PaddleNLP UIE -- 药品说明书信息抽取(名称、规格、用法、用量)
PaddleNLP UIE 实体关系抽取 -- 抽取药品说明书(名称、规格、用法、用量)
对于细分场景推荐使用轻定制功能(标注少量数据进行模型微调)以进一步提升效果
schema =['药品名称','用法','用量','频次']
ie = Taskflow('information_extraction',schema=schema)
pprint(ie("布洛芬分散片,口服或加水分散后服用。用于成人及12岁以上儿童,推荐剂里为一次0.2~0.4(1~2片)一日3次,或遵医嘱"))
如图:默认模型只能提取出药品名称,接下来,通过训练数据进行UIE模型微调

创建项目
登录AI Studio 免费算力 获得免费算力 https://aistudio.baidu.com/personalcenter/thirdview/2631487
药品说明书信息抽取
选择环境 PaddlePaddle 2.5.2
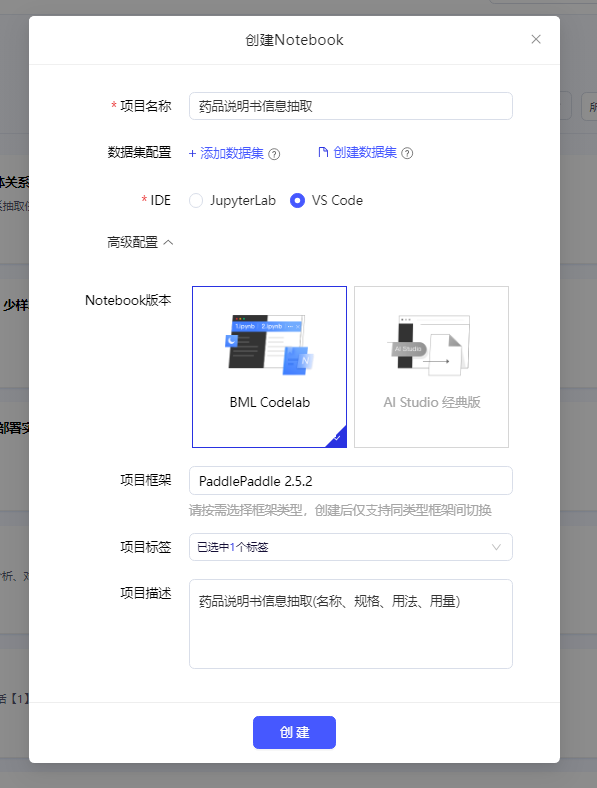
启动时,可以选择环境,CPU的基础版不限时,每天有8个点的算力供学习使用
