HEDGE: 通过特征交互检测生成文本分类的层次解释《Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection》(LIME算法、神经网络预测的分层解释CD和ACD、Shapley Value夏普利值、Leave-One-Out留一法、HEDGE)
先来吐个槽:啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊,为什么我的导师又嫌我PPT做的很烂,( Ĭ ^ Ĭ )
论文:Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
GitHub:https://github.com/UVa-NLP/HEDGE
ACL 2020的论文。
收,开始正文。
这篇文章是在知乎找的推荐,然后看的 --> ACL 2020 最新论文概览
贴一下推荐的概述:解释生成式神经网络在现实中的应用。在自然语言处理中,现有生成式方法从输入文本中选择单词或短语作为解释,但是忽略了它们之间的相互作用。在本文工作中,通过检测特征交互来构建层次性的解释。 这种解释可视化了单词和短语如何在层次结构中在不同级别上进行组合,这可以帮助用户理解黑盒模型的决策。 通过自动和人工评估,在两个基准数据集上使用三个文本分类器(LSTM,CNN和BERT)对所提出的方法进行了评估。
这篇论文,我还真的看了挺久了,看了很多资料,结果老板又嫌弃我的PPT,说我的PPT没有重点,字太多,我已经改了,这次没有那么多字了,我都放在备注里了,略微有那么一点点的桑心(就一点点,习惯就好了
这篇文章就是研究单词和短语的相互作用,来解释为什么模型最终会做出这种结果。说人话就是:看看为什么这个黑盒模型做出这种结果,因为模型不可知,所以就倒着解释为什么是这种结果。(开始绕口令
一、介绍
这篇论文涉及到了一些知识点,先罗列一些知识点。
1.LIME(黑盒模型解析技术)
算法原理:对于一个分类器(复杂模型),采用一个可解释的模型(简单模型如线性规划),搭配可解释的特征进行适配,并且这个可解释模型在局部的表现上很接近复杂模型的效果。
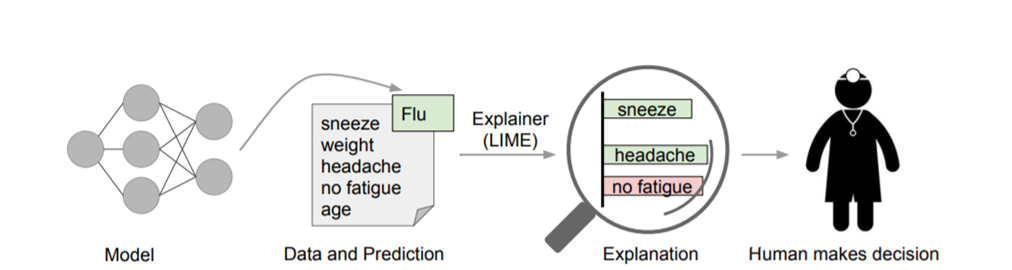

Figutr 1. Figure 2.
图1:解释个人预测。一个模型预测病人患有流感,LIME突出显示了导致该预测的病人历史记录中的症状。打喷嚏和头痛被描述为有助于预测“流感”,而“不疲劳”是反对它的证据。有了这些信息,医生就可以做出是否相信模型预测的明智决定.
如图2所示,红色和蓝色区域表示一个复杂的分类模型(黑盒),图中加粗的红色十字表示需要解释的样本,显然,我们很难从全局用一个可解释的模型(例如线性模型)去逼近拟合它。但是,当我们把关注点从全局放到局部时,可以看到在某些局部是可以用线性模型去拟合的。具体来说,我们从加粗的红色十字样本周围采样,所谓采样就是对原始样本的特征做一些扰动,将采样出的样本用分类模型分类并得到结果(红十字和蓝色点),同时根据采样样本与加粗红十字的距离赋予权重(权重以标志的大小表示)。虚线表示通过这些采样样本学到的局部可解释模型,在这个例子中就是一个简单的线性分类器。在此基础上,我们就可以依据这个局部的可解释模型对这个分类结果进行解释了。
相关参考:
1.LIME算法原理
3.论文《“Why Should I Trust You?” Explaining the Predictions of Any Classifier》
2.神经网络预测的分层解释CD和ACD
(1)Contextual Decomposition of LSTM(CD)
通过“语境分解”的概念,进而提出了上下文分解(CD)方法,一种LSTM解释算法,用于分析由标准LSTM做出的单个预测,而不需要对底层模型进行任何更改。通过分解LSTM的输出,CD捕获单词或变量组合对LSTM的最终预测的贡献,能够提取单词、短语和交互级别的重要性分数。这是一种新的解释方法,可以在不修改底层模型的情况下,对LSTM做出的个体预测进行解释。
(2)Agglomerative Contextual Decomposition (ACD)
与CD只应用于解释LSTM网络架构不同,ACD在不同的DNN模型中推广CD算法,该方法可以帮助找到错误的预测结果。ACD通过分别计算每个特征的CD分数进行初始化后,迭代地选择得分最高的特征组的k%内的所有特征组(k为超参数,图像固定为95,文本固定为90),并将其添加到层次结构中。

Figure 3.
