Python 并发编程(一)之线程
常用用法
t.is_alive()
Python中线程会在一个单独的系统级别线程中执行(比如一个POSIX线程或者一个Windows线程)
这些线程将由操作系统来全权管理。线程一旦启动,将独立执行直到目标函数返回。可以通过查询
一个线程对象的状态,看它是否还在执行t.is_alive()
t.join()
可以把一个线程加入到当前线程,并等待它终止
Python 解释器在所有线程都终止后才继续执行代码剩余的部分
daemon
对于需要长时间运行的线程或者需要一直运行的后台任务,可以用后台线程(也称为守护线程)
例:
t = Thread(target = func, args(1,), daemon = True)
t.start()
后台线程无法等待,这些线程会在主线程终止时自动销毁
小结:
后台线程无法等待,不过,这些线程会在主线程终止时自动销毁。你无法结束一个线程,无法给它发送信
号,无法调整它的调度,也无法执行其他高级操作。如果需要这些特性,你需要自己添加。比如说,
如果你需要终止线程,那么这个线程必须通过编程在某个特定点轮询来退出
如果线程执行一些像 I/O 这样的阻塞操作,那么通过轮询来终止线程将使得线程之间的协调变得非常棘手。
比如,如果一个线程一直阻塞在一个 I/O 操作上,它就永远无法返回,也就无法检查自己是否已经被结束了。
要正确处理这些问题,需要利用超时循环来小心操作线程。
线程间通信
queue
一个线程向另外一个线程发送数据最安全的方式应该就是queue库中的队列
先看一下使用例子,这里是一个简单的生产者和消费者模型:
from queue import Queue
from threading import Thread
import random
import time _sentinel = object() def producer(out_q):
n = 10
while n:
time.sleep(1)
data = random.randint(0, 10)
out_q.put(data)
print("生产者生产了数据{0}".format(data))
n -= 1
out_q.put(_sentinel) def consumer(in_q):
while True:
data = in_q.get()
print("消费者消费了{0}".format(data))
if data is _sentinel:
in_q.put(_sentinel)
break q = Queue()
t1 = Thread(target=consumer, args=(q,))
t2 = Thread(target=producer, args=(q,)) t1.start()
t2.start()
上述代码中设置了一个特殊值_sentinel用于当获取到这个值的时候终止执行
关于queue的功能有个需要注意的地方:
Queue对象虽然已经包含了必要的锁,主要有q.put和q.get
而q.size(),q.full(),q.empty()等方法不是线程安全的
使用队列进行线程通信是一个单向、不确定的过程。通常情况下,是没有办法知道接收数据的线程是什么时候接收到的数据并开始工作的。但是队列提供了一些基本的特性:q.task_done()和q.join()
如果一个线程需要在另外一个线程处理完特定的数据任务后立即得到通知,可以把要发送的数据和一个Event放到一起使用
关于线程中的Event
线程有一个非常关键的特性:每个线程都是独立运行的,且状态不可预测
如果程序中的其他线程需要通过判断每个线程的状态来确定自己下一步的操作,这时线程同步问题就会比较麻烦。
解决方法:
使用threading库中的Event
Event对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。
在初始化状态下,event对象中的信号标志被设置为假。
如果有线程等待一个event对象,而这个event的标志为假,这个线程将一直被阻塞知道该标志为真。
一个线程如果把event对象的标志设置为真,就会唤醒所有等待这个event对象的线程。
通过一个代码例子理解:
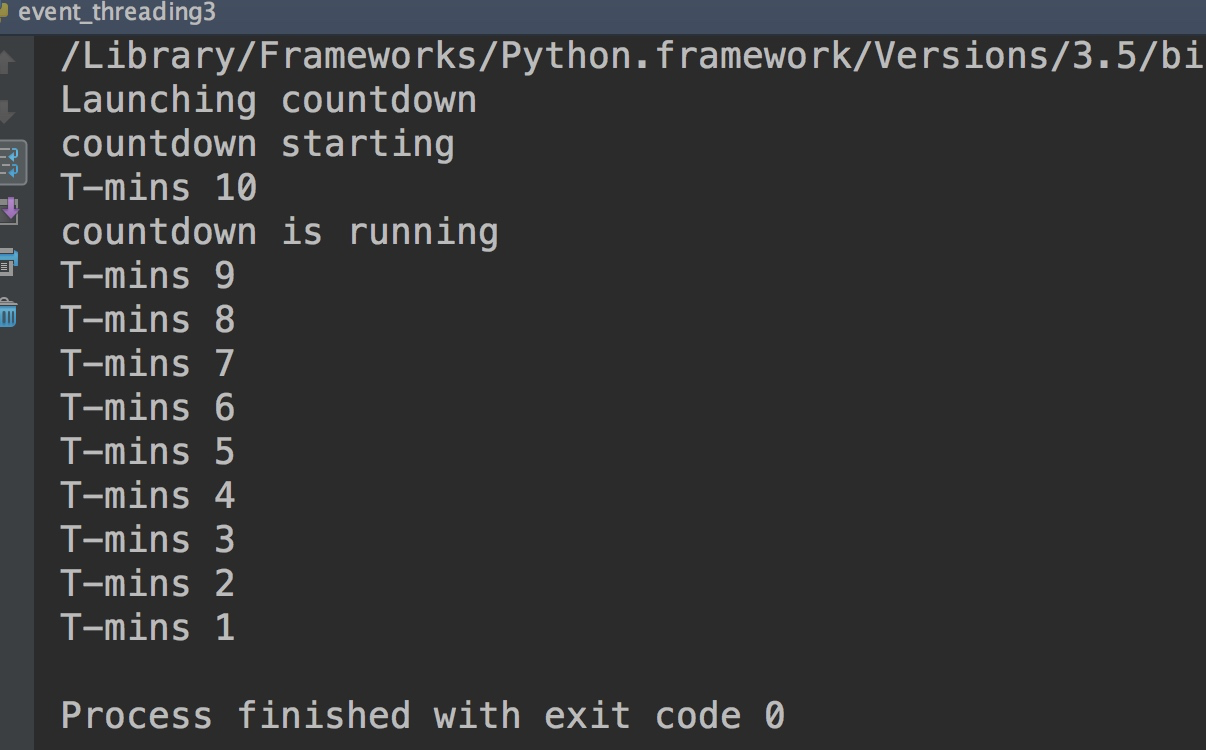
from threading import Thread, Event
import time def countdown(n, started_evt):
print("countdown starting")
# set将event的标识设置为True
started_evt.set()
while n > 0:
print("T-mins", n)
n -= 1
time.sleep(2) # 初始化的started_evt为False
started_evt = Event()
print("Launching countdown")
t = Thread(target=countdown, args=(10, started_evt,))
t.start()
# 会一直等待直到event的标志为True的时候
started_evt.wait()
print("countdown is running")
而结果,我们也可以看出当线程执行了set之后,才打印running
