DiTAC:不知如何提升性能?试试这款基于微分同胚变换的激活函数 | ECCV'24
非线性激活函数对深度神经网络的成功至关重要,选择合适的激活函数可以显著影响其性能。大多数网络使用固定的激活函数(例如,
ReLU、GELU等),这种选择可能限制了它们的表达能力。此外,不同的层可能从不同的激活函数中受益。因此,基于可训练激活函数的兴趣日益增加。论文提出了一种基于有效微分同胚变换(称为
CPAB)的可训练高表达能力激活函数DiTAC。尽管只引入了极少量的可训练参数,DiTAC仍然增强了模型的表达能力和性能,通常会带来显著的改善。它在语义分割、图像生成、回归问题和图像分类等任务中优于现有的激活函数(无论这些激活函数是固定的还是可训练的)。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Trainable Highly-expressive Activation Functions

Introduction
激活函数(AFs)在深度神经网络的成功中扮演着重要角色,因为它们赋予了后者非线性特性。实际上,激活函数对于网络能够近似几乎任意复杂的函数、学习有意义的特征表示以及实现高预测性能至关重要。除了其非线性特性,激活函数还具有各种特性,这些特性直接影响着网络的性能。传统的激活函数,如Logistic Sigmoid和Tanh Unit,会将输入值映射到一个较小的范围,这可能导致网络梯度接近零,从而影响训练性能。修正线性单元(ReLU)及其变种(例如,LReLU和PReLU)部分解决了这个问题,通过将输入映射到一个在一个或两个方向上无限制的范围内。指数激活函数如ELU继承了ReLU的优点,但也将激活函数的响应推向零均值,以提高性能。
一般来说,固定的激活函数(AFs)具有有限的非线性(因此表达能力有限),并对网络施加了学习偏差。因此,将它们调整为不同的问题类型和数据复杂性是具有挑战性的。因此,研究增强表达能力并缓解这种偏差的激活函数设计是一个开放的研究领域。可训练激活函数(TAFs)如PReLU、Swish和PELU通过添加几个可学习参数来调整标准固定激活函数的形状。根据研究,这类函数在表达能力上仅取得了微小的提升,因为这些TAFs的性能往往与其基本的不可训练激活函数相似。Maxout单元提供了另一种激活函数的方法。尽管在解决分类任务方面相较于ReLU有显著改进,但Maxout层中的参数数量会随着网络中神经元数量的增加而增加。

微分同胚是一个可微的可逆函数,具有一个可微的逆。论文提出了一种基于微分同胚的可训练激活函数(Diffeomorphism-based Trainable Activation function,DiTAC),这是一种基于高度表达和高效微分同胚(称为CPAB)的可微参数化TAF。尽管DiTAC仅添加了可以忽略不计的可训练参数,但它的表达能力仍然非常强。如图1所示,与现有的TAFs相比,这些TAFs仅限于学习某种特定形状或仅学习凸函数,而DiTAC能够学习多种形状。之前有研究展示了不同的激活函数适合于不同类型的数据和任务,这一事实激励了像这样的灵活TAF方法。特别地,DiTAC在各种数据集和任务(如语义分割、图像生成、图像分类和回归问题)上取得了显著的改进。
总之,论文的贡献如下:
- 第一个提出在可训练激活函数中使用灵活微分同胚的研究者。
- 呈现了
DiTAC,这是一种新颖的高度表达的激活函数,它解决了现有可训练激活函数的问题,并且可以轻松应用于任何模型架构。 - 展示了
DiTAC在各种任务和数据集上优于现有的激活函数和可训练激活函数。
