xv6 内存管理
前文讲述了 xv6 的启动过程,本文接着讲述 xv6 内存管理的部分,直接来看。
- 公众号:Rand_cs
启动部分完善
前文只是介绍了启动的过程,但是各类函数之间的调用,地址的变换,内存布局的变化并没有详细说明明,本节来完善。
BIOS
还是从 BIOS 开始,入口点是
0
x
f
f
f
f
0
0xffff0
0xffff0,是一跳转指令
j
m
p
f
000
:
e
05
b
jmp \ \ f000:e05b
jmp f000:e05b,然后开始执行 BIOS 的代码,内存低 1M 的顶部 64KB 都是分配给 BIOS 的,所以此时内存布局为:
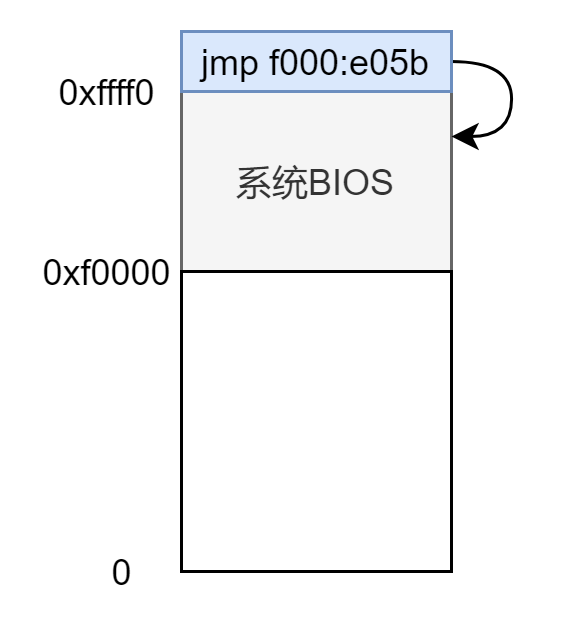
bootblock
xv6 没有实际的 MBR,bootasm.S 和 bootmain.c 两文件联合在一起编译成二进制文件 bootblock 放在磁盘最开始的那个扇区,然后被 BIOS 加载到
0
x
7
c
00
0x7c00
0x7c00 处,从
0
x
7
c
00
0x7c00
0x7c00 处开始执行。
此时内存布局为:
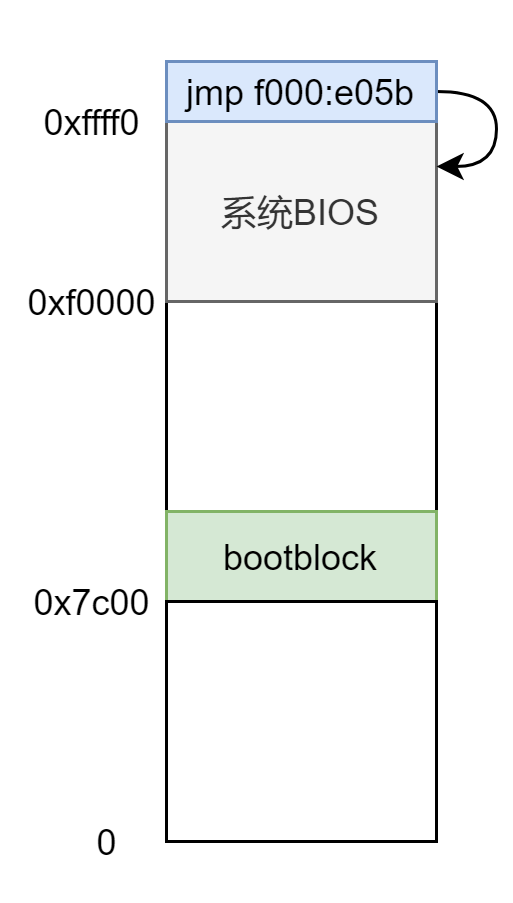
bootmain.c
bootmain 加载内核,来看看是怎么加载的,加载到哪儿。
elf = (struct elfhdr*)0x10000;
readseg((uchar*)elf, 4096, 0); //从磁盘读4096字节到物理地址 0x10000
这里 readseg 函数的意思是从磁盘的 1 扇区读取 4096字节到物理地址 0x10000 处。内核文件在磁盘的扇区 1 ,注意这里虽然参数传的是 0,但是函数内部加了 1,所以是从扇区 1 读取的。这个函数后面讲述磁盘再详述,这里知道作用就行。
0x10000 有什么意义?再来看一眼内存低 1M 的布局图:
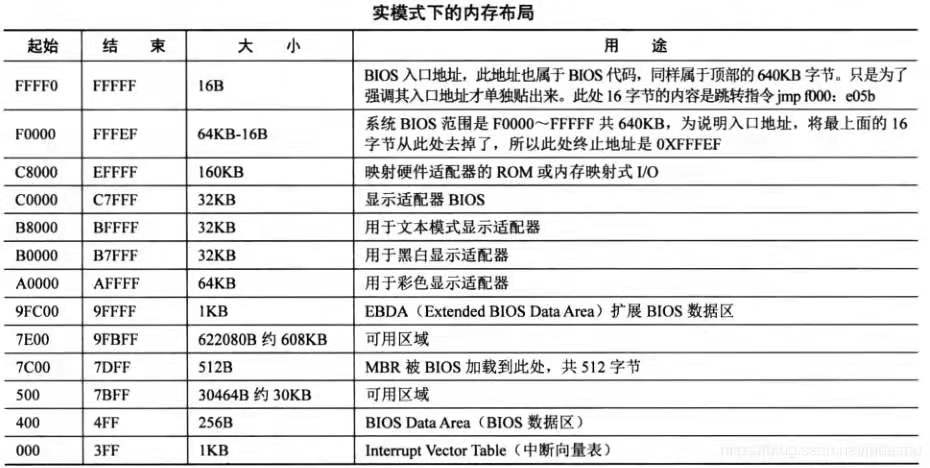
所以没什么特殊意义,就是找了一块空闲地儿,来存放内核的开始的 4096 字节。
那这 4096 字节有什么用?这就加载内核了?当然不是,xv6 的内核有 200 多 KB,开始的 4096 字节只是包括了 elf 文件的一些头部信息:
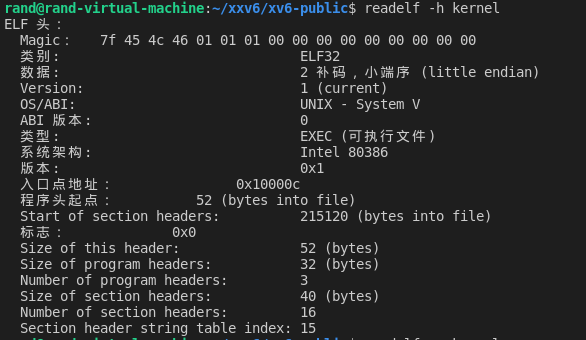
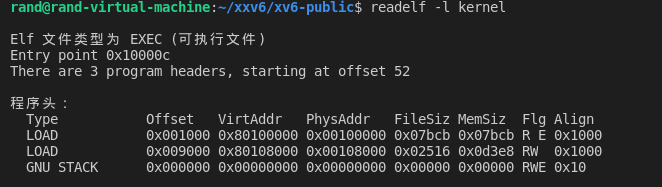
这是从我虚拟机上截的图,使用 readelf -h kernel 命令来查看内核的 elf 头信息,从截图上可知程序头的相对 elf 文件开始的偏移量为 52 字节,有 3 个程序头,每个 32 字节,所以这 4096 字节至少包括内核的 elf 头和程序头表,而这是我们加载内核正需要的信息。
此时内存中的布局:
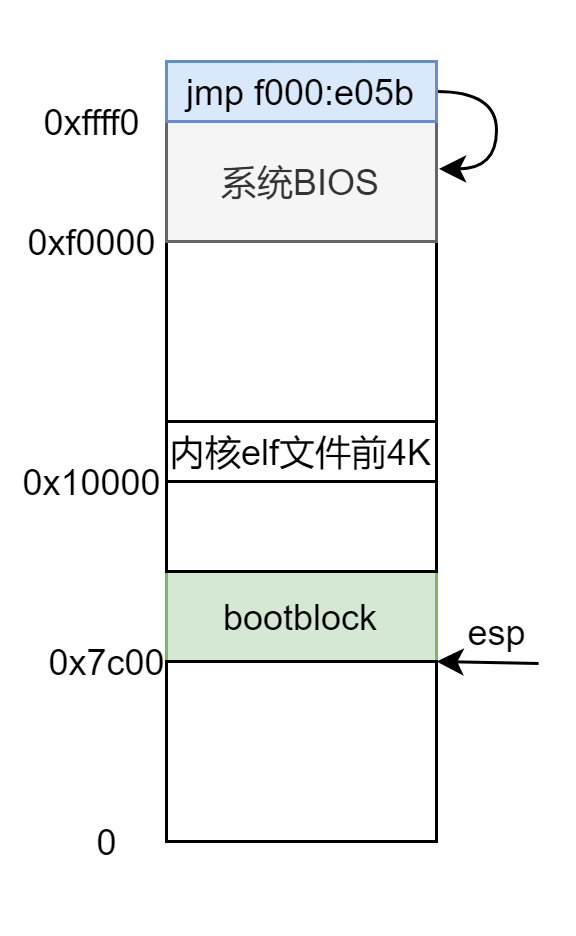
运行 bootmain.c 的时候是将 0x7c00 以下作为栈使用,根据内存低 1M 布局图可以看出,0x7c00 以下有大约 30K 的空闲空间可用,这段代码很少,栈空间用不了多少,30K 太足够了,不会有什么问题。
下面就开始正式加载内核了,加载到哪儿是一个问题,这就需要程序头中记载的信息了:
ph = (struct proghdr*)((uchar*)elf + elf->phoff); //第一个程序段的位置
eph = ph + elf->phnum;
for(; ph < eph; ph++){
pa = (uchar*)ph->paddr;