实际用event对象最好是单次使用,创建一个event对象,让某个线程等待这个对象,一旦对象被设置为Tru,就应该丢弃它,我们虽然可以通过clear()方法重置event对象,但是这个没法确保安全的清理event对象并对它进行重新的赋值。会发生错过事件,死锁等各种问题。
event对象的一个重要特点是它被设置为True时会唤醒所有等待它的线程,如果唤醒单个线程的最好用Condition或信号量Semaphore
和event功能类似的线程中还有一个Condition
关于线程中的Condition
关于Condition官网的一段话:
A condition variable is always associated with some kind of lock; this can be passed in or one will be created by default. Passing one in is useful when several condition variables must share the same lock. The lock is part of the condition object: you don’t have to track it separately.
Other methods must be called with the associated lock held. The wait() method releases the lock, and then blocks until another thread awakens it by calling notify() or notify_all(). Once awakened, wait() re-acquires the lock and returns. It is also possible to specify a timeout.
但是需要注意的是:
notify() and notify_all()这两个方法,不会释放锁,这意味着线程或者被唤醒的线程不会立刻执行wait()
我们可以通过Conditon对象实现一个周期定时器的功能,每当定时器超时的时候,其他线程都可以检测到,代码例子如下:
import threading
import time class PeriodicTimer:
"""
这里做了一个定时器
""" def __init__(self, interval):
self._interval = interval
self._flag = 0
self._cv = threading.Condition() def start(self):
t = threading.Thread(target=self.run)
t.daemon = True
t.start() def run(self):
while True:
time.sleep(self._interval)
with self._cv:
# 这个点还是非常有意思的^=
self._flag ^= 1
self._cv.notify_all() def wait_for_tick(self):
with self._cv:
last_flag = self._flag while last_flag == self._flag:
self._cv.wait() # 下面两个分别为两个需要定时执行的任务
def countdown(nticks):
while nticks > 0:
ptimer.wait_for_tick()
print('T-minus', nticks)
nticks -= 1 def countup(last):
n = 0
while n < last:
ptimer.wait_for_tick()
print('Counting', n)
n += 1 ptimer = PeriodicTimer(5)
ptimer.start() threading.Thread(target=countdown, args=(10,)).start()
threading.Thread(target=countup, args=(5,)).start()
关于线程中锁的使用
要在多线程中安全使用可变对象,需要使用threading库中的Lock对象
先看一个关于锁的基本使用:
import threading
class SharedCounter:
def __init__(self, initial_value=0):
self._value = initial_value
self._value_lock = threading.Lock()
def incr(self,delta = 1):
with self._value_lock:
self._value += delta
def decr(self, delta=1):
with self._value_lock:
self._value -= delta
Lock对象和with语句块一起使用可以保证互斥执行,这样每次就只有一个线程可以执行with语句包含的代码块。with语句会在这个代码快执行前自动获取锁,在执行结束后自动释放所。
线程的调度本质上是不确定的,因此,在多线程程序中错误的使用锁机制可能会导致随机数据
损坏或者其他异常错误,我们称之为竞争条件
你可能看到有些“老python程序员”
还是通过_value_lock.acquire() 和_value_lock.release(),明显看来
还是with更加方便,不容易出错,毕竟你无法保证那次就忘记释放锁了
