不吹不黑,赞一下应用运维管理的cassacdra
不吹不黑的为菊厂的应用运维管理AOM点个赞。Why?
某菊厂应用运维管理工具AOM每天处理着亿级条数据,这么多数据是怎么存储的呢?
说到数据存储就会想到关系型数据库,比如mysql,oracle,sybase。关系型数据库有自己的优势,数据强一致性,支持事务,通用,技术成熟。但是对于大批量数据的存储和查询就稍显吃力,毕竟AOM每秒的写入数据至少都是上万条,甚至是十几万条,随着系统规模增长,数据库的扩容也成为新的瓶颈。
AOM的数据存储系统使用的是非关系型数据库-----cassandra,相比关系型数据库,cassandra拥有高并发,大数据下读写能力强,支持分布式,易扩展等优点,当前也有最致命的缺点,不支持事务,不过对于事务我们可以通过zk/etcd等其他组件协助完成。
对于关系型数据库相比非关系型数据库为什么会有这么大的差异,这个就得从两者的架构上来讲了,下面编者以mysql和cassandra进行对比分析。
不管是mysql还是cassandra,最终数据的存储都要落盘,我们先来看下磁盘的写入原理:

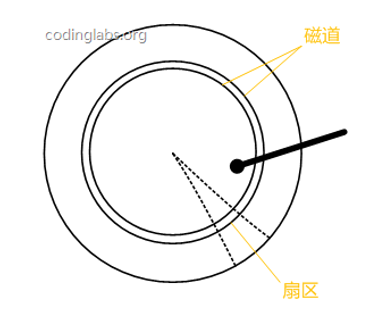
磁盘的基本组件可分为以下几部分:磁头,盘片,盘面,磁道,柱面,扇区等。
盘片被划分成一系列同心环,圆心是盘片中心,每个同心环叫做一个磁道,所有半径相同的磁道组成一个柱面。磁道被沿半径线划分成一个个小的段,每个段叫做一个扇区,每个扇区是磁盘的最小存储单元。当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘 旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
即一次访盘请求(读/写)完成过程由三个动作组成:
1)寻道(时间):磁头移动定位到指定磁道
2)旋转延迟(时间):等待指定扇区从磁头下旋转经过
3)数据传输(时间):数据在磁盘与内存之间的实际传输
大家应该有过类似的经历,进行数据拷贝时,文件个数越少,单个文件越大,拷贝的速率越快,反之文件个数多,单个文件小,拷贝的速率越慢,这其中的原因就是因为在拷贝小文件时,系统的耗时基本都耗费在寻址上了。Cassandra相比mysql有更高的写入能力,就是因为cassandra采用了更高效的写入机制,该机制大大缩短了磁盘的寻址时间(准确来讲应该是寻址次数)。
我们先来看下Mysql(InnoDB)的索引原理, InnoDB的索引采用B+树,其数据结构如下所示:

所有的数据都存储在叶子节点,叶子节点之间都有指针,这是为了做范围遍历。B+树的优势在于快速索引,B+树的层高基本都在2~3层,也就意味着一次数据查找只需要2~3次IO操作。而且每次的单条数据都非常稳定,耗时和查找次数都差不多。B+树最大的性能问题是会产生大量的随机IO,随着数据的插入,叶子节点会慢慢分裂,逻辑上连续的节点物理上确不连续,甚至相隔甚远,顺序遍历的时候,会产生大量的随机IO操作。这正如大家熟知的ArrayList和LinkedList,ArrayList在内存中是一块连续的内存,访问的时候顺序访问,LinkedList是多个内存块通过指针串联起来的,访问的时候必须先通过指针获取下一个内存块的地址,然后再通过地址访问,因此ArrayList的访问远远高于LinkedList。B+树的叶子节点就类似一个LinkedList,随着叶子节点的分裂,在做顺序检索时,跨叶子节点的访问往往需要先找到下一个叶子节点的地址(磁盘寻址),然后才能访问到具体的叶子节点。
B+树的顺序检索会产生大量的随机IO,B+树的写入同样会产生类似的问题,比如上图B+树中的9和86,它们所属的叶子节点在磁盘上相隔甚远,数据插入时就会产生两次随机写入。当大批量数据写入时,随机IO操作的次数也就更多。
如下是一张随机读写和顺序读写的性能比对图:
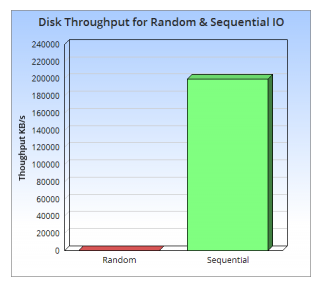
