利用python基于微博数据打造一颗“心”
一年一度的虐狗节将至,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的。程序员在晒什么,程序员在加班。但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“爱心”,我想她一定会感动得哭了吧。哈哈
准备工作
有了想法之后就开始行动了,自然最先想到的就是用 Python 了,大体思路就是把微博数据爬下来,数据经过清洗加工后再进行分词处理,处理后的数据交给词云工具,配合科学计算工具和绘图工具制作成图像出来,涉及到的工具包有:
requests 用于网络请求爬取微博数据,结巴分词进行中文分词处理,词云处理库 wordcloud,图片处理库 Pillow,科学计算工具 NumPy ,类似于 MATLAB 的 2D 绘图库 Matplotlib
工具安装
安装这些工具包时,不同系统平台有可能出现不一样的错误,wordcloud,requests,jieba 都可以通过普通的 pip 方式在线安装,
pip install wordcloud
pip install requests
pip install jieba
在Windows 平台安装 Pillow,NumPy,Matplotlib 直接用 pip 在线安装会出现各种问题,推荐的一种方式是在一个叫 Python Extension Packages for Windows 1 的第三方平台下载 相应的 .whl 文件安装。可以根据自己的系统环境选择下载安装 cp27 对应 python2.7,amd64 对应 64 位系统。下载到本地后进行安装
pip install Pillow-4.0.0-cp27-cp27m-win_amd64.whl
pip install scipy-0.18.0-cp27-cp27m-win_amd64.whl
pip install numpy-1.11.3+mkl-cp27-cp27m-win_amd64.whl
pip install matplotlib-1.5.3-cp27-cp27m-win_amd64.whl
其他平台可根据错误提示 Google 解决。或者直接基于 Anaconda 开发,它是 Python 的一个分支,内置了大量科学计算、机器学习的模块 。
获取数据
新浪微博官方提供的 API 是个渣渣,只能获取用户最新发布的5条数据,退而求其次,使用爬虫去抓取数据,抓取前先评估难度,看看是否有人写好了,在GitHub逛了一圈,基本没有满足需求的。倒是给我提供了一些思路,于是决定自己写爬虫。使用 http://m.weibo.cn/ 移动端网址去爬取数据。发现接口 http://m.weibo.cn/index/my?format=cards&page=1 可以分页获取微博数据,而且返回的数据是 json 格式,这样就省事很多了,不过该接口需要登录后的 cookies 信息,登录自己的帐号就可以通过 Chrome 浏览器 找到 Cookies 信息。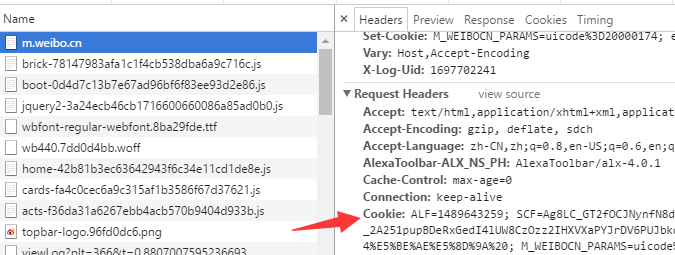
实现代码:
def fetch_weibo():
api = "http://m.weibo.cn/index/my?format=cards&page=%s"
for i in range(1, 102):
response = requests.get(url=api % i, cookies=cookies)
data = response.json()[0]
groups = data.get("card_group") or []
for group in groups:
text = group.get("mblog").get("text")
text = text.encode("utf-8")
text = cleanring(text).strip()
yield text
查看微博的总页数是101,考虑到一次性返回一个列表对象太费内存,函数用 yield 返回一个生成器,此外还要对文本进行数据清洗,例如去除标点符号,HTML 标签,“转发微博”这样的字样。
保存数据
数据获取之后,我们要把它离线保存起来,方便下次重复使用,避免重复地去爬取。使用 csv 格式保存到 weibo.csv 文件中,以便下一步使用。数据保存到 csv 文件中打开的时候可能为乱码,没关系,用 notepad++查看不是乱码。
def write_csv(texts):
with codecs.open('weibo.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=["text"])
writer.writeheader()
for text in texts:
writer.writerow({"text": text}) def read_csv():
with codecs.open('weibo.csv', 'r') as f:
reader = csv.DictReader(f)
for row in reader:
yield row['text']
分词处理
从 weibo.csv 文件中读出来的每一条微博进行分词处理后再交给 wordcloud 生成词云。结巴分词适用于大部分中文使用场景,使用停止词库 stopwords.txt 把无用的信息(比如:的,那么,因为等)过滤掉。
def word_segment(texts):
jieba.analyse.set_stop_words("stopwords.txt")
for text in texts:
tags = jieba.analyse.extract_tags(text, topK=20)
yield " ".join(tags)
生成图片
数据分词处理后,就可以给 wordcloud 处理了,wordcloud 根据数据里面的各个词出现的频率、权重按比列显示关键字的字体大小。生成方形的图像,如图:

是的,生成的图片毫无美感,毕竟是要送人的也要拿得出手才好炫耀对吧,那么我们找一张富有艺术感的图片作为模版,临摹出一张漂亮的图出来。我在网上搜到一张“心”型图:
生成图片代码:
def generate_img(texts):
data = " ".join(text for text in texts)
mask_img = imread('./heart-mask.jpg', flatten=True)
wordcloud = WordCloud(
font_path='msyh.ttc',
background_color='white',
mask=mask_img
).generate(data)
plt.imshow(wordcloud)
plt.axis('off')
plt.savefig('./heart.jpg', dpi=600)
需要注意的是处理时,需要给 matplotlib 指定中文字体,否则会显示乱码,找到字体文件夹:C:\Windows\Fonts\Microsoft YaHei UI复制该字体,拷贝到 matplotlib 安装目录:C:\Python27\Lib\site-packages\matplotlib\mpl-data\fonts\ttf 下
差不多就这样。

当我自豪地把这张图发给她的时候,出现了这样的对话:
这是什么?
