从 pheatmap 无缝迁移至 ComplexHeatmap
pheatmap 是一个非常受欢迎的绘制热图的 R 包。ComplexHeatmap 包即是受之启发而来。你可以发现Heatmap()函数中很多参数都与pheatmap()相同。在 pheatmap 的时代(请允许我这么说),pheatmap 意思是 pretty heatmap,但是随着时间推进,技术发展,各种新的数据出现,pretty is no more pretty,我们需要更加复杂和更有效率的热图可视化方法对庞大的数据进行快速并且有效的解读,因此我开发并且一直维护和改进着 ComplexHeatmap 包。
为了使庞大并且“陈旧”的(对不起,我不应该这么说。)pheatmap 用户群能够迅速并且无痛的迁移至 ComplexHeatmap,从 2.5.2 版本开始,我在 ComplexHeatmap 包中加入了一个pheatmap()函数,它涵盖了pheatmap::pheatmap()所有的功能,也就是说,它提供了和pheatmap::pheatmap()一模一样的参数,并且生成的热图的样式也几乎相同。同时,ComplexHeatmap::pheatmap()函数也能使用 ComplexHeatmap 独有的功能,比如对行和列进行切分,加入自定义的 annotation,多个热图和 annotation 的连接,或者创建一个互动的热图(interactive heatmap, 通过ht_shiny()函数)。
ComplexHeatmap::pheatmap()包含了pheatmap::pheatmap()中所有的参数,这意味着,当你从 pheatmap 迁移至 ComplexHeatmap 时,你无需添加任何额外的步骤,你只需要载入 ComplexHeatmap 而不是 pheatmap 包,然后重新运行你原始的 pheatmap 代码。剩下的你只是去见证奇迹的发生。
注意如下五个pheatmap::pheatmap()的参数在ComplexHeatmap::pheatmap()中被忽视:
kmeans_k:在pheatmap::pheatmap()中,如果这个参数被设定,输入矩阵会进行 k 均值聚类,然后每个 cluster 使用其均值向量表示。最终的热图是 k 个均值向量的热图。此操作改变了原始矩阵的大小,而且每个 cluster 的大小信息丢失了,直接解读均值向量可能会造成对数据的误解。我不赞成此操作,因此我没有支持这个参数。在 ComplexHeatmap 中,row_km和column_km参数可能是一个更好的选择。filename:如果这个参数被设定,热图直接保存至指定的文件中。我认为这只是画蛇添足(没有贬低 pheatmap 的意思,只是最近在给小孩讲成语故事,然后想在这里使用一下)的一步,ComplexHeatmap::pheatmap()不支持此参数。width:filename的宽度。height:filename的长度。silent:是否打印信息。
在pheatmap::pheatmap()中,color参数需要设置为一个长长的颜色向量(如果你想用 100 种颜色的话),比如:
pheatmap::pheatmap(mat,
color = colorRampPalette(rev(brewer.pal(n = 7, name = "RdYlBu")))(100)
)
在ComplexHeatmap::pheatmap()中,你可以简化无需使用colorRampPalette()去扩展更多的颜色,你可以直接简化为如下,颜色会被自动插值和扩展。
ComplexHeatmap::pheatmap(mat,
color = rev(brewer.pal(n = 7, name = "RdYlBu"))
)
例子
我们首先创建一个随机数据,这个来自于 pheatmap 包中提供的例子:
https://rdrr.io/cran/pheatmap/man/pheatmap.html
test = matrix(rnorm(200), 20, 10)
test[1:10, seq(1, 10, 2)] = test[1:10, seq(1, 10, 2)] + 3
test[11:20, seq(2, 10, 2)] = test[11:20, seq(2, 10, 2)] + 2
test[15:20, seq(2, 10, 2)] = test[15:20, seq(2, 10, 2)] + 4
colnames(test) = paste("Test", 1:10, sep = "")
rownames(test) = paste("Gene", 1:20, sep = "")
