第 6章 Python 应对反爬虫策略
第 6章 Python 应对反爬虫策略
爬取一个网站的基本步骤
(1)分析请求:URL 规则、请求头规则、请求参数规则。
(2)模拟请求:通过 Requests 库或 urllib 库来模拟请求。
(3)解析数据:获取请求返回的结果,利用 lxml、Beautiful Soup 或正则表达式提取需
要的节点数据。
(4)保存数据:把解析的数据持久化到本地,保存为二进制文件、TXT 文件、CSV 文
件、Excel 文件、数据库等。
随着爬取的网站越来越多,你会慢慢发现有些网站获取不到正确数据,或者根本获取不了数据,原因是这些站点使用了一些反爬虫策略。
6.1 反爬虫概述
6.1.1 为什么会出现反爬虫
编写爬虫的目的是自动获取站点的一些数据,而反爬虫则是利用技术手段防止爬虫爬
取数据,为什么要防止爬虫爬取数据的原因如下所示:
很多初级爬虫非常简单,不管服务器压力,有时甚至会使网站宕机。 保护数据,重要或涉及用户利益的数据不希望被别人爬取。 商业竞争,多发生在同行之间,如电商。
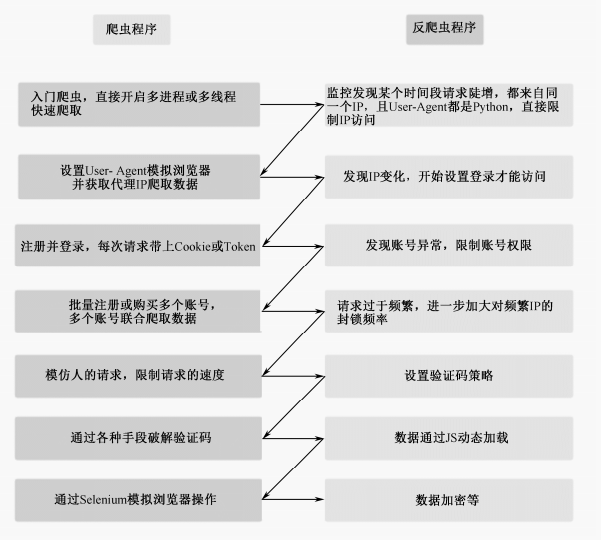
6.1.2 常见的爬虫与反爬虫大战
常见的爬虫与反爬虫大战流程
6.2 反爬虫策略
接下来了解一些基本的反爬虫策略,以及应对反爬虫的策略。
6.2.1 User-Agent 限制
服务端通过识别请求中的 User-Agent 是否为合理真实的浏览器,从而来判断是否为爬
虫程序,比如 urllib 库中默认的 User-Agent 请求头为 Python-urllib/2.1,而 Requests 库中为
python-requests/2.18.4,服务器检测到这样的非真实的浏览器请求头就会进行限制,一个正常的浏览器 User-Agent 请求头示例如下:
Mozilla/6.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/68.0.3440.106 Safari/537.36
每个浏览器的 User-Agent 因为浏览器类型和版本号的区别都会有所不同,,关于模拟 User-Agent,可以用一个很便利的库fake-useragent,但是生成伪造(模拟)数据的库中,Faker是一个非常流行的选项,它可以用来生成各种各样的假数据,如姓名、地址、电话号码等。也可用来生成useragent。
from faker import Faker
facker = Faker()
ua =facker.user_agent()
print(ua)
运行结果如下:
Mozilla/5.0 (compatible; MSIE 5.0; Windows 95; Trident/5.1)
也可以指定生成浏览器的。
from faker import Faker
def generate_user_agents(num=10):
faker = Faker()
ua =faker.user_agent()
for _ in range(num):
print("Chrome:", faker.chrome(version_from=50, version_to=80))
print("Firefox:", faker.firefox())
print("IE:", faker.internet_explorer())
print('随机生成:',ua)
if __name__ == '__main__':
# 生成并打印10个随机User-Agent字符串
generate_user_agents(1)
代码执行结果如下:
Chrome: Mozilla/5.0 (X11; Linux i686) AppleWebKit/531.0 (KHTML, like Gecko) Chrome/80.0.883.0 Safari/531.0
Firefox: Mozilla/5.0 (X11; Linux x86_64; rv:1.9.7.20) Gecko/7116-07-25 05:40:18 Firefox/3.8
IE: Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/3.1)
随机生成: Mozilla/5.0 (Windows; U; Windows NT 6.1) AppleWebKit/533.16.2 (KHTML, like Gecko) Version/4.0.1 Safari/533.16.2
6.2.2 302 重定向
当访问某个站点的速度过快或发出的请求过多时,会引起网络流量异常,服务器识别出是爬虫发出的请求,会向客户端发送一个跳转链接,大部分是一个图片验证链接,有时是空链接。对于这种情况,有两种可选的操作。
- 降低访问速度,比如每次请求后调用 time.sleep()休眠一小段时间,避免被封。
- 使用代理 IP 进行访问。
