SparkStreaming动态读取配置文件
SparkStreaming动态读取配置文件
标签: SparkStreaming HDFS 配置文件 MySql
需求
- 要实现SparkStreaming在流处理过程中能动态的获取到配置文件的改变
- 并且能在不重启应用的情况下更新配置
- 配置文件大概一个月改动一次,所以不能太耗性能
为什么需要动态读取配置文件?
在之前的项目中一直使用的读配置文件的模式是在应用启动阶段一次性读取配置文件并获取到其中的全部配置内容。并且,在程序运行过程中这些配置不能被改变,如果需要改变,则需要重新打包发布应用。
在代码测试阶段这种方式会很麻烦也很费时,所以需要一种能让应用动态更新配置的方法。
Spark程序的运行过程
1、Spark运行的基本流程
- 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
- 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
- SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
- Task在Executor上运行,运行完毕释放所有资源。
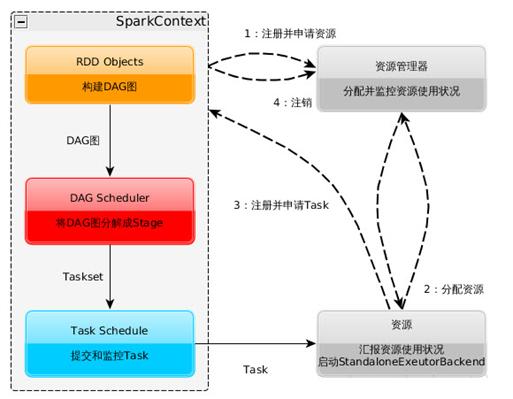
2、一个Spark程序的执行过程
一个用户编写的提交给Spark集群执行的application包含两个部分:
- 驱动: Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、计算任务分发到各个计算节点(Worker)、计算资源的分配等。
- 计算逻辑:当计算任务在Worker执行时,执行计算逻辑完成application的计算任务。
那么哪些作为"驱动代码"在Driver进程中执行,哪些"任务逻辑代码”被包装到任务中,然后分发到计算节点进行计算?
- Spark application首先在Driver上开始运行main函数。执行过程中,计算逻辑的开始是从读取数据源(比如HDFS中的文件)创建RDD开始,RDD分为transform和action两种操作,transform使用的是懒执行,而action操作将会触发Job的提交。
- Application在Driver上执行,遇到RDD的action动作后,开始提交作业,当作业执行完成后,后面的作业陆续提交。
- action操作会进行回溯,把懒执行的操作一起打包发送到各个计算节点。简单来说,发送到计算节点的对RDD的操作就是计算逻辑,其余的都在Driver中执行。
思考
了解了Spark的执行流程之后,不难发现,尽管Spark的开发者很努力的让Spark编程模式尽可能的靠近普通的顺序执行的编程模式。但是作为一个分布式执行过程,还是跟普通编程模式有很大区别,不注意的话很容易踩到坑。
我也想过了许多解决方案,但是大部分都卡在了这个分布式的坑上边。
比如:
- 一开始我考虑过是不是把读取配置文件的代码写到SparkContext初始化的代码之后,并以文件流的形式读取配置文件想要实现让Streaming每个批次都读。了解了上面的运行过程之后就会发现这是行不通的。
- 之后又思考能否利用检查点机制在程序从检查点读取数据时加载配置文件。但是有一个问题,程序发生改变之后检查点的数据会被丢弃。
- 然后又调研了市面上存在且常用的几个第三方配置管理平台,比如百度disconf,奇虎qconf,淘宝Diamond。调查结果则是现有的这些配置管理平台都是针对web项目做配置管理,不能很好的支持大数据的这种分布式架构。
在这些方向都走不通之后,我又重新回到Spark本身的执行流程上思考。Spark的action操作会发布到各个计算节点进行执行,如果把读取配置文件的操作写在action操作里带到各个节点进行执行,应该可以实现让每个节点都读取到配置文件,且可以实时改变。测试的结果也证明了这种方式是可行的。
详细设计
有了思路接下来就是代码测试。上面的三种失败方案也都进行了代码测试证明是不可行的。
首先是从HDFS中读取配置文件,在这里我写了个工具类:
object HDFSUtil {
val conf: Configuration = new Configuration
var fs: FileSystem = null
var hdfsInStream: FSDataInputStream = null
val prop = new Properties()
//获取文件输入流
def getFSDataInputStream(path: String): FSDataInputStream = {
try {
fs = FileSystem.get(URI.create(path), conf)
hdfsInStream = fs.open(new Path(path))
} catch {
case e: IOException => {
e.printStackTrace
}
}
return hdfsInStream
}
//读取配置文件
def getProperties(path:String,key:String): String = {
