数据处理包dplyr的函数
dplyr专注处理dataframe对象, 并提供更稳健的与其它数据库对象间的接口。
一、5个关键的数据处理函数:
select() 返回列的子集
filter() 返回行的子集
arrange() 根据一个或多个变量对行排序。
mutate() 使用已有数据创建新的列
summarise() 对各个群组汇总计算并返回一维结果。
Tips:
1、select()
Dplyr包有下列辅助函数,用于在select()中选择变量:
starts_with("X"): 以 "X"开头的变量名
ends_with("X"): 以 "X"结束的变量名
contains("X"): 包含 "X"的变量名
matches("X"): 匹配正则表达式“x"的变量名
num_range("x", 1:5): 变量名为 x01, x02, x03, x04 and x05
one_of(x): 出现在字符向量x中的所有变量名
在select()中直接使用列时不需要引用"",但使用上述辅助函数时必须引用""。
2、filter()
R 有一系列逻辑表达式可用于filter()中:
x < y;x <= y;x == y;x != y;x >= y;x > y;x %in% c(a, b, c)
示例:
filter(df, a > 0, b > 0)
filter(df, !is.na(x))
3、arrange()
arrange()默认从小到大排序,在arrange()中使用desc()作用于变量可以使之从大到小排序.
4、mutate()
mutate()允许在同一次调用中使用新变量来创建下一个变量,例如:
mutate(my_df, x = a + b, y = x + c)
5、 summarise()
R的下列聚合函数可用于 summarise()中
- min(x) - 最小值.
- max(x) - 最大值
- mean(x) - 平均值
- median(x) - 中位数
- quantile(x, p) - x的第P个分位数
- sd(x) - 标准差
- var(x) - 方差
- IQR(x) - 四分位数
- diff(range(x)) - x值的范围
dplyr包自身提供了一些有用的聚合函数:
- first(x) - 向量x中的第1个元素
- last(x) - 向量x中的最后1个元素
- nth(x, n) - 向量x中的第n个元素
- n() - data.frame中的行数或 summarise() 描述的观测组的数量
- n_distinct(x) - 向量x中唯一值的数量
二、管道函数%>%
dplyr包中特有的管道函数%>%,将上一个函数的输出作为下一个函数的输入。
%>%运算符允许从参数列表中提取函数的第一个参数,并放置在%>%前面。
下面两条指令相等:
mean(c(1, 2, 3, NA), na.rm = TRUE)
c(1, 2, 3, NA) %>% mean(na.rm = TRUE)
三、分组函数group_by()
对数据集定义群组。然后可对各个群组分别进行汇总统计。
通过 group_by() 添加了分组信息后,mutate(), arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作。
group_by(dataframe,colnames1,colnames2,…)
四、连接数据(joins)
1、6种连接函数如下:
left_join(dataset1,dataset2)
right_join(dataset1,dataset2)
inner_join(dataset1,dataset2,by=c(“”))
full_join(dataset1,dataset2, by = c("first", "last"))
semi_join(dataset1,dataset2, by = c("first", "last"))
anti_join(dataset1,dataset2, by = c("first", "last"))
前4种属于变形连接(mutating joins),后2种属于过滤连接(filtering joins)。
semi-joins基于第二个数据集的信息来过滤第一个数据集的数据。anti-joins找出合并时哪些行不能匹配第二个数据集

2、key值
R语言的 data frames可在 row.names属性中存储重要信息,虽然不是存储数据的好方式却很常见。如果数据集的主关键字在row.names中,将难以与其他数据集连接。一种解决方法是使用tibble包(tibble:a data frame with class tbl_df)中的rownames_to_column()函数,返回该数据集的副本,并且行名作为一列增加到该数据中。
library(tibble)
rownames_to_column(data, var="name")
如果两个数据集有相同的列名,但代表的事物不同,并且by参数不包含这些重复的列名,dplyr会忽略这些列名,并对相同的列名增加.x和 .y来帮助区分列。
当两个数据集中相同的事物有不同的列名,要完成合并,将by设置为一个命名向量。向量的名字为主数据集中的列名,向量的值为第二个数据集中的列名。例如:
x %>% left_join(y, by = c("x.name" = "y.name"))
完成连接后保留主数据集中的列名。
3、多个数据集的连接
Purrr包中的 reduce()函数对多个数据集重复应用某函数,可用于连接多个数据集,与dplyr的join类函数配合使用,例如:
library(purrr)
list(data1,data2,data3) %>% reduce(left_join,by = c("first", "last"))
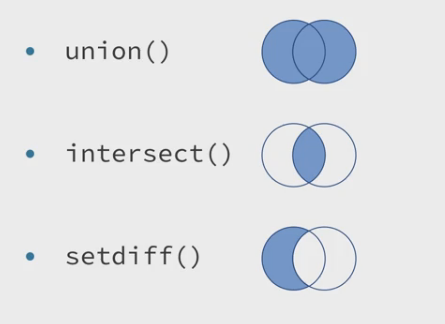
五、集合操作(set operations)
dplyr提供了intersection、union和setdiff用于获得数据集的交集、并集和差集。
六、组装数据assembling data
使用如下函数:
bind_rows()
bind_cols() :将多个data frame合成单个data frame
data_frame() : 将一系列列向量组合成data frame
as_data_frame() :将list转换成data frame
数据处理包dplyr的函数的更多相关文章
- R语言中的数据处理包dplyr、tidyr笔记
R语言中的数据处理包dplyr.tidyr笔记 dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了 ...