我:爱心啊,亲手做的
这么专业,好感动啊,你的眼里只有 python ,没有我 (哭笑)
我:明明是“心”中有 python 啊
利用python基于微博数据打造一颗“心”的更多相关文章
- 基于微博数据用 Python 打造一颗“心”
一年一度的虐狗节刚过去不久,朋友圈各种晒,晒自拍,晒娃,晒美食,秀恩爱的.程序员在晒什么,程序员在加班.但是礼物还是少不了的,送什么好?作为程序员,我准备了一份特别的礼物,用以往发的微博数据打造一颗“ ...
- 利用python将excel数据解析成json格式
利用python将excel数据解析成json格式 转成json方便项目中用post请求推送数据自定义数据,也方便测试: import xlrdimport jsonimport requests d ...
- 利用Python读取外部数据文件
不论是数据分析,数据可视化,还是数据挖掘,一切的一切全都是以数据作为最基础的元素.利用Python进行数据分析,同样最重要的一步就是如何将数据导入到Python中,然后才可以实现后面的数据分析.数 ...
- Python系列之——利用Python实现微博监控
0x00 前言: 前几个星期在写一个微博监控系统 可谓是一波三折啊 获取到微博后因为一些字符编码问题 导致心态爆炸开发中断 但是就在昨天发现了另外一个微博的接口 一个手机微博的接口https://m. ...
- 利用Python进行数据分析——数据规整化:清理、转换、合并、重塑(七)(1)
数据分析和建模方面的大量编程工作都是用在数据准备上的:载入.清理.转换以及重塑.有时候,存放在文件或数据库中的数据并不能满足你的数据处理应用的要求.很多人都选择使用通用编程语言(如Python.Per ...
- 利用python将excel数据导入mySQL
主要用到的库有xlrd和pymysql, 注意pymysql不支持python3 篇幅有限,只针对主要操作进行说明 连接数据库 首先pymysql需要连接数据库,我这里连接的是本地数据库(数据库叫ld ...
- 利用Python读取json数据并求数据平均值
要做的事情:一共十二个月的json数据(即12个json文件),json数据的一个单元如下所示.读取这些数据,并求取各个(100多个)城市年.季度平均值. { "time_point&quo ...
- 【原创】python基于大数据现实双色球预测
前提准备:利用sql筛选出每个球出现概率最高的前5个数 原理:先爬出所有的历史数据,然后模拟摇奖机出球的机制并大量模拟计算,直到出现列表中的某一个数后即停 注意事项:由于计算过程数据量很大,需要加入内 ...
- 一例tornado框架下利用python panda对数据进行crud操作
get提交部分 <script> /* $("#postbtn").click(function () { $.ajax({ url:'/loaddata', data ...
随机推荐
- MongoDB中的映射,限制记录和记录拼排序 文档的插入查询更新删除操作
映射 在 MongoDB 中,映射(Projection)指的是只选择文档中的必要数据,而非全部数据.如果文档有 5 个字段,而你只需要显示 3 个,则只需选择 3 个字段即可. find() 方法 ...
- 【概率论与数理统计】小结4 - 一维连续型随机变量及其Python实现
注:上一小节总结了离散型随机变量,这个小节总结连续型随机变量.离散型随机变量的可能取值只有有限多个或是无限可数的(可以与自然数一一对应),连续型随机变量的可能取值则是一段连续的区域或是整个实数轴,是不 ...
- Spring在JSP页面使用ServletContext
在 JSP 页面使用Application 可以 看到使用的是WebApplicationContextUtils 而不是WebApplicationContext.ROOT_WEB_APPLICAT ...
- jmeter按比例执行业务场景
可用函数 __counter实现: 函数助手中 找到 __counter,如 ${__counter(false,num)},功能简介 ---- 参数为true,每个用户有自己的计数器 ---- 参数 ...
- MySQL主从同步和读写分离的配置
主服务器:192.168.1.126 从服务器:192.168.1.163 amoeba代理服务器:192.168.1.237 系统全部是CentOS 6.7 1.配置主从同步 1.1.修改主服务器( ...
- 【JVM命令系列】jstat
命令基本概述 Jstat是JDK自带的一个轻量级小工具.全称"Java Virtual Machine statistics monitoring tool",它位于java的bi ...
- 【BZOJ】1015 [JSOI2008]星球大战starwar(并查集+离线处理)
Description 很久以前,在一个遥远的星系,一个黑暗的帝国靠着它的超级武器统治者整个星系.某一天,凭着一个偶然的机遇,一支反抗军摧毁了帝国的超级武器,并攻下了星系中几乎所有的星球.这些星球通过 ...
- Palindrome poj3974
Palindrome Time Limit: 15000MS Memory Limit: 65536K Total Submissions: 3280 Accepted: 1188 Descr ...
- .Neter玩转Linux系列之二:Linux下的文件目录及文件目录的权限
一.Linux下的文件目录 简介:linux的文件系统是采用级层式的树状目录结构,在此 结构中的最上层是根目录“/”,然后在此目录下再创建 其他的目录.深刻理解linux文件目录是非常重要的,如下图所 ...
- OpenCV探索之路(二十六):如何去除票据上的印章
最近在做票据的识别的编码工作时遇到一些问题,就是票据上往往会有一些红色印章把一些重要信息区域给覆盖了,比如一些开发票人员盖印章时比较随意,容易吧一些关键区域给遮蔽了,这让接下来的票据识别很困难,因此, ...