readseg(pa, ph->filesz, ph->off); //从ph->off所在的扇区读取ph->filesz字节到物理地址pa
if(ph->memsz > ph->filesz)
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz); //调用 stosb 将段的剩余部分置零
上下结合来看得知将内核加载到了物理地址的 0x100000 处。
此时的内存布局:
end 为内核末尾地址,不同版本有稍许不同,可以在 kernel.sym 文件中查找,也可以直接读取 elf 的程序头,根据
P
h
y
s
A
d
d
r
+
M
e
m
S
i
z
e
PhysAddr + MemSize
PhysAddr+MemSize 计算出来。
前面都是在未开启分页机制下运行,涉及到的地址都是实际的物理地址,从 bootmain.c 中 跳到 entry.S 就开启分页机制,分页必然要建立页表,涉及到内存管理,下面一一来看:
临时页表
xv6 在启动的时候建立了一个临时页表,在 main.c 文件的最后部分:
pde_t entrypgdir[NPDENTRIES] = {
// 将虚拟地址的[0,4M)映射到物理地址[0,4M)
[0] = (0) | PTE_P | PTE_W | PTE_PS,
// 将虚拟地址[800 0000,800 0000+40 0000)映射到[0,4M)
[KERNBASE>>PDXSHIFT] = (0) | PTE_P | PTE_W | PTE_PS,
};
xv6 定义虚拟地址 0x800 0000 以上为内核部分,虚拟地址空间和物理地址空间具体怎么映射的后面建立正式的页表时候再说。
为啥要将虚拟地址不同的两部分映射到相同的物理地址?这需要看 entrypgdir 用在什么地方,entrypgdir 定义在 main.c 中,用在 entry.S 文件中。启动那篇文章说过,entry.S 主要就是开启分页机制。本身代码是在物理地址低 4M 内,必须保证分页机制前的线性地址与分页机制的虚拟地址对应的物理地址一致,也就是必须使开启分页机制和跳到高地址之间的指令能够正确执行。
页面大小扩展
entry.S 代码里面有这么几句指令:
# Turn on page size extension for 4Mbyte pages
# 开启页面大小扩展,每页 4 M
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
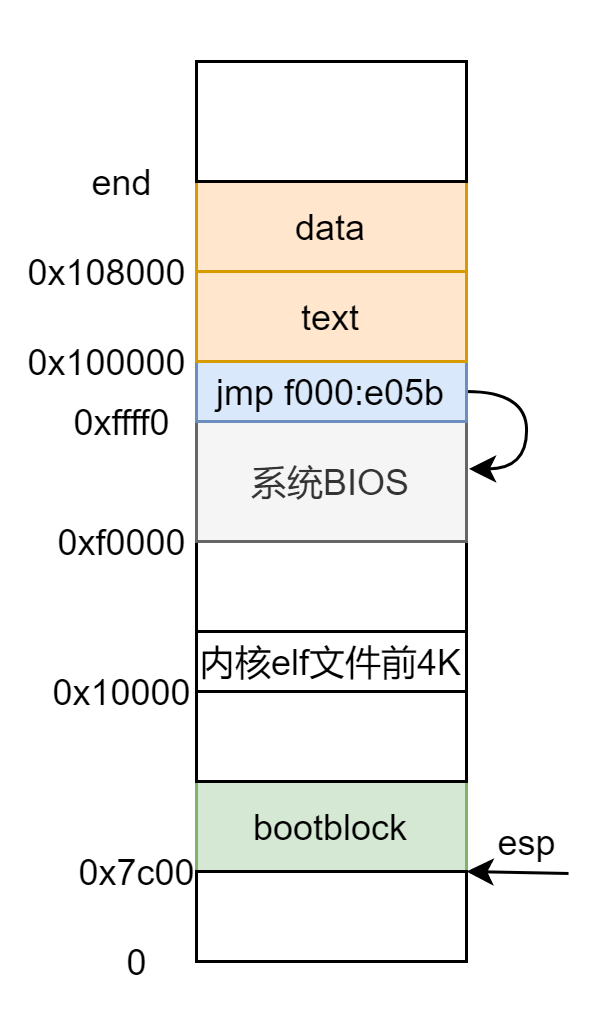
将 CR4 寄存器的 PSE 位置 1,以及设置页目录项的 PS 位,便可以设置每页的大小为 4M,但是此时对虚拟地址的解析有了变化,如果使用二级页表的话,我们是将虚拟地址的高 10 位作为页目录的索引,得到一级页表的物理地址,将中 10 位作为页表的索引,得到页框的物理地址,再加上后面 12 位的偏移地址得到最终目标的物理地址。示意图如下:

如果是使用一级页表的话,将虚拟地址的前 20 位作为页表的索引,得到页框的物理地址,加上后面 12 位的索引得到最终目标的物理地址,示意图如下:
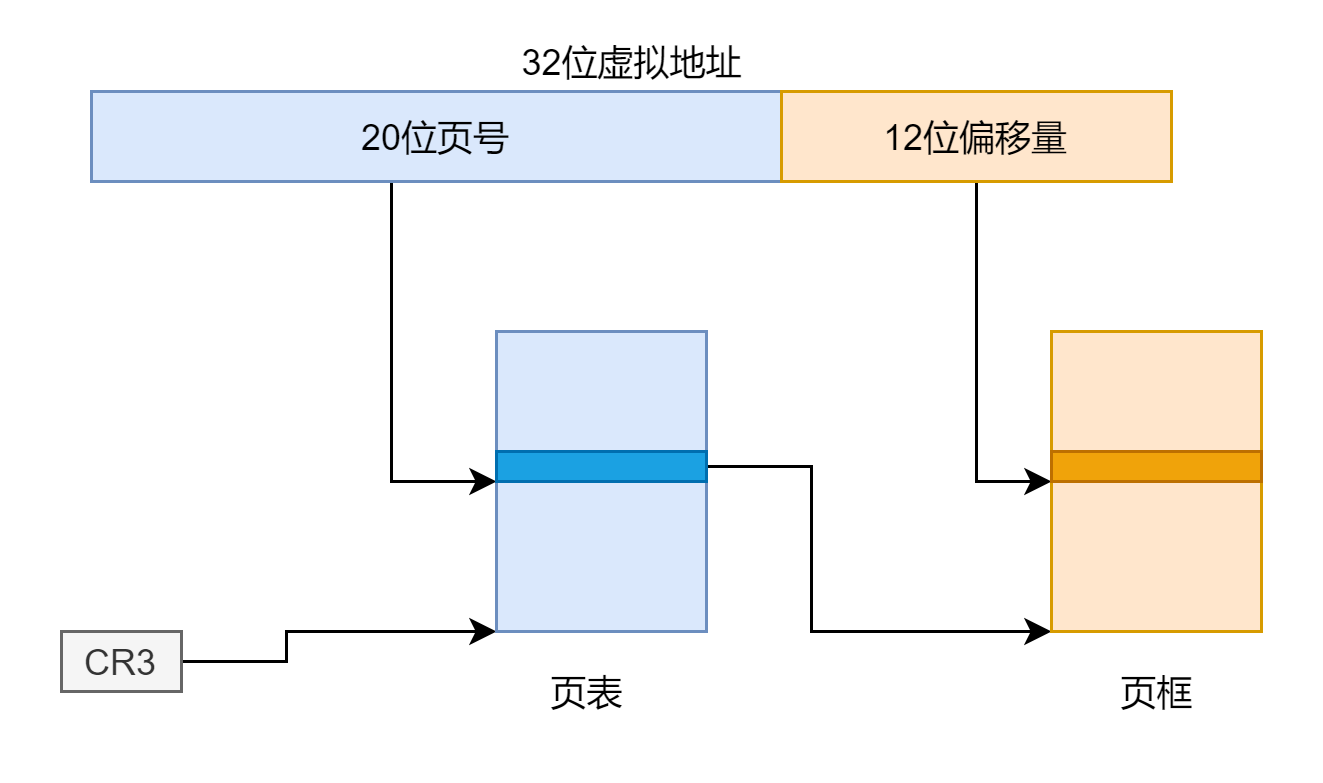
但如果是开启页面大小扩展,有点类似与一级页表,但又有所不同,它是将虚拟地址的高 10 位作为页表的索引,得到页框的物理地址,加上低 22 位的偏移量得到最终目标的物理地址,示意图如下:

所以这就解释了为什么 entrypgdir 简简单单的两项,两条语句就映射了 4M 的地址空间。那为什么要使用页面大小扩展呢?我合理的猜测下:就是简单方便,语句少,想想如果使用二级页表,页面大小不进行扩展只有 4K 的情况要怎么映射,两部分地址空间,得有两个页目录项,对应两个一级页表,4M 有 1024 个 4K,得有 1024 个页表项。虽然 4M 没有全用,不用全映射,但是总的来说使用页面大小扩展之后更加简单方便。
内存管理
建立正式页表之前先来看看 xv6 是如何对内存进行组织管理的,任何一个操作系统都需要对内存进行管理,将内存以某种方式组织起来,用的时候可以分配,不再使用的时候回收。组织方式常见的有链式和位图,xv6 里面是用链表的形式将空闲空间给组织起来,相关代码在 kalloc.c 文件中,我们来具体分析一下:
首先定义了两个结构体:
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;
这两个结构体什么意思,有什么用?看个图就明白了:

所以 kmem 就像个内存分配器,这个 freelist 就是这片空闲页链表的链头,分配内存的时候就将它先分配出去,然后每页里面有一个指针,指向下一个空闲页。有了这个了解之后来看具体的实现代码:
char* kalloc(void)
{
struct run *r; //声明run结构体指针
if(kmem.use_lock) //加锁
acquire(&kmem.lock);
r = kmem.freelist; //第一个空闲页地址赋给r
if(r)
kmem.freelist = r->next; //链头移动到下一页,相当于把链头给分配出去了
if(kmem.use_lock) //释放锁
release(&kmem.lock);
return (char*)r; //返回第一个空闲页的地址
}
代码很简单,就是加锁,取链头地址,链头移到下一个空闲页,释放锁,返回取到的链头地址。
void kfree(char *v) //释放页v
{
struct run *r;
//这个页应该在这些范围内且边界为4K的倍数
if((uint)v % PGSIZE || v < end || V2P(v) >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(v, 1, PGSIZE); //将这个页填充无用信息,全置为1
if(kmem.use_lock) //取锁
acquire(&kmem.lock);
r = (struct run*)v; //头插法将这个页放在链首
r->next = kmem.freelist;
kmem.freelist = r;
if(kmem.use_lock) //释放锁
release(&kmem.lock);
}
基本上是 kalloc 的逆操作,先检查要释放的页合理与否,然后填充无效信息,再取锁,使用头插法将这个页放在链首,释放锁。从这看出这应该是用的头插法。
void freerange(void *vstart, void *vend) //连续释放vstart到vend之间的页
{
char *p;
p = (char*)PGROUNDUP((uint)vstart);
for(; p + PGSIZE <= (char*)vend; p += PGSIZE)
kfree(p);
}
还有两个函数 kinit1,kinit2 是上述 freerange 函数的封装:
void kinit1(void *vstart, void *vend) //kinit1(end, P2V(4*1024*1024));
{