CPAB transformations in Deep Learning
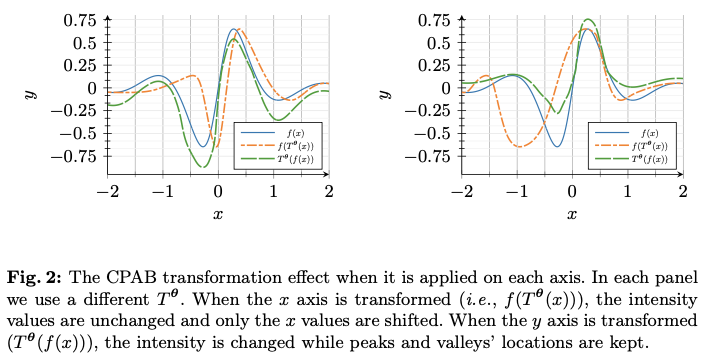
由Freifeld等人提出的CPAB变换是一种高效且表达能力强的参数微分同胚。它们被称为CPAB,源于CPA-Based,因为它们基于连续分段仿射(Continuous Piecewise-Affine, CPA)速度场。自其诞生以来,这些变换在深度学习(DL)中找到了许多应用。所有这些工作使用CPAB变换与论文使用它们之间的主要区别在于,在那些工作中,CPAB变换总是应用于目标信号的域(无论是2D图像中的空间域还是时间序列中的时间域),通常是通过将它们融入空间变换网络(Spatial Transformer Net, STN)或时间变换网络(Temporal Transformer Net, TTN)中,而论文则将其(逐元素)应用于特征图的范围(顺便提一下,这也意味着不需要进行网格重采样,这是STNs/TTNs中的一个必需步骤)。图2说明了这一区别。特别地,论文是第一批使用CPAB变换(或者说任何其他高表达性微分同胚家族)来构建可训练激活函数(TAFs)的。
Method
Preliminaries: 1D CPAB Transformations
处理微分同胚通常涉及昂贵的计算,由于在深度学习架构中直接使用微分同胚,因此降低相关计算负担变得尤为重要(相较于非深度学习应用)。设 \(T^{\theta}\) 为由 \({\theta}\) 参数化的微分同胚,在训练过程中,数量 \(x \mapsto T^{\theta}(x)\) 和 \(x \mapsto \nabla_{\theta} T^{\theta}(x)\) 需要在多个 \(x\) 值和多个 \({\theta}\) 值下进行计算。
选择CPAB变换作为使用的微分同胚家族的主要原因是它们既具有表达能力又高效。在剩下的部分中,所有的CPAB变换都假定是在一维的。
设 \(\Omega=[a,b]\subset \mathbb{R}\) 为一个有限区间,且设 \(\mathcal{V}\) 为从 \(\Omega\) 到 \(\mathbb{R}\) 的连续函数空间,这些函数相对于某个固定的将 \(\Omega\) 划分为子区间的分区也是分段仿射的。注意到 \(\mathcal{V}\) 是一个有限维线性空间。设 \(d=\dim(\mathcal{V})\) ,令 \({\theta}\in \mathbb{R}^d\) ,并令 \(v^{\theta}\in \mathcal{V}\) 表示 \(\mathcal{V}\) 中的一个通用元素,参数化为 \({\theta}\) 。通过对 \(\mathcal{V}\) 中元素的积分得到的CPAB变换空间定义为
&\mathcal{T}\triangleq
\Bigl \{
T^{\theta}:
x\mapsto \phi^{\theta}( x;1)
\text{ s.t. } \phi^{\theta}( x;t) \text{ solves the integral equation} \nonumber \\
& \phi^{\theta}(x;t) = x+\int_{0}^t v^{\theta}(\phi^{\theta}(x;\tau))\,
\mathrm{d}\tau \text{ where } v^{\theta}\in \mathcal{V}\,
\Bigr
\}\, .