从上图可以直观的感受到随机读写与顺序读写的差异,这两者完全不在一个量级。用过kafka和HDFS的开发者就会发现kafka和HDFS的磁盘IO使用率非常高,有时甚至接近磁盘的最大写入速率,这个就是因为kafka和HDFS是基于文件的顺序写入(当然还有其他技术)。从以上分析来看,磁盘的随机读取/写入是影响mysql顺序检索和批量写入的最大因素,那我们有没有办法减少这种随机写入呢,此时LSM-Tree(Log-Structured Merge-Tree)呼之欲出。
2006年,google发表了BigTable的论文。BigTable的数据结构就采用了LSM(http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf)。目前LSM被很多数据库作为存储结构,比如HBase,Cassandra,LevelDB。LSM抛弃了大多数数据库使用的传统文件组织方法,通过减少更新/写入操作带来的随机操作次数来提高数据的写入能力。
LSM Tree的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在磁盘中,等到积累到一定数目之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾(因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
LSM的核心思路可以分为两部分:
①、数据先写入内存
②、将内存中的数据排序后追加到磁盘队尾。
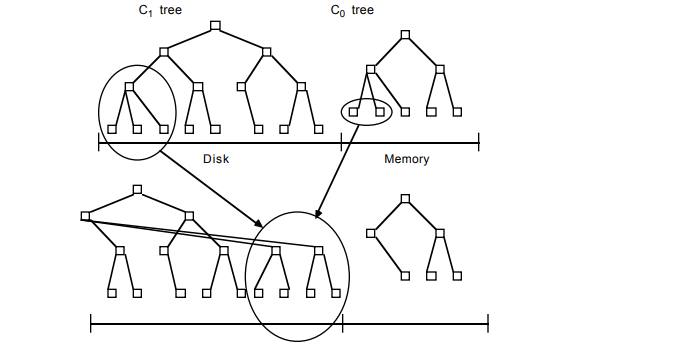
LSM由两个或两个以上的存储结构组成。最简单的LSM由两部分组成,一部分常驻内存,称为C0;另一部分存储在硬盘上,称为C1。
数据写入时,先记录到本地的操作日志文件(HLog或CommitLog),为将来做数据恢复使用。然后将数据写入到C0中,由于C0使用的是内存,因此插入性能远远高于磁盘写入。当C0的节点数目超过一定阈值时,会将C0中的数据进行一次排序,然后追加到C1树中。
多部件的LSM就是包含多个存储结构:
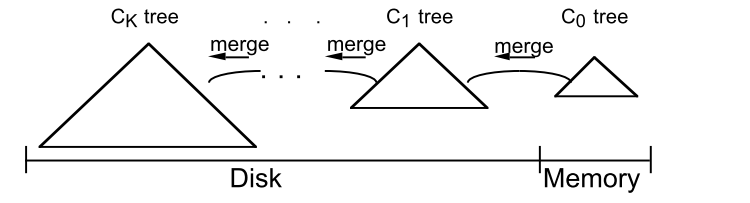
随着数据规模增加,C0中的数据超过阈值后就会往磁盘中写入一个新的file,这样磁盘中的树(file)会越来越多。当较小的Ci-1个数超过一定阈值的时候,会进行Ci-1和Ci的合并。合并是为了减少整个C树的个数,加快搜索速度。
数据查询的时候,会按照树的生成时间按照从新到旧的顺序逐个遍历每个C树,即C0,C1,C2….Ck。为什么要按照时间顺序从最近往之前遍历呢,这就是LSM的另一个巧妙点(更新/删除)。
LSM的更新和删除操作都是往C0上新增一条记录,通过新记录+标记的方式完成,因此在遍历的时候必须按照时间顺序进行遍历,这样就可以保证数据更新和删除的正确性,同时保证了数据的顺序写入。当前LSM在进行C树合并时,会对删除和更新记录进行合并。
我们来看下HBase的整个架构图:

HBase是基于HDFS之上采用LSM结构做的数据存储。HBase的主要部件可以分为如下几类:
storeFile:小文件,不可编辑。即写入到磁盘中的C树。
Hlog:LSM中用于记录写入记录的操作日志,为了将来做数据恢复使用,毕竟C0中的数据是在内存中存储,当HBase宕机后,内存中的数据就会丢失,此时需要从Hlog中恢复。
Memstore:即C0树。至此,LSM和B+树的对比也就讲完了。
不吹不黑,赞一下应用运维管理的cassacdra的更多相关文章
- 有赞MySQL自动化运维之路—ZanDB
有赞MySQL自动化运维之路—ZanDB 一.前言 在互联网时代,业务规模常常出现爆发式的增长.快速的实例交付,数据库优化以及备份管理等任务都对DBA产生了更高的要求,单纯的凭借记忆力去管理那几十 ...
- 企业该如何进行高效IT运维管理
企业该如何进行高效IT运维管理 在企业内部也是一样,当大量的生产和经营数据集中在数据中心,一旦人们与数据中心因为IT故障而失去联系,停滞的也许不是个人应用受阻这样简单的后果.我们谁也不想看到自己企业的 ...