任务量比较小时可以采取第一种策略。另外,这个休眠时间建议使用一个随机数,比如 time.sleep(random.randint(1,10)),因为有些服务器会把定时访问判定为爬虫。
6.2.3 IP 限制
除了上述这种单位时间内访问频率过高让服务器判定为爬虫进行封禁,导致无法获取数据的情况,还有一些站点限制了每个 IP 在一定时间内访问的频次,比如每个 IP 一天只能访问 100 次,超过这个次数就不能访问了。此时降低访问速度也是没用的,只能通过代理 IP 的形式来爬取更多的数据。
6.2.4 什么是网络代理
网络代理是一种特殊的网络服务,网络终端(客户端)通过这个服务(代理服务器)和另一个终端(服务器端)进行非直接的连接,简单点说就是利用代理服务器的 IP 上网。
代理 IP 的分类(根据隐藏级别)如下:
- 透明代理:服务器知道你用了代理 IP,并且知道你的真实 IP。
- 普通代理:服务器知道你用了代理 IP,但不知道你的真实 IP。
- 高匿代理:服务器不知道你用了代理 IP,也不知道你的真实 IP。
6.2.5 如何获取代理 IP
网络代理分为免费代理和付费代理两种(有些付费代理也会提供一些免费的代理 IP,
如 http://ip.zdaye.com/FreeIPlist.html),免费代理一般稳定性不高,由于免费的原因,用的
人太多,导致这些 IP 早被某些站点封禁了。可能你试了几百个,里面只有几个能用的,或者一个也不能用。可以动手编写一个自己的代理池,定时爬取免费代理站点,同时筛选出可用的代理 IP,供自己使用。付费代理稳定性会高很多,一般是按天或按量来收费,一些常见的付费代理站点:

6.2.6 Cookie 限制
有些站点需要登录后才能访问,浏览器在登录后,后续的请求都会带着这个 Cookie。我们可以在浏览器登录后,抓包找到请求里的 Cookie 字段,然后在编写爬虫时加上 Cookie就可以规避这个问题了。但是如果访问过于频繁,超过一定的阈值,也是会被服务器封禁的,不过一般过一段时间就会解封。要避免这种情况,要么控制访问速度,要么准备多个账号的 Cookie,保存到一个 Cookie 池中,每次请求随机取出一个 Cookie 来访问。
6.3 JavaScript 反爬虫策略
大部分反爬虫策略是通过 JavaScript 来实现的。站点开发者把重要的信息放在网页中,但是不写入 HTML 标签中,而浏览器会自动渲染<'script'>标签的 JavaScript 代码,然后将信息展示到浏览器中,由于爬虫不具备执行JavaScript 代码的能力,所以无法将JavaScript 产生的结果读取出来。
6.3.1 Ajax 动态加载数据
Ajax 是在不重新加载整个网页的情况下,对网页的某部分进行更新的技术。这在采用瀑布流布局或内容分页的站点中很常见,访问网页时将网页框架返回给浏览器,浏览器在交互过程中产生异步 Ajax 请求获取数据包,解析后呈现到网页上。
应对策略是抓包,比如 Chrome 浏览器会过滤 XHR(XML HTTP Request)的请求,这是浏览器后台与服务之间交换数据的文件,一般为 JSON 或 XML 格式,当然有些站点会对这个链接进行加密,如参数加密或返回加密。我们通过下面这个实例来了解 Ajax 动态加载数据,以及如何提取数据。
6.3.2 实战:爬取某素材网内容分析
(1)请求面板页面,解析页面,获取 key 并保存,返回图片列表最后一个 pin_id。
(2)循环模拟 Ajax 请求,直到返回的数据为空,同样获取 key 保存,每次请求返回最
后一个 pin_id。
(3)读取保存图片 key 的文件,遍历拼接图片 URL,把图片下载到本地。
import requests
import os
import json
# 图片完整链接
img_start_url = 'https://gd-hbimg.huaban.com/'
img_end_url = '_fw658webp'
# 初始链接
max_pin = '1907806155'
# 存储目录
SAVE_DIR = './HuaBan'
def get_info(new_pin,**kwargs):
"""获取图片的keys和下一个pin_id"""
API_URL = f'https://api.huaban.com/boards/47671358/pins?limit=40&max={new_pin}&fields=pins:PIN,board:BOARD_DETAIL,check'
response = requests.get(API_URL)
data_json = response.json()
pins = data_json['pins']
keys = [pin['file']['key'] for pin in pins]
next_pin = pins[-1]['pin_id'] if pins else None # 获取最后一个pin的ID作为下次请求的起点