为了避免死锁,使用锁机制的程序应该设定每个线程一次只能获取一个锁
threading库中还提供了其他的同步原语:RLock,Semaphore对象。但是这两个使用场景相对来说比较特殊
RLock(可重入锁)可以被同一个线程多次获取,主要用来实现基于检测对象模式的锁定和同步。在使用这种锁的时候,当锁被持有时,只有一个线程可以使用完整的函数或者类中的方法,例子如下:
import threading
class SharedCounter:
_lock = threading.RLock()
def __init__(self,initial_value=0):
self._value = initial_value
def incr(self,delta=1):
with SharedCounter._lock:
self._value += delta
def decr(self,delta=1):
with SharedCounter._lock:
self.incr(-delta)
这个例子中的锁是一个类变量,也就是所有实例共享的类级锁,这样就保证了一次只有一个线程可以调用这个类的方法。与标准锁不同的是已经持有这个锁的方法再调用同样适用这个锁的方法时,无需再次获取锁,例如上面例子中的decr方法。
这种方法的特点是:无论这个类有多少实例都使用一个锁。因此在需要使用大量使用计数器的情况下内存效率更高。
缺点:在程序中使用大量线程并频繁更新计数器时会有竞争用锁的问题。
信号量对象是一个建立在共享计数器基础上的同步原语,如果计数器不为0,with语句讲计数器减1,
线程被允许执行。with语句执行结束后,计数器加1。如果计数器为0,线程将被阻塞,直到其他线程结束并将计数器加1。但是信号量不推荐使用,增加了复杂性,影响程序性能。
所以信号量更适用于哪些需要在线程之间引入信号或者限制的程序。例如限制一段代码的并发量
from threading import Semaphore
import requests _fetch_url_sema = Semaphore(5) def fetch_url(url):
with _fetch_url_sema:
return requests.get(url)
关于防止死锁的加锁机制
在多线程程序中,死锁问题很大一部分是由于多线程同时获取多个锁造成的。
举个例子:一个线程获取一个第一个锁,在获取第二个锁的时候发生阻塞,那么这个线程就可能阻塞其他线程执行,从而导致整个程序假死。
一种解决方法:为程序中每一个锁分配一个唯一的id,然后只允许按照升序规则来使用多个锁。
import threading
from contextlib import contextmanager # 存储已经请求锁的信息
_local = threading.local() @contextmanager
def acquire(*locks):
# 把锁通过id进行排序
locks = sorted(locks, key=lambda x: id(x)) acquired = getattr(_local, 'acquired', []) if acquired and max(id(lock) for lock in acquired) >= id(locks[0]):
raise RuntimeError("Lock order Violation")
acquired.extend(locks)
_local.acquired = acquired try:
for lock in locks:
lock.acquire()
yield
finally:
for lock in reversed(locks):
lock.release()
del acquired[-len(locks):] x_lock = threading.Lock()
y_lock = threading.Lock() def thread_1():
while True:
with acquire(x_lock,y_lock):
print("Thread-1") def thread_2():
while True:
with acquire(y_lock,x_lock):
print("Thread-2") t1 = threading.Thread(target=thread_1)
t1.daemon = True
t1.start() t2 = threading.Thread(target=thread_2)
t2.daemon = True
t2.start()
通过排序,不管以什么样的顺序来请求锁,这些锁都会按照固定的顺序被获取。
这里也用了thread.local()来保存请求锁的信息
同样的这个东西也可以用来保存线程的信息,而这个线程对其他的线程是不可见的
Python 并发编程(一)之线程的更多相关文章
- Python并发编程之谈谈线程中的“锁机制”(三)
大家好,并发编程 进入第三篇. 今天我们来讲讲,线程里的锁机制. 本文目录 何为Lock( 锁 )?如何使用Lock( 锁 )?为何要使用锁?可重入锁(RLock)防止死锁的加锁机制饱受争议的GIL( ...
- Python之路【第十六篇】:Python并发编程|进程、线程
一.进程和线程 进程 假如有两个程序A和B,程序A在执行到一半的过程中,需要读取大量的数据输入(I/O操作), 而此时CPU只能静静地等待任务A读取完数据才能继续执行,这样就白白浪费了CPU资源. 是 ...
