Spark_总结一
Spark_总结一
1.Spark介绍
2.Spark运行模式(四种 )
| Local | 多用于测试 |
| Standalone | Spark自带的资源调度器(默认情况下就跑在这里面) |
| MeSOS | 资源调度器,同Hadoop中的YARN |
| YARN | 最具前景,公司里大部分都是 Spark on YRAN |
3.Spark内核之RDD的五大特性
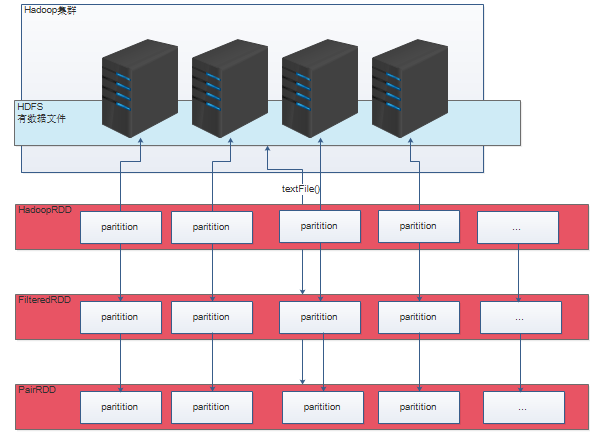
4.Spark运行机制
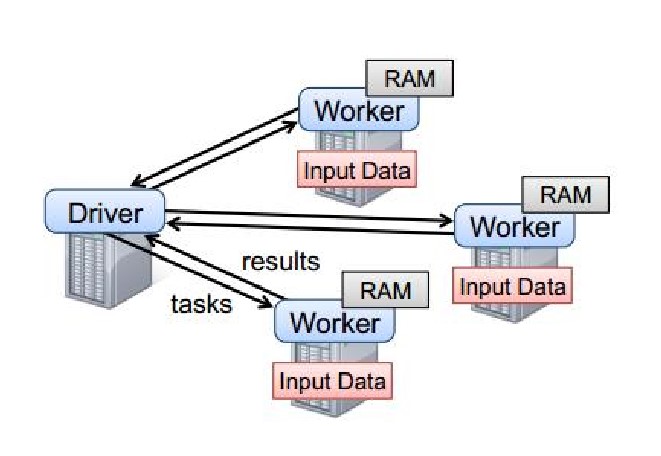
5.Spark运行时
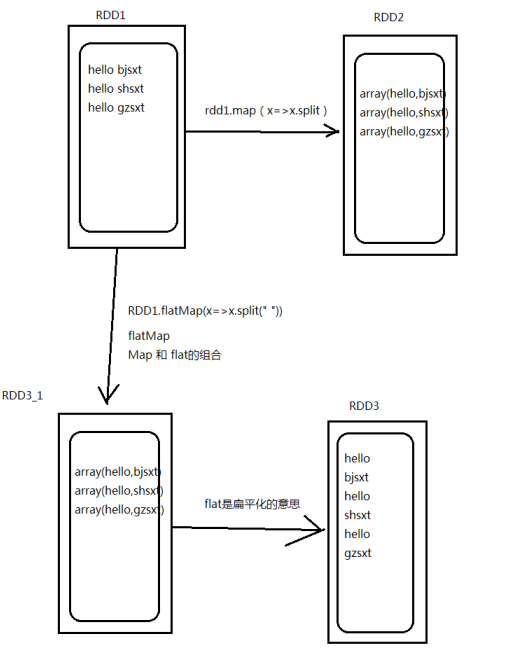
6.Spark算子--Transformations || Actions
|
Transformations || Actions 这两类算子的区别
|
||
|
Transformations
|
Transformations类的算子会返回一个新的RDD,懒执行 | |
|
Actions
|
Actions类的算子会返回基本类型或者一个集合,能够触发一个job的 执行,代码里面有多少个action类算子,那么就有多少个job | |
| Transformation类算子 | map | 输入一条,输出一条 将原来 RDD 的每个数据项通过 map 中的用户自定义函数映射转变为一个新的 元素。输入一条输出一条; |
| flatMap | 输入一条输出多条 先进行map后进行flat |
|
| mapPartitions | 与 map 函数类似,只不过映射函数的参数由 RDD 中的每一个元素变成了 RDD 中每一个分区的迭代器。将 RDD 中的所有数据通过 JDBC 连接写入数据库,如果使 用 map 函数,可能要为每一个元素都创建一个 connection,这样开销很大,如果使用 mapPartitions,那么只需要针对每一个分区建立一个 connection。 | |
| mapPartitionsWithIndex | ||
| filter | 依据条件过滤的算子 | |
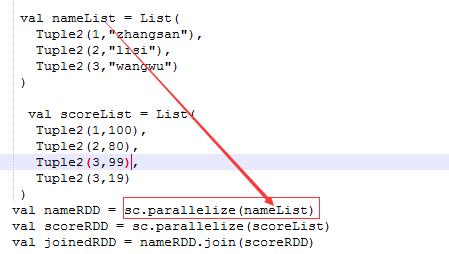
| join | 聚合类的函数,会产生shuffle,必须作用在KV格式的数据上 join 是将两个 RDD 按照 Key 相同做一次聚合;而 leftouterjoin 是依 据左边的 RDD 的 Key 进行聚 |
|
| union | 不会进行数据的传输,只不过将这两个的RDD标识一下 (代表属于一个RDD) |
|
| reduceByKey | 先分组groupByKey,后聚合根据传入的匿名函数聚合,适合在 map 端进行 combiner | |
| sortByKey | 依据 Key 进行排序,默认升序,参数设为 false 为降序 | |
| mapToPair | 进行一次 map 操作,然后返回一个键值对的 RDD。(所有的带 Pair 的算子返回值均为键值对) | |
| sortBy | 根据后面设置的参数排序 | |
| distinct | 对这个 RDD 的元素或对象进行去重操作 | |
| Actions类算子 | foreach | foreach 对 RDD 中的每个元素都应用函数操作,传入一条处理一条数据,返回值为空 |