return keys, next_pin
def download_pic(key):
url = img_start_url + key + img_end_url
resp = requests.get(url).content
save_pic(resp, key)
def save_pic(resp, key):
# 确保文件名中不包含系统不支持的字符
safe_key = key.replace('\\', '').replace('/', '').replace(':', '').replace('*', '').replace('?', '').replace('"', '').replace('<', '').replace('>', '').replace('|', '')
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
file_path = os.path.join(SAVE_DIR, f'{safe_key}.jpg')
with open(file_path, 'wb') as f:
f.write(resp)
print(f"图片{safe_key}下载成功")
if __name__ == "__main__":
new_pin = max_pin
while new_pin:
keys, new_pin = get_info(new_pin) # 更新keys和new_pin
for key in keys:
download_pic(key)
打开 HuaBan 文件夹可以看到所有图片都已经下载到本地。

6.4 Selenium 模拟浏览器操作
对于 Ajax 动态加载数据这种反爬虫策略,我们可以通过抓包分析 Ajax
接口规律,然后模拟请求来获取数据。但并不是所有接口都那么简单,大部分 Ajax 请求的参数都是会加密的,可能你花了很多时间也破解不了。还有些站点是通过 JS 生成页面的,如果用 Chrome 抓包时发现 Elements 里的代码和 Network 里抓到的页面内容不一致,说明这个网页很可能是通过 JS 动态生成的。
对于这种反爬虫策略,我们可以通过一些模拟浏览器运行的库来应对,浏览器中显示什么内容,爬取的就是什么内容。常用的库有 Selenium 和 Splash。
6.4.1 Selenium 简介
Selenium 是一个用于 Web 应用程序测试的工具,通过它我们可以编写代码,让浏览器完成如下任务:
- 自动加载网页,获取当前呈现页面的源码。
- 模拟单击和其他交互方式,最常用的是模拟表单提交(如模拟登录)。
- 页面截屏。
- 判断网页某些动作是否发生等。
Selenium 是不支持浏览器功能的,需要和第三方的浏览器一起搭配使用,支持下述浏览器,需要把对应的浏览器驱动下载到 Python 的对应路径下。 - Chrome:https://sites.google.com/a/chromium.org/chromedriver/home
- Firefox:https://github.com/mozilla/geckodriver/releases
- PhantomJS:http://phantomjs.org/
- IE:http://selenium-release.storage.googleapis.com/index.html
- Edge:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
- Opera:https://github.com/operasoftware/operachromiumdriver/releases
6.4.2 安装 Selenium
直接利用 pip 命令进行安装,命令如下:
pip install selenium
接着下载浏览器驱动,使用的是 Chrome 浏览器,以此为例,其他浏览器可自行搜索相关文档。打开 Chrome 浏览器输入:
chrome://version
即可查看 Chrome 浏览器版本的相关信息,主要是关注版本号
Google Chrome 69.0.3486.0 (正式版本) (32 位)
修订版本
472d1caeb99d99a8952e7170bbf435bd92902d73-refs/branch-heads/3486@{#1}
操作系统 Windows
JavaScript V8 6.9.323
Flash 30.0.0.154 C:\Users\CoderPig\AppData\Local\Google\Chrome\User
Data\PepperFlash\30.0.0.154\pepflashplayer.dll
用户代理 Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like
Gecko) Chrome/69.0.3486.0 Safari/537.36
...