\label{Eqn:IntegralEquation}
\end{align}
\]
可以证明,所有的 \(T^{\theta}\in\mathcal{T}\) 都是保序变换(即单调递增)并且是微分同胚。注意,尽管 \(v^{\theta}\in\mathcal{V}\) 是CPA,但CPAB变换 \(T^{\theta}\in\mathcal{T}\) 则不是(例如, \(T^{\theta}\) 是可微的,这与任何非平凡的CPA函数不同)。公式1也意味着 \(\mathcal{V}\) 中的元素被视为速度场。
特别有用的事实有:
- \(\Omega\) 的划分越精细,
CPAB族的表现力就越强(这也意味着 \(d\) 增加)。 CPAB变换使得在封闭形式中快速且准确地计算 \(x\mapsto T^{\theta}(x)\) 和梯度 \(x\mapsto\nabla_{\theta} T^{\theta}(x)\) 成为可能。
综上所述,这些事实意味着CPAB变换能提供了一种便捷且高效的方式来参数化和优化非线性单调递增函数。
The DiTAC Activation Function
论文提出的TAF称为DiTAC,是一种源自CPAB变换的TAF。DiTAC包含极少量的可训练参数,但它却具有很高的表现力。与现有的TAF不同的是,后者为每个输入通道专门分配一个参数,而DiTAC的表现力则来源于CPAB变换的表现力。
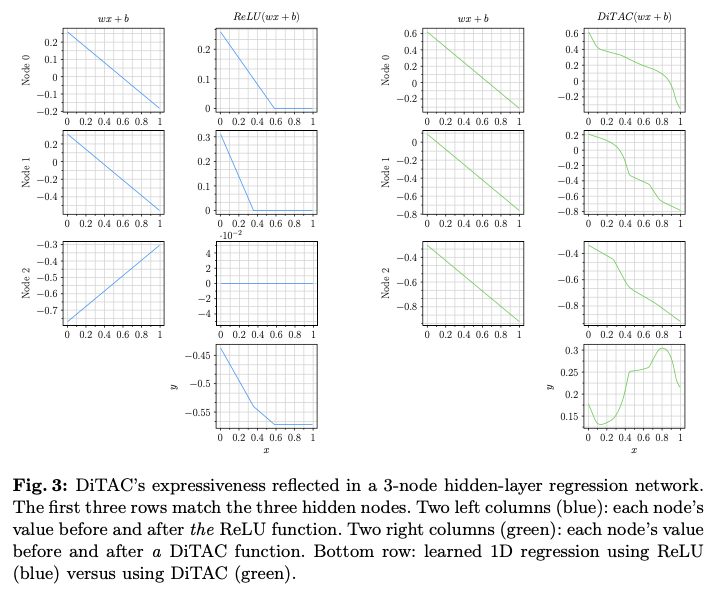
为了说明这一点,在图3中展示了在使用ReLU或DiTAC时,具有3个节点隐藏层的回归MLP中非线性是如何逐步演变的。在ReLU的情况下,表现力主要体现在对所有激活响应求和之后(并且结果函数在多个位置是不可微的),而DiTAC的表现力(和可微性)则在每个神经元经历的第一次数据变换中就明显体现出来。值得注意的是,CPAB变换及其梯度的封闭形式表达式的可用性使得DiTAC可以轻松地作为任何深度学习架构中任何激活函数的替代品。
现在解释DiTAC是如何构建的。回想一下,CPAB变换 \(T^{\theta}\) 是在有限区间 \([a,b]\) 上定义的。它的值域也是一个有限区间,这个区间可能与 \(\Omega\) 重合,也可能不重合(这取决于是否对 \(v^{\theta}\) 施加零边界条件)。由于某些激活函数的输入可能落在 \([a,b]\) 之外,主版本DiTAC将 \(T^{\theta}\) 与GELU结合在一起,后者是一些最先进模型中广泛使用的激活函数。回顾一下,GELU的定义为 \(\mathrm{GELU}(x) = x\cdot \Phi(x)\) ,其中 \(\Phi\) 是标准正态分布的累积分布函数。类似GELU的DiTAC函数是
\mathrm{DiTAC}(x) = \tilde{x}\cdot\Phi(x)\,,
\qquad
\tilde{x} = \begin{cases}
T^{\theta}(x) & \quad \text{If } a \leq x \leq b\\
x & \text{Otherwise}\\
\end{cases}\,
\end{align}
\]
其中 \(T^{\theta}\) 是一个(可学习的)CPAB变换,而 \(\Omega=[a,b]\) 是 \(T^{\theta}\) 的定义域,由用户定义。这个主要的DiTAC版本是在后续的实验中使用的。
还可以通过将 \(T^{\theta}\) 与各种其他激活函数结合来构建其他版本的DiTAC,而不仅仅是与GELU结合。例如Leaky-DiTAC,其中 \(T^{\theta}\) 作用于 \([a,b]\) ,而其余的数据则通过Leaky-ReLU(LReLU)函数处理。也就是说,