initlock(&kmem.lock, "kmem");
kmem.use_lock = 0;
freerange(vstart, vend);
}
void kinit2(void *vstart, void *vend) //kinit2(P2V(4*1024*1024), P2V(PHYSTOP));
{
freerange(vstart, vend);
kmem.use_lock = 1;
}
它俩是在 main.c 的 main() 函数中被调用,调用的参数也已经注释在后边。调用这两个函数就是初始化内存,将内存一页一页的使用头插法链在一起。
内核页表
要了解其他几个参数还需要先来了解 xv6 的虚拟地址空间和实际的物理地址空间的映射关系,这也有相应的结构体表示:
#define EXTMEM 0x100000 // Start of extended memory
#define PHYSTOP 0xE000000 // Top physical memory
#define DEVSPACE 0xFE000000 // 一些设备的地址,比如apic的一些寄存器
// Key addresses for address space layout (see kmap in vm.c for layout)
#define KERNBASE 0x80000000 // 内核的起始虚拟地址
#define KERNLINK (KERNBASE+EXTMEM) // 内核文件的链接地址
#define V2P(a) (((uint) (a)) - KERNBASE) //内核虚拟地址转物理地址
#define P2V(a) ((void *)(((char *) (a)) + KERNBASE)) //物理地址转内核虚拟地址
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices
};
上面那一坨就是说明虚拟地址空间内核部分到物理内存的映射关系,看起来可能很麻杂,做了一张表格和图:
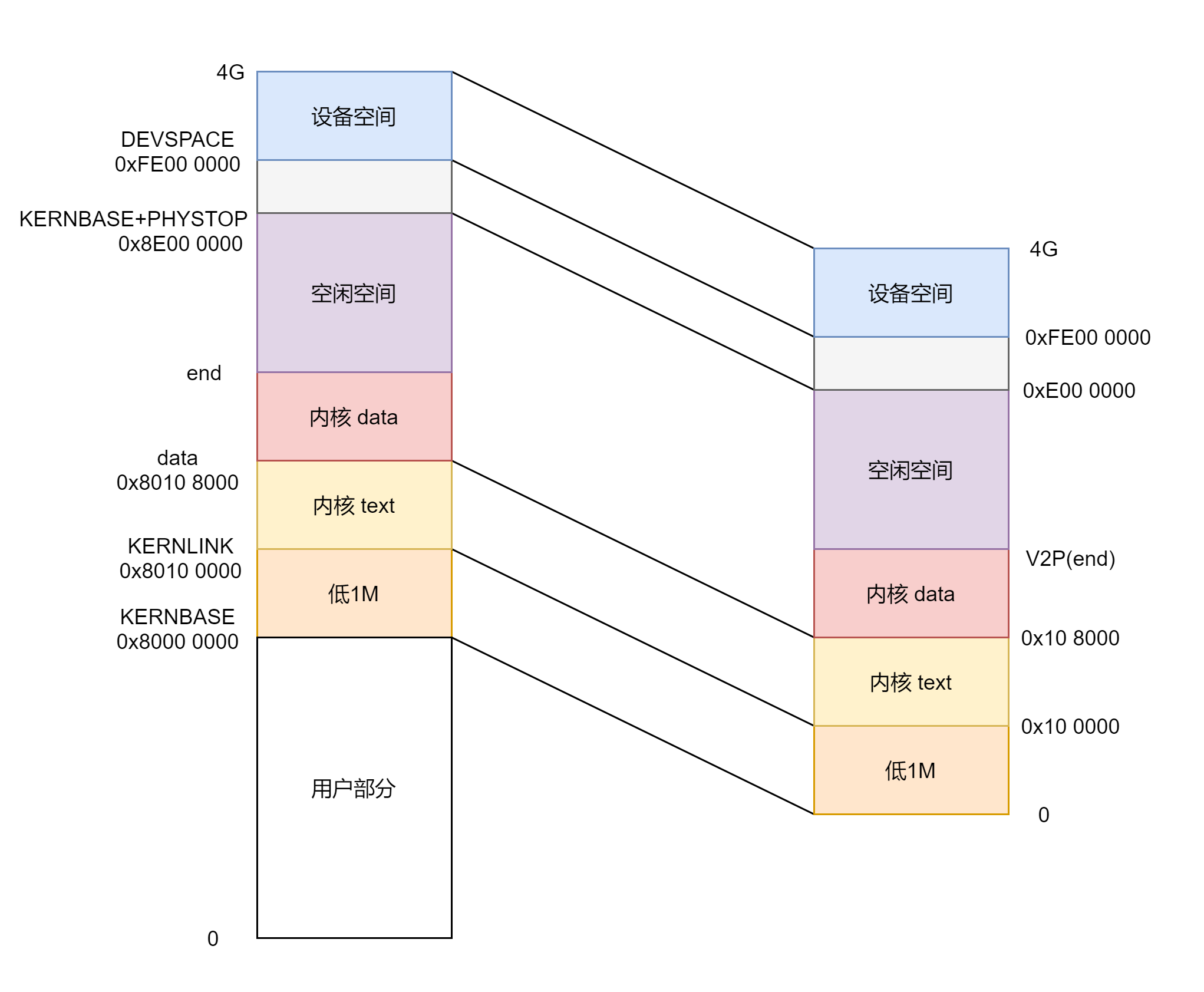
所以从这张图可以看出,内核部分的虚拟地址空间和物理地址空间就是一一对应的,只是相差了 0x8000 0000,所以这就是为什么简单的宏 V2P,P2V 就可以实现虚拟地址物理地址之间的转换,当然这只是内核部分才行。用户态部分的我们还没有涉及,用户态下的虚拟地址到物理地址之间的转换就必须要使用页表了,相关部分在进程我们再详述。
再者也可以看出 xv6 并没有使用全部的 4G 地址空间,有很大一部分都没有使用,除开这部分所有的物理内存实际都映射到内核中去了,那用户部分呢?用户部分是通过页表映射到了物理地址空间的空闲部分,这部分物理地址空间又可以通过 P2V 映射到内核部分去,是不是很绕,后面讲述进程的时候慢慢说这部分。
另外关于设备部分是直接映射的,是真的一一对应,虚拟地址和物理地址一样,这部分地址空间是分配给一些设别的,比如 APIC 的一些寄存器,详见:
实现上述的映射得建立相应的页表,来看相关代码:
#define PDX(va) (((uint)(va) >> PDXSHIFT) & 0x3FF) //高10位
#define PTX(va) (((uint)(va) >> PTXSHIFT) & 0x3FF) //中10位
#define PGADDR(d, t, o) ((uint)((d) << PDXSHIFT | (t) << PTXSHIFT | (o))) //d为高10位,t为中10位,o为低12位,将他们组合成虚拟地址
