分布式学习(一)——基于ZooKeeper的队列爬虫
zookeeper
一直琢磨着分布式的东西怎么搞,公司也没有相关的项目能够参与,所以还是回归自己的专长来吧——基于ZooKeeper的分布式队列爬虫,由于没什么人能够一起沟通分布式的相关知识,下面的小项目纯属“胡编乱造”。
简单介绍下ZooKeeper:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
基本的知识就不过多介绍了,可以参考参考下面这些人的:
ZooKeeper官网
http://www.cnblogs.com/wuxl360/p/5817471.html
一、整体架构
这张图来自skyme,我也是看了这张图的启发写了这篇文章的。

最基本的分布式队列即一个生产者不断抓取链接,然后将链接存储进ZooKeeper的队列节点里,每个节点的value都只是链接,然后消费者从中获取一条url进行抓取。本项目生产这主要是用来生产URL即可,这部分就不要要求太多。然后是消费者,消费者需要解决的问题有:
1.队列如何保证自己的分发正确;
2.消费这如何进行高效的抓取。
二、ZooKeeper队列原理
2.1 介绍
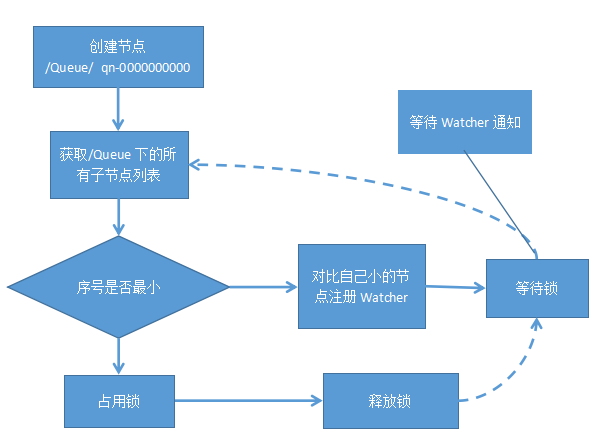
分布式队列,目前此类产品大多类似于ActiveMQ、RabbitMQ等,本文主要介绍的是Zookeeper实现的分布式队列,它的实现方式也有两种,一种是FIFO(先进先出)的队列,另一种是等待队列元素聚集之后才统一安排的Barrier模型。同样,本文主要讲的是FIFO的队列模型。其大体设计思路也很简单,主要是在/SinaQueue下创建顺序节点,如/SinaQueue/qn-000000000,创建完节点之后,根据下面的4个步骤来决定执行的顺序。
1.通过调用getChildren()接口来获取某一节点下的所有节点,即获取队列中的所有元素。
2.确定自己的节点序号在所有子节点中的顺序。
3.如果自己不是序号最小的子节点,那么就需要进入等待,同时向比自己序号小的最后一个节点注册Watcher监听。
4.接收到Watcher通知后,重复步骤1。
2.2 Watcher介绍
znode以某种方式发生变化时,“观察”(watch)机制可以让客户端得到通知.可以针对ZooKeeper服务的“操作”来设置观察,该服务的其他 操作可以触发观察。
1.Watch是一次性的,每次都需要重新注册,并且客户端在会话异常结束时不会收到任何通知,而快速重连接时仍不影响接收通知。
2.Watch的回调执行都是顺序执行的,并且客户端在没有收到关注数据的变化事件通知之前是不会看到最新的数据,另外需要注意不要在Watch回调逻辑中阻塞整个客户端的Watch回调
3.Watch是轻量级的,WatchEvent是最小的通信单元,结构上只包含通知状态、事件类型和节点路径。ZooKeeper服务端只会通知客户端发生了什么,并不会告诉具体内容。
2.3 源码
在csdn上找到了某个人写的这个过程,使用的是ZKClient,有兴趣可以看看杰布斯的博客,但是没有实现上面过程的第三步(Watcher相关的),这里,我们使用的是Zookeeper的另一个客户端工具curator,其中,curator实现了各种Zookeeper的特性,如:Election(选举),Lock(锁),Barrier(关卡),Atonmic(原子量),Cache(缓存),Queue(队列)等。我们来看看Curator实现的简单的分布式队列的源码。
public class SimpleDistributedQueue {
...
private final CuratorFramework client;//连接Zookeeper的客户端
private final String path;//路径
private final EnsureContainers ensureContainers;//确保原子特性
private final String PREFIX = "qn-";//顺序节点的同意前缀,使用qn-
...
