ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路
ItemCF_基于物品的协同过滤
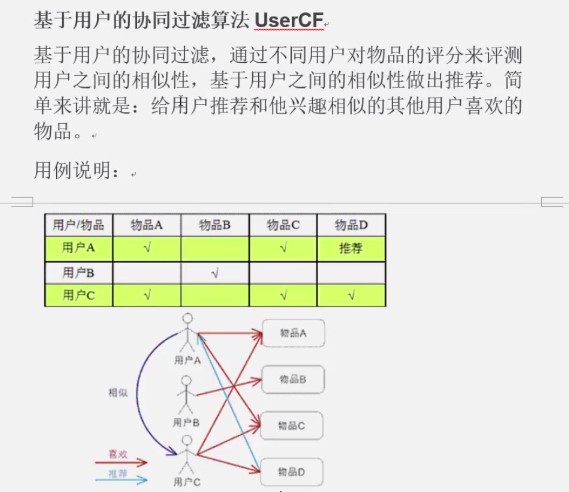
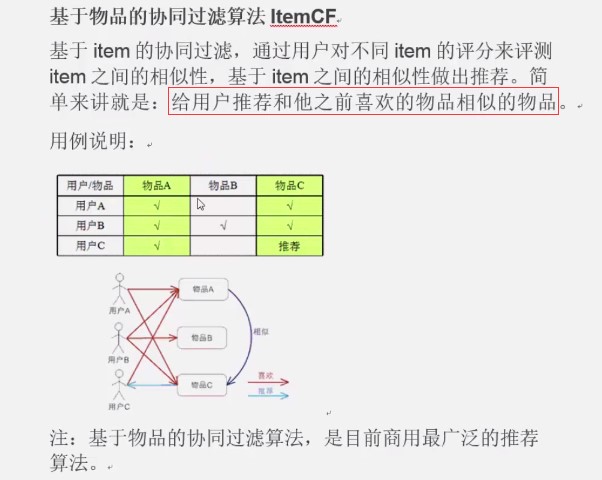
1. 概念

2. 原理
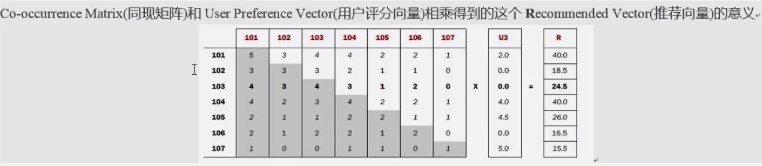

3. java代码实现思路
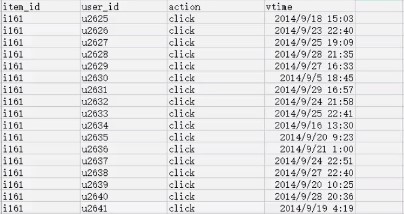
六个MapReduce
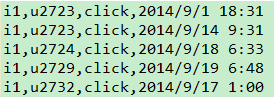
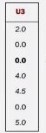
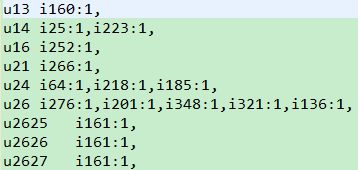
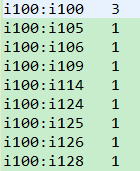
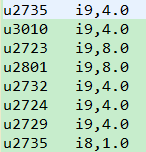
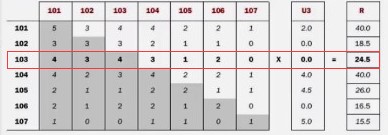