static pte_t * walkpgdir(pde_t *pgdir, const void *va, int alloc) //根据虚拟地址 va 返回相应的页表项地址
{
pde_t *pde; //页目录项地址
pte_t *pgtab; //一级页表地址
pde = &pgdir[PDX(va)]; //va取高12位->页目录项
if(*pde & PTE_P){ //若一级页表存在
pgtab = (pte_t*)P2V(PTE_ADDR(*pde)); //取一级页表的物理地址,转化成虚拟地址
} else {
if(!alloc || (pgtab = (pte_t*)kalloc()) == 0) //否则分配一页出来做页表
return 0;
// Make sure all those PTE_P bits are zero.
memset(pgtab, 0, PGSIZE); //初始化置0
*pde = V2P(pgtab) | PTE_P | PTE_W | PTE_U; //将新分配出来的以及页表记录在页目录中
}
return &pgtab[PTX(va)]; //va取中10位->页表项
}
static int mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm)
{
char *a, *last;
pte_t *pte;
a = (char*)PGROUNDDOWN((uint)va); //虚拟地址va以4K为单位的下边界
last = (char*)PGROUNDDOWN(((uint)va) + size - 1); //偏移量,所以减1
for(;;){
if((pte = walkpgdir(pgdir, a, 1)) == 0) //获取地址a的页表项地址
return -1;
if(*pte & PTE_P) //如果该页本来就存在
panic("remap");
*pte = pa | perm | PTE_P; //填写地址a相应的页表项
if(a == last) //映射完了退出循环
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
mappages 映射虚拟地址 va 到物理地址 pa,映射大小为 size,实现方式将相应的页表项填进 pgdir 指向的页表中去。总的来说分为两步,调用 walkpgdir 获取虚拟地址相应的页表项,然后将物理地址属性位填进这个页表项。这就是映射一页的操作,重复这个操作映射从 va 开始的 size 大小区域。
现在有了内核映射的要求和实现方法,可以建立内核正式的页表了:
#define NELEM(x) (sizeof(x)/sizeof((x)[0])) //x有多少项
pde_t* setupkvm(void) //建立内核页表
{
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0) //分配一页作为页目录表
return 0;
memset(pgdir, 0, PGSIZE); //页目录表置0
if (P2V(PHYSTOP) > (void*)DEVSPACE) //PHYSTOP的地址不能高于DEVSPACE
panic("PHYSTOP too high");
for(k = kmap; k < &kmap[NELEM(kmap)]; k++) //映射4项,循环4次
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start, (uint)k->phys_start, k->perm) < 0) {