我们载入 ComplexHeatmap 包,然后执行pheatmap()函数,生成一副和pheatmap::pheatmap()非常类似的热图。
library(ComplexHeatmap)
# 注意这是ComplexHeatmap::pheatmap
pheatmap(test)
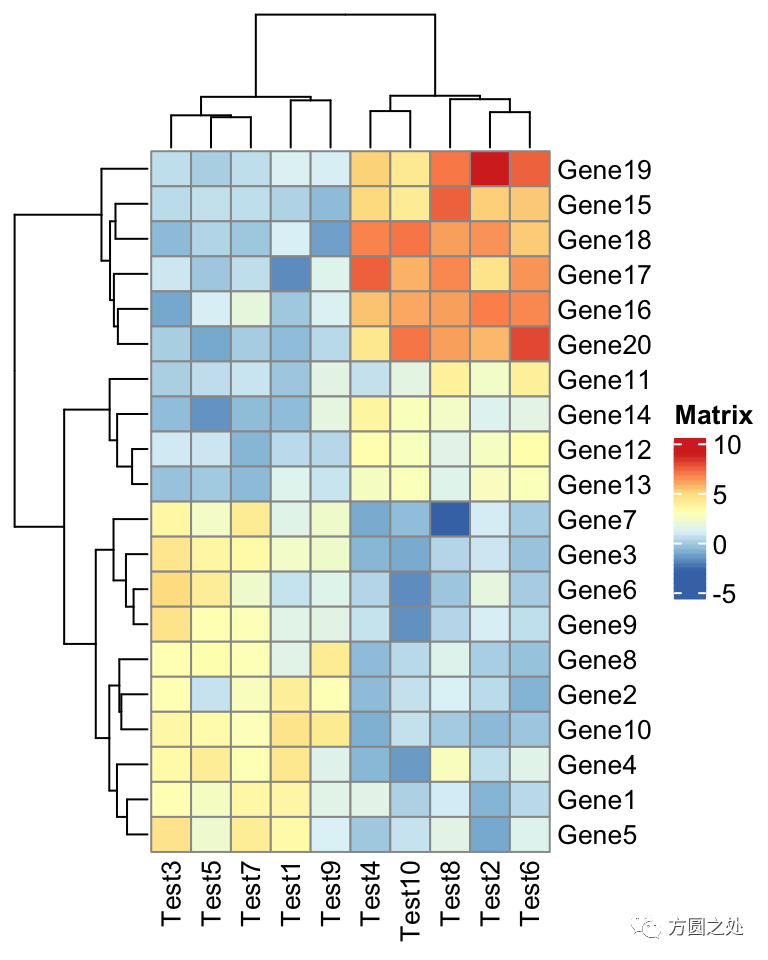
在ComplexHeatmap::pheatmap()中,按照pheatmap::pheatmap()的样式进行了相应的配置,因此,大部分元素的样式一模一样。只有少部分不一致,比如说热图的 legend。
下一个例子是在热图中加入 annotation。以下代码是在pheatmap()中添加 annotation。如果你是pheatmap()用户,你应该对 annotation 的数据格式不太陌生。
annotation_col = data.frame(
CellType = factor(rep(c("CT1", "CT2"), 5)),
Time = 1:5
)
rownames(annotation_col) = paste("Test", 1:10, sep = "")
annotation_row = data.frame(
GeneClass = factor(rep(c("Path1", "Path2", "Path3"), c(10, 4, 6)))
)
rownames(annotation_row) = paste("Gene", 1:20, sep = "")
ann_colors = list(
Time = c("white", "firebrick"),
CellType = c(CT1 = "#1B9E77", CT2 = "#D95F02"),
GeneClass = c(Path1 = "#7570B3", Path2 = "#E7298A", Path3 = "#66A61E")
)
pheatmap(test,
annotation_col = annotation_col,
annotation_row = annotation_row,
annotation_colors = ann_colors)
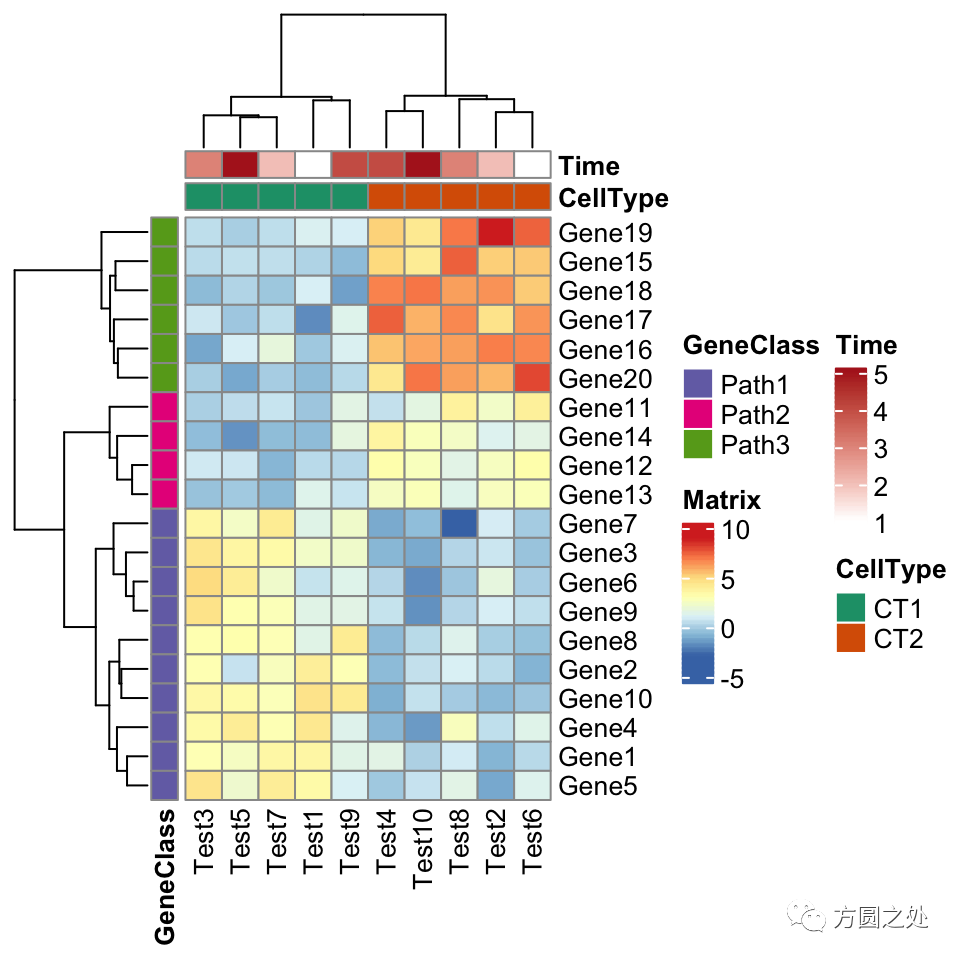
看起来和pheatmap::pheatmap()还是很一致。
ComplexHeatmap::pheatmap()内部其实使用了Heatmap()函数,因此更多的参数都最终传递给了Heatmap()。我们可以在pheatmap()中使用一些Heatmap()特有的参数,比如row_split和column_split来对行和列进行切分。
pheatmap(test,
annotation_col = annotation_col,
annotation_row = annotation_row,
annotation_colors = ann_colors,
row_split = annotation_row$GeneClass,
column_split = annotation_col$CellType)
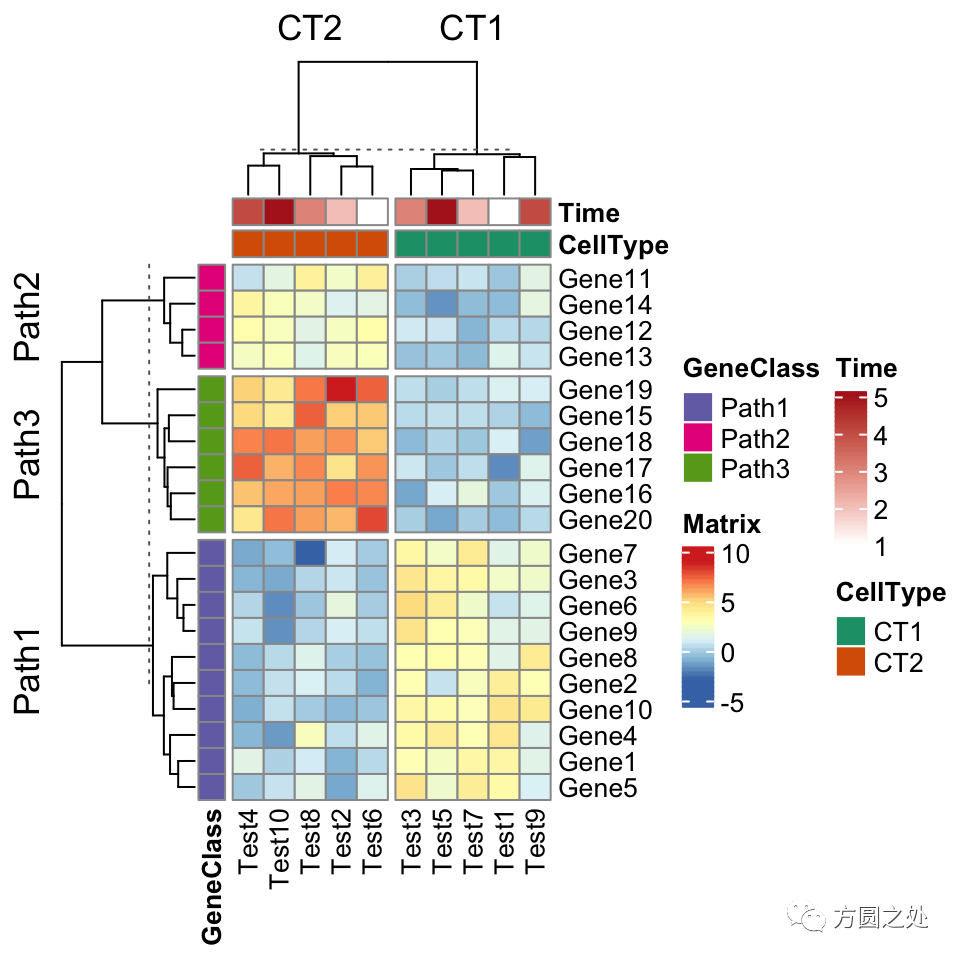
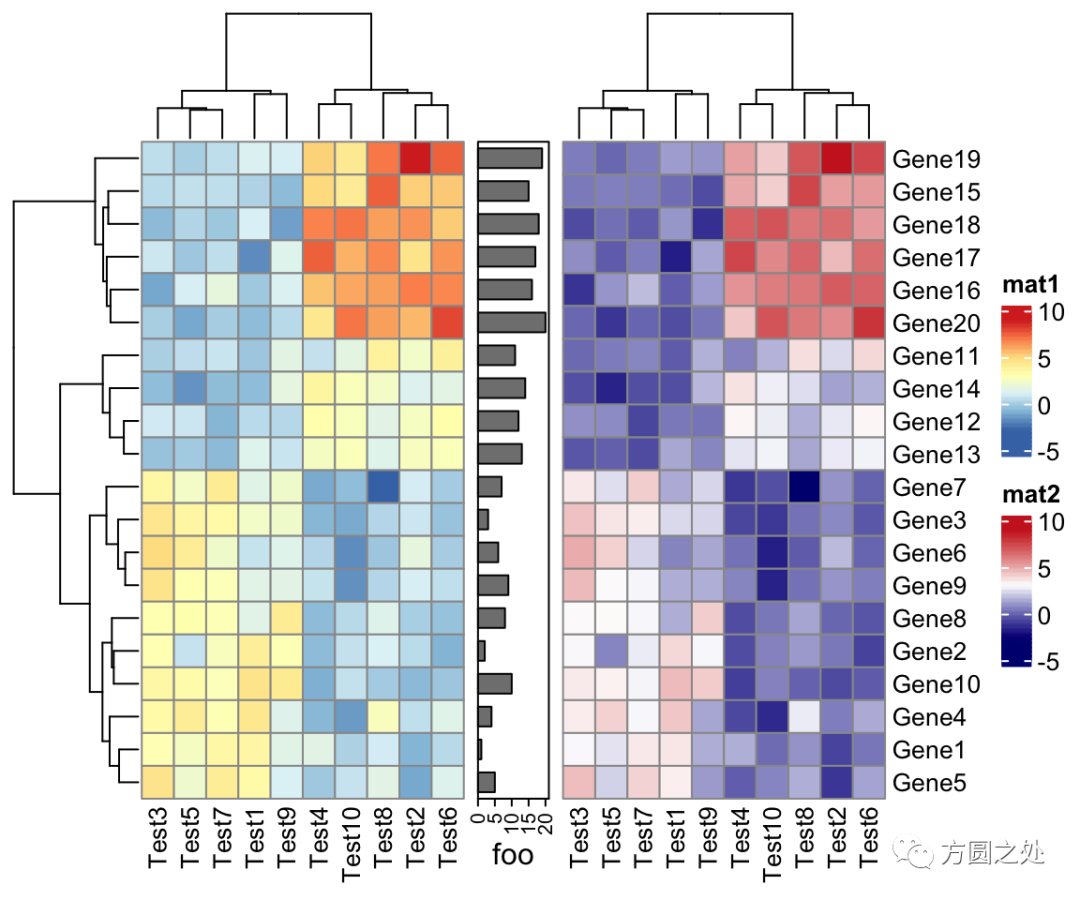
ComplexHeatmap::pheatmap()返回一个Heatmap对象,因此它可以与其他Heatmap/HeatmapAnnotation对象连接。换句话说,你可以使用炫酷的+或者%v%对多个 pheatmap 水平连接或者垂直连接。
p1 = pheatmap(test, name = "mat1")
p2 = rowAnnotation(foo = anno_barplot(1:nrow(test)))
p3 = pheatmap(test, name = "mat2",
col = c("navy", "white", "firebrick3"))
p1 + p2 + p3
ComplexHeatmap 支持将一个热图导出为一个 shiny app,这也同样适用于pheatmap(),因此你可以这样做:
ht = pheatmap(...)
ht_shiny(ht) # 强烈建议试一试
还有一件重要的小事是,因为ComplexHeatmap::pheatmap()返回一个Heatmap对象,如果pheatmap()并没有在一个 interactive 的环境执行,比如说在一个 R 脚本中,或者在一个函数/for loop 中,你应该显式的调用draw()函数进行画图。
for(...) {
p = pheatmap(...)