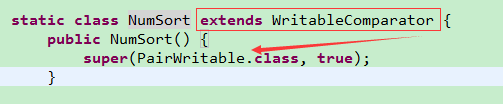
PairWritable,

ItemCF_基于物品的协同过滤_MapReduceJava代码实现思路的更多相关文章
- ItemCF_基于物品的协同过滤
ItemCF_基于物品的协同过滤 1. 概念 2. 原理 如何给用户推荐? 给用户推荐他没有买过的物品--103 3. java代码实现思路 数据集: 第一步:构建物品的同现矩阵 第 ...
- 转】Mahout分步式程序开发 基于物品的协同过滤ItemCF
原博文出自于: http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ 感谢! Posted: Oct 14, 2013 Tags: Hadoopite ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- Mahout分步式程序开发 基于物品的协同过滤ItemCF
http://blog.fens.me/hadoop-mahout-mapreduce-itemcf/ Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
- Spark 基于物品的协同过滤算法实现
J由于 Spark MLlib 中协同过滤算法只提供了基于模型的协同过滤算法,在网上也没有找到有很好的实现,所以尝试自己实现基于物品的协同过滤算法(使用余弦相似度距离) 算法介绍 基于物品的协同过滤算 ...
- 基于物品的协同过滤算法(ItemCF)
最近在学习使用阿里云的推荐引擎时,在使用的过程中用到很多推荐算法,所以就研究了一下,这里主要介绍一种推荐算法—基于物品的协同过滤算法.ItemCF算法不是根据物品内容的属性计算物品之间的相似度,而是通 ...
- 基于物品的协同过滤ItemCF的mapreduce实现
文章的UML图比较好看..... 原文链接:www.cnblogs.com/anny-1980/articles/3519555.html 基于物品的协同过滤ItemCF 数据集字段: 1. Use ...
随机推荐
- 在亚马逊linux环境上装mysql+添加启动项
安装mysql sudo yum install mysql sudo yum install mysql-server sudo yum install mysql-devel 添加到系统启动项su ...
- ASP.NET Core MVC中的 [Required]与[BindRequired]
在开发ASP.NET Core MVC应用程序时,需要对控制器中的模型校验数据有效性,元数据注释(Data Annotations)是一个完美的解决方案. 元数据注释最典型例子是确保API的调用者提供 ...
- ntopng 推送solr
1.修改代码在且不说 2.修改完之后先卸载原先的ntopng 使用 whereis ntopng 找到安装目录,然后删除 /usr/local/bin/ntopng /usr/local/share/ ...
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
- Selectize使用总结
一.简介 Selectize是一个可扩展的基于jQuery 的自定义下拉框的UI控件.它对展示标签.联系人列表.国家选择器等比较有用.它的大小在~ 7kb(gzip压缩)左右.提供一个可靠且体验良好的 ...
- 从开源项目看python代码注释
最近看了不少代码,也写了不少代码,所以在看和写之间发现了很多的问题,真的是很多,至少从我的认识来看,有几个地方有很大的改进空间,这里不准备把所有的问题都列举出来,所以就先挑选一个比较明显得来和大家聊聊 ...
- CSS 鼠标样式大全
cursor是CSS中用于定义鼠标在元素标签上的显示样式,如常用的手型鼠标样式 cursor: pointer; 也可以通过url网址指定扩展名一般为.cur的鼠标图片文件. 名称 属性代码 描述 默 ...
- [Micropython]TPYBoardV102 Dfu固件烧写教程
TPYBoardv10x固件烧写一直是大家比较关心的问题,上次教大家用SWD接口烧写TPYBoard的固件,这次教大家用另一种方式烧写我们TPYBoardv10x的固件,直接用dfu模式烧写固件. 用 ...
- Anaconda使用
转自PeterYuan 序 Python易用,但用好却不易,其中比较头疼的就是包管理和Python不同版本的问题,特别是当你使用Windows的时候.为了解决这些问题,有不少发行版的Python, ...
- 微信小程序实现简易留言板
微信小程序现在很火,于是也就玩玩,做了一个简易的留言板,让大家看看,你们会说no picture you say a j8 a,好吧先上图. 样子就是的,功能一目了然,下面我们就贴实现的代码,首先是H ...