开放 LLM 排行榜: 深入研究 DROP
最近,开放 LLM 排行榜 迎来了 3 个新成员: Winogrande、GSM8k 以及 DROP,它们都使用了 EleutherAI Harness 的原始实现。一眼望去,我们就会发现 DROP 的分数有点古怪: 绝大多数模型的 F1 分数都低于 10 分 (满分 100 分)!我们对此进行了深入调查以一探究竟,请随我们一起踏上发现之旅吧!
初步观察
在 DROP (Discrete Reasoning Over Paragraphs,段落级离散推理) 评估中,模型需要先从英文文段中提取相关信息,然后再对其执行离散推理 (例如,对目标对象进行排序或计数以得出正确答案,如下图中的例子)。其使用的指标是自定义 F1 以及精确匹配分数。

三周前,我们将 DROP 添加至开放 LLM 排行榜中,然后我们观察到预训练模型的 DROP F1 分数有个奇怪的趋势: 当我们把排行榜所有原始基准 (ARC、HellaSwag、TruthfulQA 和 MMLU) 的平均分 (我们认为其一定程度上代表了模型的总体性能) 和 DROP 分数作为两个轴绘制散点图时,我们本来希望看到 DROP 分数与原始均分呈正相关的关系 (即原始均值高的模型,DROP 分数也应更高)。然而,事实证明只有少数模型符合这一预期,其他大多数模型的 DROP F1 分数都非常低,低于 10。
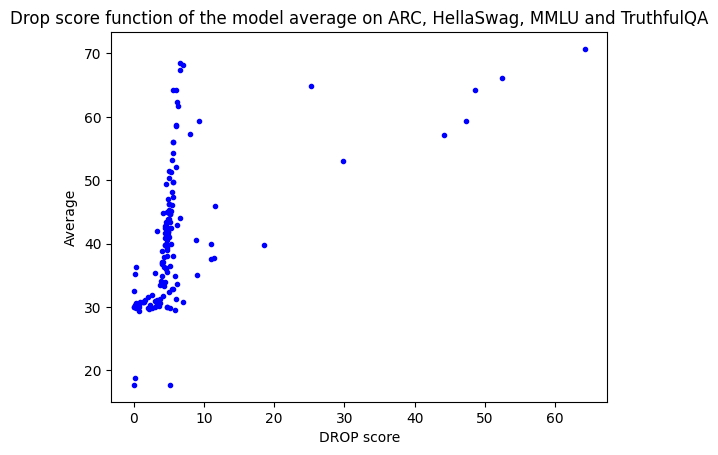
文本规范化的锅
第一站,我们观察到文本规范化的结果与预期不符: 在某些情况下,当正确的数字答案后面直接跟有除空格之外的其他空白字符 (如: 换行符) 时,规范化操作导致即使答案正确也无法匹配。举个例子,假设生成的文本是 10\n\nPassage: The 2011 census recorded a population of 1,001,360 ,而对应的标准答案为 10 。
测试基准会先对生成文本和标准答案文本都进行文本规范化,整个过程分为多个步骤:
- 按分隔符 (
|、-或
生成文本的开头10\n\nPassage:并不包含分隔符,因此会被放进同一个词元 (即第一个词元) ; - 删除标点符号
删除标点后,第一个词元会变为10\n\nPassage(:被删除); - 数字均质化
每个可以转换为浮点数的字符串都会被视为数字并转换为浮点数,然后再重新转回字符串。10\n\nPassage保持不变,因为它不能被转换为浮点数,而标准答案的10变成了10.0。 - 其他步骤
随后继续执行其他规范化步骤 (如删除冠词、删除其他空格等),最终得到的规范化文本是:10 passage 2011.0 census recorded population of 1001360.0。
最终得分并不是根据字符串计算而得,而是根据从字符串中提取的词袋 (bag of words,BOW) 计算而得。仍用上例,规范化后的生成文本词袋为 {'recorded', 'population', 'passage', 'census', '2011.0', ' 1001360.0', '10'} ,而规范化后的标准答案词袋为 {10.0} ,两者求交,正如你所看到的,即使模型生成了正确答案,两者交集也为 0!