freevm(pgdir);
return 0;
}
return pgdir;
}
setupkvm() 相当于 mappages() 的封装,它循环四次,将 kmap 给出的信息当作参数传给 mappages,映射相应的地址空间。
注意 kmap 最后一项的 phys_end 为0,kmap 结构体中声明的物理地址都是无符号数,所以最后一项k->phys_end - k->phys_start,如此计算也是没有问题的,对于数值问题有疑惑的请看我这篇文章:
建好页表就该切换页表,就是将页表的及地址赋给 CR3,看下面对 setupkvm() 封装的函数:
pde_t *kpgdir;
void kvmalloc(void)
{
kpgdir = setupkvm(); //建立页表
switchkvm(); //切换页表
}
void switchkvm(void)
{
lcr3(V2P(kpgdir)); //加载内核页表到cr3寄存器,cr3存放的是页目录物理地址
}
kpgdir 是个全局变量,为内核页表的地址,kvmalloc() 调用 setupkvm() 建立页表,返回的页表地址赋给 kpgdir,然后调用 switchkvm() 切换成内核页表,也就是将 kpgdir 的物理地址加载到 CR3 寄存器。
页表的事完成之后,内核完全运行在高地址之上了,相应的一些结构的地址也得切换到高地址上面去,比如说 GDTR 中存放的 GDT 地址和界限。最开始的 GDT 是在 bootasm.S 文件建立的,放在物理地址值的低 1M,后来分页机制开启之后使用的临时页表,映射了虚拟地址空间低 4M 和 内核之上的低 4M 到物理地址空间的低 4M,所以 GDTR 中的地址没问题,CPU 能够找到 GDT。但是切换成正式页表之后不再映射虚拟地址空间的低地址部分,低地址部分是给用户态用的,内核都处于高地址,所以 GDTR 中的地址不再有效。况且 GDT 还需要重新建立正式的 GDT,所以有了如下的 seginit():
void seginit(void) //设置内核用户的代码段和数据段
{
struct cpu *c;
c = &cpus[cpuid()]; //获取当前CPU
//建立段描述符,内核态用户态的代码段和数据段
c->gdt[SEG_KCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, 0);
c->gdt[SEG_KDATA] = SEG(STA_W, 0, 0xffffffff, 0);
c->gdt[SEG_UCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, DPL_USER);
c->gdt[SEG_UDATA] = SEG(STA_W, 0, 0xffffffff, DPL_USER);
lgdt(c->gdt, sizeof(c->gdt)); //加载到GDTR
}
每个 CPU 有自己的结构,cpus 这个结构体数组本身位于内核,内核现已运行在高地址,GDT 放在 CPU 结构体中,那么也就相当于放在了高地址上。设置好段描述符,建立好 GDT 之后,便将 GDT 的新地址和界限写进 GDTR 寄存器中去。
上述讲述了内核页表的过程,有了这全局的认识之后,来解决上述遗留的一些问题:
- 为什么要分两次初始化内存:kinit1() 和 kinit2()
- 为什么 kinit2() 必须在 startothers() 之后