其中PREFIX是用来生成顺序节点的,默认不可更改,将生成的路径赋予给path,然后向节点赋予数据。下面是赋予数据的代码
public boolean offer(byte[] data) throws Exception {
String thisPath = ZKPaths.makePath(this.path, "qn-");//生成的路径
((ACLBackgroundPathAndBytesable)this.client.create().creatingParentContainersIfNeeded().withMode(CreateMode.PERSISTENT_SEQUENTIAL)).forPath(thisPath, data);//如果没有路径将生成持久化的路径然后存储节点的数据。
return true;
}
最关键的来了,队列如何保证自己的分发正确?SimpleDistributedQueue使用take()来取得队列的头部,然后将头部删掉,这一过程的一致性是通过CountDownLatch和Watcher来实现的。
public byte[] take() throws Exception {//直接调用interPoll,并将超时的设置为0;
return this.internalPoll(0L, (TimeUnit)null);
}
private byte[] internalPoll(long timeout, TimeUnit unit) throws Exception {
...//忽略超时的设置代码
while(true) {
final CountDownLatch latch = new CountDownLatch(1);//定义一个latch,设置为1,先加锁,然后执行完任务后再释放锁
Watcher watcher = new Watcher() {
public void process(WatchedEvent event) {
latch.countDown();
}
};
byte[] bytes;
try {
bytes = this.internalElement(true, watcher);//调用internalElement函数来获取字节流
} catch (NoSuchElementException var17) {
}
...
if (hasTimeout) {
long elapsedMs = System.currentTimeMillis() - startMs;
long thisWaitMs = maxWaitMs - elapsedMs;
if (thisWaitMs <= 0L) { //如果等待超时了则返回为空
return null;
}
latch.await(thisWaitMs, TimeUnit.MILLISECONDS);
} else {
latch.await();
}
}
}
private byte[] internalElement(boolean removeIt, Watcher watcher) throws Exception {
this.ensurePath();
List nodes;
try {
nodes = watcher != null ? (List)((BackgroundPathable)this.client.getChildren().usingWatcher(watcher)).forPath(this.path) : (List)this.client.getChildren().forPath(this.path);//获取节点下的所有子节点注册监听(watcher默认都不是为空的,每一个都注册)
} catch (NoNodeException var8) {
throw new NoSuchElementException();
}
Collections.sort(nodes);//对节点进行排序
Iterator var4 = nodes.iterator();
while(true) {//遍历
while(var4.hasNext()) {
String node = (String)var4.next();//取得当前头结点
if (node.startsWith("qn-")) {