环境配置
自己创建项目有个好处,避免了好多版本问题带来的坑:https://www.cnblogs.com/vipsoft/p/18265581#问题处理
- Python 3.10.10
- paddlepaddle-gpu Version: 2.5.2
- PaddleNLP 2.6.1
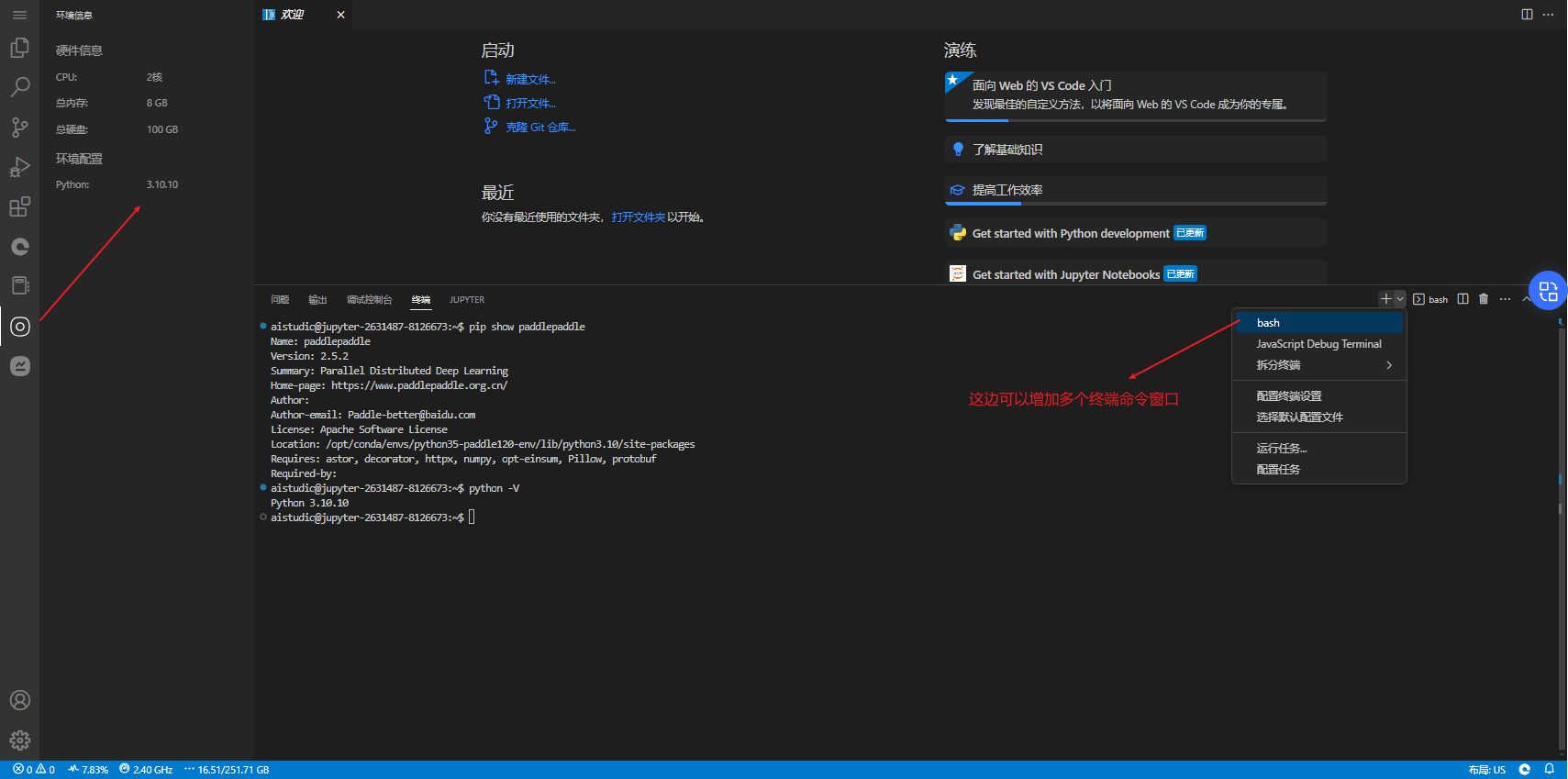
上传代码
AI Studio 不能访问 gitee.com ,通过本地下载。再上传的方式操作
下载 V2.8:https://gitee.com/paddlepaddle/PaddleNLP/branches
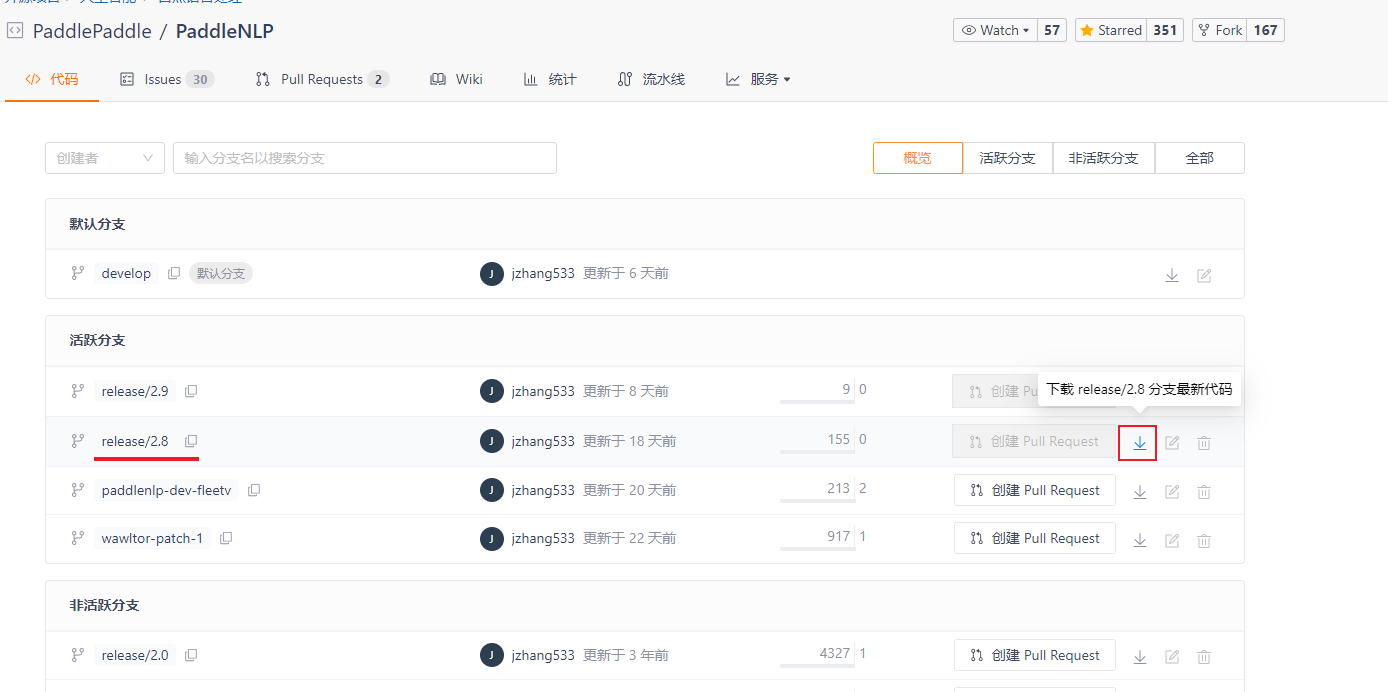
上传代码
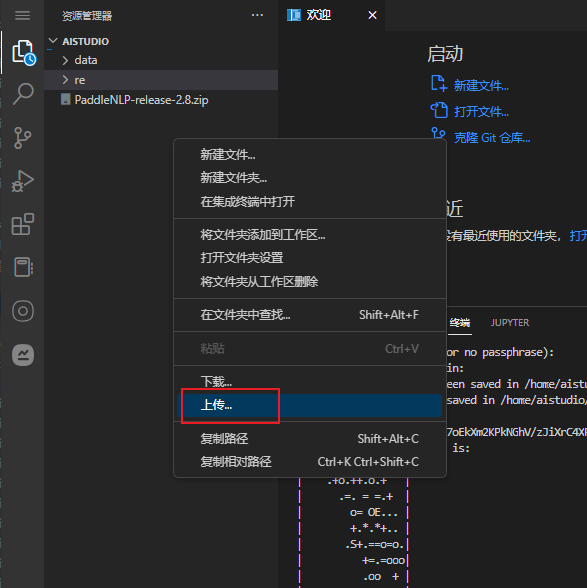
解压代码
unzip PaddleNLP-release-2.8.zip
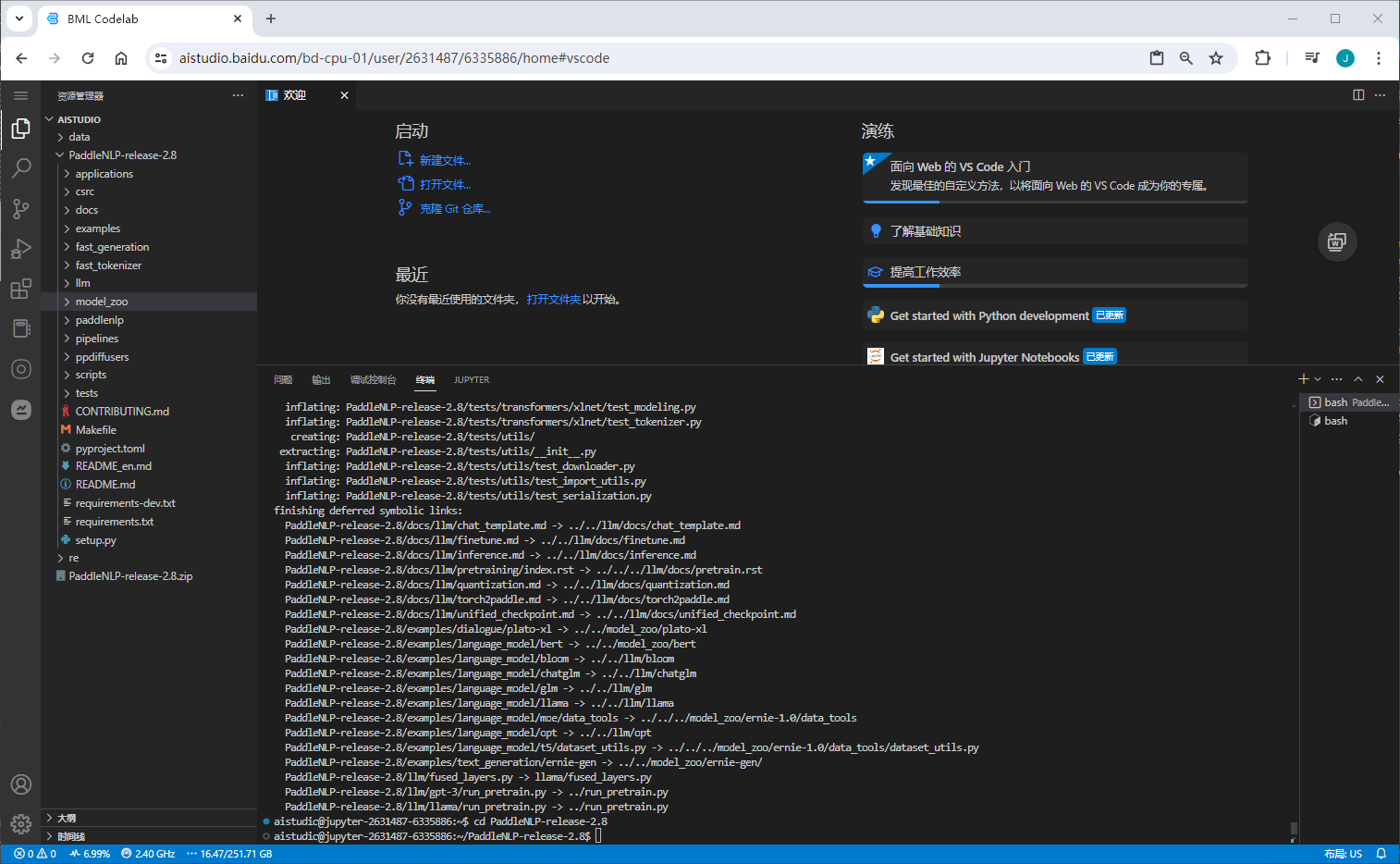
训练定制
代码结构
model_zoo/uie 目录代码文件说明如下:
.