draw(p)
}
最后我想说的事,这篇文章的主旨并不是鼓励用户直接使用ComplexHeatmap::pheatmap(),我只是在此展示了 pheatmap 完全可以用 ComplexHeatmap 来代替,而且 ComplexHeatmap 提供了工具让用户无需任何额外的操作(zero effort)就可以迁移以前旧的代码。但是我还是强烈建议用户直接使用 ComplexHeatmap 中的“正经函数”。
从 pheatmap 到 ComplexHeatmap 的翻译
在“阅读原文”中,你可以找到一个表格,其中详细的列出了如何将pheatmap::pheatmap()中的参数对应到Heatmap()中。
比较
这一小节我比较了相同参数下pheatmap::pheatmap()生成的热图和ComplexHeatmap::pheatmap()的相似度。我使用了 pheatmap 包中所有的例子(https://rdrr.io/cran/pheatmap/man/pheatmap.html)。同时我也使用了 ComplexHeatmap 中提供的一个简单的帮助函数ComplexHeatmap::compare_pheatmap()。它的功能就是把参数同时传递给pheatmap::pheatmap()和ComplexHeatmap::pheatmap(),然后生成两幅热图,这样可以直接进行比较。因此如下代码:
compare_pheatmap(test)
其实等同于:
pheatmap::pheatmap(test)
ComplexHeatmap::pheatmap(test)
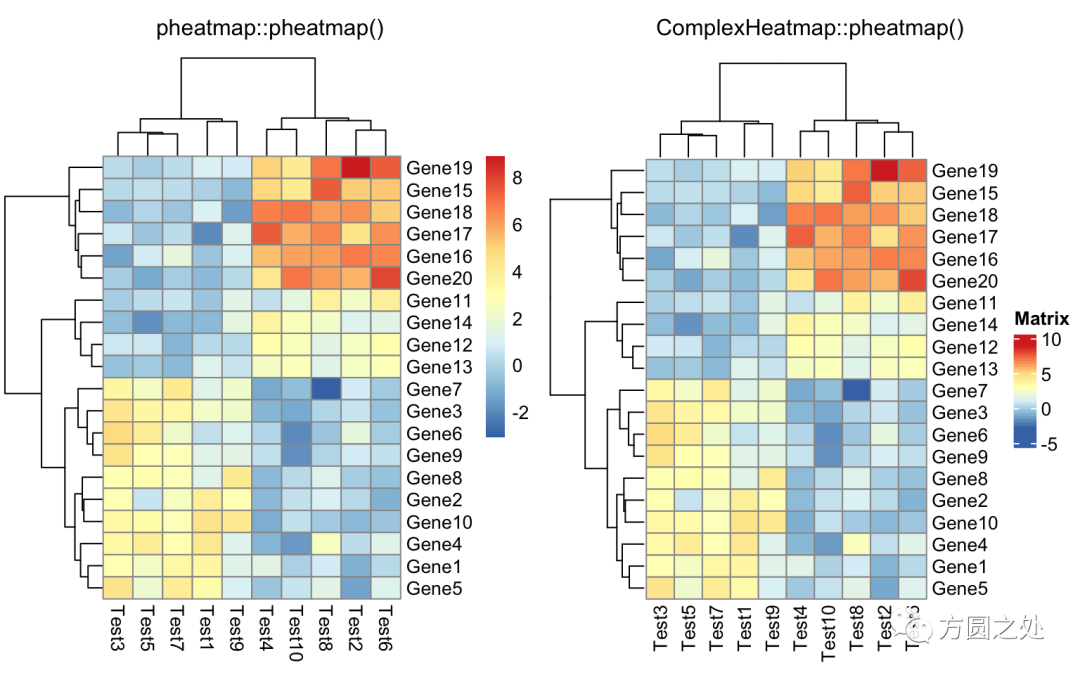
在往下阅读之前,我先告诉你结论:pheatmap::pheatmap()和ComplexHeatmap::pheatmap()产生的热图几乎完全相同。
只提供一个矩阵:
compare_pheatmap(test)
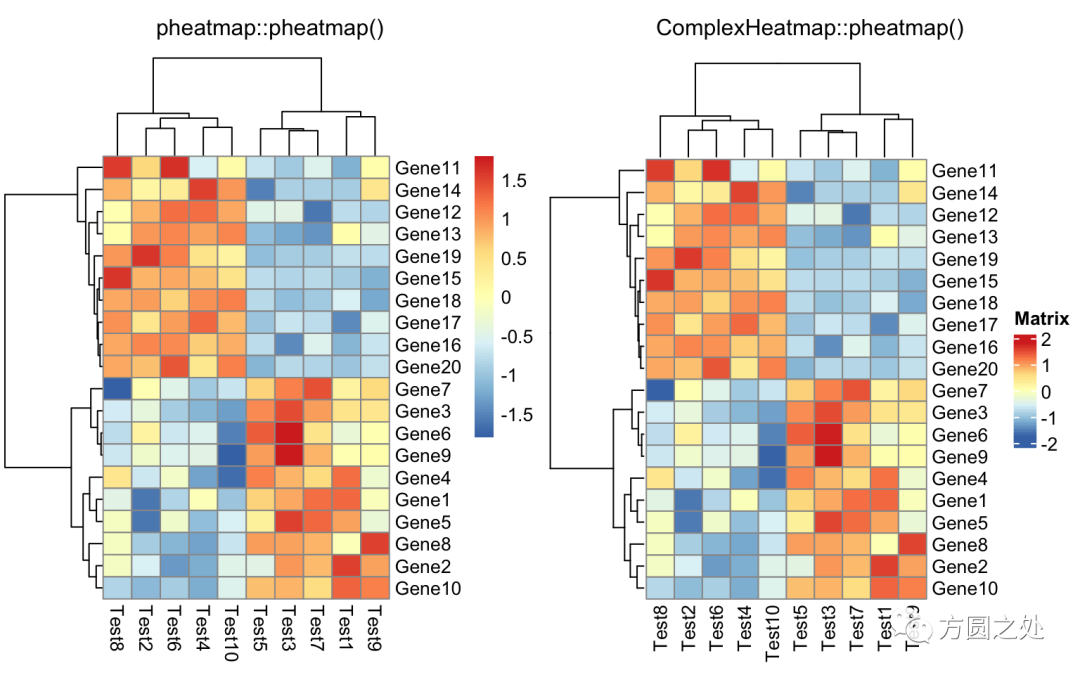
对列进行 z-score 归一化,行聚类距离使用相关性距离:
compare_pheatmap(test,
scale = "row",
clustering_distance_rows = "correlation")
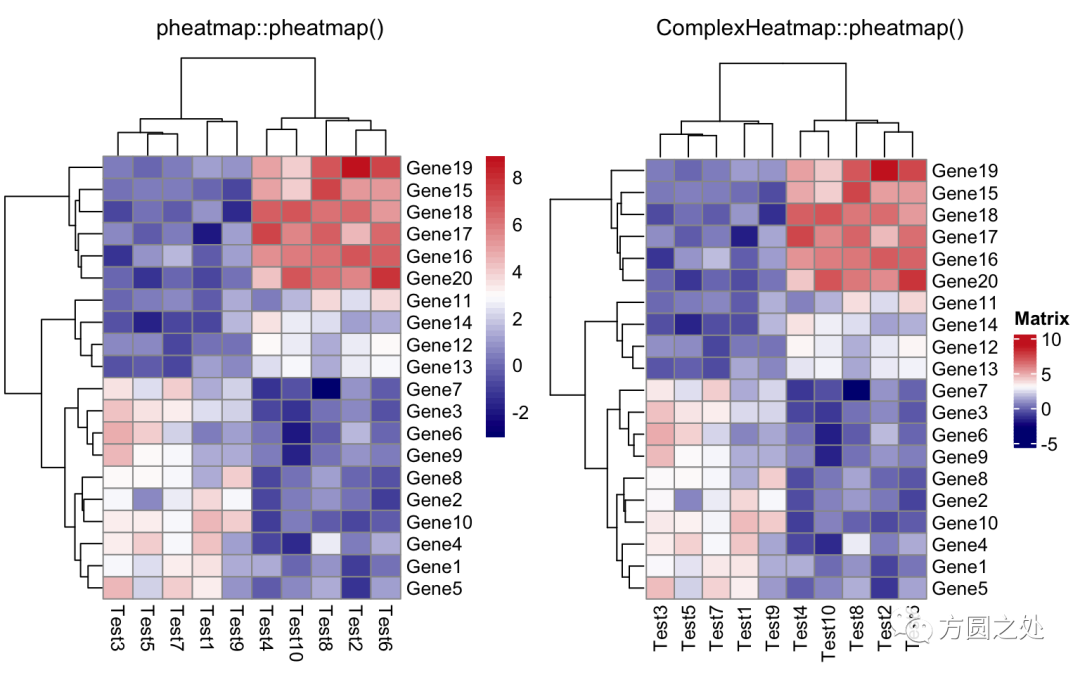
设定颜色:
compare_pheatmap(test,
color = colorRampPalette(c("navy", "white", "firebrick3"))(50))
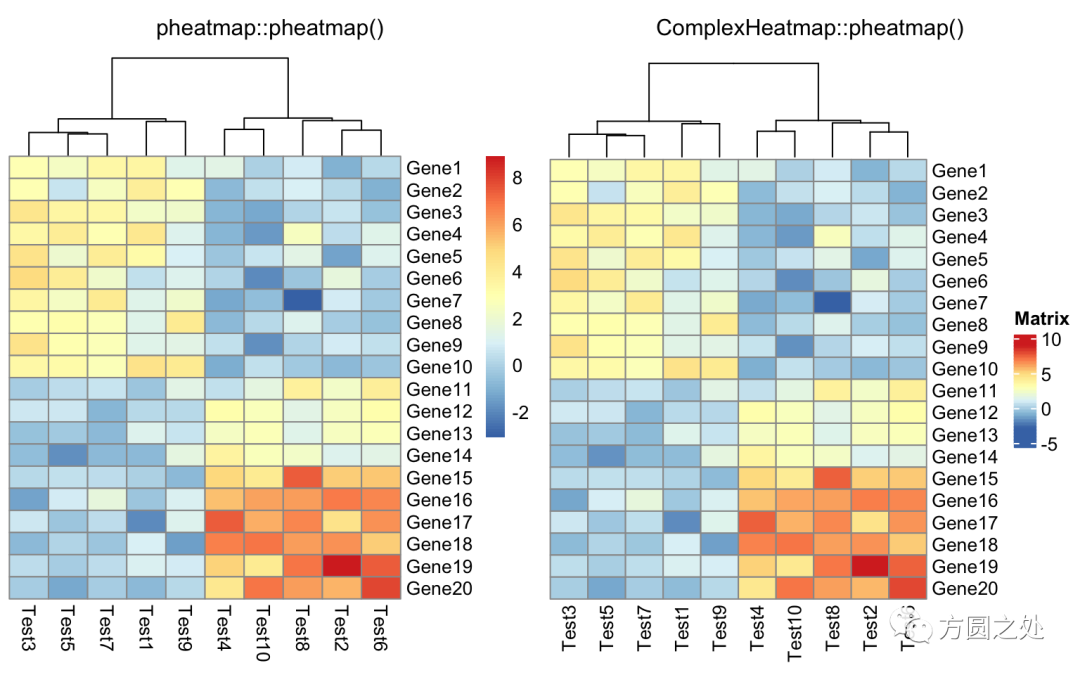
不对行聚类:
compare_pheatmap(test,