String thisPath = ZKPaths.makePath(this.path, node);
try {
byte[] bytes = (byte[])this.client.getData().forPath(thisPath);
if (removeIt) {
this.client.delete().forPath(thisPath);//删除该节点
}
return bytes;//返回节点的字节流
...
}
三、多线程并发
对于分布式爬虫来说,让每一个消费者高效的进行抓取是具有重要意义的,为了加快爬虫的速度,采用多线程爬虫的方法。Java多线程实现方式主要有三种:继承Thread类、实现Runnable接口、使用ExecutorService、Callable、Future实现有返回结果的多线程。其中前两种方式线程执行完后都没有返回值,只有最后一种是带返回值的。其中使用Executors提供了四种声明线程池的方法,分别是newCachedThreadPool、newFixedThreadPool、newSingleThreadExecutor和newScheduledThreadPool,为了监控实时监控队列的长度,我们使用数组型的阻塞队列ArrayBlockingQueue。声明方式如下:
private static final BlockingQueue<Runnable> queuelength = new ArrayBlockingQueue<>(1000);
ExecutorService es = new ThreadPoolExecutor(CORE, CORE,
0L, TimeUnit.MILLISECONDS,
queuelength);
四、使用
本次实验主要环境如下:
zookeeper.version=3.5
java.version=1.8.0_65
os.arch=amd64
i5 四核心CPU
网速为中国电信100M
这里主要是对博客园中的前两千条博客进行爬取,本文主要是对分布式队列的理解,就不再进行什么难度的处理(比如元素的选取、数据的存储等),只输出每篇博客的title即可。
生产者代码:
public class Producer {
//logger
private static final Logger logger = LoggerFactory.getLogger(Producer.class);
public static final CuratorFramework client = CuratorFrameworkFactory.builder().connectString("119.23.46.71:2181")
.sessionTimeoutMs(1000)
.connectionTimeoutMs(1000)
.canBeReadOnly(false)
.retryPolicy(new ExponentialBackoffRetry(1000, Integer.MAX_VALUE))
.defaultData(null)
.build();
private static SimpleDistributedQueue queue = new SimpleDistributedQueue(client, "/Queue");
private static Integer j = 0;
public static void begin(String url) {//对博客园的每一页进行爬取
try {
String content = HttpHelper.getInstance().get(url);
resolveweb(content);
} catch (Exception e) {
logger.error("", e);
}
}
public static void resolveweb(String content) throws Exception {
Elements elements = Jsoup.parse(content).select("a.titlelink");//对每篇博客的标题进行获取
for (Element element : elements) {
String url = element.attr("href");//