通过文本示例,证明ACD可以诊断出不正确的预测:
图3为ACD解读了SST LSTM的预测情绪。蓝色是积极情绪,白色是中性情绪,红色是消极情绪。最下面一行显示句子中单个单词的CD分数,往上的每一行显示的是ACD识别的重要短语,以及短语的CD分数,收敛到最上面一行的模型颜色为最终预测的情绪。
这句话的意思是:一个好的演员阵容无法让这部发自内心的电影脱颖而出
a great ensemble cast (positive) 和 n’t lift this heartfelt enterprise out of the ordinary (negative).这两个短句结合在一起才结论为积极,这表明机器错误的将这两个短句产生联系。在ACD下很容易辨认出。
相关参考:
2.HIERARCHICAL INTERPRETATIONS FOR NEURAL NET- WORK PREDICTIONS
3.Shapley Value(夏普利值)
本篇论文中,运用了夏普利值的概念,重点介绍一下夏普利值。
Shapley Value起源于博弈论:n个人合作,创造了v(N)的价值,如何对所创造的价值进行分配。
它的目标是构造一种综合考虑冲突各方要求的折中的效用分配方案,从而保证分配的公平性。
约克3块饼、汤姆5块饼、邀请路人吃饼,路人给了他们8个金币。
汤姆:“理应我得5个金币,你得3个金币。”约克:“既然一起吃,理应平分这8个金币,每人各4块金币。”
夏普利:“3人吃了8块饼,其中,约克带了3块饼,汤姆带了5块,一共是8块饼。
约克吃了其中的1/3,即8/3块,路人吃了约克饼中的3-8/3=1/3;汤姆也吃了8/3,路人吃了他的饼中的5-8/3=7/3。
这样,路人所吃的8/3块饼中,有约克的1/3,汤姆的7/3。因此,公平的分法:约克得1个金币,汤姆得7个金币。”
在这个故事中,夏普利所提出的对金币的“公平的”分法,遵循的原则是:所得与自己的贡献相等。
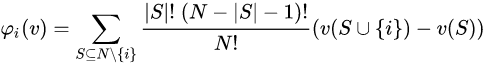
这个公式就是:每个参与者i应当分配的收益。这个公式堪称合作博弈中的纳什均衡。
夏普利值是一种分配方式,其原则就是所得与自己的贡献相等。
Shapley值是一个特征值在不同联盟中对预测的平均贡献。Shapley值并不是从模型中删除特征时的预测差异。
优点:预测和平均预测之间的差异在实例的特征值中是公平分布的–这就是Shapley值的效率属性。这个属性使Shapley值区别于其他方法,如LIME。LIME并不能保证预测值在特征间是公平分布的。Shapley值可能是唯一能提供完整解释的方法。在可解释性的情况下–Shapley 值可能是唯一符合法律规定的方法,因为它是建立在坚实的理论基础上的,并且公平地分配了效果。
Shapley 值允许进行对比性解释(contrastive explanations)。你可以不将一个预测与整个数据集的平均预测进行比较,而是与一个子集甚至一个数据点进行比较。这种对比性也是LIME等局部模型所不具备的。
Shapley 值是唯一具有坚实理论的解释方法。像LIME这样的方法假设机器学习模型在局部的线性行为,但没有理论来解释为什么要这样做。
缺点:Shapley值需要大量的计算时间。因为是指数型增长的,在99.9%的实际问题中,只有近似解是可行的。
Shapley值可能被误解。特征值的Shapley值不是模型训练中去掉特征后的预测值之差。
对Shapley值的解释是:给定当前的特征值集,一个特征值对实际预测值和平均预测值之差的贡献就是估计的Shapley值。
相关参考:
1.夏普利值(百度百科)
7.一篇改进论文,树结构,但是我没看《Consistent feature attribution for tree ensembles》
4.Leave-One-Out(留一法)
相关参考:
1.留一法(交叉验证法,Leave-One-Out Cross Validation)
2.10折交叉验证(10-fold Cross Validation)与留一法(Leave-One-Out)、分层采样(Stratification)
//------------------------------------------分割线------------------------------------------------------//
接下来是正文部分。

Figure 4.