\mathrm{Leaky \ DiTAC}(x) =
\begin{cases}
T^{\theta}(x) & \quad \text{If } a \leq x \leq b\\ \mathrm{LReLU}(x) & \text{Otherwise}\\
\end{cases}
\end{align}
\]
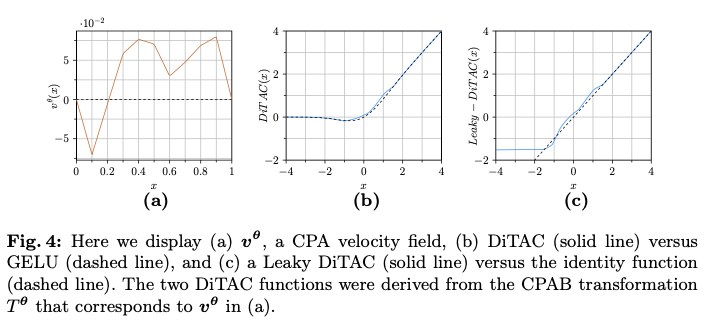
有关这两种DiTAC类型的说明,请参见图4。
为了稳定训练并防止学习过于极端的变换,还要对速度场进行了正则化:
\mathcal{L}_{\mathrm{reg}} = \sum\nolimits_{l=1}^{L} {{\theta}_l}^T \Sigma_{\mathrm{CPA}}^{-1} {\theta}_l
\end{align}
\]
其中, \(L\) 是网络中激活层的数量, \({\theta} \in {\mathbb{R}}^d\) 是DiTAC参数, \(\Sigma_{\mathrm{CPA}}^{-1}\) 是与高斯平滑先验(在文献中提出)相关的 \(d \times d\) 协方差矩阵,用于CPA速度场。该矩阵有两个超参数: \(\lambda_{var}\) ,用于控制速度场的方差,以及 \(\lambda_{smooth}\) ,用于控制不同子区间内速度的相似性,从而影响该场的平滑性(在机器学习的意义上)。
How to Drastically Reduce the Computational Cost
在深度学习(DL)中,训练通常涉及大量的激活函数(AF)调用。对于一个大小为 \((b,c,h,w)\) 的张量,其中 \(b\) 是批量大小, \(c\) 是通道数量, \((h,w)\) 是高度和宽度。对张量中的每个元素应用CPAB变换自然需要评估 \(b \cdot c \cdot h \cdot w\) 次。
例如,ResNet-50最后一个瓶颈块的AF在批量大小为32的情况下,操作约800K个元素。因此,尽管CPAB变换提供了表示微分同胚的高效解决方案,但在这里天真地使用这样的变换仍然可能在训练过程中产生显著的计算成本,并且过于缓慢。幸运的是,还有更好的方法。该方法能够在学习过程中显著减轻了这一成本。此外,在推理过程中,该解决方案使DiTAC与其他激活函数同样高效。
为了大幅降低学习过程中的成本,将区间 \([a,b]\) (CPAB变换应用的区间)量化为 \(n\) 个离散值,且均匀分布。尽管会丢失一些信息,但在神经网络中,量化激活通常对准确性几乎没有影响,只要使用足够多的元素(通常 \(2^8\) 就足够了)。在这种方法中,对量化后的元素集使用CPAB变换,并创建一个查找表,然后可以用来转换输入张量中所有条目的值。即输出 \(y_i=T^{\theta}(Q(x_i))\) ,其中 \(Q(\cdot)\) 是量化函数,并且 \(Q(x_i)\in\{ a+k\Delta \}_{k=0}^n\) ,其中 \(\Delta=\tfrac{b-a}{n}\) 。
在反向传播中,采用了一种直通估计器的变体。仅计算量化值输出的CPAB导数,然后将其广播为 \(x_i\) 的导数估计:
\frac{\partial T^{{\theta}}(x_i)}{\partial x_i} \approx \frac{\partial T^{{\theta}}(q_j)}{\partial q_j}, \enspace
\frac{\partial T^{{\theta}}(x_i)}{\partial \theta_\ell} \approx \frac{\partial T^{{\theta}}(q_j)}{\partial \theta_\ell}, \quad\text{where } q_j=Q(x_i).