if (StringUtils.isNotEmpty(url) && !url.contains("javascript") && !url.contains("jump")) {//去除a中调用href过程
logger.info(url + " " + String.valueOf(j++));
queue.offer(url.getBytes());
}
}
}
public static void main(String[] args) {
client.start();
for (int i = 0; i < 100; i++) {
begin("https://www.cnblogs.com/#p" + String.valueOf(i));
}
}
}
消费者
public class Consumer {
//logger
private static final Logger logger = LoggerFactory.getLogger(Consumer.class);
private static final CuratorFramework client = CuratorFrameworkFactory.builder().connectString("119.23.46.71:2181")
.sessionTimeoutMs(1000)
.connectionTimeoutMs(1000)
.canBeReadOnly(false)
.retryPolicy(new ExponentialBackoffRetry(1000, Integer.MAX_VALUE))
.defaultData(null)
.build();
private static SimpleDistributedQueue queue = new SimpleDistributedQueue(client, "/SinaQueue");
private static Integer i = 0;
private static final Integer CORE = Runtime.getRuntime().availableProcessors();
//声明为一个数组型的阻塞队列,这里限制大小为
private static final BlockingQueue<Runnable> queuelength = new ArrayBlockingQueue<>(1000);
static class CBCrawler implements Runnable {
private String url;
public CBCrawler(String url) {
this.url = url;
}
@Override
public void run() {
String content = HttpHelper.getInstance().get(url);
logger.info(url + " " + Jsoup.parse(content).title());//打印网页的标题
}
}
public static void begin() {
try {
ExecutorService es = new ThreadPoolExecutor(CORE, CORE,
0L, TimeUnit.MILLISECONDS,
queuelength);
while (client.getChildren().forPath("/SinaQueue").size() > 0) {
CBCrawler crawler = new CBCrawler(new String(queue.take()));
es.submit(crawler);//执行爬虫
i = i + 1;
logger.info(String.valueOf(i) + " is finished\n" + " queue size is" + queuelength.size());//监控当前队列的长度
}
if (!es.isShutdown()) {//如果线程池没有关闭则关闭
es.shutdown();
}
} catch (Exception e) {
logger.error("", e);
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
client.start();
begin();
client.close();