| collect | 返回一个集合(RDD[T] => Seq[T]) collect 相当于 toArray, collect 将分布式的 RDD 返回为一个单机的 Array 数组。 |
|
| count | 一个 action 算子,计数功能,返回一个 Long 类型的对象 | |
| take(n) | 取前N条数据 | |
| save | 将RDD的数据存入磁盘或者HDFS | |
| reduce | 返回T和原来的类型一致(RDD[T] => T) | |
| foreachPartition | foreachPartition 也是根据传入的 function 进行处理,但不 同处在于 function 的传入参数是一个 partition 对应数据的 iterator,而不是直接使用 iterator 的 foreach。 |
7.Spark中WordCount演变流程图_Scala和Java代码
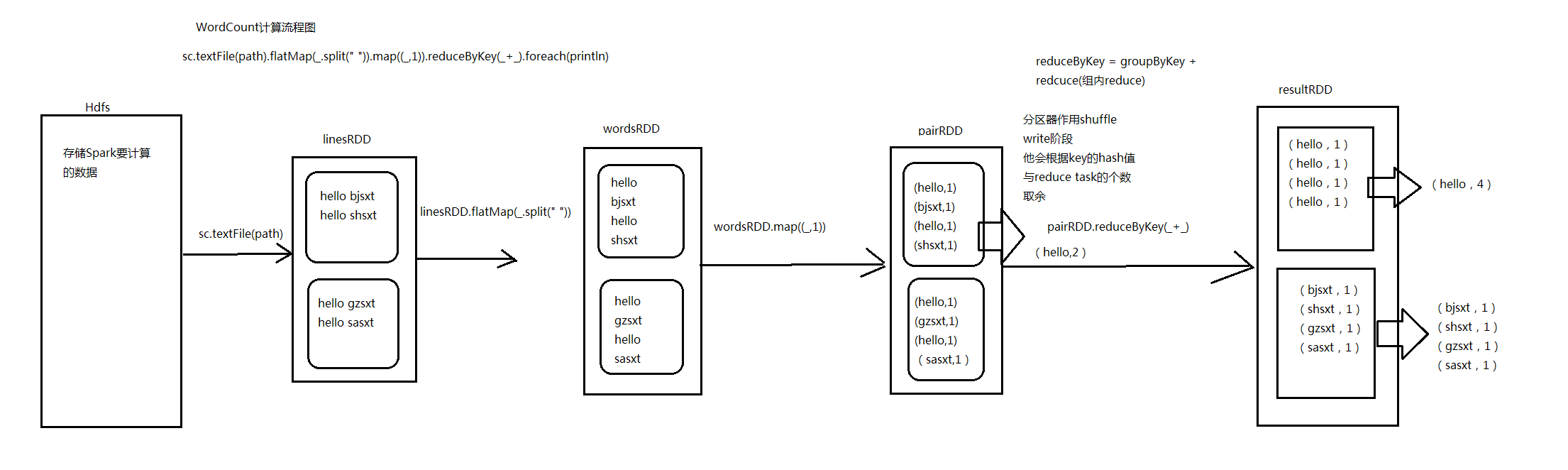
package com.hzf.spark.exerciseimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/*** 统计每一个单词出现的次数*/object WordCount{def main(args:Array[String]):Unit={/*** 设置Spark运行时候环境参数 ,可以在SparkConf对象里面设置* 我这个应用程序使用多少资源 appname 运行模式*/val conf =newSparkConf().setAppName("WordCount").setMaster("local")/*** 创建Spark的上下文 SparkContext** SparkContext是通往集群的唯一通道。* Driver*/val sc =newSparkContext(conf)//将文本中数据加载到linesRDD中val linesRDD = sc.textFile("userLog")//对linesRDD中每一行数据进行切割val wordsRDD = linesRDD.flatMap(_.split(" "))val pairRDD = wordsRDD.map{(_,1)}/*** reduceByKey是一个聚合类的算子,实际上是由两步组成** 1、groupByKey* 2、recuce*/val resultRDD = pairRDD.reduceByKey(_+_)/*(you,2)(Hello,2)(B,2)(a,1)(SQL,2)(A,3)(how,2)(core,2)(apple,1)(H,1)(C,1)(E,1)(what,2)(D,2)(world,2)*/resultRDD.foreach(println)/*(Spark,5)(A,3)(are,2)(you,2)(Hello,2)*/val sortRDD = resultRDD.map(x=>(x._2,x._1))val topN = sortRDD.sortByKey(false).map(x=>(x._2,x._1)).take(5)topN.foreach(println)}}

Spark_总结一的更多相关文章
- Spark_总结四
Spark_总结四 1.Spark SQL Spark SQL 和 Hive on Spark 两者的区别? spark on hive:hive只是作为元数据存储的角色,解析 ...