\end{align}
\]
回顾ResNet-50的例子,只需对一个更小的条目集进行变换(例如, \(2^{10}=1024\ll 800K\) ),就可以对相同的输入实现几乎相同的结果。在学习过程中,每当 \({\theta}\) 发生变化时(快速)构建这样的查找表。一旦学习完成并在推理之前,将计算一个单一的查找表(每个DiTAC函数一个),并在推理过程中根据需要重复使用该查找表。
DiTAC Versions
DiTAC使用的CPAB变换 \(T^{\theta}\) 定义在一个有限区间上,即 \(\Omega=[a,b]\subset {\mathbb{R}}\) ,其共域也是一个有限区间。为了处理落在 \([a,b]\) 之外的输入数据,将 \(T^{\theta}\) 与GELU结合,GELU是一种在最新的先进模型中广泛使用的激活函数。通过将 \(T^{\theta}\) 与多种其他激活函数结合,或在CPAB的映射外定义某种函数(不一定是已知的激活函数),还可以构建DiTAC的其他版本。
需要注意的是,从概念上讲,可以通过首先应用一种将数据映射到 \(\Omega\) 的归一化方法,然后执行CPAB变换,最后将变换后的数据重新缩放回其原始范围,从而在整个输入数据上应用CPAB变换。然而,这样就必须提取整个输入数据的最小值和最大值,而这在训练过程中是很难实现的,因为这些值依赖于网络参数的学习。因此,在训练之前设置 \([a,b]\) 区间,通常包括大量的数据,并对超出该范围的数据应用不同的处理。
GELU-like DiTAC (DiTAC)
这是主要的DiTAC版本,也是所有实验中使用的版本。考虑到其在先进架构中的普遍性和成功,GELU是一个自然的选择。落在 \([a,b]\) 区间外的输入数据继承GELU的行为,而落在 \([a,b]\) 区间内的输入数据则首先经过CPAB变换,然后再通过GELU函数。
GELU-like DiTAC定义如下:
\mathrm{DiTAC}(x) = \tilde{x}\cdot\Phi(x)\,,
\qquad
\tilde{x} = \begin{cases}
T^{\theta}(x) & \quad \text{If } a \leq x \leq b\\
x & \text{Otherwise}\\
\end{cases}\,
\end{align}
\]
其中, \(\Phi\) 是标准正态分布的累积分布函数(CDF), \(T^{\theta}\) 是CPAB变换, \(\Omega=[a,b]\) 是 \(T^{\theta}\) 的定义域,由用户定义。
GELU-DiTAC (GE-DiTAC)