Selenium安装WebDriver最新Chrome驱动
114版本以前可以通过下面的下载地址进行下载
https://chromedriver.storage.googleapis.com/index.html
114版本以后可以通过下面的下载地址进行下载
https://googlechromelabs.github.io/chrome-for-testing/
下载完成后,把压缩文件解压,把解压后的 chromedriver.exe 复制到 Python 的 Scripts目录下,在 64 位的浏览器上也是可以正常使用的。Mac 系统需要把解压后的文件复制到usr/local/bin 目录下,Ubuntu 系统需要复制到 usr/bin 目录下。
下面编写一个简单的代码来进行测试:
from selenium import webdriver
browser = webdriver.Chrome() # 调用本地的Chrome浏览器
browser.get('http://www.baidu.com') # 请求页面,会打开一个浏览器窗口
html_text = browser.page_source # 获得页面代码
browser.quit() # 关闭浏览器
print(html_text)
执行这段代码后,会自动调用 Chrome 浏览器并访问百度,可以看到浏览器顶部有如图的提示。
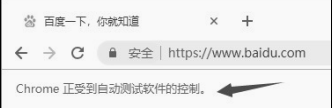
并且控制台会输出 HTML 代码,和 Chrome 的 Elements 页面结构完全一致。
6.4.3 Selenium 常用函数
Selenium 作为自动化测试的工具,提供了很多自动化操作的函数,下面介绍几个常用
函数,更多内容可以访问官方 API 文档来学习:https://www.selenium.dev/selenium/docs/api/py/index.html
- 定位元素
- find_element_by_class_name:根据 class 定位。
- find_element_by_css_selector:根据 css 定位。
- find_element_by_id:根据 id 定位。
- find_element_by_link_text:根据链接的文本来定位。
- find_element_by_name:根据节点名定位。
- find_element_by_partial_link_text:根据链接的文本来定位,只要包含在整个文本
- 中即可。
- find_element_by_tag_name:通过 tag 定位。
- find_element_by_xpath:使用 xpath 进行定位。
另外,如果把 element 改为 elements 会定位所有符合条件的元素,返回一个 List。比如find_elements_by_class_name,Selenium 定位到节点位置会返回一个 WebElement 类型的对
象,可以调用下述方法来提取需要的信息。 - 获取属性:element.get_attribute()。
- 获取文本:element.text。
- 获取标签名称:element.tag_name。
- 获取节点 id:element.id。
- 鼠标动作
有时需要在页面上模拟鼠标操作,比如单击、双击、右键单击、按住、拖曳等,可以导入 ActionChains 类selenium.webdriver.common.action_chains.ActionChains,使用 Action Chains(driver).函数名的形式调用对应节点的行为。
- click(element):单击某个节点。
- click_and_hold(element):单击某个节点并按住不放。
- context_click(element):右键单击某个节点。
- double_click(element):双击某个节点。
- drag_and_drop(source,target):按住某个节点拖曳到另一个节点。
- drag_and_drop_by_offset(source, xoffset, yoffset):按住节点,沿着 x 轴和 y 轴方向
- 拖曳特定距离。
- key_down:按下特殊键,只能用 Ctrl、Alt 或 Shift 键,比如 Ctrl+C。
- key_up:释放特殊键。
- move_by_offset(xoffset, yoffset):按偏移移动鼠标。
- move_to_element(element):鼠标移动到某个节点的位置。
- move_to_element_with_offset(element, xoffset, yoffset):鼠标移到某个节点并偏移。
- pause(second):在一个时间段内暂停所有的输入,单位秒。