- Spark_总结五
Spark_总结五 1.Storm 和 SparkStreaming区别 Storm 纯实时的流式处理,来一条数据就立即进行处理 SparkStreaming ...
- Spark_总结七_troubleshooting
转载标明出处 http://www.cnblogs.com/haozhengfei/p/07ef4bda071b1519f404f26503fcba44.html Spark_总结七_troubles ...
- 创建spark_读取数据
在2.0版本之前,使用Spark必须先创建SparkConf和SparkContext,不过在Spark2.0中只要创建一个SparkSession就够了,SparkConf.SparkContext ...
- Spark_安装配置_运行模式
一.Spark支持的安装模式: 1.伪分布式(一台机器即可) 2.全分布式(至少需要3台机器) 二.Spark的安装配置 1.准备工作 安装Linux和JDK1.8 配置Linux:关闭防火墙.主机名 ...
- spark_运行spark-shell报错_javax.jdo.JDOFatalDataStoreException: Unable to open a test connection to the given database.
error: # ./spark-shell Caused by: javax.jdo.JDOFatalDataStoreException: Unable to open a test connec ...
- Scala 中object和class的区别
Scala中没有静态类型,但是有有“伴侣对象”,起到类似的作用. Scala中类对象中不可有静态变量和静态方法,但是提供了“伴侣对象”的功能:在和类的同一个文件中定义同名的Object对象:(须在同一 ...
- 【原创】大数据基础之Benchmark(2)TPC-DS
tpc 官方:http://www.tpc.org/ 一 简介 The TPC is a non-profit corporation founded to define transaction pr ...
- Spark-Streaming总结
文章出处:http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html Spark_总结五 1.Storm 和 ...
随机推荐
- Java NIO (一) 初识NIO
Java NIO(New IO / Non-Blocking IO)是从JDK 1.4版本开始引入的IO API , 可以替代标准的Java IO API .NIO与原来标准IO有同样的作用和目的,但 ...
- Golang 网络爬虫框架gocolly/colly 二 jQuery selector
Golang 网络爬虫框架gocolly/colly 二 jQuery selector colly框架依赖goquery库,goquery将jQuery的语法和特性引入到了go语言中.如果要灵活自如 ...
- js数组操作-添加,删除
js 数组操作常用方法. push():在数组后面加入元素,并返回数组的长度 unshift():在数组前面加入元素,并返回数组的长度 pop()删除最后一个元素 shift()删除第一个元素 var ...
- Java基础之引用(String,char[],Integer)总结
1.String的引用: 下列代码执行后的结果为: public class Test { public static void main(String[] args) { StringBuffer ...
- 4、公司经营的业务来源 - CEO之公司管理经验谈
公司经营的业务来源为公司的运作资金提供了帮助,一般来说,整个公司的领导层为公司的经营做管理,而业务员就为公司的业务提供来源,然后建设部为业务开展做建设. 一.总经理: 公司的总经理主要负责公司运作经营 ...
- PHP 判断Header 送出前, 是否有值被送出去: headers_sent()
1 为避免header()函数是,出现 <b>Warning</b>: Cannot modify header information - headers already ...
- APP开发选择什么框架好? 请看这里!
背景 App的开发一般都需要满足Android和iOS两个系统环境,也就意味着一个App需要定制两套实现方案,造成开发成本和维护成本都很高.为了解决这个问题,最好的办法就是实现一套代码跨端运行,所以H ...
- 阿里云EMR集群初始化后的开发准备工作
前言:EMR的集群使用越来越普遍,但是每一次的集群释放到集群的重新创建,期间总有一些反复的工作需要查询与配置.为方便后续工作查阅,现在对集群初始化后的工作进行大概的梳理如下. ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
- Android 根据字符串动态获取资源ID
1.常用方法public int getResId(String name,Context context){ Resources r = context.getResources(); int id ...