├── utils.py # 数据处理工具
├── model.py # 模型组网脚本
├── doccano.py # 数据标注脚本 => 下面数据转换时会用到
├── doccano.md # 数据标注文档
├── finetune.py # 模型微调、压缩脚本
├── evaluate.py # 模型评估脚本
└── README.md
数据标注
详细过程参考 数据标注工具 doccano | 命名实体识别(Named Entity Recognition,简称NER)
准备语料库
准备语料库、每一行为一条待标注文本,示例:corpus.txt
布洛芬分散片,口服或加水分散后服用。用于成人及12岁以上儿童,推荐剂里为一次0.2~0.4(1~2片)一日3次,或遵医嘱
白加黑(氨酚伪麻美芬片Ⅱ氨麻苯美片),口服。一次1~2片,一日3次(早、中各1~2白片,夜晚1~2片黑片),儿童遵医嘱
氯雷他定片,口服,规格为10mg的氯雷他定片,通常成人及12岁以上儿童1天1次,1次1片
扶他林(双氯芬酸二乙胺乳胶剂),外用。按照痛处面积大小,使用本品适量,轻轻揉搓,使本品渗透皮肤,一日3-4次
七叶洋地黄双苷,外用。用于黄斑变性时,每日3次,每次1滴,滴入眼结膜囊内(近耳侧外眼角)
数据标注
定义标签
Demo简单的定了 "药品名称、通用名、规格、用法、用量、频次"
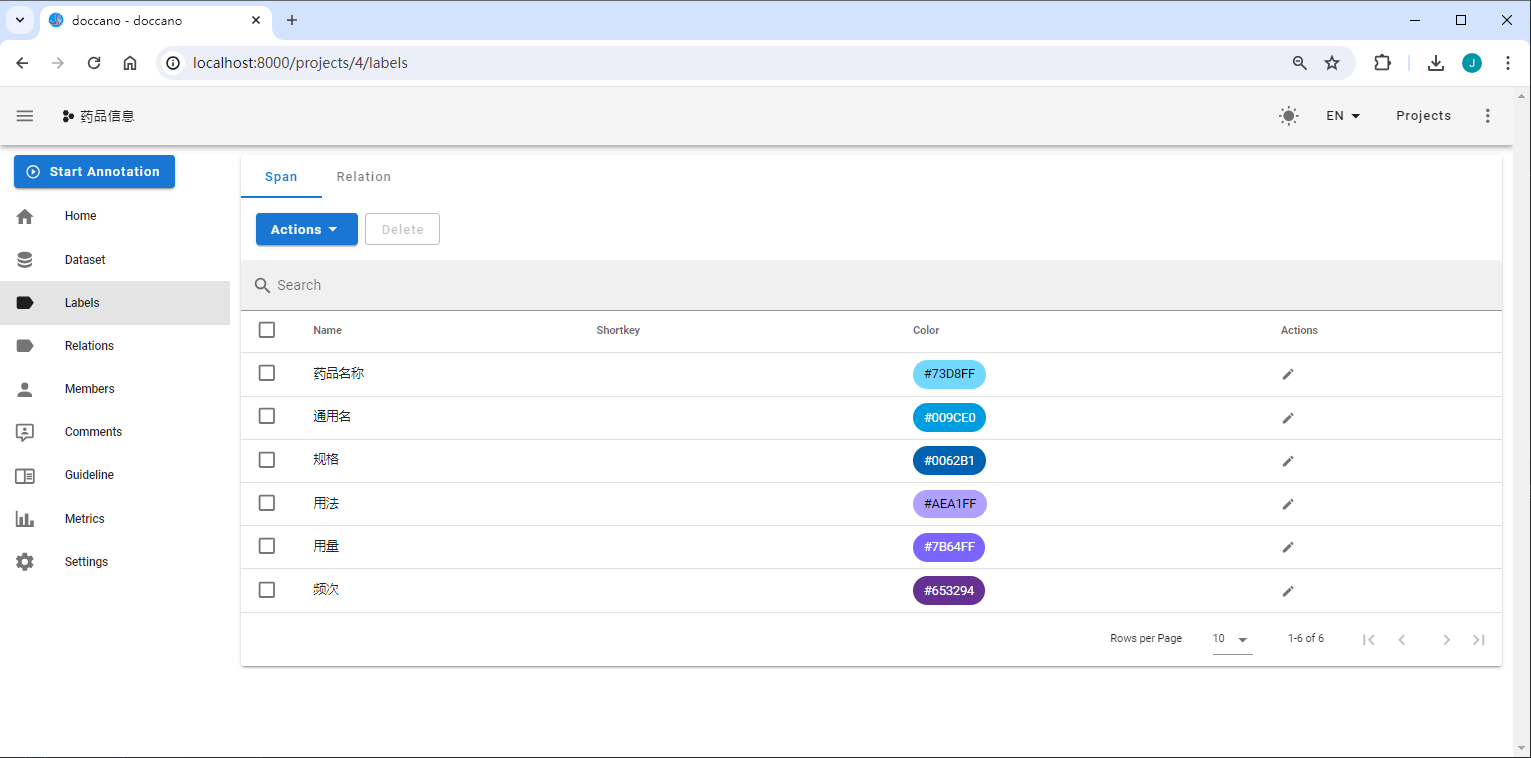