- 系统批量运维管理器Fabric详解
系统批量运维管理器Fabric详解 Fabrici 是基于python现实的SSH命令行工具,简化了SSH的应用程序部署及系统管理任务,它提供了系统基础的操作组件,可以实现本地或远程shell命令,包 ...
- 有赞 MySQL 自动化运维之路 — ZanDB
转自:https://tech.youzan.com/youzan-mysql-auto-ops-road/ 一.前言 在互联网时代,业务规模常常出现爆发式的增长.快速的实例交付,数据库优化以及备份管 ...
- 谈谈我的windows服务器运维管理
我们开发的页游General War(http://gw.gamebox.com)上线运营也有半年多了,服务器的开发到运维基本都由我一手包办,在服务器上线之后我们又招了一个程序员接手后续功能的开发,而 ...
- IT服务(运维)管理实施的几个要点--第一章 IT服务质量的标准
子曰"干的最好就是个60分,稍有纰漏就是不及格" 谈一个事情,最先要谈的就是统一标准,又或者这个标准已经约定俗成,广泛认可,所以就可以略过.对于IT服务质量来说,确实有一个统一的标 ...
- IT服务(运维)管理实施的几个要点--序言
IT服务(运维)管理(不是IT运维技术)是IT行业当中相对比较"窄"的一个分支,通常只被金融.电信等大型数据中心的中高层管理人员所关注.但是根据笔者多年从事IT服务和服务管理的经验 ...
- zk日常运维管理
清理数据目录 dataDir目录指定了ZK的数据目录,用于存储ZK的快照文件(snapshot).另外,默认情况下,ZK的事务日志也会存储在这个目录中.在完成若干次事务日志之后(在ZK中,凡是对数据有 ...
- 使用Ansible实现数据中心自动化运维管理
长久以来,IT 运维在企业内部一直是个耗人耗力的事情.随着虚拟化的大量应用.私有云.容器的不断普及,数据中心内部的压力愈发增加.传统的自动化工具,往往是面向于数据中心特定的一类对象,例如操作系统.虚拟 ...
随机推荐
- Jenkins+Ant+Git+Jmeter接口自动化
一.服务器分别安装JKD.Jenkins.Ant.Git.Jmeter 1.JKD安装参考:https://www.cnblogs.com/xiaoxitest/p/6168045.html 2.Je ...
- Hdu5178
Hdu5178 题意: 题目给你N个点,问有多少对点的长度小于K . 解法: 首先将所给的坐标从大到小排序,则此题转化为:对排序后的新数列,对每个左边的\(x_a\)找到它右边最远的 $ x_b $ ...
- easyui复选框实现单选框
$(':checkbox[name=primary_key_flag]').each(function(){ $(this).click(function(){ if(this.checked){ $ ...
- Js 中那些 隐式转换
曾经看到过这样一个代码: (!(~+[])+{})[--[~+""][+[]]*[~+[]]+~~!+[]]+({}+[])[[~!+[]*~+[]]] = sb , 你敢相信, ...
- tomcat 启动报错org.apache.catalina.LifecycleException: Failed to start component [StandardEngine[Catalina].StandardHost[localhost].xxx
今天在写完一个非常简单的servlet页面跳转的web项目后,启动tomcat报错org.apache.catalina.LifecycleException: Failed to start com ...
- MYSQL数据库基础概念
数据库的发展史 1.萌芽阶段:文件系统 使用磁盘文件来存储数据2.初级阶段:第一代数据库 出现了网状模型.层次模型的数据库3.中级阶段:第二代数据库 关系型数据库和结构化查询语言4.高级阶段:新一代数 ...
- onNewIntent
当Activity不是Standard模式,并且被复用的时候,会触发onNewIntent(Intent intent) 这个方法,一般用来获取新的Intent传递的数据 我们一般会把MainAcit ...
- 阶段5 3.微服务项目【学成在线】_day03 CMS页面管理开发_08-新增页面-前端-Api调用
表单数据提交到后台 export const page_add = paramas => { return http.requestPost(apiUrl+'/cms/page/add',par ...
- springboot动态定时任务
SpringBoot设置动态定时任务 一.说明 1.在我们日常的开发中,很多时候,定时任务都不是写死的,而是写到数据库中,从而实现定时任务的动态配置. 2.定时任务执行时间可根据数据库中某个设置字段动 ...
- 安装完 MySQL 后必须调整的 10 项配置(转)
当我们被人雇来监测MySQL性能时,人们希望我们能够检视一下MySQL配置然后给出一些提高建议.许多人在事后都非常惊讶,因为我们建议他们仅仅改动几个设置,即使是这里有好几百个配置项.这篇文章的目的在于 ...