这种激活函数类似于DiTAC的主要版本,只是这里仅对负输入值应用GELU,而对输入数据范围 \([0, b]\) 进行纯CPAB变换。为了保持函数的连续性(如果对 \(v^{\theta}\) 施加零边界条件),对大于 \(b\) 的值应用恒等函数。
GE-DiTAC定义如下:
\mathrm{GE-DiTAC}(x) = \begin{cases}
x\cdot\Phi(x) & \quad \text{If } x < 0 \\
T^{\theta}(x) & \quad \text{If } 0 \leq x \leq b\\
x & \quad \text{If } x > b\\
\end{cases}\,
\end{align}
\]
其中, \(\Phi\) 是标准正态分布的累积分布函数(CDF), \(T^{\theta}\) 是CPAB变换, \(\Omega=[0,b]\) 是 \(T^{\theta}\) 的定义域,由用户定义。
需要注意的是,GE-DiTAC使CPAB变换的能力更加明显,因为这部分变换的数据并不与其他任何函数组合。从经验上看,在大多数实验中,它的表现与DiTAC相似,而它的优势主要在于使用简单网络进行简单回归任务时体现出来。
Leaky DiTAC (L-DiTAC)
这里 \(T^{\theta}\) 应用于 \([a,b]\) 区间,而其余数据通过Leaky-ReLU(LReLU)函数处理。也就是说,
\mathrm{Leaky \ DiTAC}(x) =
\begin{cases}
T^{\theta}(x) & \quad \text{If } a \leq x \leq b\\ \mathrm{LReLU}(x) & \text{Otherwise}\\
\end{cases}
\end{align}
\]
其中, \(T^{\theta}\) 是CPAB变换, \(\Omega[a,b]\) 是 \(T^{\theta}\) 的定义域,由用户定义。这种版本可以被视为ReLU的一个更具表现力的版本。如所示,不同的激活函数(AFs)适合不同类型的数据和任务。这个DiTAC版本可能会改善在ReLU函数表现优于其他现有激活函数的问题。
Infinite-edges DiTAC (inf-DiTAC)
CPAB变换是通过对 \(\mathcal{V}\) 中的元素进行积分而获得的, \(\mathcal{V}\) 是一个从 \(\Omega\) 到 \({\mathbb{R}}\) 的连续函数空间,这些函数对于 \(\Omega\) 的某个固定划分为分段仿射的。在inf-DiTAC中,类似于GE-DiTAC和L-DiTAC, \(T^{\theta}\) 应用于 \([a,b]\) 区间。对于落在该范围之外的输入数据,应用在 \(\Omega\) 的剖分(最右和最左单元)两侧学习到的仿射变换,从而产生一个完全由CPAB变换参数控制的连续激活函数。