数据标注
在doccano平台上,创建一个类型为序列标注的标注项目。
定义实体标签类别,上例中需要定义的实体标签有[ 药品名称、通用名、规格、用法、用量、频次 ]。
使用以上定义的标签开始标注数据,下面展示了一个doccano标注示例:
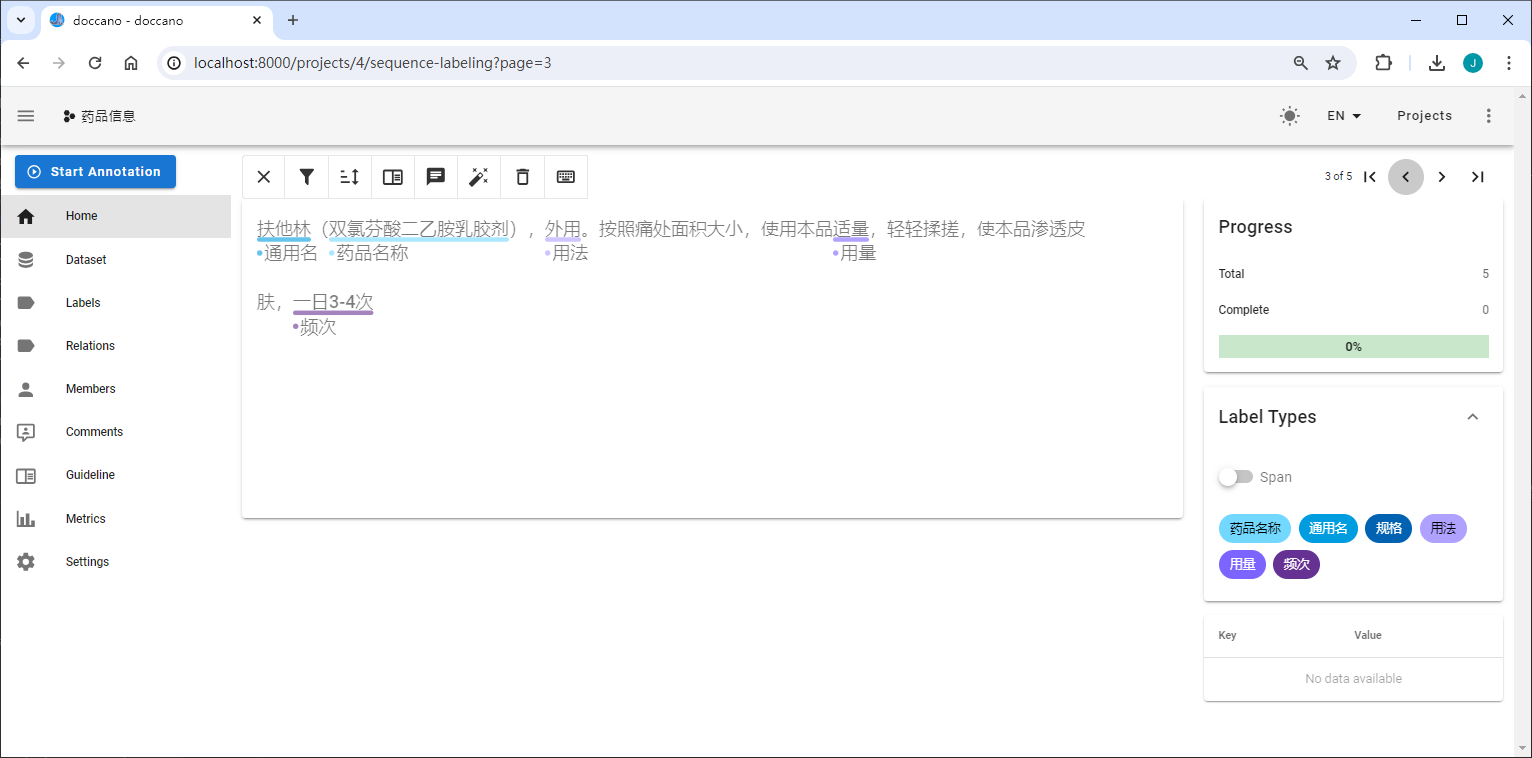
导出数据
标注完成后,在doccano平台上导出文件,并将其重命名为doccano_ext.json后,放入./data目录下
数据转换
doccano
在 AI Studio 环境中创建 data 目录,将 doccano_ext.json 放入data目录中
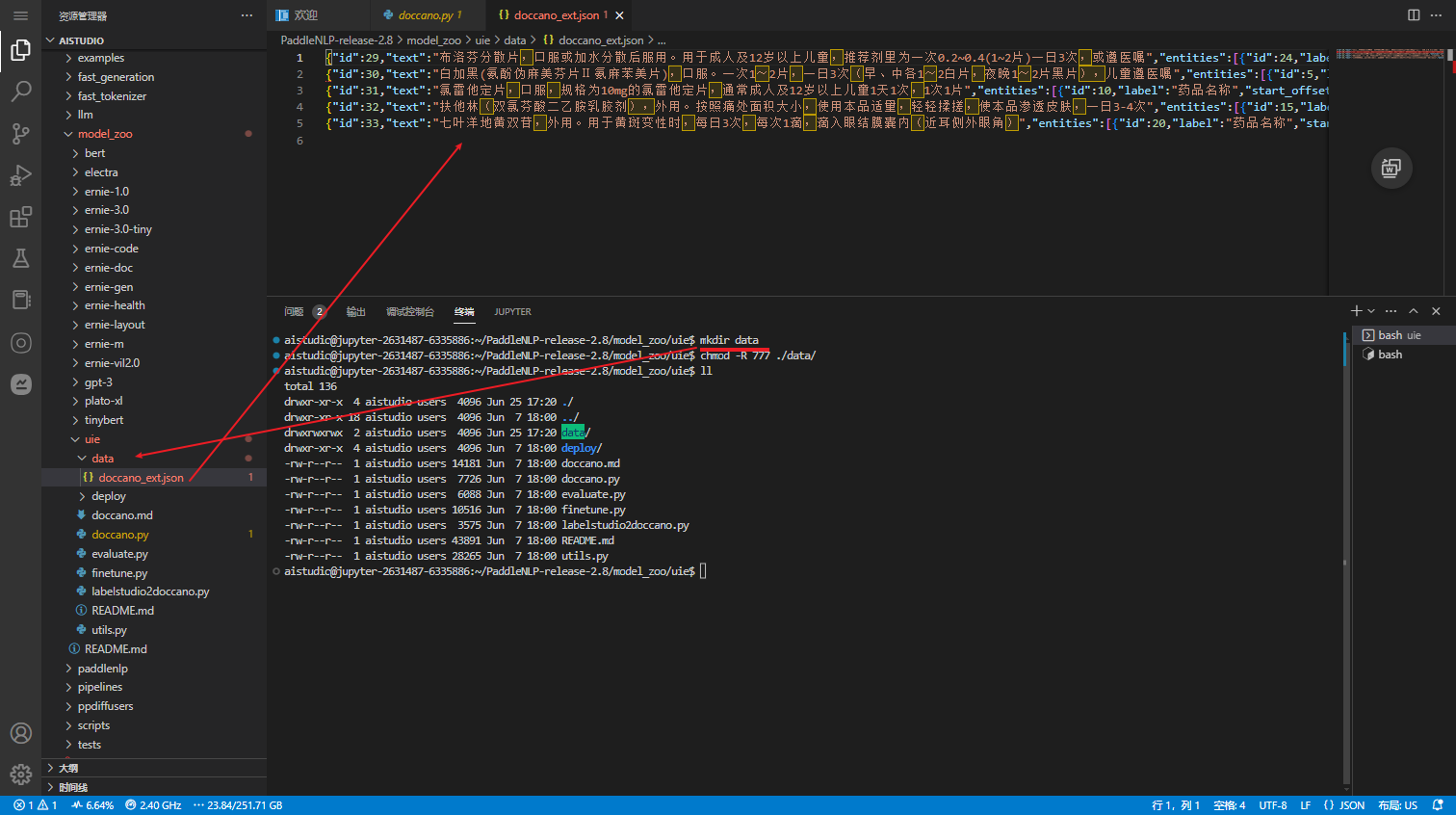
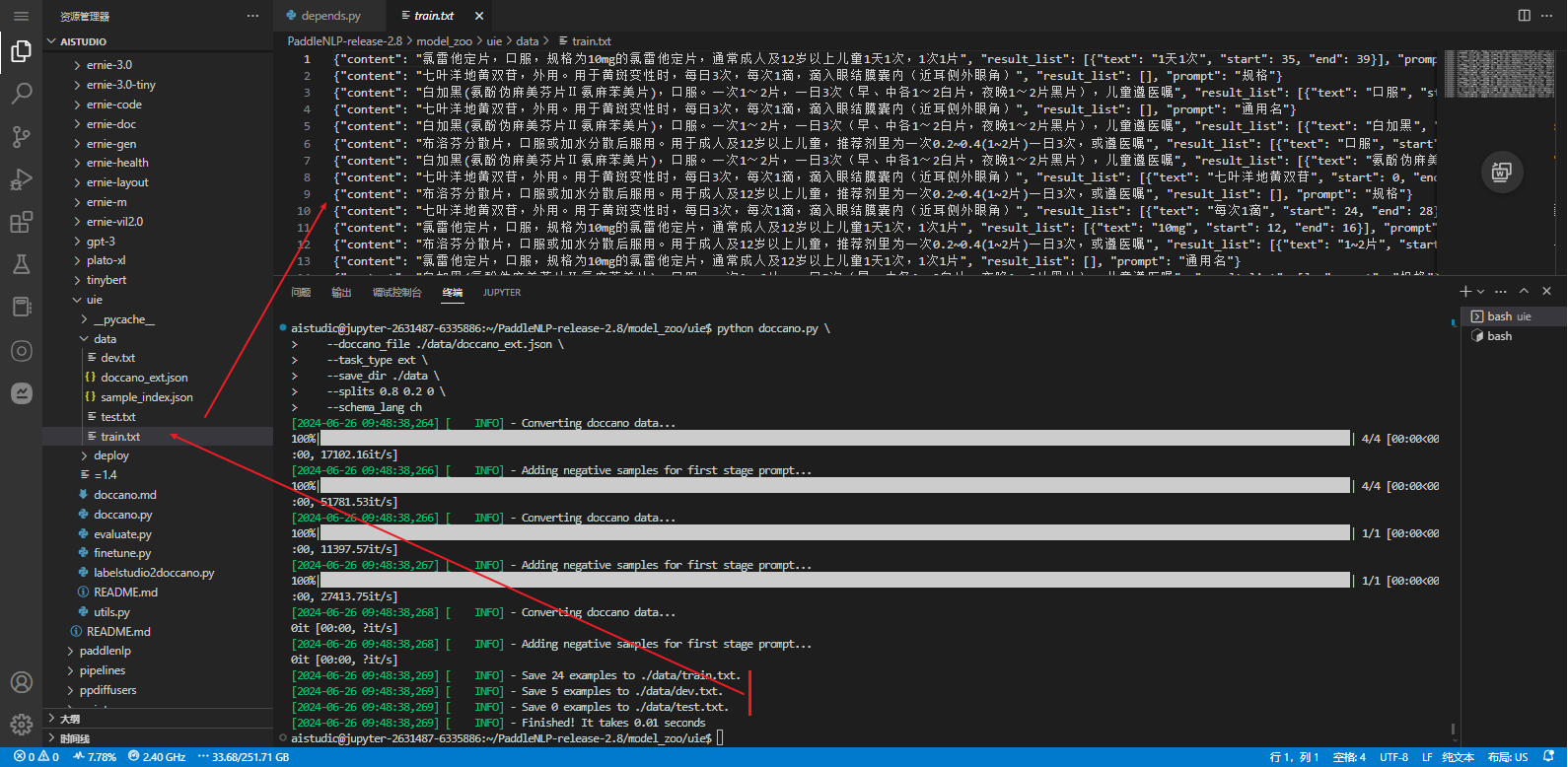
执行以下脚本进行数据转换,执行后会在./data目录下生成训练/验证/测试集文件。
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0 \
--schema_lang ch
# 执行后会在./data目录下生成训练/验证/测试集文件。
[2024-06-26 09:48:38,269] [ INFO] - Save 24 examples to ./data/train.txt.