cluster_row = FALSE)
不显示 legend:
compare_pheatmap(test,
legend = FALSE)
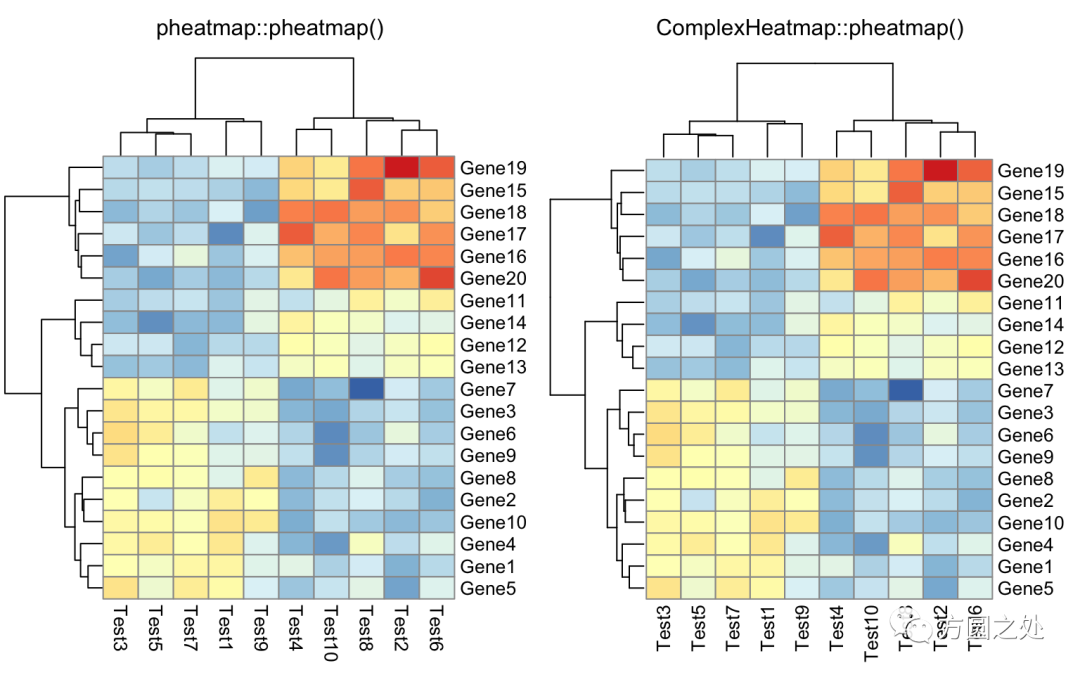
在矩阵格子上显示数值:
compare_pheatmap(test,
display_numbers = TRUE)
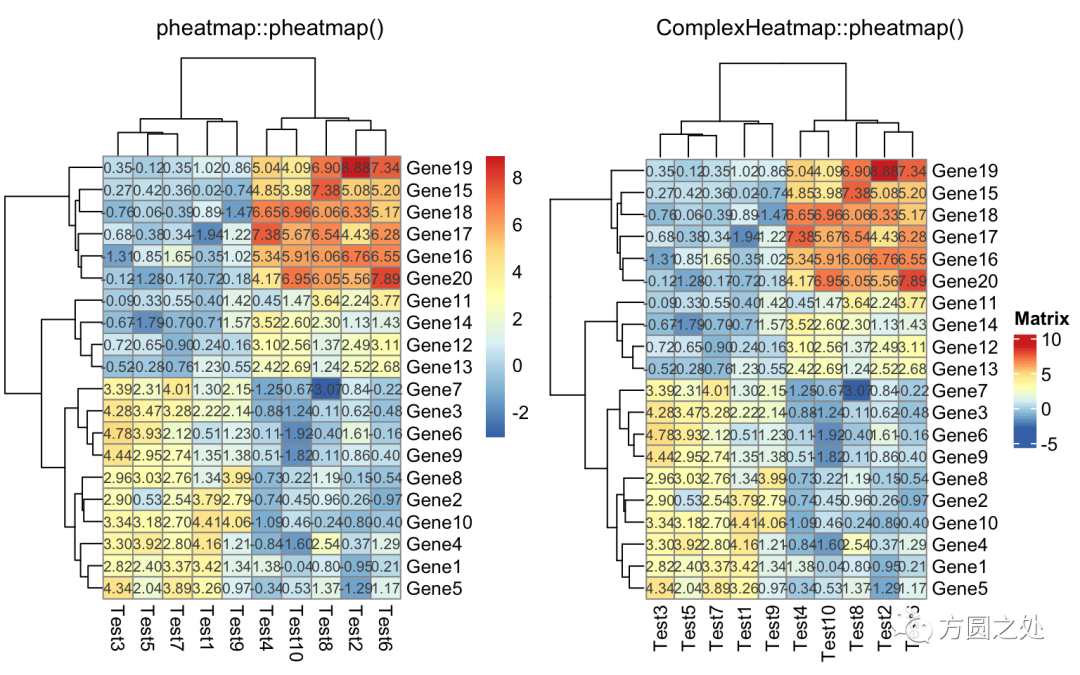
对矩阵格子上的数值进行格式化:
compare_pheatmap(test,
display_numbers = TRUE,
number_format = "%.1e")
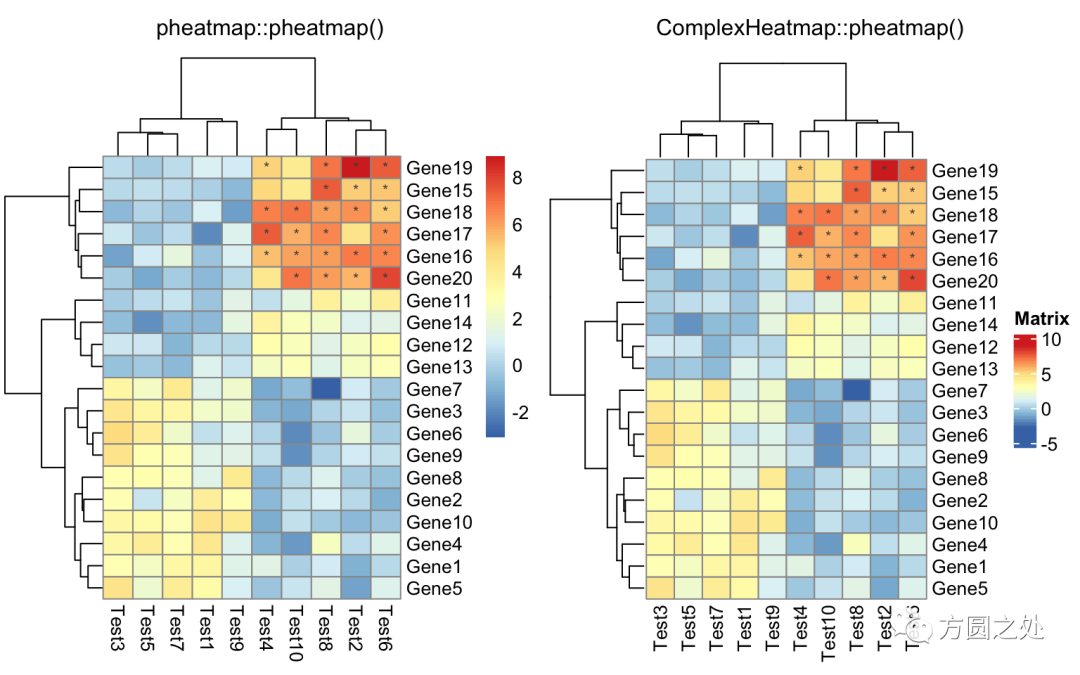
自定义矩阵格子上的文字:
compare_pheatmap(test,
display_numbers = matrix(ifelse(test > 5, "*", ""),
nrow(test)))
定义 legend 上的 label:
compare_pheatmap(test,
cluster_row = FALSE,
legend_breaks = -1:4,
legend_labels = c("0", "1e-4", "1e-3", "1e-2", "1e-1", "1"))
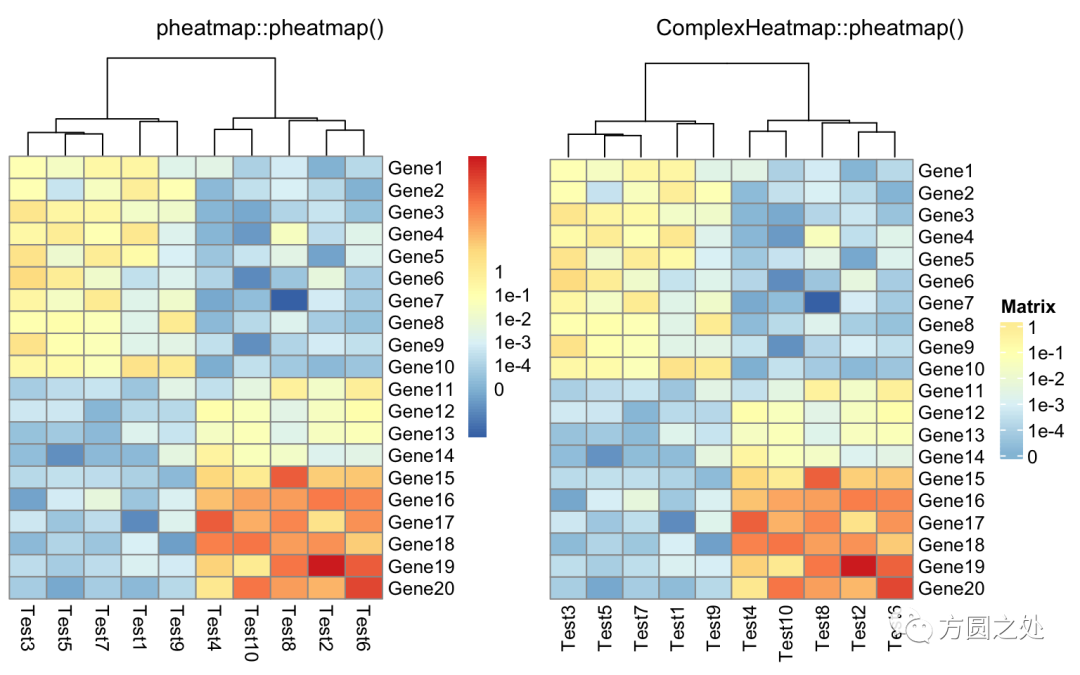
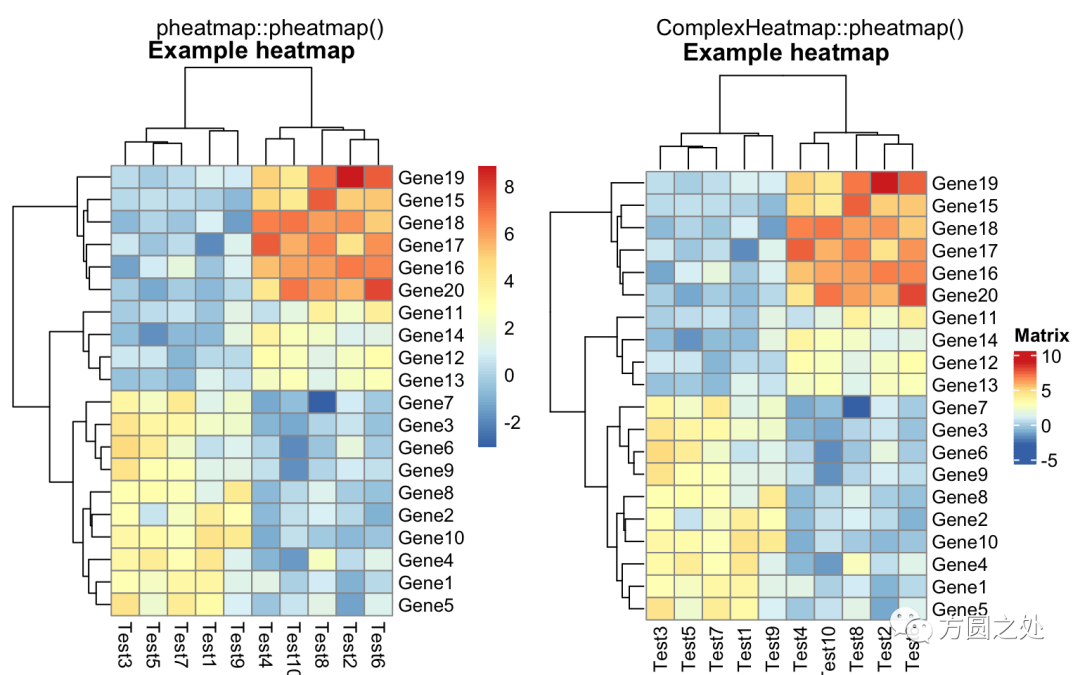
热图的标题:
compare_pheatmap(test,
cellwidth = 15,
cellheight = 12,
main = "Example heatmap")
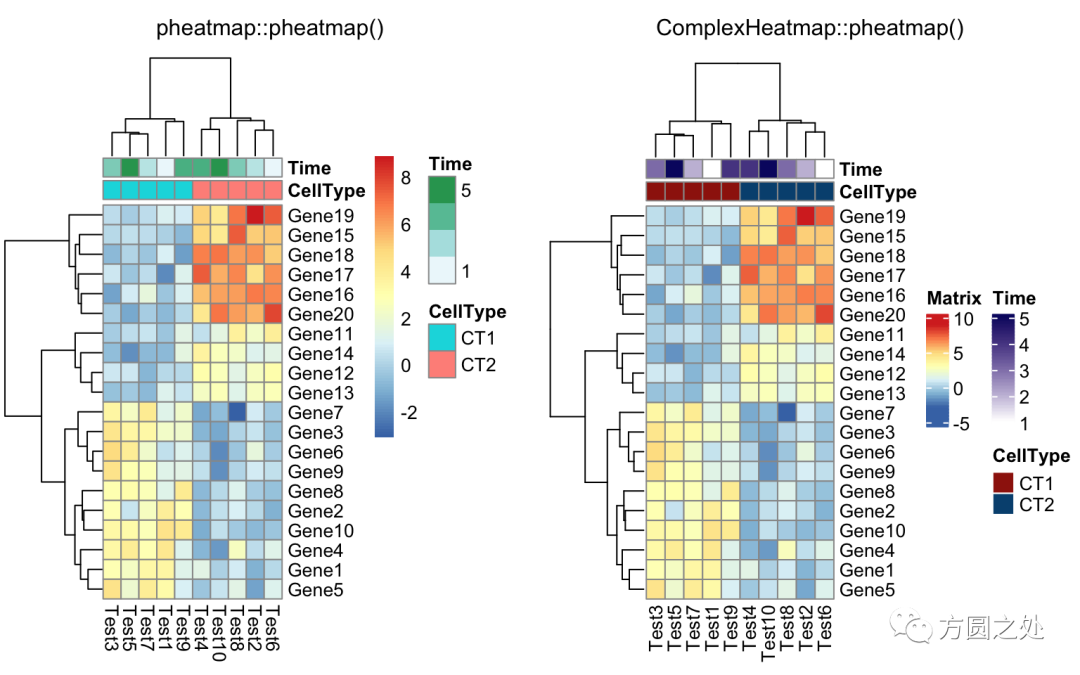
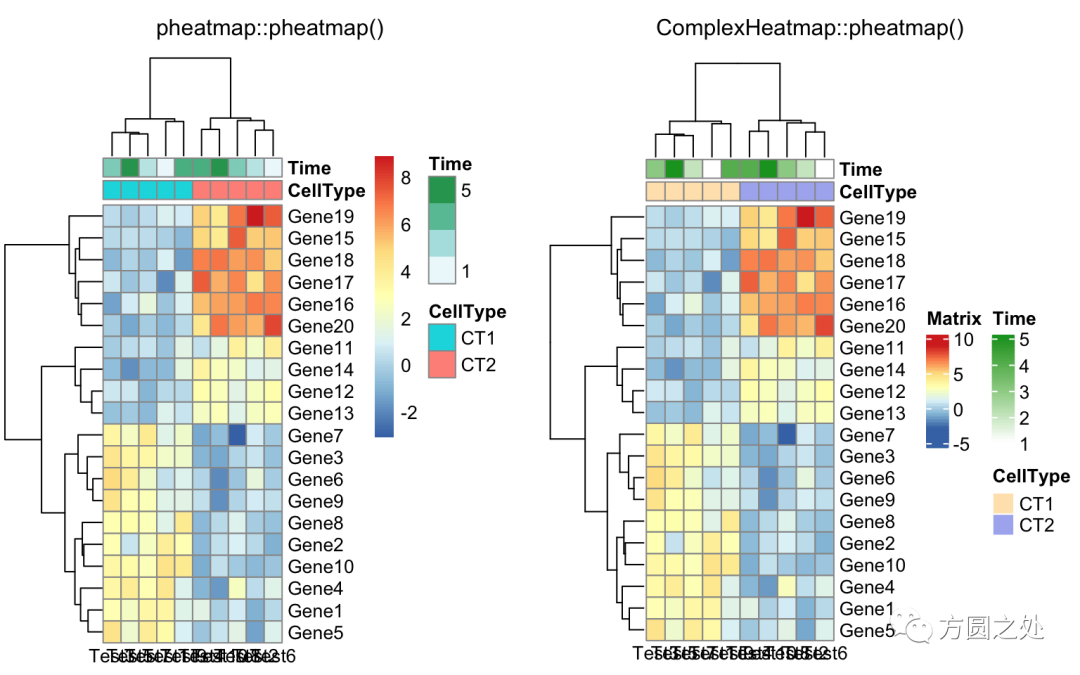
添加列的 annotation:
annotation_col = data.frame(
CellType = factor(rep(c("CT1", "CT2"), 5)),
Time = 1:5
)
rownames(annotation_col) = paste("Test", 1:10, sep = "")
annotation_row = data.frame(
GeneClass = factor(rep(c("Path1", "Path2", "Path3"), c(10, 4, 6)))
)
rownames(annotation_row) = paste("Gene", 1:20, sep = "")
compare_pheatmap(test,
annotation_col = annotation_col)