总之,如果一个数字后面跟着除标准空格字符外的任何其它表示空格的字符,目前的文本规范化实现就不会对该数字进行规范化,因此如果此时标准答案也是一个数字,那么两者就永远无法匹配了!这个问题可能给最终分数带来严重影响,但显然这并是导致 DROP 分数如此低的唯一罪魁祸首。我们决定继续调查。
对结果进行深入研究
我们在 Zeno 的朋友加入了调查并对结果 进行了更深入的探索,他们选择了 5 个有代表性的模型进行深入分析: falcon-180B 和 mistra-7B 表现低于预期,Yi-34B 和 Tigerbot-70B 的 DROP 分数与原始均分正相关,而 facebook/xglm-7.5B 则落在中间。
如果你有兴趣的话,也可以试试在 这个 Zeno 项目 上分析一把。
Zeno 团队发现了两件更麻烦的事情:
- 如果答案是浮点数,没有一个模型的结果是正确的
- 擅长生成长答案的高质量模型 F1 分数反而更低
最后,我们认为这两件事情实际上是同一个根因引起的,即: 使用 . 作为停止词 (以结束生成):
- 浮点数答案在生成过程中直接被截断了 [译者注: 小数点被当成句号直接中断输出了。]
- 更高质量的模型,为了尝试匹配少样本提示格式,其生成会像这样
Answer\n\nPlausible prompt for the next question.,而按照当前停止词的设定,该行为仅会在结果生成后且遇到第一个.停止,因此模型会生成太多多余的单词从而导致糟糕的 F1 分数。
我们假设这两个问题都可以通过使用 \n 而不是 . 来充当停止词而得到解决。
更改生成停止词
我们对此进行了初步实验!我们试验了在现有的生成文本上使用 \n 作为结束符。如果生成的答案中有 \n ,我们就在遇到第一个 \n 时截断文本,并基于截断文本重新计算分数。
请注意,这只能近似正确结果,因为它不会修复由于 . 而过早截断的答案 (如浮点数答案)。但同时,它也不会给任何模型带来不公平的优势,因为所有模型都受这个问题的影响。因此,这是我们在不重新运行模型的情况下 (因为我们希望尽快向社区发布进展) 能做的最好的事情了。
结果如下。使用 \n 作为停止词后,DROP 分数与原始均分的相关度提高不少,因此模型的 DROP 分数与模型原始的总体表现相关度也变高了。
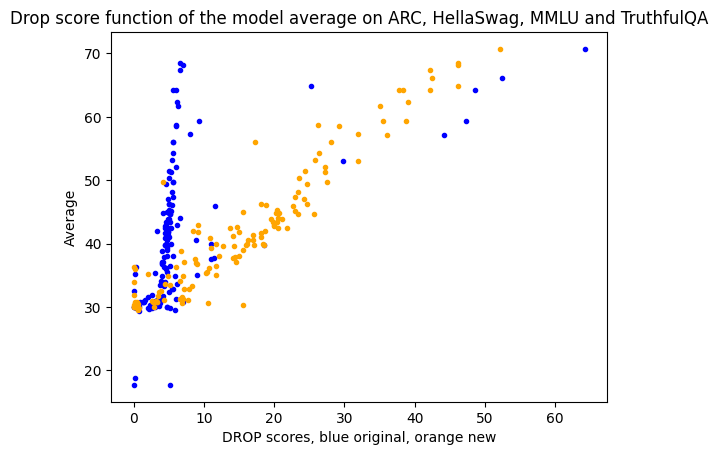
那下一步咋整
快速估算一下,重新对所有模型运行完整评估的成本相当高 (全部更新需花 8 个 GPU 年,DROP 占用了其中的很大一部分)。因此,我们对仅重新运行失败的例子所需要的成本进行了估算。
有 10% 样本的标准答案是浮点数 (如 12.25 ),且模型输出以正确答案开头 (本例中为 12 ),但在 . 处被截断 - 这种情况如果继续生成的话,有可能答案是正确的,因此我们肯定要重新运行!但这 10% 尚不包括以数字结尾的句子,这类句子也可能会被不当截断 (在剩下的 90% 中占 40%),也不包括被规范化操作搞乱掉的情况。
因此,为了获得正确的结果,我们需要重新运行超过 50% 的样本,这需要大量的 GPU 时!我们需要确保这次要运行的代码是正确的。
于是,我们与 EleutherAI 团队通过 GitHub 及内部渠道进行了广泛的讨论,他们指导我们理解代码并帮助我们进行调查,很明显,LM Eval Harness 的实现严格遵循了“官方 DROP 代码”的实现,因此这不是 LM Eval Harness 的 bug,而是需要开发 DROP 基准评估的新版本!
因此,我们决定暂时从 Open LLM 排行榜中删除 DROP,直到新版本出现为止。
从本次调查中我们学到的一点是,通过社区协作对基准测试进行检阅,能发现以前遗漏的错误,这一点很有价值。开源、社区和开放式研发的力量再次闪耀,有了这些,我们甚至可以透明地调查一个已经存在数年的基准上的问题并找到根因。
我们希望有兴趣的社区成员与发明 DROP 评估的学者联手,以解决其在评分及文本规范化上的问题。我们希望能再次使用它,因为数据集本身非常有趣而且很酷。如国你对如何评估 DROP 有任何见解,请不要犹豫,告诉我们。
感谢众多社区成员指出 DROP 分数的问题,也非常感谢 EleutherAI Harness 和 Zeno 团队在此问题上的大力协助。
英文原文: https://hf.co/blog/leaderboard-drop-dive
原文作者: Clémentine Fourrier,Alex Cabrera,Stella Biderman,Nathan Habib,Thomas Wolf
译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。
开放 LLM 排行榜: 深入研究 DROP的更多相关文章
- 从中间件的历史来看移动App开发的未来
在移动开发领域我们发现一个很奇怪的现象:普通菜鸟新手经过3个月的培训就可以拿到 8K 甚至上万的工作:在北京稍微有点工作经验的 iOS 开发,就要求 2 万一个月的工资.不知道大家是否想过:移动应用开 ...