解决这两个问题,我们要来看看 xv6 的设计思路,当然只是看和内存相关比较紧密的部分:
最开始内核加载到物理地址 0x10 0000 处,xv6 内核很小,整个内核只有 200 多 K。内核一开始就先运行 entry.S 的代码,开启分页机制,分页当然得有页表,为简单方便将页面大小扩展到了 4M,制作了一个启动时用的临时页表,映射了低 4M 的内存。entry.S 代码运行完之后跳到 main() 中去。
int main(void)
{
kinit1(end, P2V(4*1024*1024)); // phys page allocator
kvmalloc(); // kernel page table
/*********/
seginit(); // segment descriptors
/*********/
startothers(); // start other processors
kinit2(P2V(4*1024*1024), P2V(PHYSTOP)); // must come after startothers()
/*********/
}
首先就是初始化内核结束点到 4M 之间的内存,kinit1() 使用的地址是虚拟地址,此时的页表只映射了低 4M,所以传的参数为 end 到 P2V(4*1024*1024)。
初始化了 end 到 4M 之间的内存区域之后就可以构建正式的内核页表映射更多的地址空间,所以紧接着调用了 kvmalloc() 建立内核部分的页表。
原本内核在低地址,由于分页机制的开启,内核跑到高地址上面去了,需要改变一些寄存器中记录的值,比如记录 GDT 地址和界限的 GDTR 寄存器,所以有了 seginit() 重新初始化 GDT,然后将 GDT 的虚拟地址和界限写到 GDTR 中去。
现在已经建立了正式的内核页表,映射了整个内核部分,有更多的虚拟地址空间可用,所以可以初始化更多的内存了,因此有了 kinit2(),初始化的区域是 4M 到 PHYSTOP,这个宏定义可以在一定范围内改变,从这个宏定义可以看出,xv6 实际并没有用到 32 位全部的 4G 空间。
那为什么 kinit2() 必须在 startothers() 后面呢?原因就在于其他 CPU 启动的时候也是用的那张临时页表,只映射了物理地址的低 4M, kinit2() 的初始化内存是用头插法依次链接在头部的,如果先执行 kinit2() 的话,那么在执行 startothers() 时候给 APs 分配内存的时候就会先分配高处的内存,而这些内存的地址临时页表是没有映射的,就会引发错误,所以 kinit2() 必须在 startothers() 之后。
至于其他 APs 的启动,大都重复 BSP 的过程,只不过 APs 的启动代码放在了 0x7000 处,其他的基本一样就不再赘述了。
本文讲述了 xv6 的内存管理部分,完善了启动过程中的内存布局变化,但也只涉及了内核部分,用户部分将和进程结合在一起叙述。好啦本文就到这里,有什么错误还请批评指正,也欢迎大家来同我讨论交流。
- 公众号:Rand_cs
找了一个相关资料的网站,有各种手册:
bochs: The Open Source IA-32 Emulation Project (Tech Specs) (sourceforge.io)
xv6 内存管理的更多相关文章
- XV6学习笔记(2) :内存管理
XV6学习笔记(2) :内存管理 在学习笔记1中,完成了对于pc启动和加载的过程.目前已经可以开始在c语言代码中运行了,而当前已经开启了分页模式,不过是两个4mb的大的内存页,而没有开启小的内存页.接 ...