不绘制 annotation 的 legend:
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_legend = FALSE)
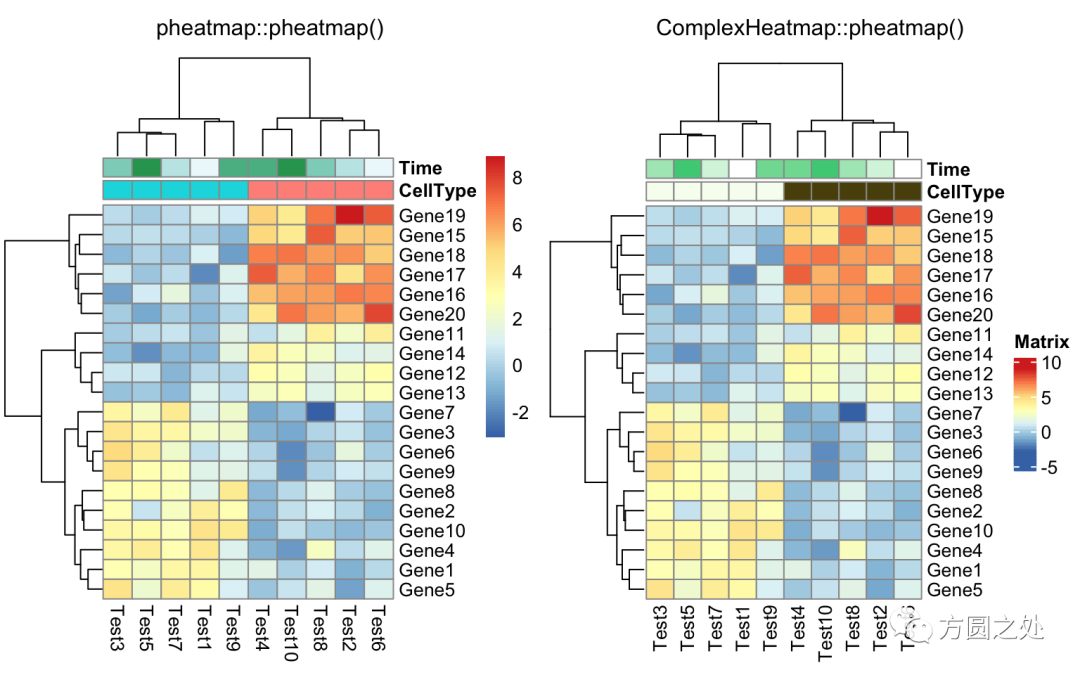
同时添加行和列的 annotation:
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_row = annotation_row)
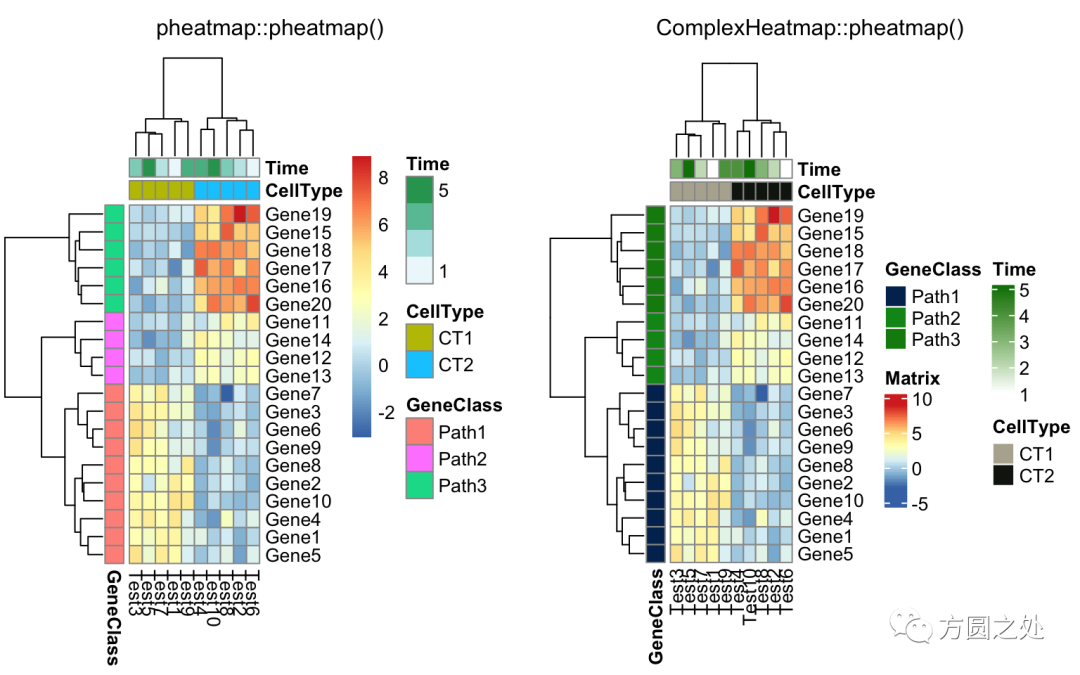
调整列名的旋转:
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_row = annotation_row,
angle_col = "45")
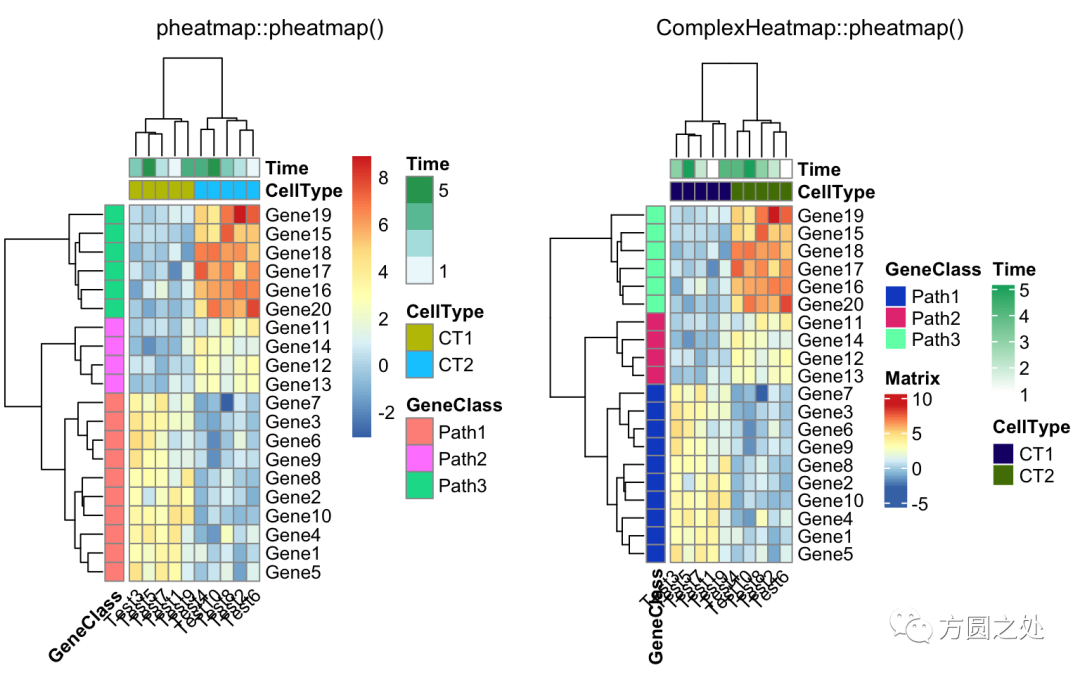
调整列名的旋转至水平方向:
compare_pheatmap(test,
annotation_col = annotation_col,
angle_col = "0")
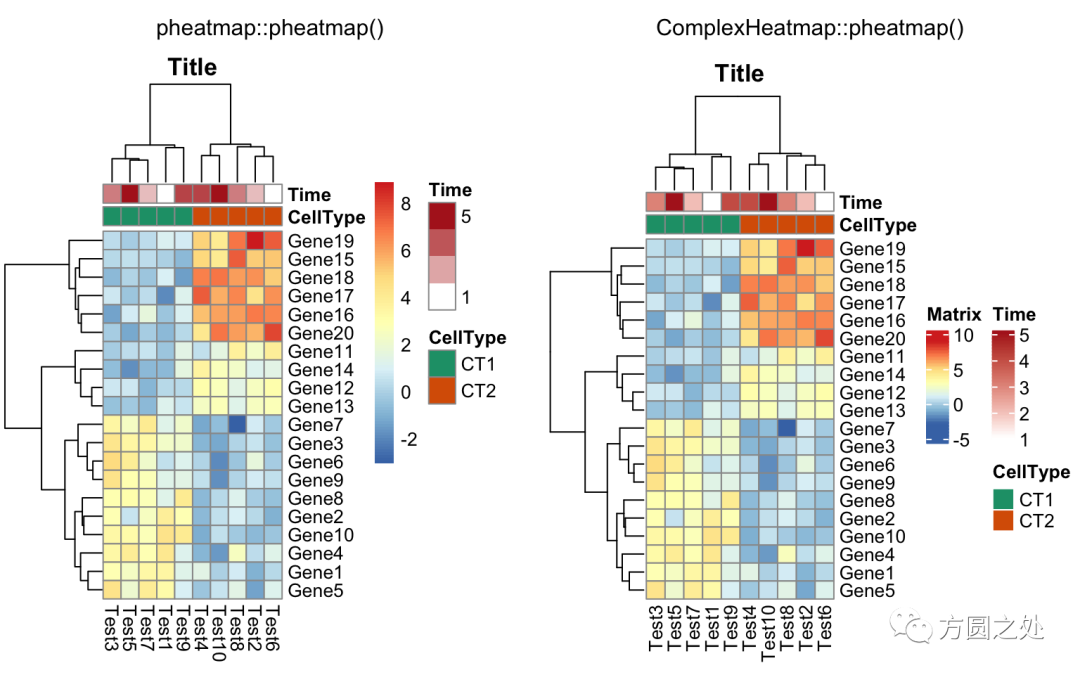
控制 annotation 的颜色:
ann_colors = list(
Time = c("white", "firebrick"),
CellType = c(CT1 = "#1B9E77", CT2 = "#D95F02"),
GeneClass = c(Path1 = "#7570B3", Path2 = "#E7298A", Path3 = "#66A61E")
)
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_colors = ann_colors,
main = "Title")
同时控制行和列 annotation 的颜色:
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_row = annotation_row,
annotation_colors = ann_colors)
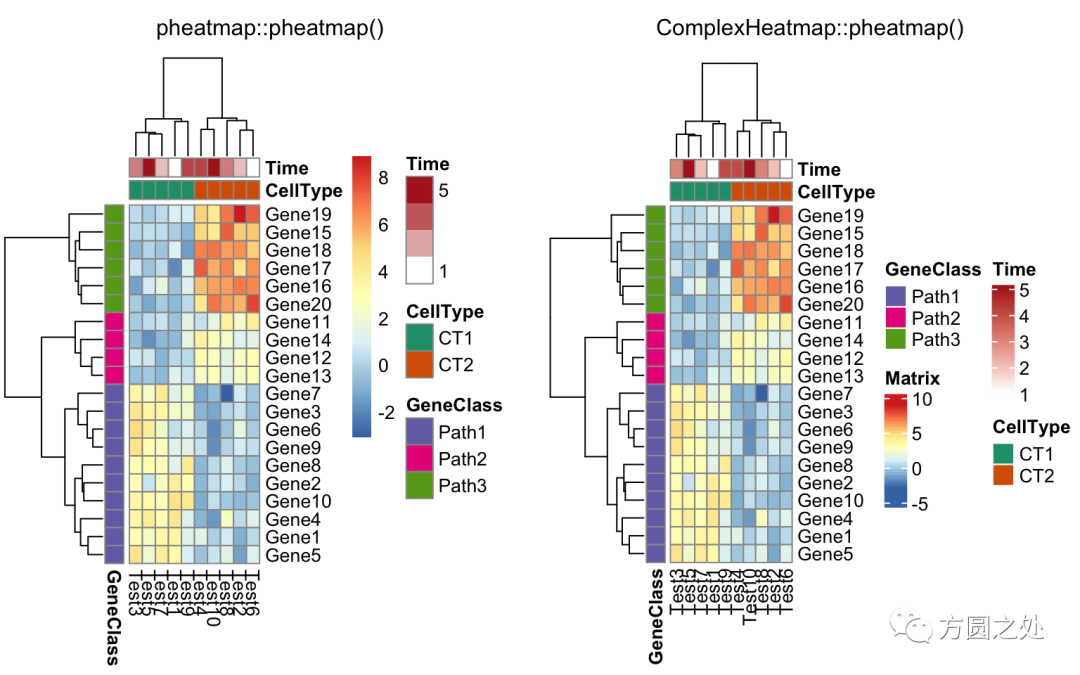
只提供部分 annotation 的颜色,未提供颜色的 annotation 使用随机颜色:
compare_pheatmap(test,
annotation_col = annotation_col,
annotation_colors = ann_colors[2])
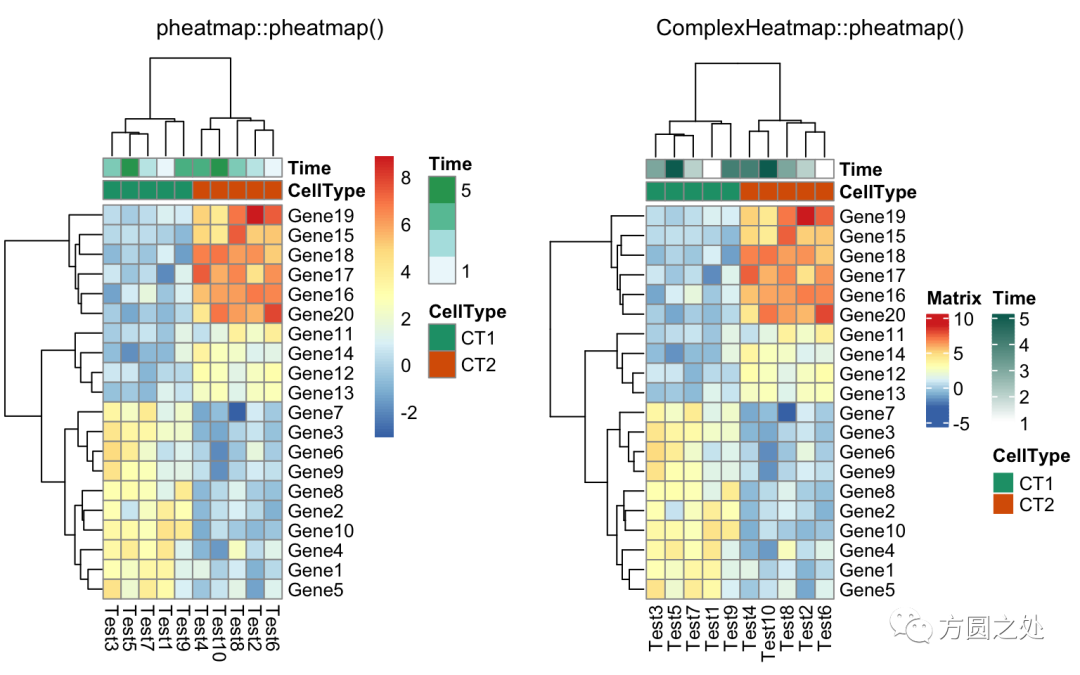