inf-DiTAC定义如下:
\mathrm{inf-DiTAC}(x) =
\begin{cases}
A_{l}^{\theta} x & \quad \text{If } x < a \\
T^{\theta}(x) & \quad \text{If } a \leq x \leq b \\
A_{r}^{\theta} x & \quad \text{If } x > b \\
\end{cases}
\end{align}
\]
其中, \(T^{\theta}\) 是CPAB变换, \(A_{l}^{\theta}\) 和 \(A_{r}^{\theta}\) 分别是在剖分中最左和最右单元的仿射变换,而 \(\Omega[a,b]\) 是 \(T^{\theta}\) 的定义域,由用户定义。
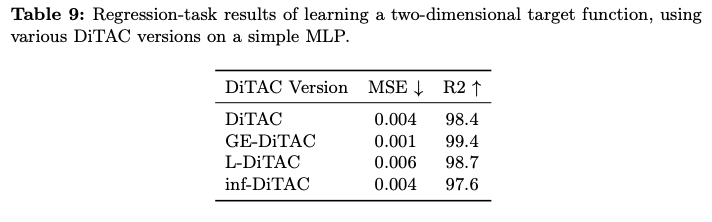
在表9中,展示了所有上述DiTAC版本在论文中提出的二维函数重建任务上的性能评估。可以看出,GE-DiTAC在这个特定任务上提供了最佳性能。
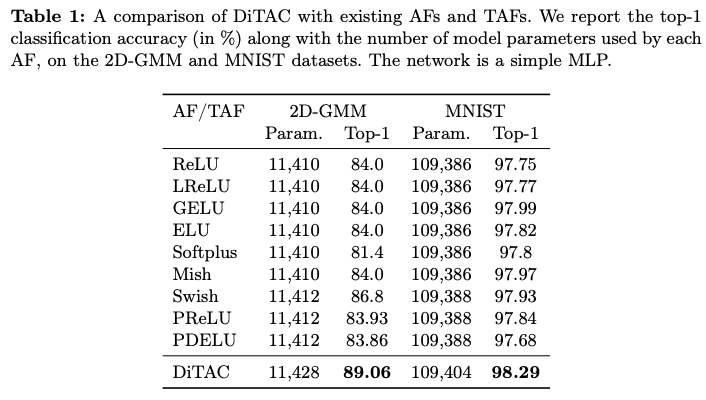
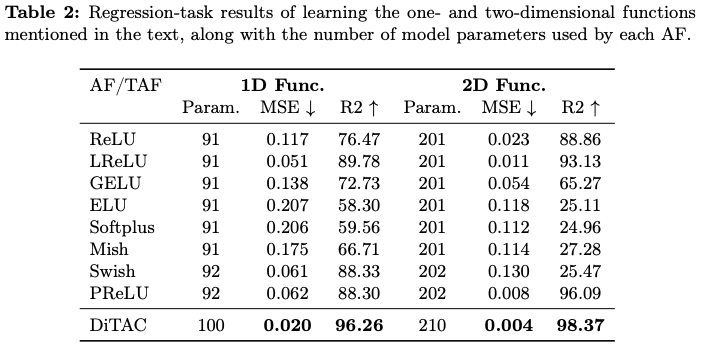
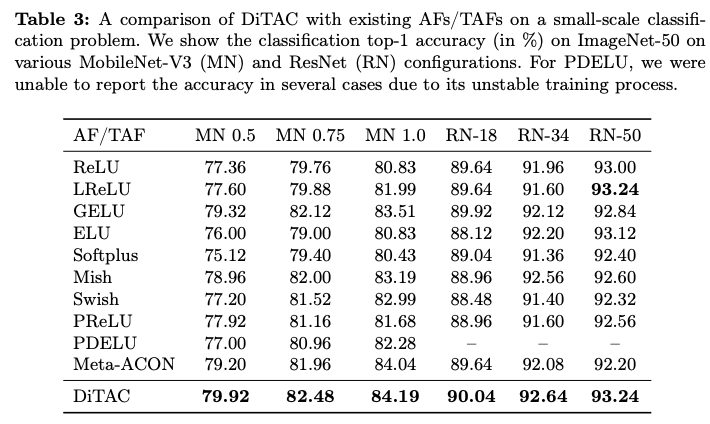
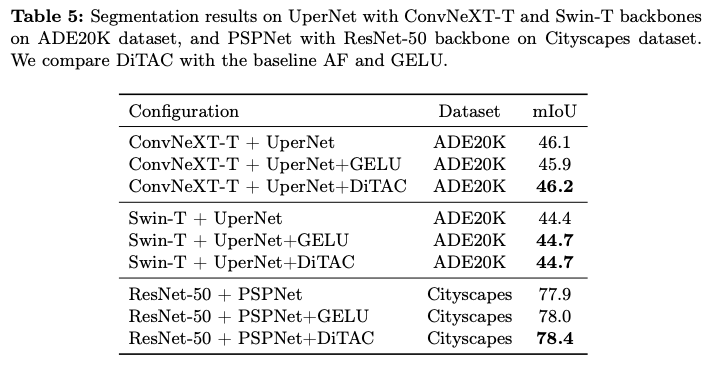
Results
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

DiTAC:不知如何提升性能?试试这款基于微分同胚变换的激活函数 | ECCV'24的更多相关文章
- 还在写CURD?试试这款基于mybatis-plus的springboot代码生成器
目录 ⚡Introduction ✔️Release Features Quick Start Examples 1.Controller模板代码示例 2.Service模板代码示例 3.Servic ...
- 从零开始写一个武侠冒险游戏-8-用GPU提升性能(3)
从零开始写一个武侠冒险游戏-8-用GPU提升性能(3) ----解决因绘制雷达图导致的帧速下降问题 作者:FreeBlues 修订记录 2016.06.23 初稿完成. 2016.08.07 增加对 ...
- 从零开始写一个武侠冒险游戏-7-用GPU提升性能(2)
从零开始写一个武侠冒险游戏-7-用GPU提升性能(2) ----把地图处理放在GPU上 作者:FreeBlues 修订记录 2016.06.21 初稿完成. 2016.08.06 增加对 XCode ...
