hive(II)--sql考查的高频问题
在了解别人hive能力水平的时候,不管是别人问我还是我了解别人,有一些都是必然会问的东西。问的问题也大都大同小异。这里总结一下我遇到的那些hive方面面试可能涉及的问题
1、行转列(列转行)
当我们建设数据仓库时,我们对来自OLAP的数据进行加工以便处理成维度模型。在维度模型设计的时候就需要面对这样的问题(其他时候可能也会用到)
数据准备
建表:create table shj_cnblogs(customer_id string,trans_year string,trans_amount int,product_name string) row format delimited fields terminated by ',';
导入数据:load data local inpath '/home/www/su*****n/sample/data.csv' into table shj_cnblogs;

行转列
上表是一个虚拟数据(业务含义:customer_id代表一个客户,其每年购买的产品和金额),希望将展示客户不同年份购买了多少以及产品。呈现的数据希望是这样的。

这里我们的难点就是如何在行聚合时将产品行转列了,这就说到hive中的函数UDTF(表生成函数)。UDTF函数有:array/explode/collect_set/collect_list等。这里使用了collect_set,脚本为:
select customer_id,trans_year,sum(trans_amount) as total_fund,concat_ws(',',collect_set(product_name)) as all_product from shj_cnblogs group by customer_id,trans_year;
--(当遇到不懂得函数可以用命令查看解释:show function [extended] fun_name;)
上面我们将多行转为一列,也可以转为多列。转多列使用的是collect_set的集合属性,通过调用集合元素实现多行转多列。
列转行
假如我们虚拟了这样的数据来描述电影的表,想要将它的列拆分多行,该怎么办呢?

这里我们使用explode函数,该函数输入的是一个数组,后将数组中的每个元素都作为一行来输出。但有一个明显的限制,不能与其他列共同使用。如果要包含其他列,则需要laterval view来实现。使用lateral view需要指定视图别名和生成的字段别人。
select film_id,actor_id,dd from shj_1 lateral view explode(split(feature_desc,',')) cc as dd ;[这里cc是视图别名,dd是字段别名]
假如这里需要列分割的不止一列,则使用两次lateral view来实现。比如说这里的actor_id列是多值分布的,则写法如下
select film_id,bb,dd from shj_1 lateral view explode(split(actor_id,',')) aa as bb lateral view explode(split(feature_desc,',')) cc as dd ;
执行后结果如图
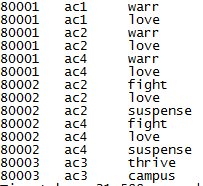
2、窗口函数
在做OLAP分析或报表时,常常使用窗口函数能大幅度提升我们的分析效率。在说窗口函数前,请一定要记住:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前.
窗口函数的关键字:over(),它帮助我们在行记录上实现聚合,我们既可以看到明细数据也可以看到聚合数据(使用中,发现窗口函数可以和聚合函数一起使用的,但注意!窗口函数是仅早于order by步骤。写sql时应注意两者之间是否存在冲突,这点容易出错。)。这里我们从一个样本数据出发(客户买东西场景),探索窗口函数的妙用(数据和内容参考博客:http://blog.csdn.net/qq_26937525/article/details/54925827,这篇博客写的真不错!)
jack,2015-01-01,10
tony,2015-01-02,15
jack,2015-02-03,23
tony,2015-01-04,29
jack,2015-01-05,46
jack,2015-04-06,42
tony,2015-01-07,50
jack,2015-01-08,55
mart,2015-04-08,62
mart,2015-04-09,68
neil,2015-05-10,12
mart,2015-04-11,75
neil,2015-06-12,80
mart,2015-04-13,94
I、认识窗口函数
我们先看看下面的三个sql语句的差异。第一个是传统的group by聚合函数,实现以name维度的聚合,展示客户的购买次数;第二个使用窗口函数,展示明细数据并聚合所有的购买次数(这里没有指定分区,则针对全表);第三个先分组,对分组数据进行聚合,得出聚合的分组数。该sql可以也可写成select distinct name,count(*) over() from shj_2;
脚本1> select name,count(*) from shj_2 group by name order by name;
jack 5
mart 4
neil 2
tony 3
脚本2> select name,count(*) over() from shj_2 order by name;
jack 14
....
jack 14
mart 14
...
tony 14
脚本3> select name,count(*) over() from shj_2 group by name order by name;
jack 4
mart 4
neil 4
tony 4
II、partition by下的序列函数
上面我们说的都是全表的情况,这里我们讨论一下分区的使用。在传统sql中,我们对数据进行除重清洗时会使用到row_number() over(partition by ...order by ...)语句,这其实就是一个窗口函数的应用案例。像row_number()这样的序列函数还有rank() over(partition by ...order by );dense_rank() over(partiton by ... order by ...)【rank:有空位;dense_rank:没有空位】;ntile() over(partition by ... order by ...);这些函数的工作机制:先分区(partition by关键字后的字段),再排序(order by后的字段),然后在分区中进行序列赋值(row_number从1开始赋值,ntile是根据指定字段进行切片,不均匀时增加前面的分组数)
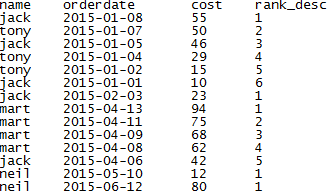
示例:月度的消费排名
select name,orderdate,cost,rank() over(partition by month(orderdate) order by cost desc ) as rank_desc from shj_2;
III、聚合函数+over
前面提到的partition by可以将数据表以指定的分式进行分区,类似于row_number()等函数,我们也可以使用聚合函数(类似有sum/count/avg/),在使用聚合函数时,指定order by与否将影响整个聚合的效果。不指定时,聚合整个分区,指定order by时,则是以order by顺序累加聚合。说明:窗口函数之间是互不影响的。
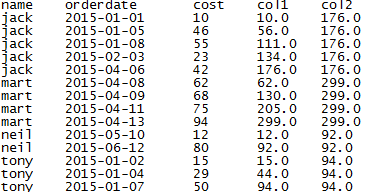
--查看客户月度消费和增加,col1是随着时间增加的累加金额,col2是总金额
select name,orderdate,cost,sum(cost) over(partition by name order by orderdate) as col1,sum(cost) over(partition by name) as col2
from shj_2 order by name, orderdate;
然而,分区函数的粒度还可以更加的细分,这里我们说到window子句,指定聚合的作用范围(分区中的范围)。这里我们需要order by来进行排序,否则无序的数据是毫无意义的。指定范围的关键字有:
PRECEDING:前面行
FOLLOWING:后面行
CURRENT ROW:当前行
UMBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点
这里我使用博客中的脚本和结果
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from shj_2;