- python并发编程-进程池线程池-协程-I/O模型-04
目录 进程池线程池的使用***** 进程池/线程池的创建和提交回调 验证复用池子里的线程或进程 异步回调机制 通过闭包给回调函数添加额外参数(扩展) 协程*** 概念回顾(协程这里再理一下) 如何实现 ...
- python 并发编程 多线程 守护线程
做完工作这个进程就应该被销毁 单线程情况: 一个进程 ,默认有一个主线程 ,这个主线程执行完代码后 ,就应该自动销毁.然后进程也销毁. 多线程情况: 主线程代表进程结束 一个进程可以开多个线程,默认开 ...
- python 并发编程 多线程 开启线程的两种方式
一 threading模块介绍 multiprocess模块的完全模仿了threading模块的接口,二者在使用层面,有很大的相似性 二 开启线程的两种方式 第一种 每造一个进程,默认有一个线程,就是 ...
- python 并发编程 多线程 目录
线程理论 python 并发编程 多线程 开启线程的两种方式 python 并发编程 多线程与多进程的区别 python 并发编程 多线程 Thread对象的其他属性或方法 python 并发编程 多 ...
- 《转载》Python并发编程之线程池/进程池--concurrent.futures模块
本文转载自Python并发编程之线程池/进程池--concurrent.futures模块 一.关于concurrent.futures模块 Python标准库为我们提供了threading和mult ...
- python并发编程之进程、线程、协程的调度原理(六)
进程.线程和协程的调度和运行原理总结. 系列文章 python并发编程之threading线程(一) python并发编程之multiprocessing进程(二) python并发编程之asynci ...
- Python进阶(4)_进程与线程 (python并发编程之多进程)
一.python并发编程之多进程 1.1 multiprocessing模块介绍 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大 ...
随机推荐
- css编写注意事项(不定时更新)
CSS的编写是需要积累的,而一个好的css编写习惯对我们将来的成长是非常有利的,我会把我平时看到的或者遇到的会不定时的更新到这里,不时翻一下,但求有所进步. 如果各位看官也有看法和建议,评论下,我也会 ...
- java.lang.OutOfMemoryError 解决程序启动内存溢出问题
java.lang.OutOfMemoryError: Java heap space Myeclipse里面部署的java web项目,浏览器访问的时候出现错误: type Exception re ...
- Java单元测试之覆盖率统计eclemma
安装 有两种安装方法 下载安装(推荐) 地址: http://sourceforge.net/projects/eclemma/ 将解压后的features和plugins目录下的文件分别拷贝到Ecl ...
- 201521123081《Java程序设计》 第8周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结集合与泛型相关内容. 参考资料:XMIND 1.2 选做:收集你认为有用的代码片段 2. 书面作业 本次作业题集 集合 Q1. Li ...
- 201521123112《Java程序设计》第7周学习总结
1. 本周学习总结 2. 书面作业 1.ArrayList代码分析 1.1 解释ArrayList的contains源代码 下面先贴出contains的源代码: public boolean cont ...
- IDEA导入Eclipse项目 【未结束的注释、非法类型的开始、缺少符号】
如果我们导入Eclipse项目的使用出现了未结束的注释.非法类型的开始.缺少符号这么一些编译时期的错误,而我们的代码明明看起来就是正常的-. 我们去检查一下是否编码的问题:把FileEncoding全 ...
- SpringMVC第二篇【过滤编码器、注解开发、requestMapping、业务方法与传统参数】
SpringMVC过滤编码器 在SpringMVC的控制器中,如果没有对编码进行任何的操作,那么获取到的中文数据是乱码! 即使我们在handle()方法中,使用request对象设置编码也不行!原因也 ...
- 记一次【模拟点击】,WinForm小软件开发过程
前言 年初四月份的时候,有朋友找到我,说想开发一个模拟点击的软件.最终软件做完后,发现效果不理想.唯一开发的我是认为最好是放弃了,做运营的他,坚持说这个没问题,说是改变合作方式.最终也是不了了之了. ...
- [转]Xcode的快捷键及代码格式化
Xcode比较常用的快捷键,特别是红色标注的,很常用.1. 文件CMD + N: 新文件CMD + SHIFT + N: 新项目CMD + O: 打开CMD + S: 保存CMD+OPt+S:保存所有 ...
- IE无法获得cookie,ie不支持cookie的解决办法,火狐支持
发现用自己的电脑 IE7.0总是无法正常登录,别的电脑都可以. 每次登录后又被重定向回了登录页面. 可换成Firefox和google chrome 却一切OK,后来还把浏览器升级到IE8.0 问题依 ...