- perform():执行操作,可以设置多个操作,调用 perform()才会执行。
- release():释放鼠标按键。
- reset_actions():重置操作。
- send_keys(keys_to_send):模拟按键。
- send_keys_to_element(element, *keys_to_send):和 send_keys 类似。
- 弹窗
对应类为selenium.webdriver.common.alert.Alert,使用得不多,如果触发了某个事件,弹出了对话框,可以通过调用这个方法获得对话框:alert = driver.switch_to_alert(),alert 对象可以调用下述方法。
- accept():确定。
- dismiss():关闭对话框。
- send_keys():传入值。
- text():获得对话框文本。
- 页面前进、后退、切换
# 切换窗口
driver.switch_to.window("窗口名")
# 或通过window_handles来遍历
for handle in driver.window_handles:
driver.switch_to_window(handle)
driver.forward() # 前进
driver.back() # 后退
- 页面截图
代码示例如下:
driver.save_screenshot("截图.png")
- 页面等待
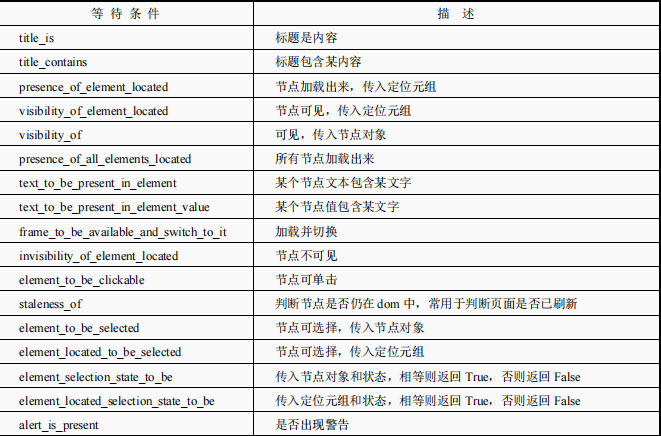
现在越来越多的网页采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。如果实际页面等待的时间过长,会导致某个 dom 元素还没加载出来,但是代码直接使用了这个WebElement,那么就会抛出 NullPointer 异常。为了避免这种元素定位困难,Selenium 提供了两种等待方式:一种是显式等待,另一种是隐式等待。
显式等待:指定某个条件,然后设置最长等待时间。如果在这个时间内还没有找到元素,便会抛出异常,代码示例如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverWait 库,负责循环等待
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions 类,负责条件出发
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
driver.get("http://www.xxxxx.com/loading")
try:
# 每隔10s查找页面元素 id="myDynamicElement",直到出现才返回
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
如果不写参数,程序会默认每隔 0.5s 调用一次来查看元素是否已经生成,如果本来元素就是存在的,那么会立即返回。
隐式等待就是简单地设置一个等待时间,单位为秒。代码示例如下:
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.implicitly_wait(10) # seconds
driver.get("http://www.xxxxx.com/loading")
myDynamicElement = driver.find_element_by_id("myDynamicElement")
如果不设置,默认等待时间为 0。
7. 执行 JS 语句
driver.execute_script(js语句)
比如,滚动到底部的代码示例如下:
js = document.body.scrollTop=10000
driver.execute_script(js)
- Cookies
有些站点需要登录后才能访问,用 Selenium 模拟登录后获取 Cookies,然后供爬虫使用的场景很常见,Selenium 提供了获取、增加、删除 Cookies 的函数,代码示例如下:
# 获取Cookies
browser.get_cookies()
# 增加Cookies
browers.add_cookie({xxx})
# 删除Cookies
browser.delete_cookie()
6.5 实战:模拟登录某网站
该网站的链接为https://user.17k.com/www/bookshelf/
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://user.17k.com/www/bookshelf/")
time.sleep(2)
#获取登陆模块的iframe
el_path = driver.find_element_by_xpath('/html/body/div[4]/div/div/iframe')