- R语言数据处理包dplyr、tidyr笔记
dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了与其它数据库的接口:tidyr包的作者是Hadley ...
- R(6): 数据处理包dplyr
dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了与其它数据库的接口,本节学习dplyr包函数基本用法 ...
- 数据处理包plyr和dplyr包的整理
以下内容主要参照 Introducing dplyr 和 dplyr 包自带的简介 (Introduction to dplyr), 复制了原文对应代码, 并夹杂了个人理解和观点 (多附于括号内). ...
- R语言数据处理利器——dplyr简介
dplyr是由Hadley Wickham主持开发和维护的一个主要针对数据框快速计算.整合的函数包,同时提供一些常用函数的高速写法以及几个开源数据库的连接.此包是plyr包的深化功能包,其名字中的字母 ...
- R︱并行计算以及提高运算效率的方式(parallel包、clusterExport函数、SupR包简介)
要学的东西太多,无笔记不能学~~ 欢迎关注公众号,一起分享学习笔记,记录每一颗"贝壳"~ --------------------------- 终于开始攻克并行这一块了,有点小兴 ...
- R语言扩展包dplyr——数据清洗和整理
R语言扩展包dplyr——数据清洗和整理 标签: 数据R语言数据清洗数据整理 2015-01-22 18:04 7357人阅读 评论(0) 收藏 举报 分类: R Programming(11) ...
- R语言扩展包dplyr笔记
引言 2014年刚到, 就在 Feedly 订阅里看到 RStudio Blog 介绍 dplyr 包已发布 (Introducing dplyr), 此包将原本 plyr 包中的 ddply() 等 ...
- tidyr包--数据处理包
tidyr包的作者是Hadley Wickham.这个包常跟dplyr结合使用.本文将介绍tidyr包中下述四个函数的用法: gather—宽数据转为长数据.类似于reshape2包中的melt函数 ...
随机推荐
- jquery通过ajax向后台发送(checkbox)数组,并在后台接收,(发送的数据是checkedbox)
版权声明:本文为博主原创文章,未经博主允许不得转载. $(document).ready(function(){ var flag = 1; $("#delBtn").click( ...
- Lucene5.5.4入门以及基于Lucene实现博客搜索功能
前言 一直以来个人博客的搜索功能很蹩脚,只是自己简单用数据库的like %keyword%来实现的,所以导致经常搜不到想要找的内容,而且高亮显示.摘要截取等也不好实现,所以决定采用Lucene改写博客 ...
- Docker- 创建支持SSH服务的容器镜像
示例 - CentOS7 [root@CentOS-7 ~]# cat ssh-centos7 FROM centos:centos7 MAINTAINER anliven "anliven ...
- hdu4764 Stone 博弈
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=4764 很水的博弈题目 代码: #pragma comment(linker, "/STAC ...
- String深度解析
文章出处:http://my.oschina.net/xiaohui249/blog/170013 一.引题 String类型是比较特殊的一种类型,同时也是面试经常被问到的一个知识点,本文结合java ...
- Java7中的ForkJoin并发框架初探(下)—— ForkJoin的应用
前两篇文章已经对Fork Join的设计和JDK中源码的简要分析.这篇文章,我们来简单地看看我们在开发中怎么对JDK提供的工具类进行应用,以提高我们的需求处理效率. Fork Join这东西确实用好了 ...
- Java学习笔记——Linux下安装配置MySQL
山重水复疑无路,柳暗花明又一村 --游山西村 系统:Ubuntu 16.04LTS 1\官网下载mysql-5.7.18-linux-glibc2.5-x86_64.tar.gz2\建立工作组:$su ...
- Bash Excercises
1. cat <<EOF #!/bin/bash function printHelp { cat<<EOF Run the Dash vector tests. Usage: ...
- 解决selenium驱动Firefox跳转页慢慢慢的问题
首先我给自己定义为是一个更新偏执狂.不知道从哪个版本开始,使用selenium驱动打开Firefox浏览器时,会跳转到官网指定页,这个过程真是慢得要死. 为了解决这个问题,我是查了很多资料,解决方案是 ...
- 【Netty】Netty之ByteBuf
一.前言 前面已经学习了Netty中传输部分,现在接着学习Netty中的ByteBuf. 二.ByteBuf 2.1 ByteBuf API 在网络上传输的数据形式为Byte,Java NIO提供了B ...