现存的方法只是单独提取输入句子的词或短语作为自然语言处理模型的解释特征,将模型预测结果按贡献程度归到单独的词或短语,没有考虑到它们之间的交互关系,只提供了局部的解释性,使得模型的解释性不强,因此需要将词或短语的交互关系和模型预测结果联系起来,从而更好地解释模型的运行机制。
如图4,LIME和CD两种方法分别捉住了单词waste和短语waste of 两个关键词,并赋予相应的贡献度,再根据各个词语对句子正负情绪判断的贡献度将句子判断为负,但是只考虑了局部的解释性,没办法很好地解释good performance这个短语对于这整个句子被判断为负的贡献程度。
所以本文提出了通过检测特征交互来构建层次化的解释,构建的这些解释能够可视化不同的词组和短语在不同的特征层次中是怎么组合发挥作用的,进一步让人们明白模型的运作原理。本文提出的模型为model-agnostic,与模型无关的方法,称为HEDGE,其根据句子中词或短语之间最弱的连接将句子分割,并赋予每个部分贡献值,最后形成对模型结果的多粒度的层次化的解释。例如上面的例子,本文的模型能够判断出good是从属于waste的,所以就能很好的解释为什么整个句子在good存在的情况下还被判断为负的情况。
HEDGE(Hierarchical Explanation via Divisive Generation) (通过分裂生成进行层次结构解释)
这项工作的贡献有三点:
(1)设计了一种自上而下的模型不可知论方法,该方法通过特征交互检测构造层次解释。
(2)提出了一种简单有效的评分函数来量化与模型预测有关的特征贡献。
(3)将本文提出的算法与几种竞争方法通过自动评估和人工评估进行解释生成的结果进行比较。
二、相关工作和方法
生成模型不可知的解释的核心是如何有效地评估特征相对于预测的重要性。
相关工作:
1.与模型无关的解释
Leave-one-out、LIME、Shapley Value
2.层次解释
CD、ACD、树结构、语言树结构
1.到目前为止,有关模型不可知的说明的大多数现有工作都集中在单词级别上,比如留一法(就是把一个大的数据集分为k个小数据集,其中k-1个作为训练集,剩下的一个作为测试集,然后选择下一个作为测试集,剩下的k-1个作为训练集,以此类推。),LIME,Shapley值,仍然属于生成单词级解释的类别。受Shapley值的扩展的启发,设计了一种功能来检测特征相互作用,以构建分层模型不可知的解释。与以往使用Shapley值进行特征重要性评估的工作不同,本文提出了一种有效且更简单的方法,该方法胜过基于Shapley的方法。
2.层次解释,CD和ACD,进行特征重要性评估,并采用分层层次聚类算法将特征汇总在一起以进行层次解释。指出了CD和ACD在形式上下文中计算短语交互时的局限性,并通过量化单词和短语的上下文无关性的重要性提出了两种解释算法。所提出的特征交互检测方法的主要组成部分是基于Shapley交互指数。后来改进,通过沿给定树结构的SHAP交互值计算特征交互,以及利用语言树结构来捕获文本分类之外的各个特征。这两种方法都需要给出层次结构,而本文的方法仅基于特征交互检测构造结构,而无需借助外部结构信息。算法使用自上而下的方式根据最弱的交互将长文本分为短语和单词。