将热图分为两部分,我建议直接使用Heatmap()中的row_split或者row_km参数。
compare_pheatmap(test,
annotation_col = annotation_col,
cluster_rows = FALSE,
gaps_row = c(10, 14))
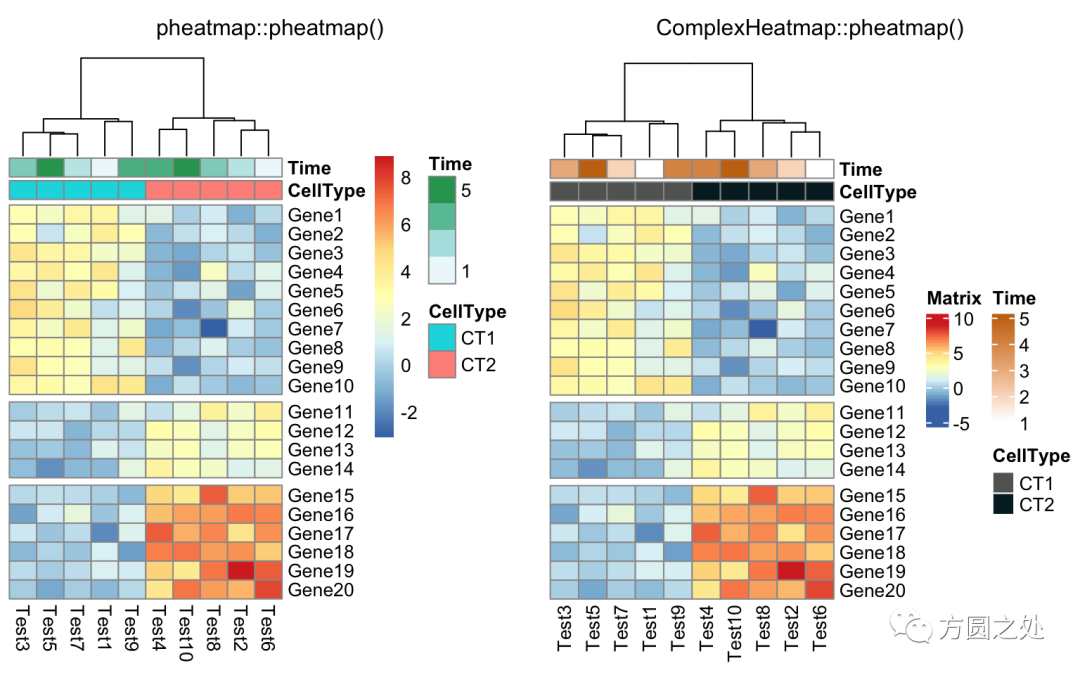
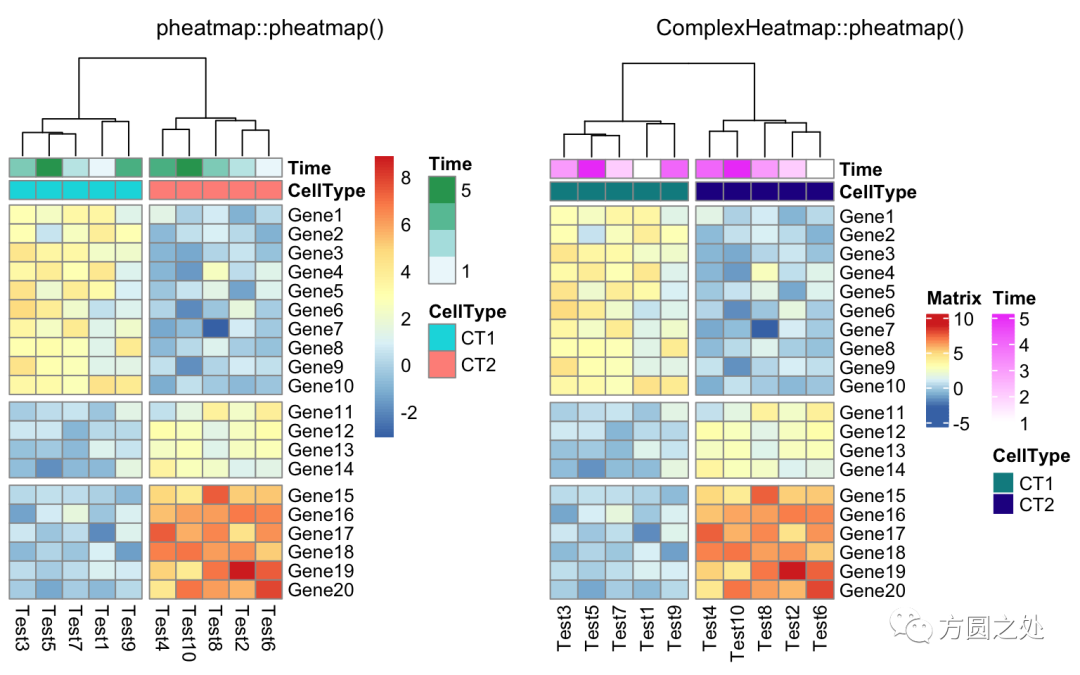
使用cutree()对列的 dendrogram 切分:
compare_pheatmap(test,
annotation_col = annotation_col,
cluster_rows = FALSE,
gaps_row = c(10, 14),
cutree_col = 2)
自定义行名:
labels_row = c("", "", "", "", "", "",
"", "", "", "", "", "", "", "", "",
"", "", "Il10", "Il15", "Il1b")
compare_pheatmap(test,
annotation_col = annotation_col,
labels_row = labels_row)
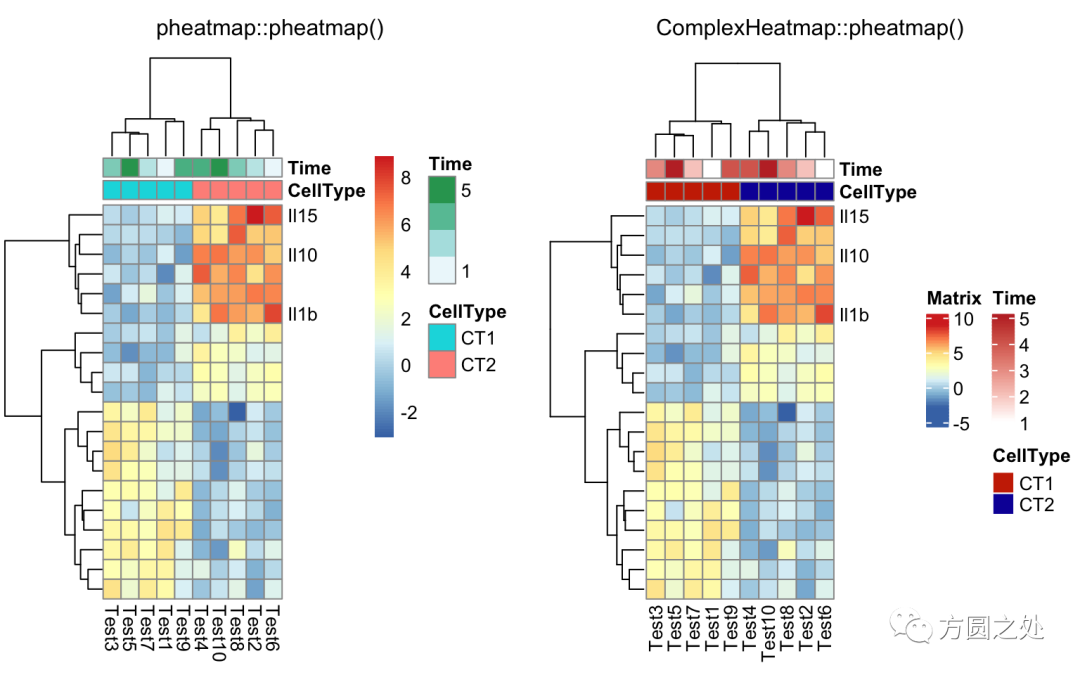
自定义聚类的距离:
drows = dist(test, method = "minkowski")
dcols = dist(t(test), method = "minkowski")
compare_pheatmap(test,
clustering_distance_rows = drows,
clustering_distance_cols = dcols)
对聚类的回调处理:
library(dendsort)
callback = function(hc, ...){dendsort(hc)}
compare_pheatmap(test,
clustering_callback = callback)
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
从 pheatmap 无缝迁移至 ComplexHeatmap的更多相关文章
- 镜像回源主要用于无缝迁移数据到OSS,即服务已经在自己建立的源站或者在其他云产品上运行,需要迁移到OSS上,但是又不能停止服务,此时可利用镜像回写功能实现。
管理回源设置_管理文件_开发指南_对象存储 OSS-阿里云 https://help.aliyun.com/document_detail/31865.html 通过回源设置,对于获取数据的请求以多种 ...
- git 使用案例(本地仓库无缝迁移远程仓库)