[2024-06-26 09:48:38,269] [ INFO] - Save 5 examples to ./data/dev.txt.
[2024-06-26 09:48:38,269] [ INFO] - Save 0 examples to ./data/test.txt.
可配置参数说明:
doccano_file: 从doccano导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。task_type: 选择任务类型,可选有抽取和分类两种类型的任务。options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为["正向", "负向"]。prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。
备注:
- 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过
negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。 - 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
Label Studio
也可以通过数据标注平台 Label Studio 进行数据标注。 labelstudio2doccano.py 脚本,将 label studio 导出的 JSON 数据文件格式转换成 doccano 导出的数据文件格式,后续的数据转换与模型微调等操作不变。
python labelstudio2doccano.py --labelstudio_file label-studio.json
可配置参数说明:
labelstudio_file: label studio 的导出文件路径(仅支持 JSON 格式)。doccano_file: doccano 格式的数据文件保存路径,默认为 "doccano_ext.jsonl"。task_type: 任务类型,可选有抽取("ext")和分类("cls")两种类型的任务,默认为 "ext"。
模型微调
注意使用GPU环境
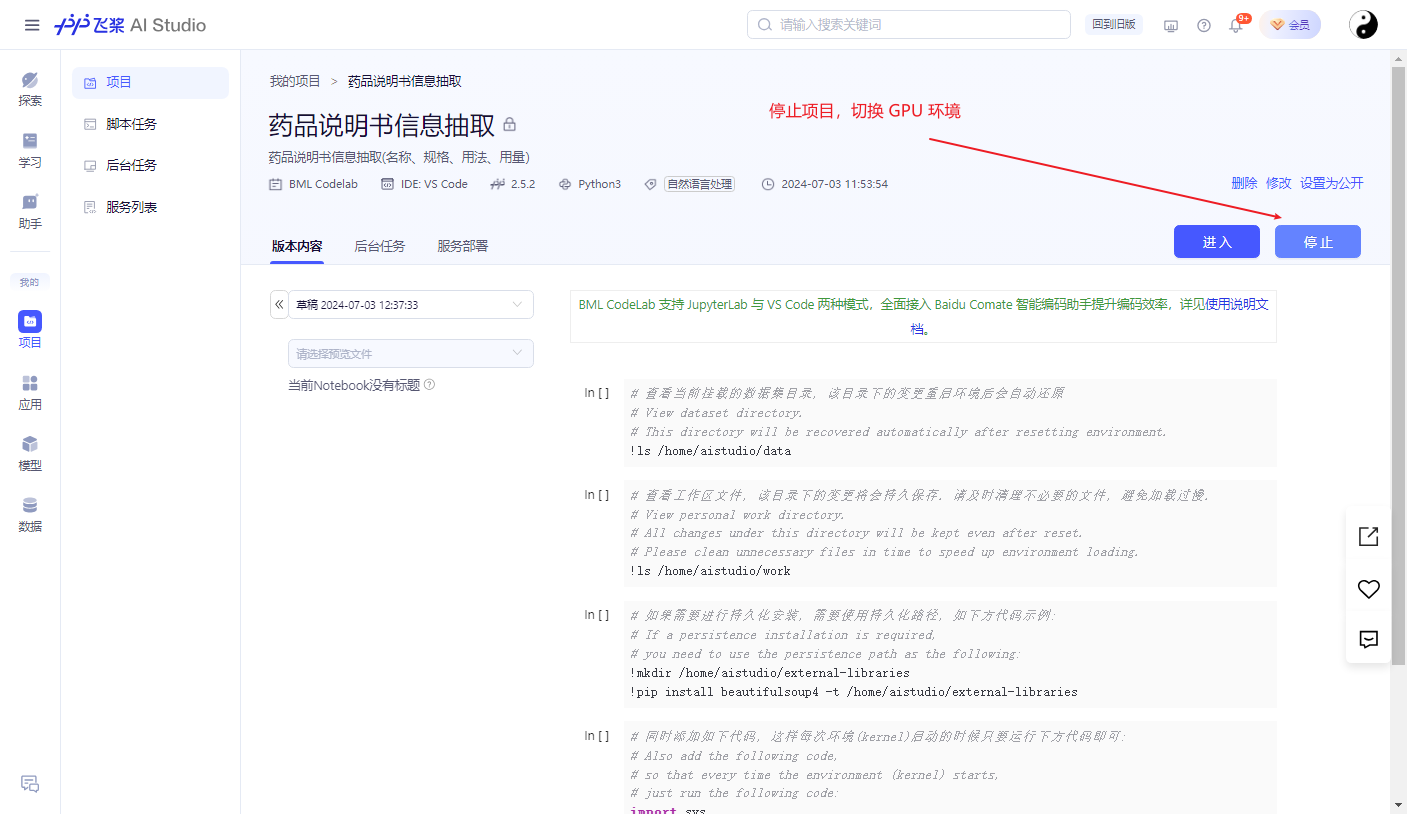
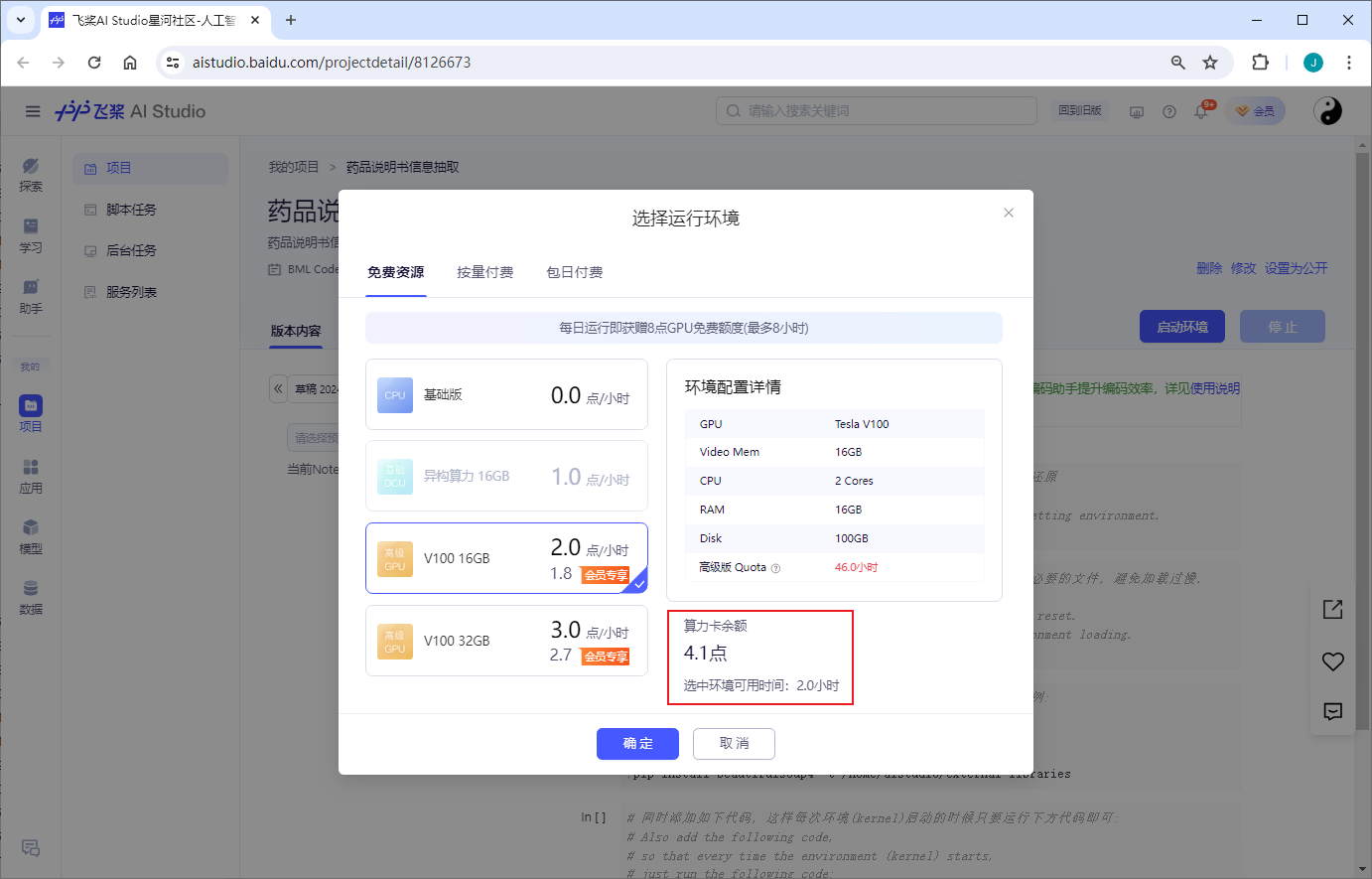
启用GPU 环境
aistudio@jupyter-2631487-8126673:~$ python -V
Python 3.10.10
aistudio@jupyter-2631487-8126673:~$ pip show paddlepaddle-gpu
Name: paddlepaddle-gpu
Version: 2.5.2
Summary: Parallel Distributed Deep Learning
Home-page: https://www.paddlepaddle.org.cn/
Author:
Author-email: Paddle-better@baidu.com
License: Apache Software License
Location: /opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages
Requires: astor, decorator, httpx, numpy, opt-einsum, Pillow, protobuf
Required-by:
aistudio@jupyter-2631487-8126673:~$ pip show paddlenlp
Name: paddlenlp
Version: 2.6.1.post0
Summary: Easy-to-use and powerful NLP library with Awesome model zoo, supporting wide-range of NLP tasks from research to industrial applications, including Neural Search, Question Answering, Information Extraction and Sentiment Analysis end-to-end system.