prop.load(this.getFSDataInputStream(path))
prop.getProperty(key)
}
然后是SparkStreaming初始化以及处理TCP流数据:
val conf = new SparkConf().setAppName("write data to mysql")
val ssc = new StreamingContext(conf,Seconds(10))
val streamData = ssc.socketTextStream("T002",9999)
val wordCount = streamData.map(line =>(line.split(",")(0),1)).reduceByKey(_+_)
val hottestWord = wordCount.transform(itemRDD => {
val top3 = itemRDD.map(pair => (pair._2, pair._1))
.sortByKey(false).map(pair => (pair._2, pair._1)).take(3)
ssc.sparkContext.makeRDD(top3)
})
hottestWord.foreachRDD( rdd =>{
rdd.foreachPartition(partitionOfRecords =>{
val path = "hdfs:///home/wuyue/property/test.properties"
val MD5Value = HDFSUtil.getHdfsFileMd5(path)
val sql=HDFSUtil.getProperties(path,"sql")
HDFSUtil.close
测试读取的数据是一条sql语句,如果能读取到就可以把数据正确的存入MySql中,如果读取不到配置,程序就会报错。连接数据库的代码如下:
val connect = scalaConnectPool.getConnection
connect.setAutoCommit(false)
val ps = connect.prepareStatement(sql)
partitionOfRecords.foreach(record =>{
val word = record._1
val count = record._2
ps.setString(1,word)
ps.setInt(2,count)
ps.addBatch()
})
ps.executeBatch()
connect.commit()
scalaConnectPool.closeConnection(ps,connect)
我写了一个数据库连接池方便进行数据库连接,因为获取数据库的连接并不是很耗性能,sql语句的执行最耗性能,所以出于性能角度考虑,存入MySql的操作我使用的是批处理模式。
经过测试,数据能够正确的存入数据库中,并且手动更改配置文件之后程序出错停止,说明程序能够读到配置文件中的变化并进行更新。
设计的不足之处
因为Spark读取数据的操作是分布在各个计算节点执行的,如果使用传统的文件资源管理器就必须在每个节点机器的目录下都存放一份配置文件,并且在改动时要同时进行,这是很不方便的。所以在测试中使用HDFS(分布式文件系统)存储配置文件。
但是HDFS主要用来做大数据量批量读写操作的,对单个文件的随机读写会很慢。
所以我在要读取配置文件之前增加了一个对文件是否改动进行的判断,如果配置文件发生变化则重新读取文件,如果没有变化则不读取。
具体实现方式为获取文件的MD5值,如果MD5值发生变化说明文件有改动,如果不变说明文件没有改动。
但即使是这样,在HDFS上进行随机读写依然很耗性能。因为是测试阶段,主要为了证明这种方式是可行的,在进一步的测试中可以考虑使用MySql或者Redis替换掉HDFS来存储配置文件。
SparkStreaming动态读取配置文件的更多相关文章
- 利用java反射机制 读取配置文件 实现动态类载入以及动态类型转换
作者:54dabang 在spring的学习过程之中,我们能够看出通过配置文件来动态管理bean对象的优点(松耦合 能够让零散部分组成一个总体,而这些总体并不在意之间彼此的细节,从而达到了真正的物理上 ...
- ResourceBundle与Properties读取配置文件
ResourceBundle与Properties的区别在于ResourceBundle通常是用于国际化的属性配置文件读取,Properties则是一般的属性配置文件读取. ResourceBundl ...
- python中读取配置文件的方式
方式1:argparse argparse,是Python标准库中推荐使用的编写命令行程序的工具.也可以用于读取配置文件. 字典样式的配置文件*.conf 配置文件test1.conf { " ...
- Spring 读取配置文件(一)
注册 @Configuration 标识的类,spring 读取配置文件的时候该类会被自动装载 package cn.com.receive;import org.springframework.be ...