#进去该iframe
driver.switch_to.frame(el_path)
#进入成功后,输入账号密码以及勾选同意并点击登陆
driver.find_element_by_xpath('//dd[@class="user"]/input').send_keys('你的账号')
driver.find_element_by_xpath('//dd[@class="pass"]/input').send_keys('你的密码')
#勾选同意
driver.find_element_by_xpath('//*[@id="protocol"]').click()
#点击登陆
driver.find_element_by_xpath('//dd[@class="button"]/input').click()
# 关闭浏览器
#driver.quit()
6.6 PhantomJS
PhantomJS 是没有界面的浏览器,特点是会把网站加载到内存并执行页面上的 JavaScript,
因为不会展示图形界面,所以运行起来比完整的浏览器要高效。在一些 Linux 的主机上没有图形化界面,不能使用有界面的浏览器,可以通过PhantomJS 来解决这个问题。
6.7 常见验证码策略
验证码可谓是站点开发者的最爱,生成技术门槛低,集成第三方技术就可以了。但验证码的类型五花八门,对于爬虫开发者来说简直是噩梦。从最开始的数学算式求结果,到普通的图片验证码,之后图片验证码又复杂化,并出现了逻辑判断计算、字符粘连变形、前置噪声多色干扰、多语种字符混搭等验证码。后来又出现了滑动验证码,并且不断复杂化,如需要把缺失的图片滑动到缺失位置(Bilibili)。此外,还有回答问题验证(虎扑)、选择点触图片验证(12306)、高数题目、化学表达式填写等。
6.7.1 图片验证码
对于简单的数字图片验证码,最简单的应对方法就是对验证码图片做灰度和二值化处理,然后用 OCR 库识别图片里的文字,高级一点的方法可以利用深度学习训练一个识别验证码图片的模型。
tesseract-ocr 库是谷歌提供的免费的 ORC 文字识别引擎,仓库地址为https://github.com/tesseract-ocr/tesseract ,稳定版本是 3.0,最新的 4.0 版本还处于研发阶段,对中文的识别率比较低。
安装 tesserocr。
直接通过 pip 命令安装:
pip install -i tesserocr
安装 pillow 库。
pillow 库是一个图片处理模块,可以通过 pip 命令直接安装:
pip install pillow
爬虫要做的就是使用 Selenium 模拟登录,然后来到这个页面输入账号和密码,获取验证码图片进行识别,识别完成后填充验证码,单击“登录”按钮。
6.7.2 实战:实现图片验证码自动登录
具体案例:https://www.cnblogs.com/Z-Queen/p/10683793.html
6.7.3 实战:实现滑动验证码自动登录
滑动验证码,只需要把滑块移动到缺失位置即可,一般的流程如下:
(1)移动到滑块节点上,弹出没缺口的图片,获取并保存该图片。
(2)单击滑动按钮,弹出带缺口的图片,获取并保存该图片。
(3)对比两张图片所有的 RBG 像素点,得到不一样的像素点的 x 值,这个 x 值就是滑块大概的滑动距离。
(4)模拟人滑动的习惯(匀加速后匀减速),把滑动总距离分成多个小段轨迹。
(5)按轨迹滑动,完成验证后登录。
具体案例:https://blog.csdn.net/acmman/article/details/133827764
使用此类脚本下载网站内容时应遵守网站的使用条款,以及相关的法律法规。
本系列文章皆做为学习使用,勿商用。
第 6章 Python 应对反爬虫策略的更多相关文章
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
- scrapy反反爬虫策略和settings配置解析
反反爬虫相关机制 Some websites implement certain measures to prevent bots from crawling them, with varying d ...
- 第7章 Scrapy突破反爬虫的限制
7-1 爬虫和反爬的对抗过程以及策略 Ⅰ.爬虫和反爬虫基本概念 爬虫:自动获取网站数据的程序,关键是批量的获取. 反爬虫:使用技术手段防止爬虫程序的方法. 误伤:反爬虫技术将普通用户识别为爬虫,如果误 ...
- Python Scrapy反爬虫常见解决方案(包含5种方法)
爬虫的本质就是“抓取”第二方网站中有价值的数据,因此,每个网站都会或多或少地采用一些反爬虫技术来防范爬虫.比如前面介绍的通过 User-Agent 请求头验证是否为浏览器.使用 JavaScript ...