- 网站集成QQ登录功能
最近在做一个项目时,客户要求网站能够集成QQ登录的功能,以前没做过这方面的开发,于是去QQ的开放平台官网研究了一下相关资料,经过自己的艰苦探索,终于实现了集成QQ登录的功能,现在把相关的开发经验总结一 ...
- 网站集成QQ登录功能(转)
最近在做一个项目时,客户要求网站能够集成QQ登录的功能,以前没做过这方面的开发,于是去QQ的开放平台官网研究了一下相关资料,经过自己的艰苦探索,终于实现了集成QQ登录的功能,现在把相关的开发经验总结一 ...
- Linux内核探索之路——关于方法
转载自:http://blog.chinaunix.net/uid-20608849-id-3014502.html Linux内核实践之路 -给那些想从Linux内核找点乐趣的人 一个不能回避的 ...
- NYOJ 2356 哈希计划(模拟)
题目链接: http://acm.nyist.me/JudgeOnline/problem.php?id=2356 题目描述 众所周知,LLM的算法之所以菜,就是因为成天打游戏,最近LLM突然想玩&l ...
- Linux养成笔记
教程来自慕课网@Tony老师的课程 Linux简介 Linux发展史 Andrew S. Tanenbaum为了给学生讲课,买了一个Unix操作系统,参考他开发了Minix,并开放代码作为大学研究,2 ...
- 使用colab运行深度学习gpu应用(Mask R-CNN)实践
1,目的 Google Colaboratory(https://colab.research.google.com)是谷歌开放的一款研究工具,主要用于机器学习的开发和研究.这款工具现在可以免费使用, ...
- 如何免费使用GPU跑深度学习代码
从事深度学习的研究者都知道,深度学习代码需要设计海量的数据,需要很大很大很大(重要的事情说三遍)的计算量,以至于CPU算不过来,需要通过GPU帮忙,但这必不意味着CPU的性能没GPU强,CPU是那种综 ...
- Cacti-0.8.8b详细安装及配置步骤
1. Cacti环境安装 1.1 安装LAMP环境 安装LAMP环境,当然,如果你有兴趣可以采用编译,我线上Mysql是编译的,其余是yum安装的.在这次实验采用yum安装. 关闭i ...
- Google Colab——用谷歌免费GPU跑你的深度学习代码
Google Colab简介 Google Colaboratory是谷歌开放的一款研究工具,主要用于机器学习的开发和研究.这款工具现在可以免费使用,但是不是永久免费暂时还不确定.Google Col ...
随机推荐
- Python中的爬虫应用及常用Python库
Python的爬虫应用非常广泛,以下是一些典型的示例: 数据采集:使用爬虫可以从网页上抓取数据,并将其保存到本地或数据库中.这对于构建大规模数据集.进行市场调研.舆情监测等任务非常有用. 搜索引擎索引 ...
- 比STL还STL?——更全面的解析!
如何更快的使用高级数据结构 Part 1 :__gnu_pbds 库 __gnu_pbds 自带了封装好了的平衡树.字典树.hash等强有力的数据结构,常数还比自己写的小,效率更高 一.平衡树 #de ...
- L2-040 哲哲打游戏
这题读懂题目之后就发现它很呆 #include <bits/stdc++.h> using namespace std; const int N = 100010, M = 110; ve ...
- [CF1849F] XOR Partition
XOR Partition 题目描述 For a set of integers $ S $ , let's define its cost as the minimum value of $ x \ ...
- 聊一聊 .NET高级调试 内核模式堆泄露
一:背景 1. 讲故事 前几天有位朋友找到我,说他的机器内存在不断的上涨,但在任务管理器中查不出是哪个进程吃的内存,特别奇怪,截图如下: 在我的分析旅程中都是用户态模式的内存泄漏,像上图中的异常征兆已 ...
- 从零开始封装 vue 组件
对于学习 Vue 的同学来说,封装 vue 组件是实现代码复用的重要一环.在 Vue 官网中非常详细地介绍了 vue 组件的相关知识,我这里简单摘取使用最频繁的几个知识点,带大家快速入门 vue 组件 ...
- bash shell笔记整理——stat命令
stat命令的作用 stat主要用于查看文件的详细信息,包括access time(atime).modify time(mtime).change time.权限.属主.属组等信息 atime:只有 ...
- 获取微信的token工具类
import cn.hutool.extra.spring.SpringUtil; import cn.hutool.http.HttpUtil; import cn.RedisUtil; impor ...
- Git和Github库详细使用教程
SVN 是集中式或者有中心式版本控制系统,版本库是集中放在中央服务器的; Git 是分布式版本控制系统,那么它就没有中央服务器的,每个人的电脑就是一个完整的版本库,这样,工作的时候就不需要联网了,因为 ...
- Pikachu漏洞靶场 XXE(xml外部实体注入漏洞)
XXE(xml外部实体注入漏洞) 概述 XXE -"xml external entity injection" 既"xml外部实体注入漏洞". 概括一下就是& ...