- electron-vue 项目启动动态获取配置文件中的后端服务地址
前言 最近的项目迭代中新增一个需求,需要在electron-vue 项目打包之后,启动exe 可执行程序的时候,动态获取配置文件中的 baseUrl 作为服务端的地址.electron 可以使用 no ...
- 自己动手之使用反射和泛型,动态读取XML创建类实例并赋值
前言: 最近小匹夫参与的游戏项目到了需要读取数据的阶段了,那么觉得自己业余时间也该实践下数据相关的内容.那么从哪入手呢?因为用的是Unity3d的游戏引擎,思来想去就选择了C#读取XML文件这个小功能 ...
- Unity3D移动平台动态读取外部文件全解析
前言: 一直有个想法,就是把工作中遇到的坑通过自己的深挖,总结成一套相同问题的解决方案供各位同行拍砖探讨.眼瞅着2015年第一个工作日就要来到了,小匹夫也休息的差不多了,寻思着也该写点东西活动活动大脑 ...
- 【无私分享:ASP.NET CORE 项目实战(第八章)】读取配置文件(二) 读取自定义配置文件
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 我们在 读取配置文件(一) appsettings.json 中介绍了,如何读取appsettings.json. 但随之产生 ...
- 解决IntelliJ IDEA无法读取配置文件的问题
解决IntelliJ IDEA无法读取配置文件的问题 最近在学Mybatis,按照视频的讲解在项目的某个包里建立配置文件,然后读取配置文件,但是一直提示异常. 读取配置文件的为官方代码: String ...
随机推荐
- ubuntu下MySQL修改root密码的多种方法,phpmyadmin空密码无法登陆的解决方法
phpmyadmin是默认不允许使用空密码的,所以若是在安装时没有设置密码,在登陆phpmyadmin时是个很头疼的问题 方法1是修改phpmyadmin的配置文件,这里不做推荐.. 方法2: php ...
- junit搭配hamcrest使用
开篇 - 快速进行软件编码,与功能测试应该是每个写代码的人,应该掌握的技能,如何进行优雅的写代码,把测试的时间压缩,腾出时间来休息.下面听我一一道来: 依赖:junit 4.4 hamcrest 1. ...
- 解析 .Net Core 注入 (2) 创建容器
在上一节的学习中,我们已经知道了通过 IServiceCollection 拓展方法创建 IServiceProvider 默认的是一个类型为 ServiceProvider 对象,并且实际提供创建对 ...
- Cosmos OpenSSD--greedy_ftl1.2.0(一)
从主函数跳到ReqHandler,在ReqHandler内先初始化SSD--InitNandReset,然后建立映射表InitFtlMapTable void InitNandReset() { // ...
- 【ASP.NET MVC 学习笔记】- 19 REST和RESTful Web API
本文参考:http://www.cnblogs.com/willick/p/3441432.html 1.目前使用Web服务的三种主流的方式是:远程过程调用(RPC),面向服务架构(SOA)以及表征性 ...
- 【ASP.NET MVC 学习笔记】- 01 理解MVC模式
本文参考:http://www.cnblogs.com/willick/p/3195560.html 1.MVC模式是软件系统的一种架构模式,它将软件分为三大模块: 模型(Model):封装业务逻辑以 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Latent Variables
下一章有意讲讲EM和变分推断的内容. EM和变分推断的内容能Google到很多,虽然质量乘次不齐,但本文也无意再赘述那么些个细节. 此处记录一些核心思想,帮助菜鸡形成整体上的认识.不过,变分推断也不是 ...
- Ionic3 组件懒加载
使用懒加载能够减少程序启动时间,减少打包后的体积,而且可以很方便的使用路由的功能. 使用懒加载: 右侧红色区域可以省略掉(引用.声明也删掉) 若使用ionic命令新建page,则无需进行下面的操作,否 ...
- runtime--小白看过来
目录 RunTime 概述 RunTime消息机制 RunTime交换方法 RunTime消息转发 RunTime关联对象 RunTime实现字典与模型互转 1.RunTime 概述 我们在面试的时候 ...
- 负载均衡集群企业级应用实战—LVS
一.负载均衡集群介绍 1.集群 ① 集群(cluster)技术是一种较新的技术,通过集群技术,可以在付出较低成本的情况下获得在性能.可靠性.灵活性方面的相对较高的收益,其任务调度则是集群系统中的核心技 ...