之前都是直接从gitlab上clone代码,然后把本地代码copy过去,然后push.有点麻烦,查询了一下如何无缝从本地仓库迁移到远程仓库.记录一波... 下面的例子采用github来做例子. 1. ...
- 从log4j日志无缝迁移至logback
ogback对比log4j的有点在此就不赘述了. 由于在项目的原有代码中,大量的日志生成是通过log4j实现的,新的代码希望通过logback的方式生成日志,同时希望将老的代码在不修改的情况下直接将日 ...
- Kubernetes实战指南(三十一):零宕机无缝迁移Spring Cloud至k8s
1. 项目迁移背景 1.1 为什么要在"太岁"上动土? 目前公司的测试环境.UAT环境.生产环境均已经使用k8s进行维护管理,大部分项目均已完成容器化,并且已经在线上平稳运行许久. ...
- 「Elasticsearch」ES重建索引怎么才能做到数据无缝迁移呢?
背景 众所周知,Elasticsearch是⼀个实时的分布式搜索引擎,为⽤户提供搜索服务.当我们决定存储某种数据,在创建索引的时候就需要将数据结构,即Mapping确定下来,于此同时索引的设定和很多固 ...
- 如何无缝迁移 SpringCloud/Dubbo 应用到 Serverless 架构
作者 | 行松 阿里巴巴云原生团队 本文整理自<Serverless 技术公开课>,"Serverless"公众号后台回复"入门",即可获取系列文章 ...
- linux 软连接方式实现上传文件存储目录的无缝迁移
背景: 由于前期的磁盘空间规划与后期的业务要求不符合.原先/home被用于用户上传文件的存储目录,但是由于上传文件的逐渐增多,而原来的/home目录的空间不足,需要给/home目录进行扩容.同时各个应 ...
- 手绘流程图,教你WSL2与Docker容器无缝互相迁移
摘要:本文主要介绍WSL2与Docker容器无缝迁移镜像. 本文分享自华为云社区<WSL2与Docker容器,无缝互相迁移>,作者: tsjsdbd . 注:本文提到的WSL都是指WSL2 ...
- 为什么要 MySQL 迁移到 Maria DB
在Oracle收购了SUN公司之后, MySQL很不幸的落在了Oracle的手中,MySQL与Oracle DB存在竞争关系,很可能导致Oracle公司影响MySQL的开发与开放.MySQL之父Wid ...
- 利用mysql-proxy 代理无法迁移数据库
一.什么是数据库迁移? 随着业务的增长或机器老化等原因,不可避免会碰到将数据库从一台机器迁移到另一台机器(集群)的问题.数据库迁移可分为冷迁(离线)和热迁(在线实时). 二.如何无缝迁移? 以旧库 1 ...
随机推荐
- Hadoop 安装及目录结构