logger.info("start time: " + start);
long end = System.currentTimeMillis();
logger.info("end time: " + end);
logger.info("take time: " + String.valueOf(end - start));//记录开始时间和结束时间
}
}
由于在队列的take中使用了CountDownLatch和Collections.sort(nodes)进行排序,耗时过程变长了不少,2000个节点,单台服务器和多台服务器的耗时是一样的,都是9分钟,具体实验见下面。
实验结果
生产者生产URL:
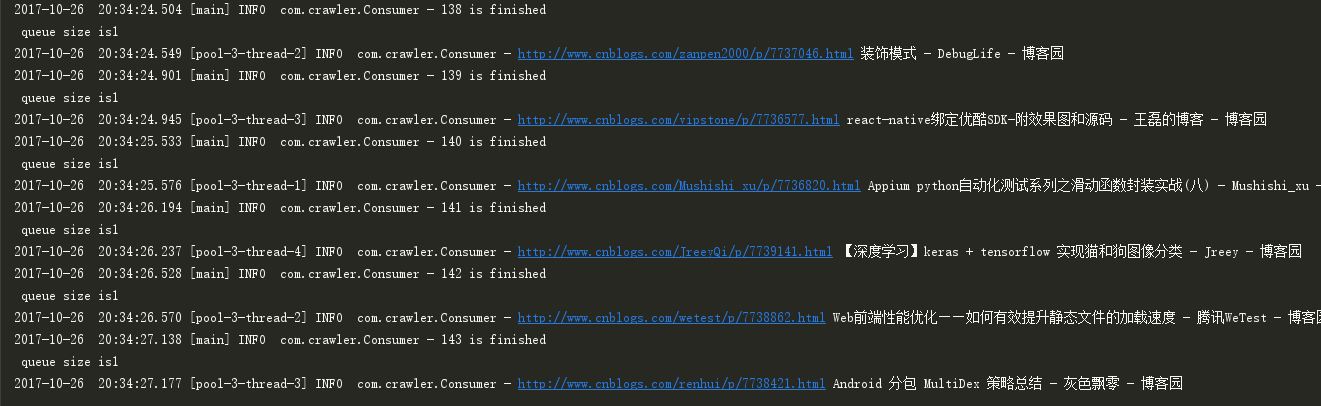
单机模式下的消费者,耗时:560825/(1000*60)=9分钟

分布式模式下的抓取:
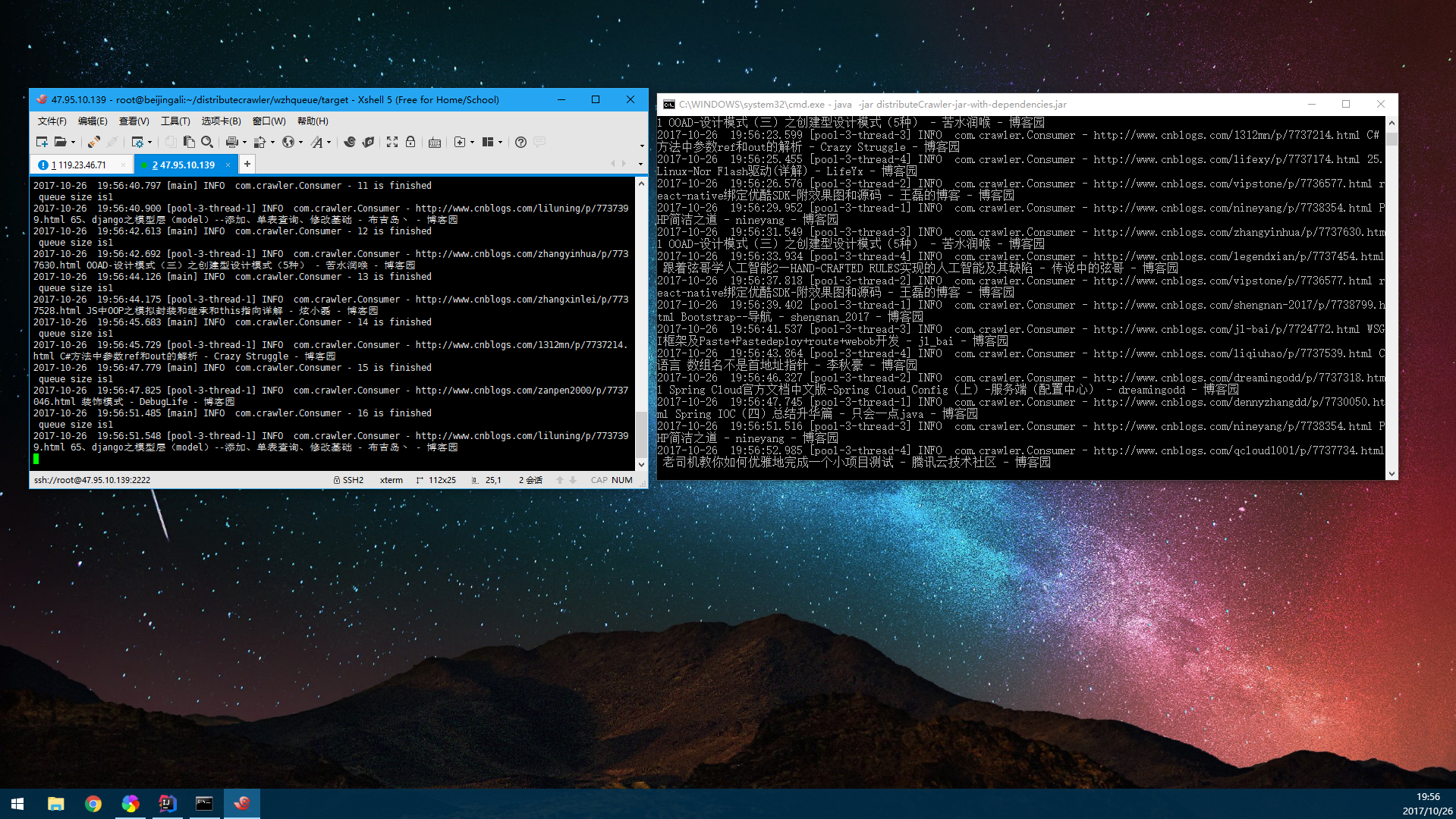
耗时:564374/(1000*60)=9分钟:

由图可见,当每个消费者处理能力大于队列分配的能力时,耗时的过程反而是在队列,毕竟分布式队列在进行take动作的时候对节点进行了加锁,还要对队列进行排序,特别是在节点多达2000+的情况下,耗时是十分严重的。
实验二
实验二的主要解决的问题是将消费者处理的耗时延长,我们使用Thread.sleep(n)来模拟时长。由于博客园突然连不上,为了减少这种不可控的故障,抓取的网页改为新浪,并将抓取后的URL以文本形式保存下来。
public static void sleepUtil(Integer time) {
try {
Thread.sleep(time * 1000);
} catch (Exception e) {
logger.error("线程sleep异常", e);
}
}
此时再看程序的输出,可以看出,队列的分发能力已经大于消费者的处理能力,总算是正常了。
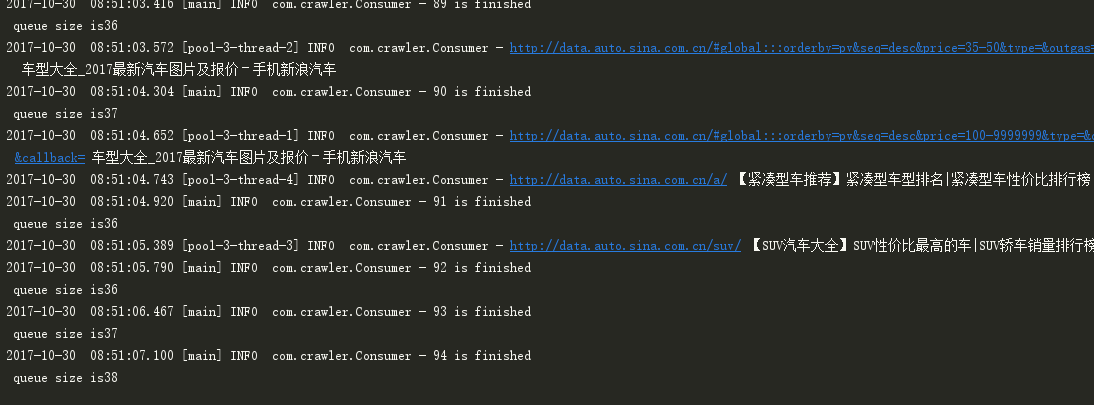
分布式队列分发的时间是:341998/(1000*60)=5.6分钟
2017-10-30 08:55:48.458 [main] INFO com.crawler.Consumer - start time: 1509324606460
2017-10-30 08:55:48.458 [main] INFO com.crawler.Consumer - end time: 1509324948458
2017-10-30 08:55:48.458 [main] INFO com.crawler.Consumer - take time: 341998
两台机子抓取完毕的耗时分别是:
A服务器:08:49:54.509——09:02:07
B服务器:08:49:54.509——09:05:05
单机的时候分发时间是:353198/(1000*60)=5.8分钟
2017-10-30 09:30:25.812 [main] INFO com.crawler.Consumer - start time: 1509326672614
2017-10-30 09:30:25.812 [main] INFO com.crawler.Consumer - end time: 1509327025812
2017-10-30 09:30:25.812 [main] INFO com.crawler.Consumer - take time: 353198
耗时
09:24:33.391——09:51:44.733
分布式下平均耗时约为13分钟,单机模式下耗时约为27分钟,还是蛮符合估算的。
总结
源代码都放在这里了,有兴趣的可以star一下或者下载看一下,也欢迎大家提提意见,没企业级的实战环境,见笑了O(∩_∩)O~
欢迎访问我的个人网站
个人网站网址:http://www.wenzhihuai.com
个人网站代码地址:https://github.com/Zephery/newblog
分布式学习(一)——基于ZooKeeper的队列爬虫的更多相关文章
- 爬虫学习之基于Scrapy的网络爬虫
###概述 在上一篇文章<爬虫学习之一个简单的网络爬虫>中我们对爬虫的概念有了一个初步的认识,并且通过Python的一些第三方库很方便的提取了我们想要的内容,但是通常面对工作当作复杂的需求 ...