- .NET基础拾遗(1)类型语法基础和内存管理基础
Index : (1)类型语法.内存管理和垃圾回收基础 (2)面向对象的实现和异常的处理 (3)字符串.集合与流 (4)委托.事件.反射与特性 (5)多线程开发基础 (6)ADO.NET与数据库开发基 ...
- PHP扩展-生命周期和内存管理
1. PHP源码结构 PHP的内核子系统有两个,ZE(Zend Engine)和PHP Core.ZE负责将PHP脚本解析成机器码(也成为token符)后,在进程空间执行这些机器码:ZE还负责内存管理 ...
- linux2.6 内存管理——逻辑地址转换为线性地址(逻辑地址、线性地址、物理地址、虚拟地址)
Linux系统中的物理存储空间和虚拟存储空间的地址范围分别都是从0x00000000到0xFFFFFFFF,共4GB,但物理存储空间与虚拟存储空间布局完全不同.Linux运行在虚拟存储空间,并负责把系 ...
- linux2.6 内存管理——概述
在紧接着相当长的篇幅中,都是围绕着Linux如何管理内存进行阐述,在内核中分配内存并不是一件非常容易的事情,因为在此过程中必须遵从内核特定的状态约束.linux内存管理建立在基本的分页机制基础上,在l ...
- Objective-C内存管理之引用计数
初学者在学习Objective-c的时候,很容易在内存管理这一部分陷入混乱状态,很大一部分原因是没有弄清楚引用计数的原理,搞不明白对象的引用数量,这样就当然无法彻底释放对象的内存了,苹果官方文档在内存 ...
- Quartz2D内存管理
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 14.0px "PingFang SC"; color: #239619 } p.p2 ...
- 浅谈Linux内存管理机制
经常遇到一些刚接触Linux的新手会问内存占用怎么那么多?在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,表面感觉是内存不够用了,其实不然.这是Linux内存管理的一个优秀特性,在这 ...
- linux内存管理
一.Linux 进程在内存中的数据结构 一个可执行程序在存储(没有调入内存)时分为代码段,数据段,未初始化数据段三部分: 1) 代码段:存放CPU执行的机器指令.通常代码区是共享的,即其它执行程 ...
- cocos2d-x内存管理
Cocos2d-x内存管理 老师让我给班上同学讲讲cocos2d-x的内存管理,时间也不多,于是看了看源码,写了个提纲和大概思想 一. 为什么需要内存管理 1. new和delete 2. 堆上申 ...
随机推荐
- dbeaver导出结果集中乱码
重要的一步 需要点击
- 力扣645(java)-错误的集合(简单)
题目: 集合 s 包含从 1 到 n 的整数.不幸的是,因为数据错误,导致集合里面某一个数字复制了成了集合里面的另外一个数字的值,导致集合 丢失了一个数字 并且 有一个数字重复 . 给定一个数组 nu ...
- 【pytorch学习】之数据操作
1 数据操作 为了能够完成各种数据操作,我们需要某种方法来存储和操作数据.通常,我们需要做两件重要的事:(1)获取数据: (2)将数据读入计算机后对其进行处理.如果没有某种方法来存储数据,那么获取数据 ...
- HarmonyOS NEXT应用开发之异常处理案例
介绍 本示例介绍了通过应用事件打点hiAppEvent获取上一次应用异常信息的方法,主要分为应用崩溃.应用卡死以及系统查杀三种. 效果图预览 使用说明: 点击构建应用崩溃事件,3s之后应用退出,然后打 ...
- 云原生应用实现规范 - 初识 Operator
简介: 本文我们将首先了解到 Operator 是什么,之后逐步了解到 Operator 的生态建设,Operator 的关键组件及其基本的工作原理,下面让我们来一探究竟吧. 作者 | 匡大虎.阚俊宝 ...
- 阿里巴巴开源大规模稀疏模型训练/预测引擎DeepRec
简介:经历6年时间,在各团队的努力下,阿里巴巴集团大规模稀疏模型训练/预测引擎DeepRec正式对外开源,助力开发者提升稀疏模型训练性能和效果. 作者 | 烟秋 来源 | 阿里技术公众号 经历6 ...
- [Cryptocurrency] rDAI 与 DAI 的区别, 如何质押 rDAI 获取利息
以下合约操作需要在安装 MetaMask ( 以太坊的浏览器钱包 ) 的情况下进行. rDAI 通过和 DAI 1 : 1 互换得到,在 rDAI 提供的 dapp 上面操作 https://app ...
- UNO 的 SamplesApp.Skia.Gtk 丢失字体文件抛出空异常
在运行 UNO 的 SamplesApp.Skia.Gtk 例子程序时,如果没有拷贝字体文件夹,导致字体丢失,将会在运行的时候抛出 NullReferenceException 空异常 抛出的异常堆栈 ...
- 2018-8-10-使用-Resharper-快速做适配器
title author date CreateTime categories 使用 Resharper 快速做适配器 lindexi 2018-08-10 19:16:51 +0800 2018-2 ...
- C++ 多级继承与多重继承:代码组织与灵活性的平衡
C++ 多级继承 多级继承是一种面向对象编程(OOP)特性,允许一个类从多个基类继承属性和方法.它使代码更易于组织和维护,并促进代码重用. 多级继承的语法 在 C++ 中,使用 : 符号来指定继承关系 ...