Home-page: https://github.com/PaddlePaddle/PaddleNLP
Author: PaddleNLP Team
Author-email: paddlenlp@baidu.com
License: Apache 2.0
Location: /opt/conda/envs/python35-paddle120-env/lib/python3.10/site-packages
Requires: aistudio-sdk, colorama, colorlog, datasets, dill, fastapi, Flask-Babel, huggingface-hub, jieba, jinja2, multiprocess, onnx, paddle2onnx, paddlefsl, protobuf, rich, safetensors, sentencepiece, seqeval, tool-helpers, tqdm, typer, uvicorn, visualdl
Required-by: paddlehub
aistudio@jupyter-2631487-8126673:~$
推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至$finetuned_model:
单卡启动:
cd PaddleNLP-release-2.8/model_zoo/uie/
export finetuned_model=./checkpoint/model_best
python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 42 \
--model_name_or_path uie-base \
--output_dir $finetuned_model \
--train_path data/train.txt \
--dev_path data/dev.txt \
--per_device_eval_batch_size 16 \
--per_device_train_batch_size 16 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--label_names "start_positions" "end_positions" \
--do_train \
--do_eval \
--do_export \
--export_model_dir $finetuned_model \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
注意:如果模型是跨语言模型 UIE-M,还需设置 --multilingual。
可配置参数说明:
model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 "uie-base"、 "uie-medium", "uie-mini", "uie-micro", "uie-nano", "uie-m-base", "uie-m-large"。multilingual:是否是跨语言模型,用 "uie-m-base", "uie-m-large" 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。device: 训练设备,可选择 'cpu'、'gpu' 、'npu'其中的一种;默认为 GPU 训练。per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估。
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
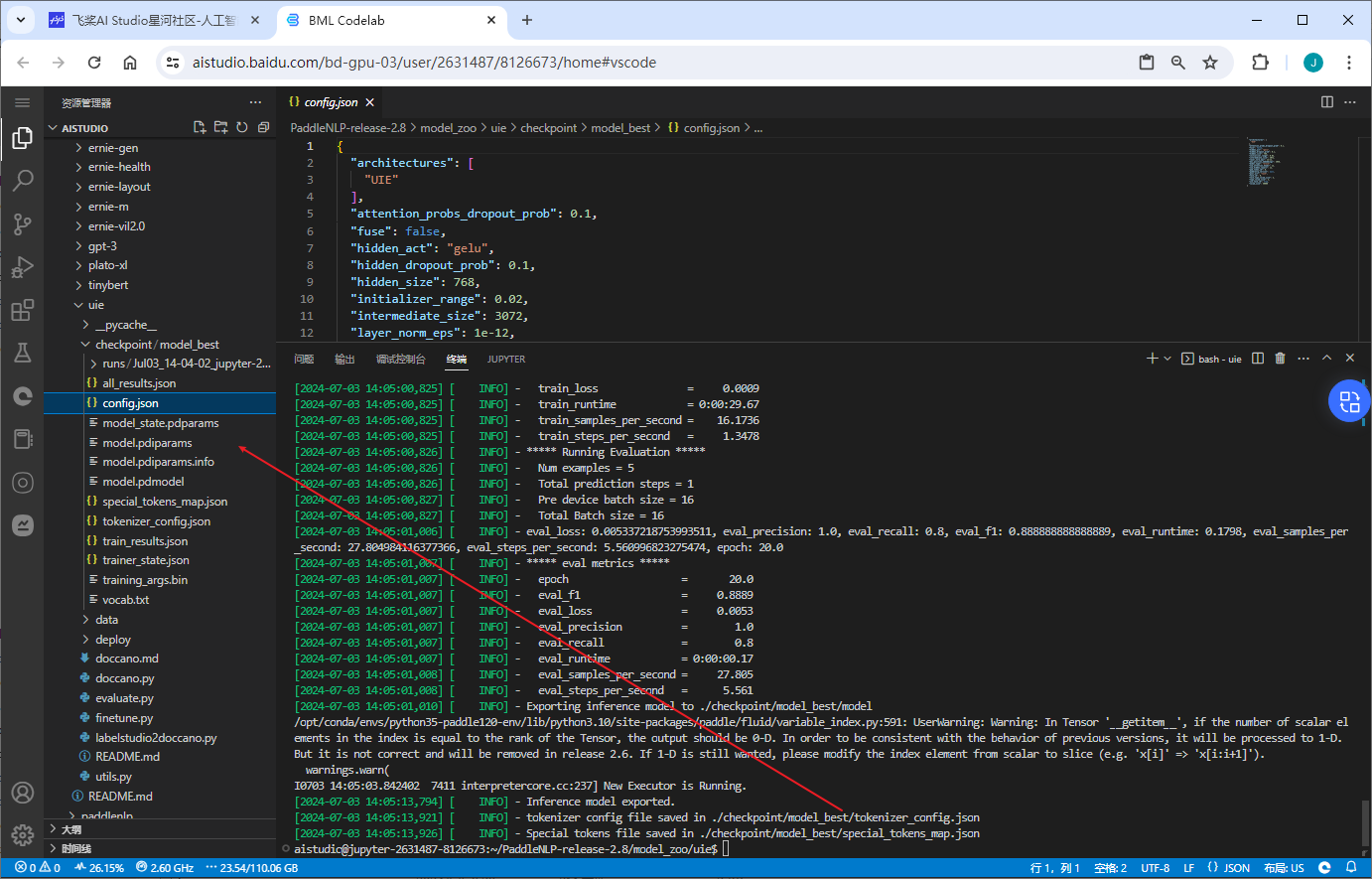
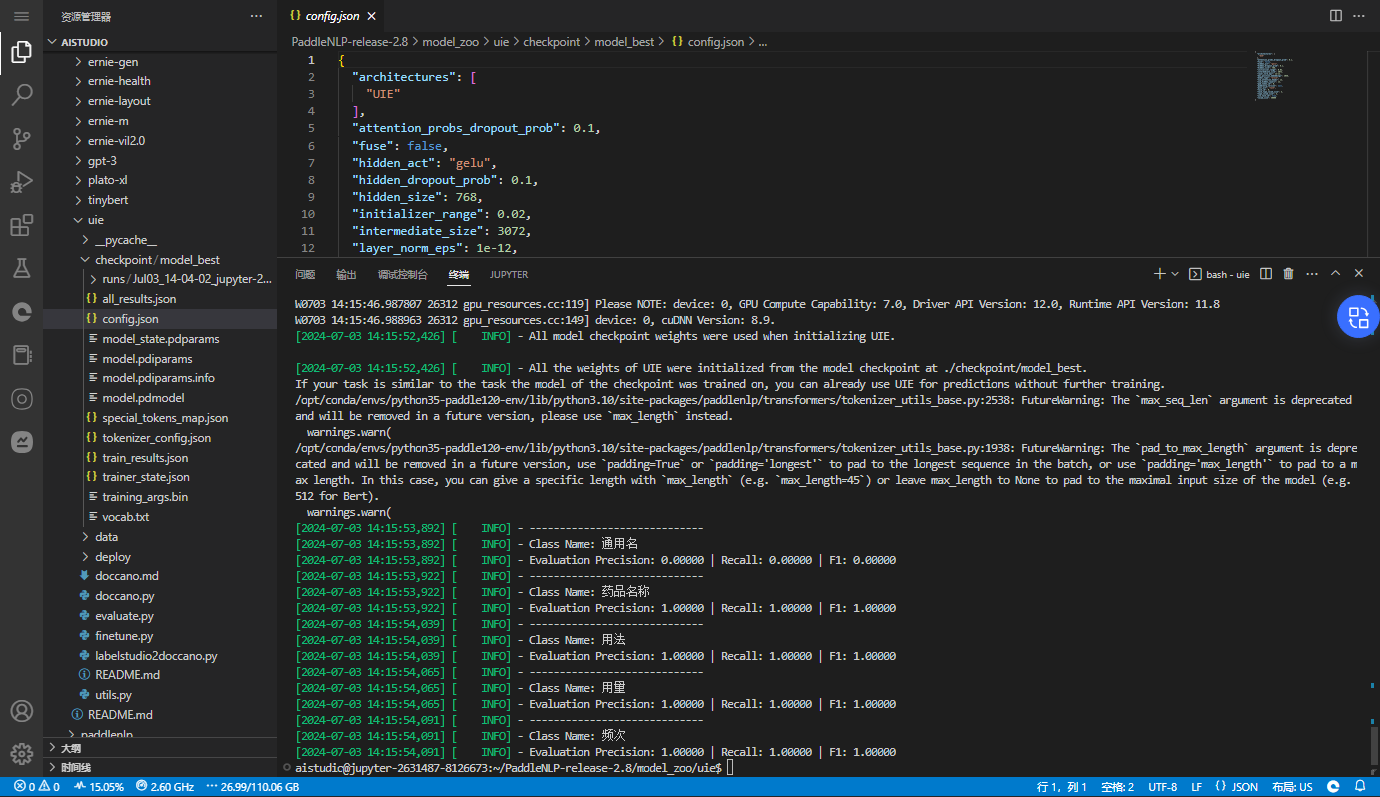
模型评估
通过运行以下命令进行模型评估:
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
输出:
[2024-07-03 14:14:16,345] [ INFO] - Class Name: all_classes
[2024-07-03 14:14:16,345] [ INFO] - Evaluation Precision: 1.00000 | Recall: 0.80000 | F1: 0.88889
通过运行以下命令对 UIE-M 进行模型评估:
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512 \
--multilingual
评估方式说明:采用单阶段评价的方式,即关系抽取、事件抽取等需要分阶段预测的任务对每一阶段的预测结果进行分别评价。验证/测试集默认会利用同一层级的所有标签来构造出全部负例。
可开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试:
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--debug
输出:
[2024-07-03 14:15:53,892] [ INFO] - -----------------------------
[2024-07-03 14:15:53,892] [ INFO] - Class Name: 通用名
[2024-07-03 14:15:53,892] [ INFO] - Evaluation Precision: 0.00000 | Recall: 0.00000 | F1: 0.00000