方法:
1.检测特征交互detecting
2.量化特征重要性quantifying

整个算法流程如图:
第6步的Equation 1 就是detecting,第9步是quantifying,
整个流程基本是这两步的交替,寻找分割点和赋予贡献度。
接下来是公式(我只知道公式是做什么的,但是为什么是这个公式以及这个公式怎么实现的,我不知道...):
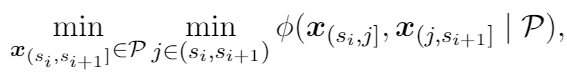 (1)
(1)
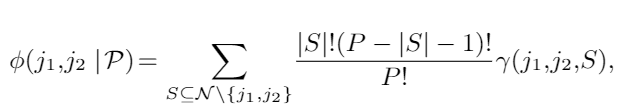 (2)
(2)
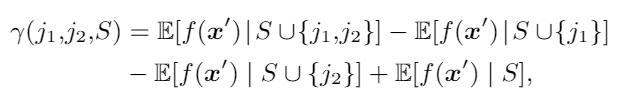 (3)
(3)
 (4)
(4)
 (5)
(5)
公式(1)的内层最小化是用来寻找分割点,外层最小化是用来寻找分割段,公式(1)中的交互关系是使用coalition game theory联盟博弈理论的Shapley interaction index夏普利交互指标来计算,即公式(2)
公式(2)S表示文本跨度的子集,位于N \ {j1,j2}中,| S |是S的大小,而γ(j1,j2,S)的定义如公式(3)
公式(3)其实就是各个文段在经过模型后的结果的期望值的加减
随着分割的进行,计算量以指数级增长,(2)式会变成不可解,所以改为求它的近似解。公式(4),这是基于一个词或短语通常跟它的周围的上下文有强联系的假设,将文段的范围限定在关键词的周围m个词。
公式(5)是为了衡量特征x对模型预测的贡献
如果模型预测正确,公式(5)等式右边第一项会比第二项大,表示该文段对模型预测结果的贡献是正的值,反之为负的值。
(具体的可以去论文里仔细看看)
三、实验
数据集:SST-2、IMDB
模型:CNN、LSTM 、BERT

Table 1.
表1显示了实验中两个数据集上模型的最佳性能,其中BERT以更高的分类精度胜过CNN和LSTM
三种评估方法:
 (6)
(6)
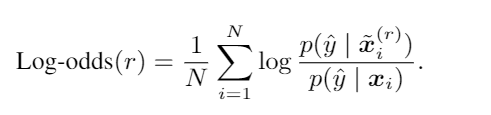 (7)
(7)
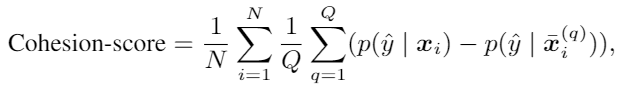 (8)
(8)
AOPC:通过删去得分靠前的k个词后模型的结果与删除之前比较,可以得到删去的词的重要性,结果值越大表示词对于句子预测结果贡献越大。
log-odds scores优势对数记分法:将句子中的前r%个词用0 mask,结果越小,表示被mask掉的词越重要
Cohesion-score内聚得分:这是本文提出的衡量一段文字中词之间的交互程度的方法。挑选一个HEDGE分割出来的片段,随机插入到句子中其他位置,重复得到Q个不同的乱序句子,然后计算平均值,值越高越好
定量评价:
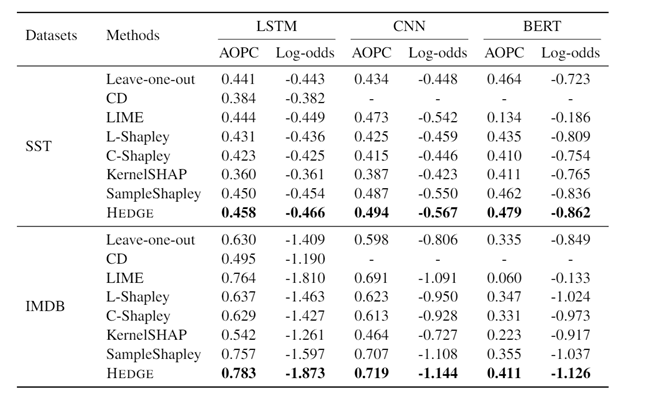

Table 2. Table 3.