一.准备工作 [1]创建用户:useradd 用户名[2]配置创建的用户具有 root权限,修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:(注意:需要先给sud ...
- 内核不中断前提下,Gaussdb(DWS)内存报错排查方法
摘要:本文主要讲解如何在内核保证操作不能中断采取的特殊处理,理论上用户执行的sql使用的内存(dynamic_used_memory) 是不会大范围的超过max_dynamic_memory的内存的 ...
- Dubbo服务提供者如何优雅升级?
文章首发于公众号:BiggerBoy.欢迎关注. 往期文章推荐 大坑!隐式转换导致索引失效...高性能分布式限流:Redis+Lua真香!MySQL索引知识点&常见问题汇总联合索引在B+树上的 ...
- bpmnjs的基本使用(vue)
bpmn-js在vue中的基本使用 效果: 下载依赖包 npm i bpmn-js bpmn-js-properties-panel camunda-bpmn-moddle "bpmn-js ...
- python中socket使用UDP协议简单实现服务端与客户端通信
UDP为不可靠传输,也就是发送方不关心对方是否收到消息,一般用于聊天软件.但现在的聊天软件虽然使用的是UDP协议,但已从代码层面上解决了丢失信息的问题. 下面使用python代码简单实现了服务端与客户 ...
- Prometheus+Grafana监控系统
Prometheus vs Zabbix Zabbix的客户端更多是只做上报的事情,push模式.而Prometheus则是客户端本地也会存储监控数据,服务端定时来拉取想要的数据. Zabbix的客户 ...
- Unity学习笔记01 —— 编辑器
场景Scene 基本操作 按下鼠标滚轮拖动场景,滑动滚轮缩放场景. 鼠标右键旋转场景,点击""后,通过左键移动场景. 点击右键同时按下W/S/A/D/Q/E键可实现场景漫游. 在S ...
- 3.载荷和结果实体类以及Jwt
1.昨天为了将两个项目推送到远程仓库,了解了一下分支,将一个小工程作为一个分支,这是发生在git add .,git commit -m "描述"以及git reomte add ...
- 进程,Process模块,join方法,ipc机制,守护进程
多道技术: """ 在学习并发编程的过程中 不做刻意提醒的情况下 默认一台计算机就一个CPU(只有一个干活的人) """ 单道技术 所有的程 ...
- Springboot一些常用注解
Springboot启动注解 @SpringbootApplication 这个注解是Springboot最核心的注解,用在Springboot的主类上,标识这是一个Springboot应用,用来开启 ...