- 爬虫学习之基于Scrapy的爬虫自动登录
###概述 在前面两篇(爬虫学习之基于Scrapy的网络爬虫和爬虫学习之简单的网络爬虫)文章中我们通过两个实际的案例,采用不同的方式进行了内容提取.我们对网络爬虫有了一个比较初级的认识,只要发起请求获 ...
- 基于Zookeeper实现的分布式互斥锁 - InterProcessMutex
Curator是ZooKeeper的一个客户端框架,其中封装了分布式互斥锁的实现,最为常用的是InterProcessMutex,本文将对其进行代码剖析 简介 InterProcessMutex基于Z ...
- 基于Zookeeper的分布式锁(干干干货)
原文地址: https://juejin.im/post/5df883d96fb9a0163514d97f 介绍 为什么使用锁 锁的出现是为了解决资源争用问题,在单进程环境下的资源争夺可以使用 JDK ...
- 基于ZooKeeper的分布式锁和队列
在分布式系统中,往往需要一些分布式同步原语来做一些协同工作,上一篇文章介绍了Zookeeper的基本原理,本文介绍下基于Zookeeper的Lock和Queue的实现,主要代码都来自Zookeeper ...
- Java Web学习总结(20)——基于ZooKeeper的分布式session实现
1. 认识ZooKeeper ZooKeeper-- "动物园管理员".动物园里当然有好多的动物,游客可以根据动物园提供的向导图到不同的场馆观赏各种类型的动物,而不是像走在原始 ...
- AMQ学习笔记 - 14. 实践方案:基于ZooKeeper + ActiveMQ + replicatedLevelDB的主从部署
概述 基于ZooKeeper + ActiveMQ + replicatedLevelDB,在Windows平台的主从部署方案. 主从部署可以提供数据备份.容错[1]的功能,但是不能提供负载均衡的功能 ...
- 基于 Zookeeper 的分布式锁实现
1. 背景 最近在学习 Zookeeper,在刚开始接触 Zookeeper 的时候,完全不知道 Zookeeper 有什么用.且很多资料都是将 Zookeeper 描述成一个“类 Unix/Linu ...
- 基于Zookeeper的分步式队列系统集成案例
基于Zookeeper的分步式队列系统集成案例 Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, ...
随机推荐
- Struts2第六篇【文件上传和下载】
前言 在讲解开山篇的时候就已经说了,Struts2框架封装了文件上传的功能--..本博文主要讲解怎么使用Struts框架来完成文件上传和下载 回顾以前的文件上传 首先,我们先来回顾一下以前,我们在we ...
- Java内存分配之堆、栈和常量池
Java内存分配主要包括以下几个区域: 1. 寄存器:我们在程序中无法控制 2. 栈:存放基本类型的数据和对象的引用,但对象本身不存放在栈中,而是存放在堆中 3. 堆:存放用new产生的数据 4. 静 ...
- JAVA数据流再传递
有一个filter类,在请求进入的时候读取了URL信息,并且读取了requestBod中的参数信息,那么在请求到达实际的控制层时,入参信息是拿不到的,对这种情况就需要数据流做再传递处理. 处理原理:使 ...
- 初次就这么给了你(Django-rest-framework)
Django-Rest-Framework Django-Rest框架是构建Web API强大而灵活的工具包. 简单粗暴,直奔主题. pip install django pip install dj ...
- Android性能优化xml之<include>、<merge>、<ViewStub>标签的使用
一.使用<include>标签对"重复代码"进行复用 <include>标签是我们进行Android开发中经常用到的标签,比如多个界面都同样用到了一个左侧筛 ...
- jsp base路径
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"% ...
- vim与sublime,程序员的屠龙刀和倚天剑
对程序员来说,写代码是再熟悉不过的事情了,windows系统自带有记事本软件,能写写小规模的代码,可是代码量大了,它的局限性就暴露得很明显了:没有语法高亮,没有自动提示,不支持项目管理,界面难看-- ...
- Cow Uncle 学习了叉积的一点运用,叉积真的不错
Cow Uncle Time Limit: 4000/2000MS (Java/Others) Memory Limit: 128000/64000KB (Java/Others) SubmitSta ...
- 简单Elixir游戏服设计- 创建项目
反正是写到哪算哪. 创建umbrella项目 mix new simple_game --umbrella 创建model项目 cd simple_game\apps mix new model 创建 ...
- HelloWorld改编,仿bilibili手机端(一)——侧滑菜单界面布局
讲解目录: 1.要实现的效果图展示及详细分析HelloWorld项目的xml布局文件(基于navigation drawer activity) 2.简单修改menu及menu相关详解 ...