表2:本文的HEDGE在AOPC、Log-odds优势对数记分两个指标的表现都要优于其他模型,Shapley类的方法也有不错的表现,但是模型的复杂度比HEDGE高。
表3:在Cohesion-score内聚得分衡量下,同是结构可视化的方法,HEDGE比ACD好,而且HEDGE在BERT模型上的效果要比其他模型要好,说明BERT对于关键词语的变动更敏感
定性分析:
(1)当LSTM误判时,HEDGE和ACD的可视化结果
这句话的意思是:虚空中的精彩练习

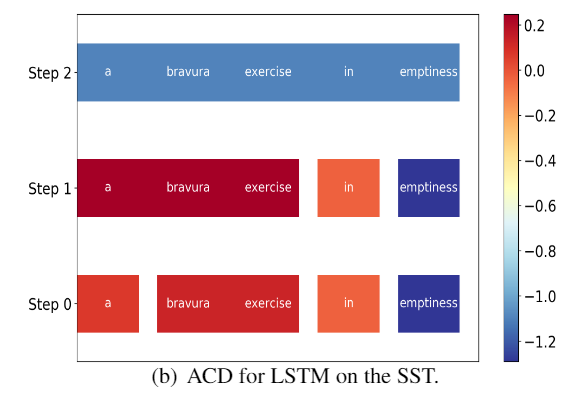
Figure 5. Figure 6.
LSTM判断为正的句子,实际为负。bravura exercise 翻转了in emptiness的极性为正,这也解释了为什么LSTM判断错误。
ACD 错误地标识两个词的极性,而且忽略了词之间的交互关系。
(2)HEDGE在LSTM和BERT上的比较
这句话的意思是:一点也不坏
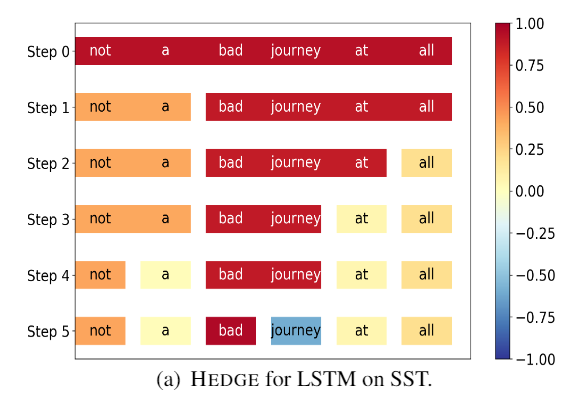

Figure 7. Figure 8.
BERT捉住了not a bad这段关键信息,从而可以做出正确判断,而LSTM却忽略了这段信息。
四、总结与展望
总结:
本文提出了一种有效的方法HEDGE,即通过检测特征相互作用来建立模型不可知的分层解释。在这项工作中,主要关注情绪分类任务。在两个基准数据集上使用三种不同的神经网络模型对HEDGE进行了测试,并将其与几种竞争性基准方法进行了比较。 HEDGE的优越性已通过自动评估和人工评估得到了认可。
展望(参考):
1.主要是针对文本情感分类模型的解释,需要利用分类结果信息,还不能扩展到无监督的模型。
2.算法的主要不同点是利用单词或短语之间的交互关系,但是这种交互关系是否可以直接在模型的基础上改进。
相关参考:
1.《Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection》阅读笔记
3.Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection(里面有视频链接,但是我没看)
参考文献(直接百度学术引用的,格式可能不太对,烦了,毁灭吧):
[1] Ribeiro M T , Singh S , Guestrin C . "Why Should I Trust You?": Explaining the Predictions of Any Classifier [C]// the 22nd ACM SIGKDD International Conference. ACM, 2016.
[2] Murdoch W J , Liu P J , Yu B . Beyond Word Importance: Contextual Decomposition to Extract Interactions from LSTMs[J]. 2018.
[3] Singh C , Murdoch W J , Yu B . Hierarchical interpretations for neural network predictions[J]. 2019.
[4] Kuhn H W , Tucker A W . Contributions to the theory of games (AM-28)[J]. 1953, 10.1515/9781400881970.
[5] Chen H , Zheng G , Ji Y . Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection[J].Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020.
最近怨气有点重,打扰打扰。
多干正事,少看没用的东西。
告辞。
HEDGE: 通过特征交互检测生成文本分类的层次解释《Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection》(LIME算法、神经网络预测的分层解释CD和ACD、Shapley Value夏普利值、Leave-One-Out留一法、HEDGE)的更多相关文章
- NLP文本分类
引言 其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作.我觉得这也是我这辈子为数不多的剩下的可以自己去追 ...