- python 反爬虫策略
1.限制IP地址单位时间的访问次数 : 分析:没有哪个常人一秒钟内能访问相同网站5次,除非是程序访问,而有这种喜好的,就剩下搜索引擎爬虫和讨厌的采集器了. 弊端:一刀切,这同样会阻止搜索引擎对网站的收 ...
- 前端反爬虫策略--font-face 猫眼数据爬取
1 .font-face定义了字符集,通过unicode去印射展示. 2 .font-face加载网络字体,我么可以自己创建一套字体,然后自定义一套字符映射关系表例如设置0xefab是映射字符1, ...
- Python爬虫与反爬虫(7)
[Python基础知识]Python爬虫与反爬虫(7) 很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧 这节我会做个基本分享. 从功能上来讲,爬虫一般分为数据采集,处理, ...
- 深入细枝末节,Python的字体反爬虫到底怎么一回事
内容选自 即将出版 的<Python3 反爬虫原理与绕过实战>,本次公开书稿范围为第 6 章——文本混淆反爬虫.本篇为第 6 章中的第 4 小节,其余小节将 逐步放送 . 字体反爬虫开篇概 ...
- [Python]新手写爬虫全过程(转)
今天早上起来,第一件事情就是理一理今天该做的事情,瞬间get到任务,写一个只用python字符串内建函数的爬虫,定义为v1.0,开发中的版本号定义为v0.x.数据存放?这个是一个练手的玩具,就写在tx ...
- Python3 网络爬虫:漫画下载,动态加载、反爬虫这都不叫事
一.前言 作者:Jack Cui 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那 ...
随机推荐
- pod的拉取和重启策略
在Kubernetes中,Pod的拉取策略和重启策略可以通过YAML配置文件来定义. Pod的拉取策略 Pod的拉取策略指的是Kubernetes在创建或重启Pod时,如何获取Pod所需的容器镜像.这 ...
- gulp-imagemin版本9图片压缩
由于网上大多数的博文已经比较久,参考性不大 版本 gulp PS D:\XXX\github\hexo> gulp -v CLI version: 2.3.0 Local version: 4. ...
- Performance Improvements in .NET 8 -- Native AOT & VM & GC & Mono【翻译】
原生 AOT 原生 AOT 在 .NET 7 中发布.它使 .NET 程序在构建时被编译成一个完全由原生代码组成的自包含可执行文件或库:在执行时不需要 JIT 来编译任何东西,实际上,编译的程序中没有 ...
- Windows下写脚本无法运行在linux上?怎麽办?
Windows下写脚本无法运行在linux上?怎麽办? $'\r': command not found的解决方法 在Linux系统中,运行Shell脚本,出现了如下错误: one-more.sh: ...
- 基于C#的自动校时器 - 开源研究系列文章
上次在公司的Windows7电脑上操作系统没有自动进行校时,导致系统时间老是快那么几分钟,于是想到了用C#开发一个系统时间自动校时器.这个应用不难,主要是能够校时那个操作类的问题. 1. 项目目录: ...
- Activity、Window、View三者关系
目录介绍 01.Window,View,子Window 02.什么是Activity 03.什么是Window 04.什么是DecorView 05.什么是View 06.关系结构图 07.Windo ...
- 记录转载:Vite多环境配置--让项目拥有更高定制化能力
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 业务背景 近些年来,随着前端工程架构发展,使得前端项目中也能拥有如后端工程的模块能力.正所谓 "能力(越)越大(来),责任(越) ...
- 深入在线文档系统的 MarkDown/Word/PDF 导出能力设计
深入在线文档系统的 MarkDown/Word/PDF 导出能力设计 当我们实现在线文档的系统时,通常需要考虑到文档的导出能力,特别是对于私有化部署的复杂ToB产品来说,文档的私有化版本交付能力就显得 ...
- C# 人脸检测 人脸比对 活体检测 口罩检测 年龄预测 性别预测 眼睛状态检测
基于以下开源软件做了一个Demo GitHub - ViewFaceCore/ViewFaceCore: C# 超简单的离线人脸识别库.( 基于 SeetaFace6 ) 效果 代码 using Sy ...
- MySQL备份还原工具
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...