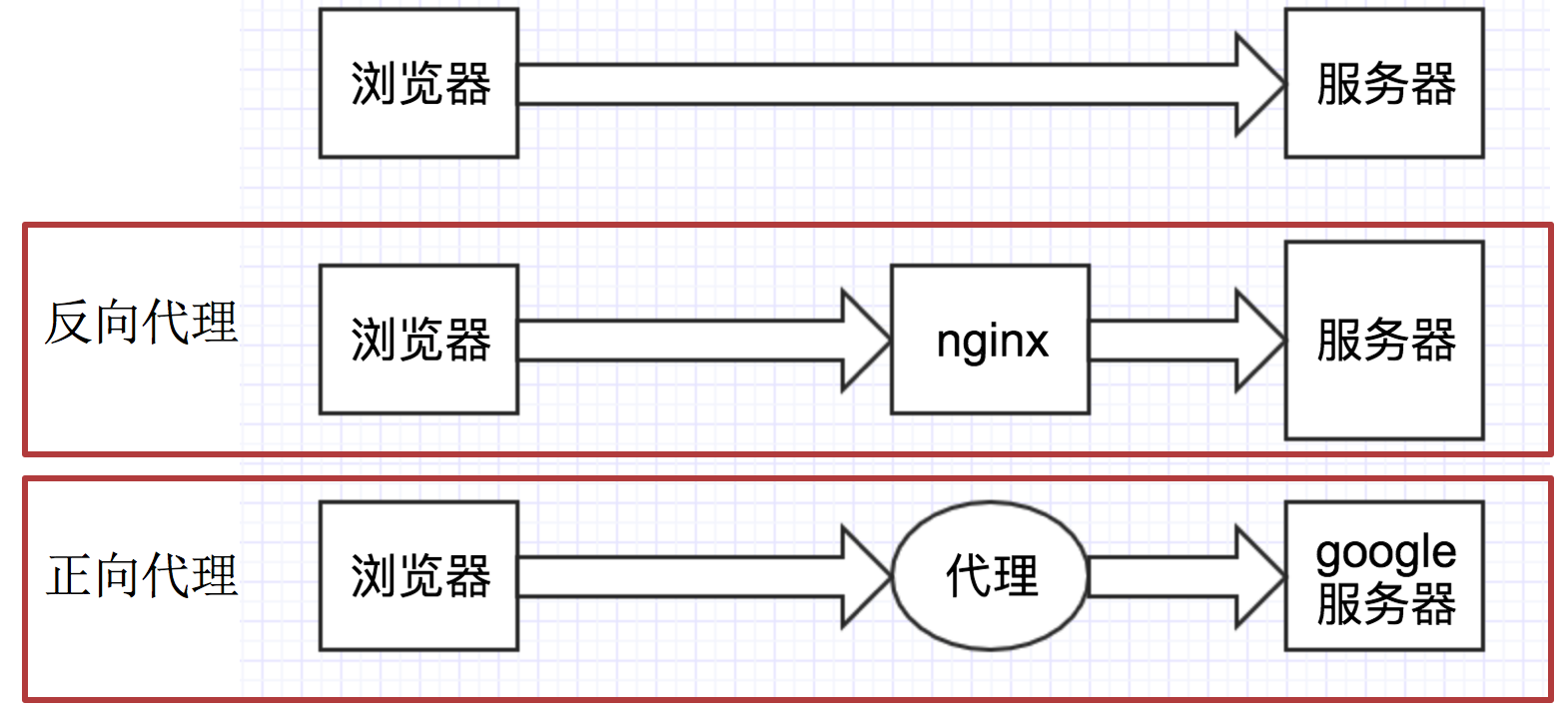
通过上图可以看出:
- 正向代理:对于浏览器知道服务器的真实地址,例如VPN
- 反向代理:浏览器不知道服务器的真实地址,例如nginx
详细讲解:
正向代理是客户端与正向代理客户端在同一局域网,客户端发出请求,正向代理 替代客户端向服务器发出请求。服务器不知道谁是真正的客户端,正向代理隐藏了真实的请求客户端。
反向代理:服务器与反向代理在同一个局域网,客服端发出请求,反向代理接收请求 ,反向代理服务器会把我们的请求分转发到真实提供服务的各台服务器Nginx就是性能非常好的反向代理服务器,用来做负载均衡
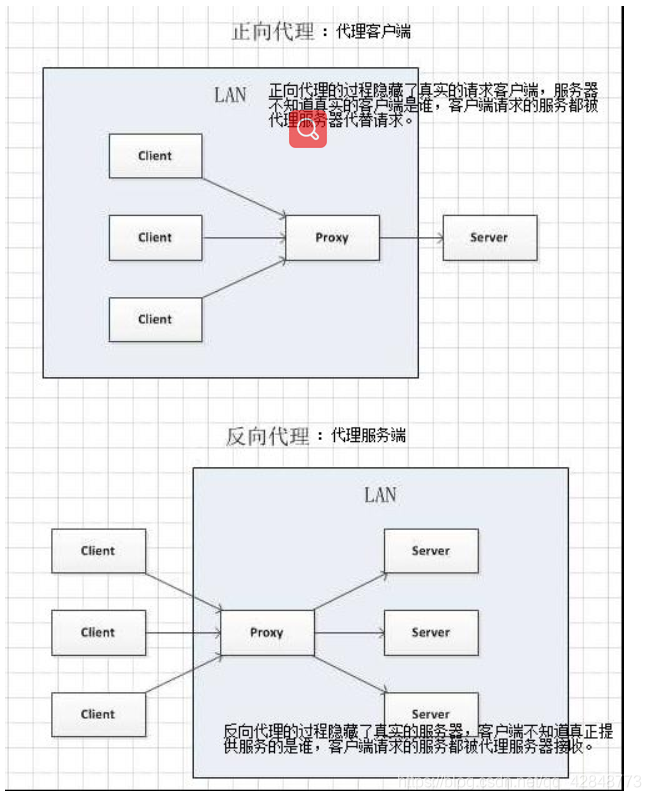
2.4 代理的使用
用法:
requests.get("http://www.baidu.com", proxies = proxies)
proxies的形式:字典
例如:
proxies = {
"http": "http://12.34.56.79:9527",
"https": "https://12.34.56.79:9527",
}
2.5 代理IP的分类
根据代理ip的匿名程度,代理IP可以分为下面四类:
- 透明代理(Transparent Proxy):透明代理的意思是客户端根本不需要知道有代理服务器的存在,但是它传送的仍然是真实的IP。使用透明代理时,对方服务器是可以知道你使用了代理的,并且他们也知道你的真实IP。你要想隐藏的话,不要用这个。透明代理为什么无法隐藏身份呢?因为他们将你的真实IP发送给了对方服务器,所以无法达到保护真实信息。
- 匿名代理(Anonymous Proxy):匿名代理隐藏了您的真实IP,但是向访问对象可以检测是使用代理服务器访问他们的。会改变我们的请求信息,服务器端有可能会认为我们使用了代理。不过使用此种代理时,虽然被访问的网站不能知道你的ip地址,但仍然可以知道你在使用代理,当然某些能够侦测ip的网页也是可以查到你的ip。(https://wenku.baidu.com/view/9bf7b5bd3a3567ec102de2bd960590c69fc3d8cf.html)
- 高匿代理(Elite proxy或High Anonymity Proxy):高匿名代理不改变客户机的请求,这样在服务器看来就像有个真正的客户浏览器在访问它,这时客户的真实IP是隐藏的,完全用代理服务器的信息替代了您的所有信息,就象您就是完全使用那台代理服务器直接访问对象,同时服务器端不会认为我们使用了代理。IPDIEA覆盖全球240+国家地区ip高匿名代理不必担心被追踪。