- atitit.提升性能AppCache
atitit.提升性能AppCache 1.1. 起源1 2. 离线存储2 3. AppCache2 3.1. Appcache事件点如图2 3.2. Manifest文件4 3.3. 自动化工具4 ...
- SQL Server中使用Check约束提升性能
在SQL Server中,SQL语句的执行是依赖查询优化器生成的执行计划,而执行计划的好坏直接关乎执行性能. 在查询优化器生成执行计划过程中,需要参考元数据来尽可能生成高效的执行计划, ...
- paip.提升性能--多核cpu中的java/.net/php/c++编程
paip.提升性能--多核cpu中的java/.net/php/c++编程 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http ...
- paip. 提升性能---hibernate的缓存使用 总结
paip. 提升性能---hibernate的缓存使用 总结 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://blog ...
- Android ViewPager Fragment使用懒加载提升性能
Android ViewPager Fragment使用懒加载提升性能 Fragment在如今的Android开发中越来越普遍,但是当ViewPager结合Fragment时候,由于Androi ...
- paip.提升性能---mysql 优化cpu多核以及lan性能的关系.
paip.提升性能---mysql 优化cpu多核以及lan性能的关系. 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http:/ ...
- paip.提升性能---mysql 性能 测试以及 参数调整.txt
paip.提升性能---mysql 性能 测试以及 参数调整.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://b ...
随机推荐
- 【Redis】01 NoSQL概述 & Redis
NoSQL概述: 1.什么是NoSQL NoSQL 是 Not Only SQL 的缩写,意即"不仅仅是SQL"的意思,泛指非关系型的数据库.强调Key-Value Stores和 ...
- 如何访问SCI-Hub上的资源?
答案: 使用tor访问.onion网络资源. tor 下载地址: https://www.torproject.org/ 如果不使用tor方式访问可能会无法访问,被提示:
- IPython notebook(Jupyter notebook)指定IP和端口运行
1. 使用conda 安装 jupyter conda install jupyter 2. 在服务器端不打开浏览器,指定 端口, IP , 运行jupyter notebook 这里假设端口 ...
- JVM指令大全之不太全系列
一.未归类系列A 此系列暂未归类. 指令码 助记符 说明0x00 nop ...
- Linux库概念,动态库和静态库的制作,如何移植第三方库
一.什么是库? 在windows平台和linux平台下都大量存在着库.一般是软件作者为了发布方便.替换方便或二次开发目的,而发布的一组可以单独与应用程序进行compile time或runtime链接 ...
- 寻访中国100家.NET中大企业 —— 第二站:苏州行
一:事情起因 在.NET圈里混了十多年,相信有不少人知道我专注于玩 .NET高级调试,如今技术上的硬实力还是能够解决市面上的一些疑难杂症,但软实力却在另一个极端,如(人际交往,人情事故),所以就萌生了 ...
- dfs剪枝与优化
搜索树 剪枝方法 1.优化搜索顺序 2.排除等效冗余 3.可行性 4.最优性(估价) 5.记忆化(树形不会重复计算时不需要) A.针对每个维度边界信息缩放.推倒 B.计算未来最少花费 C.结合各维度的 ...
- AI的那些名词
AI 是什么? Artificial Intelligence,即人工智能,1956年于Dartmouth学会上提出,一种旨在以类似人类反应的方式对刺激做出反应并从中学习的技术,其理解和判断水平通常只 ...
- .NET 摄像头采集
本文主要介绍摄像头(相机)如何采集数据,用于类似摄像头本地显示软件,以及流媒体数据传输场景如传屏.视讯会议等. 摄像头采集有多种方案,如AForge.NET.WPFMediaKit.OpenCvSha ...
- hashmap组成原理及调用时机
整个HashMap中最重要的点有四个:初始化,数据寻址-hash方法,数据存储-put方法,扩容-resize方法,只要理解了这四个点的原理和调用时机,也就理解了整个HashMap的设计. 如果有疑惑 ...