IV、常用的窗口函数
lag(var,n[defualt_value]):向后取上第n个数据(lag:有落后的意思)
lead(var,n[defualt_value]):向前取下第n个数据(lead:有领先的意思)
first_value(var):取分组内排序后,截止到当前行,第一个值
last_value(var):取分组内排序后,截止到当前行,最后一个值
select name,orderdate,cost,
lag(cost,1) over(partition by name order by orderdate) as first_lag_cost, --上一次消费金额
lag(cost,2) over(partition by name order by orderdate) as second_lag_cost, --上上一次消费金额
lead(cost,1) over(partition by name order by orderdate) as first_next_cost, --下一次消费金额
lead(cost,2) over(partition by name order by orderdate) as first_next_cost, --下下一次消费金额
first_value(orderdate) over(partition by name order by orderdate) as month_first_buy, --客户首次购买的时间
last_value(orderdate) over(partition by name order by orderdate) as month_last_buy --分组后截止当前行客户最后购买时间
from shj_2;

3、数据倾斜
倾斜的情况接触不多,总结一下我的理解和别人的看法。数据倾斜简单理解就是sql耗时长或在某一个reduce上半天不出结果。我们知道,hive是基于MR任务,如果在MR阶段数据分配不均衡,就会导致倾斜。数据处理时,首先会进行map阶段,对数据进行拆分并执行map函数,后根据partitioner接口,将数据分配到不同的reduce中进行最后的计算。理想情况下,数据均匀分配不会出现倾斜。但是由于partitioner本身是通过hash对key进行取模的特点存在一定问题,以及数据、脚本等原因,导致倾斜。处理数据倾斜,可以从sql、调整参数进行规避。
I、SQL优化
a、Map-Join:在两张表进行关联时,将小表作为驱动表(左边),执行MR时左边的表会被写入缓存中(小表不会出现内存溢出)提升执行效率。方式1/:查询中添加/*+ MAPJOIN(SmallTableNmae)*/进行指定;方式2:设置系统参数自动判断,
set hive.auto.convert.join=true;(自动开户MAPJOIN优化);set hive.mapjoin.smalltable.filesize=10000000;(设置100M时自动启用)
b、进行不适用distinct count;可以替换成group by
c、处理大表时,进行列裁剪(字段选择),fiter操作(where条件限定)来减小任务文件
2、参数设置
a、hive.map.aggr=true;允许map端进行combiner操作(相当于reduce)
b、hive.groupby.skewindata=true;负载均衡,在使用group by时常用;
c、set hive.exec.parallel=true;set hive.exec.parallel.thread.number=16;允许并发,及最大并发数
d、还有一些不怎么用,如合并小文件、设置bitmap index
3、数据处理
a、主要对null值进行处理,设置为字符常量加随机数或在filter操作时限定
b、建表时,合理设置分区以及字段类型
原创博客,转载请注明出处!欢迎邮件沟通:shj8319@sina.com
hive(II)--sql考查的高频问题的更多相关文章
- 别只用hive写sql -- hive的更多技能
hive是Apache的一个顶级项目,由facebook团队开发,基于java开发出面向分析师或BI等人员的数据工具(常用作出具仓库),它将文件系统映射为表,使用SQL实现mapreduce任务完成分 ...
- 【HIVE】sql语句转换成mapreduce
1.hive是什么? 2.MapReduce框架实现SQL基本操作的原理是什么? 3.Hive怎样实现SQL的词法和语法解析? 连接:http://www.aboutyun.com/thread-20 ...
- Hive执行sql文件
方法1: hive -f sql文件 t.sql文件内容: ; 执行命令 hive -f t.sql 方法2: 进入hive shell, 执行source命令 进入hive 终端 $ hive hi ...
- [Spark][Hive][Python][SQL]Spark 读取Hive表的小例子