在使用的使用,毫无疑问使用高匿代理效果最好
从请求使用的协议可以分为:
- http代理
- https代理
- socket代理等
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择
2.6 代理IP使用的注意点
反反爬
使用代理ip是非常必要的一种
反反爬的方式但是即使使用了代理ip,对方服务器任然会有很多的方式来检测我们是否是一个爬虫,比如:
一段时间内,检测IP访问的频率,访问太多频繁会屏蔽
检查Cookie,User-Agent,Referer等header参数,若没有则屏蔽
服务方购买所有代理提供商,加入到反爬虫数据库里,若检测是代理则屏蔽
所以更好的方式在使用代理ip的时候使用随机的方式进行选择使用,不要每次都用一个代理ip
代理ip池的更新
购买的代理ip很多时候大部分(超过60%)可能都没办法使用,这个时候就需要通过程序去检测哪些可用,把不能用的删除掉。
代理服务器平台的使用:
当然还有很多免费的,但是大多都不可用需要自己尝试
3、配置
浏览器配置代理
右边三点==> 设置==> 高级==> 代理==> 局域网设置==> 为LAN使用代理==> 输入ip和端口号即可
参考网址:https://jingyan.baidu.com/article/a681b0dece76407a1843468d.html
代码配置
urllib
handler = urllib.request.ProxyHandler({'http': '114.215.95.188:3128'})
opener = urllib.request.build_opener(handler)
# 后续都使用opener.open方法去发送请求即可
requests
# 用到的库
import requests
# 写入获取到的ip地址到proxy
# 一个ip地址
proxy = {
'https':'https://221.178.232.130:8080'
}
"""
# 多个ip地址
proxy = [
{'https':'221.178.232.130:8080'},
{'https':'221.178.232.130:8080'}
]
import random
proxy = random.choice(proxy)
"""
# 用百度检测ip代理是否成功
url = 'https://www.baidu.com/s?'