- 自己动手实现深度学习框架-8 RNN文本分类和文本生成模型
代码仓库: https://github.com/brandonlyg/cute-dl 目标 上阶段cute-dl已经可以构建基础的RNN模型.但对文本相模型的支持不够友好, 这个阶段 ...
- NLTK学习笔记(六):利用机器学习进行文本分类
目录 一.监督式分类:建立在训练语料基础上的分类 特征提取器和朴素贝叶斯分类器 过拟合:当特征过多 错误分析 二.实例:文本分类和词性标注 文本分类 词性标注:"决策树"分类器 三 ...
- DL4J之CNN对今日头条文本分类
一.数据集介绍 数据来源:今日头条客户端 数据格式如下: 6551700932705387022_!_101_!_news_culture_!_京城最值得你来场文化之旅的博物馆_!_保利集团,马未都, ...
- 使用PyTorch建立你的第一个文本分类模型
概述 学习如何使用PyTorch执行文本分类 理解解决文本分类时所涉及的要点 学习使用包填充(Pack Padding)特性 介绍 我总是使用最先进的架构来在一些比赛提交模型结果.得益于PyTorch ...
- 文本图Tranformer在文本分类中的应用
原创作者 | 苏菲 论文来源: https://aclanthology.org/2020.emnlp-main.668/ 论文题目: Text Graph Transformer for Docum ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- NLP系列(3)_用朴素贝叶斯进行文本分类(下)
作者: 龙心尘 && 寒小阳 时间:2016年2月. 出处: http://blog.csdn.net/longxinchen_ml/article/details/50629110 ...
- 基于SVMLight的文本分类
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本 .非线性及高维模式识别 中表现出许多特有的优势,并能够推广应用到函数拟合等 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- 洛谷P1432
水一道绿题,整体思路和八数码很像,哈希表存解,然后常规模拟即可 #include<iostream> #include<utility> #include<queue&g ...
- 解决方案 | AutoCAD 版本+版本号+受支持的 .NET SDK版本+.NET Framework版本
关于 Managed .NET 兼容性 Managed .NET 应用程序通常与扩展基于 AutoCAD 的产品的行为和功能的公司和第三方应用程序关联. 在移植到最新版本后,并非所有 .NET 应用程 ...
- centos7安装pcntl扩展
查看PHP扩展加载的目录php -i | grep extension_dir Centos下使用yum安装php默认是都不带pcntl扩展,需要安装扩展需要下载安装包,编译安装. 首先查看你的服务器 ...
- 基于Java+Spring+Vue仓储出入库管理系统设计和实现
\n文末获取源码联系 感兴趣的可以先收藏起来,大家在毕设选题,项目以及论文编写等相关问题都可以给我加好友咨询 系统介绍: 网络的广泛应用给生活带来了十分的便利.所以把仓储出入库管理与现在网络相结合,利 ...
- NOIP2023
坐标HA 背景 打完CSP-S后觉得自主招生稳了,就想着NOIP摆烂,所以此游记仅仅是为了凑数. 正文 Day 0 不出所料,机房统一集训,但是在CSP集训后导致的期中挂分的影响下,这一想法被家长以及 ...
- Java maven反应堆构建学习实践
Java maven反应堆构建学习实践 实践环境 Apache Maven 3.0.5 (Red Hat 3.0.5-17) 应用示例 示例项目结构 maven示例项目组织结构如下 maven-stu ...
- STL 算法 <algorithm>,
STL 算法部分主要由头文件 <algorithm>,<numeric>,<functional > 组成.要使用 STL 中的算法函数必须包含头文件 < a ...
- python解决urllib发送请求报错:urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:xxxx)>
在使用urllib.request.Request(url)前,添加代码放到最前面 import ssl ssl._create_default_https_context = ssl._create ...
- 倒装句&强调句
倒装句 你[吃][胡萝卜]了吗? 吃胡萝卜了吗,[你]? 强调点不同 汉语常见于口语表达 英语则常见于书面用语 英语的语序是 主语 谓语(动词) 通常把谓语动词提前 1.完全倒装句 谓语部分完全放在主 ...
- ubuntu禁止内核自动更新
ubuntu禁止内核自动更新 查看已安装内核dpkg --get-selections |grep linux-image 查看正在使用的内核uname -a 禁止内核更新sudo apt-mark ...