[Spark][Hive][Python][SQL]Spark 读取Hive表的小例子$ cat customers.txt 1 Ali us 2 Bsb ca 3 Carls mx $ hive h ...
- Hive将SQL转化为MapReduce的过程
Hive将SQL转化为MapReduce的过程: Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree 遍历AST Tree,抽象出查询的基本组成单元Qu ...
- hive Hbase sql
Hive和HBase的区别 hive是为了简化编写MapReduce程序而生的,使用MapReduce做过数据分析的人都知道,很多分析程序除业务逻辑不同外,程序流程基本一样.在这种情况下,就需要h ...
- Hadoop Hive基础sql语法
目录 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的 ...
- [Hive - LanguageManual ] ]SQL Standard Based Hive Authorization
Status of Hive Authorization before Hive 0.13 SQL Standards Based Hive Authorization (New in Hive 0. ...
- hive中sql解析出对应表和字段的调查
---恢复内容开始--- .阿里的druid中的sql parser有各种关系数据库sql的解析,但hive的不支持. druid初期的版本中是包含hive的,将以前版本中的hive dialect对 ...
随机推荐
- robotframework学习笔记(七)------筛选执行用例
第一种:手动勾选用例 可勾选用户,然后点击运行,这样就只运行到勾选的用例.如果不勾选的点击运行就会运行所有用例. 第二种 菜单中去筛选 可在菜单中去筛选勾用例,然后点击运行 Select All Te ...
- 如何用Python在豆瓣中获取自己喜欢的TOP N电影信息
一.什么是 Python Python (蟒蛇)是一门简单易学. 优雅健壮. 功能强大. 面向对象的解释型脚本语言.具有 20+ 年发展历史, 成熟稳定. 具有丰富和强大的类库支持日常应用. 1989 ...
- SpringCloud学习笔记(5)——Config
参考Spring Cloud官方文档第4~10章 官网文档中所有示例中的配置都在git上 https://github.com/spring-cloud-samples/config-repo Par ...
- SP3精密星历简介
IGS精密星历采用sp3格式,其存储方式为ASCII文本文件,内容包括表头信息以及文件体,文件体中每隔15 min给出1个卫星的位置,有时还给出卫星的速度.它的特点就是提供卫星精确的轨道位置.采样率为 ...
- 在webstorm开发微信小程序之使用阿里自定义字体图标
1.下载阿里图标,解压出来之后有个.css文件 然后复制这css里面的所有代码 2.新建一个wxss文件,例如我新建的就是iconfont.wxss,然后把刚才复制的所有代码,复制到这个文件里面去. ...
- 【eclipse】Target runtime Apache Tomcat v7.0 is not defined解决
在eclipse中导入项目时提示Target runtime Apache Tomcat v7.0 is not defined, 解决方法:右键项目--properties--targeted ru ...
- IdentityServer(11)- 使用Hybrid Flow并添加API访问控制
关于Hybrid Flow 和 implicit flow 我在前一篇文章使用OpenID Connect添加用户认证中提到了implicit flow,那么它们是什么呢,它和Hybrid Flow有 ...
- CentOS上安装RabbitMQ
所需环境 操作系统:Centos服务一台 网络环境:可以访问公网 安装Erlang RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python.Ruby ...
- re 模块 正则表达式
re模块(正则表达式) 一.什么是正则表达式 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法.或者说:正则就是用来描述一类事物的规则.(在Python中)它 ...
- java.io.FileNotFoundException class path resource [xxx.xml] cannot be opened
没有找到xxx.xml,首先确定你项目里有这个文件吗,如果没有请添加,或者你已经存在配置文件,只是名字不是xxx.xml,请改正名字.此外还要注意最好把xxx.xml加入到classpath里,就是放 ...