[2024-07-03 14:15:53,922] [ INFO] - -----------------------------
[2024-07-03 14:15:53,922] [ INFO] - Class Name: 药品名称
[2024-07-03 14:15:53,922] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2024-07-03 14:15:54,039] [ INFO] - -----------------------------
[2024-07-03 14:15:54,039] [ INFO] - Class Name: 用法
[2024-07-03 14:15:54,039] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2024-07-03 14:15:54,065] [ INFO] - -----------------------------
[2024-07-03 14:15:54,065] [ INFO] - Class Name: 用量
[2024-07-03 14:15:54,065] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
[2024-07-03 14:15:54,091] [ INFO] - -----------------------------
[2024-07-03 14:15:54,091] [ INFO] - Class Name: 频次
[2024-07-03 14:15:54,091] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000
可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。multilingual: 是否是跨语言模型,默认关闭。schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。
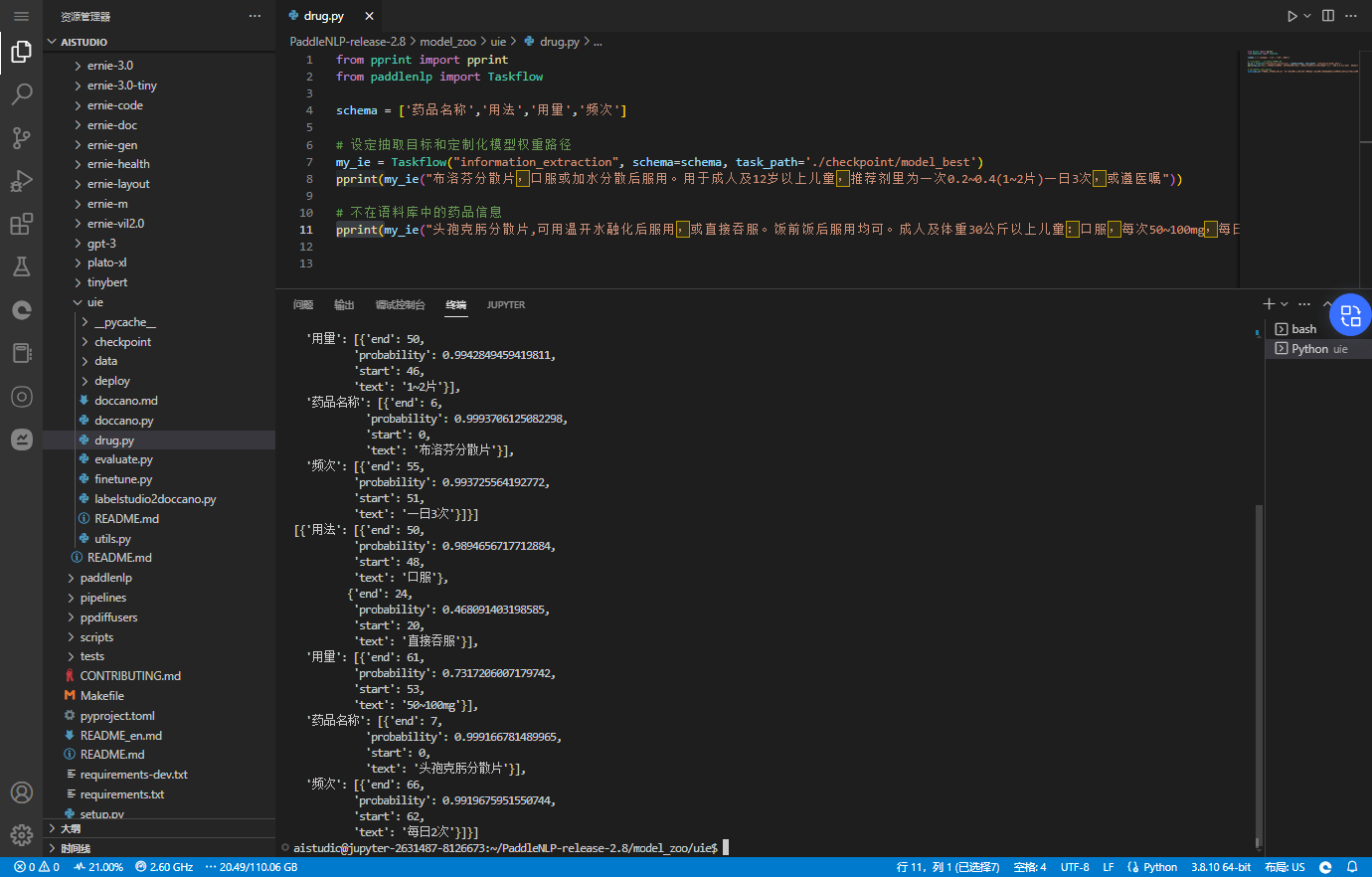
定制模型--预测
在 uie 目录下创建测试文件 drug.py (也可直接在终端命令行中敲,个人比较喜欢用文件的方式执行)
from pprint import pprint
from paddlenlp import Taskflow
schema = ['药品名称','用法','用量','频次']
# 设定抽取目标和定制化模型权重路径
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
pprint(my_ie("布洛芬分散片,口服或加水分散后服用。用于成人及12岁以上儿童,推荐剂里为一次0.2~0.4(1~2片)一日3次,或遵医嘱"))
# 不在语料库中的药品信息
pprint(my_ie("头孢克肟分散片,可用温开水融化后服用,或直接吞服。饭前饭后服用均可。成人及体重30公斤以上儿童:口服,每次50~100mg,每日2次;"))
注意到 drug.py 所在的目录 uie 下运行
aistudio@jupyter-2631487-8126673:~/PaddleNLP-release-2.8/model_zoo/uie$ python drug.py
输出
[{'用法': [{'end': 9,
'probability': 0.9967116760425654,
'start': 7,
'text': '口服'}],
'用量': [{'end': 50,
'probability': 0.9942849459419811,
'start': 46,
'text': '1~2片'}],
'药品名称': [{'end': 6,
'probability': 0.9993706125082298,
'start': 0,
'text': '布洛芬分散片'}],
'频次': [{'end': 55,
'probability': 0.993725564192772,
'start': 51,
'text': '一日3次'}]}]
[{'用法': [{'end': 50,
'probability': 0.9894656717712884,
'start': 48,
'text': '口服'},
{'end': 24,
'probability': 0.468091403198585,
'start': 20,
'text': '直接吞服'}],
'用量': [{'end': 61,
'probability': 0.7317206007179742,
'start': 53,
'text': '50~100mg'}],
'药品名称': [{'end': 7,
'probability': 0.999166781489965,
'start': 0,
'text': '头孢克肟分散片'}],
'频次': [{'end': 66,
'probability': 0.9919675951550744,
'start': 62,
'text': '每日2次'}]}]
效果
项目地址:
药品说明书信息抽取:https://aistudio.baidu.com/projectdetail/8126673?sUid=2631487&shared=1&ts=1719990517603
PaddleNLP UIE -- 药品说明书信息抽取(名称、规格、用法、用量)的更多相关文章
- 基于Label studio实现UIE信息抽取智能标注方案,提升标注效率!