# 请求网页传的参数
params={
'wd':'ip地址'
}
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
}
# 发送get请求
response = requests.get(url=url,headers=headers,params=params,proxies=proxy)
# 获取返回页面保存到本地,便于查看
with open('ip.html','w',encoding='utf-8') as f:
f.write(response.text)
4、小结
- requests发送post请求使用requests.post方法,带上请求体,其中请求体需要时字典的形式,传递给data参数接收
- 在requests中使用代理,需要准备字典形式的代理,传递给proxies参数接收
- 不同协议的url地址,需要使用不同的代理去请求
初识urllib与requests的更多相关文章
- 【Python爬虫实战--1】深入理解urllib;urllib2;requests
摘自:http://1oscar.github.io/blog/2015/07/05/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3urllib;urllib2;reques ...
- Python 网络请求模块 urllib 、requests
Python 给人的印象是抓取网页非常方便,提供这种生产力的,主要依靠的就是 urllib.requests这两个模块. urlib 介绍 urllib.request 提供了一个 urlopen 函 ...
- 人生苦短之Python的urllib urllib2 requests
在Python中涉及到URL请求相关的操作涉及到模块有urllib,urllib2,requests,其中urllib和urllib2是Python自带的HTTP访问标准库,requsets是第三方库 ...
- 浅谈urllib和requests
urllib和requests的学习 urllib requests 参考资料 urllib urllib是python的基本库之一,内置四大模块,即request,error,parse,robot ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python 跨语言数据交互、json、pickle(序列化)、urllib、requests(爬虫模块)、XML。
Python中用于序列化的两个模块 json 用于[字符串]和 [python基本数据类型] 间进行转换 pickle 用于[python特有的类型] 和 [python基本数据类型]间进 ...
- urllib,urllib2,requests对比
#coding:utf-8 import urllib2 import urllib import httplib import socket import requests #实现以下几个方面内容: ...
- python3 urllib及requests基本使用
在python中,urllib是请求url连接的标准库,在python2中,分别有urllib和urllib,在python3中,整合成了一个,称谓urllib 1.urllib.request re ...
- urllib和requests库
目录 1. Python3 使用urllib库请求网络 1.1 基于urllib库的GET请求 1.2 使用User-Agent伪装后请求网站 1.3 基于urllib库的POST请求,并用Cooki ...
- python3 urllib和requests模块
urllib模块是python自带的,直接调用就好,用法如下: 1 #处理get请求,不传data,则为get请求 2 import urllib 3 from urllib.request impo ...
随机推荐
- webrtc 的理解
常规视频的传输包括以下几个步骤:采集,编码,推流,转码,分发,拉流,解码和渲染 在一个实时的音视频系统架构里,上面的每个环节都会有一定程度的优化空间. 以下内容摘自:rtmp直播和webrtc直播对比 ...
- win32-读取控制台中所有的字符串
我们可以先读取字符串所占的行数,再乘以控制台的实际宽度 bool ReadFromConsole() { HANDLE hConsole = GetStdHandle(STD_OUTPUT_HANDL ...
- dd命令创建文件
dd if=... of=... bs=... count=... if表示输入文件,of表示输出文件,bs默认指定了以字节为单位的块大小(单位有字节c,字w,块B,千字节m,兆字节m,吉字节G),c ...
- Apifox:成熟的测试工具要学会自己写接口文档
好家伙, 在开发过程中,我们总是避免不了进行接口的测试, 而相比手动敲测试代码,使用测试工具进行测试更为便捷,高效 今天发现了一个非常好用的接口测试工具Apifox 相比于Postman,他还拥有一个 ...
- 关于Python中math 和 decimal 模块的解析与实践
本文分享自华为云社区<Python数学模块深度解析与实战应用>,作者: 柠檬味拥抱. 在Python中,math 和 decimal 模块是处理数学运算的重要工具.math 提供了一系列常 ...
- TypeScript项目开发运行(即时编译、运行,所见所得)
1.项目*.ts自动编译 $ tsc . --watch 2.项目本地web服务运行 $ npm install --save-dev webpack-dev-server npm install - ...
- 【Azure 环境】向Azure Key Vault中导入证书有输入密码,那么导出pfx证书的时候,为什么没有密码呢?
问题描述 将pfx证书导入Key Vault的证书时,这个PFX需要输入正确的密码导入成功.但是当需要导出时,生成的pfx证书则不需要密码.这是正常的情况吗? 问题解答 是的,这是Azure Key ...
- 【Azure 应用服务】登录App Service 高级工具 Kudu站点的 Basic Auth 方式
问题描述 从Azure App Service的页面中,直接跳转到高级管理工具Kudu站点(https://<your app service name>.scm.chinacloudsi ...
- expect tcl 摘录
目录 部分参考来源说明 例子 expect命令 核心命令有三个 spawn.expect.send 其他expect命令 expect命令的选项 变量 tcl摘录 数据类型 符号 命令 其他说明 部分 ...
- 浅入ABP(2):添加基础集成服务
浅入ABP(2):添加基础集成服务 版权护体作者:痴者工良,微信公众号转载文章需要 <NCC开源社区>同意. 目录 浅入ABP(2):添加基础集成服务 定义一个特性标记 全局统一消息格式 ...