基于Label studio实现UIE信息抽取智能标注方案,提升标注效率! 项目链接见文末 人工标注的缺点主要有以下几点: 产能低:人工标注需要大量的人力物力投入,且标注速度慢,产能低,无法满足大规模 ...
- [信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取
[信息抽取]基于ERNIE3.0的多对多信息抽取算法:属性关系抽取 实体关系,实体属性抽取是信息抽取的关键任务:实体关系抽取是指从一段文本中抽取关系三元组,实体属性抽取是指从一段文本中抽取属性三元组: ...
- 基于ERNIELayout&pdfplumber-UIE的多方案学术论文信息抽取
本项目链接:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1 基于ERNIELayout& ...
- NLP知识图谱项目合集(信息抽取、文本分类、图神经网络、性能优化等)
NLP知识图谱项目合集(信息抽取.文本分类.图神经网络.性能优化等) 这段时间完成了很多大大小小的小项目,现在做一个整体归纳方便学习和收藏,有利于持续学习. 1. 信息抽取项目合集 1.PaddleN ...
- ACL2016信息抽取与知识图谱相关论文掠影
实体关系推理与知识图谱补全 Unsupervised Person Slot Filling based on Graph Mining 作者:Dian Yu, Heng Ji 机构:Computer ...
- 【开源】C#信息抽取系统【招募C#队友】
FDDC2018金融算法挑战赛02-A股上市公司公告信息抽取 更新时间 2018年7月11日 By 带着兔子去旅行 信息抽取是NLP里的一个实用内容.该工具的目标是打造一个泛用的自动信息抽取工具.使得 ...
- Java中正则表达式、模式匹配与信息抽取
引言 记得几年前在做网页爬虫后的信息抽取时,针对网页源码中隐藏的要提取的信息,比如评论.用户信息等属性信息,直接利用HtmlParser得到.如此做倒是简单,不过利用的是网页的规范的tag标记.其实j ...
- trie树信息抽取之中文数字抽取
这一章讲一下利用trie树对中文数字抽取的算法.trie树是一个非常有用的数据结构,可以应用于大部分文本信息抽取/转换之中,后续会开一个系列,对我在实践中摸索出来的各种抽取算法讲开来.比如中文时间抽取 ...
- 对step文件进行信息抽取算法
任务描述:给定一个step文件,对该文件的字符串进行信息抽取,结构化的组织文件描述模型的数据.形成抽象化数据结构,存入计算机数据库.并能按照有条理结构把这些数据展示出来. 信息抽取的结果描述: 1 数 ...
- ubuntu系统中查看本机cpu和内存信息的命令和用法
https://zhidao.baidu.com/question/192966322.html 写出ubuntu linux系统中查看本机cpu和内存信息的命令和用法,以及如何解读这些命令 ubun ...
随机推荐
- 【web安全】修改和配置tomcat版本信息
场景 目前网络安全的越来越受重视,tomcat作为重要的web容器被广泛应用,如何隐藏信息保证.在开放网络世界中,不易被攻击. 操作思路 1.进入Tomcat文件中的lib文件夹,将catalina. ...
- 带你十天轻松搞定 Go 微服务系列全集+勘误
官网手册: https://go-zero.dev/cn/ 文档说明: https://zhuanlan.zhihu.com/p/461604538 本地开发运行环境: https://github. ...
- ruby 常用代码片段
# 文件的当前目录 puts __FILE__ # string.rb # 文件的当前行 puts __LINE__ # 6 #文件的当前目录 puts __dir__ #/media/haima/3 ...
- Golang使用正则
目录 正则在线测试网站 Golang标准库--regexp 相关文章 课程学习地址: 手册地址: dome 正则在线测试网站 https://regex101.com/ Golang标准库--rege ...
- C 语言编程 — 代码规范
目录 文章目录 目录 前文列表 空行 空格 缩进 对齐 代码行 注释 示例 前文列表 <程序编译流程与 GCC 编译器> <C 语言编程 - 基本语法> <C 语言编程 ...
- C 语言编程 — 基本数据类型
目录 文章目录 目录 前文列表 数据类型 基本数据类型 整型 浮点型 前文列表 <程序编译流程与 GCC 编译器> <C 语言编程 - 基本语法> 数据类型 数据类型,即数据对 ...
- opensips开启lua支持
操作系统 :CentOS 7.6_x64 opensips版本 :2.4.9 lua版本:5.1 今天整理下CentOS7环境下opensips2.4.9的lua模块笔记及使用示例,并提供运行效果截图 ...
- linux下srpm源码包的使用和安装
目录 一.关于srpm包 二.srpm包和rpm包的区别 三.不对srpm包做修改,直接安装srpm包 四.对srpm包的源码进行修改,然后安装srpm包 一.关于srpm包 SRPM包是Sour ...
- Wpf虚拟屏幕键盘
在Wpf使用虚拟键盘有基于osk和tabtip,后者只能在win8和win10之后电脑使用,而且两者在wpf中调用时都必须提升为管理员权限,实际应用中还是不方便. 今天介绍的方法是使用第三方库oskl ...
- 国产大语言模型ChatGLM3本地搭建、使用和功能扩展
1.官网 ChatGLM3 2.下载ChatGLM3源码 直接在https://github.com/THUDM/ChatGLM3,下载源码 3.下载模型 如果显卡8G一下建议下载ChatGLM3-6 ...