编码方式之ASCII、ANSI、Unicode概述
1、ASCII
ASCII全称(American Standard Code for Information Interchange)美国信息交换标准代码,在计算机内部中8位二进制位组成1个字节(8(比特)bit=1(字节)byte),而ASCII的编码方式是把一个字节中的低7位用来编码,
最高位也就是第8位留着不用(最高位一般为0,但有时也被用作一些通讯系统的奇偶校验位),从0x00一直编码到0x7f(0000 0000 到 0111 1111),一共128个字符
2、ANSI
ANSI全称(American National Standard Institite)美国国家标准学会(美国的一个非营利组织),首先ANSI不是指的一种特定的编码,而是不同地区扩展编码方式的统称,各个国家和地区所独立制定的兼容ASCII
但互相不兼容的字符编码,微软统称为ANSI编码

(GBK是在国家标准GB2312基础上进行了扩容,包含的字符更多)
补充:在windows下输入命令行的黑框下,右键再点击属性可以看到当前的编码方式和代码页
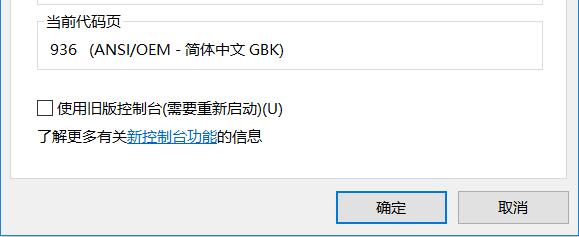
代码页也称为“内码表”,是与特定语言的字符集相对应的一张表。操作系统中不同的语言和区域设置可能使用不同的代码页(代码页一般与其所直接对应的字符集之间并非完全等同,往往因为种种原因
(比如标准跟不上现实实践的需要)而会对字符集有所扩展)
3、Unicode
Unicode 是一套字符集,而不是一套字符编码,严格来说,字符集和字符编码不是一个概念:
1、字符集定义了字符和二进制的对应关系,为每个字符分配了唯一的编号。可以将字符集理解成一个很大的表格,它列出了所有字符和二进制的对应关系,计算机显示文字或者存储文字,就是一个查表的过程。
2、而字符编码规定了如何将字符的编号存储到计算机中,如果使用了类似 GB2312 和 GBK 的变长存储方案(不同的字符占用的字节数不一样),那么为了区分一个字符到底使用了几个字节,就不能将字符的编号
直接存储到计算机中,字符编号在存储之前必须要经过转换,在读取时还要再逆向转换一次,这套转换方案就叫做字符编码。
有的字符集在制定时就考虑到了编码的问题,是和编码结合在一起的,例如 ASCII、GB2312、GBK、BIG5 等,所以无论称作字符集还是字符编码都无所谓,也不好区分两者的概念。而有的字符集只管制定字符的编号,
至于怎么存储,那是字符编码的事情,Unicode 就是一个典型的例子,它只是定义了全球文字的唯一编号,我们还需要 UTF-8、UTF-16、UTF-32 这几种编码方案将 Unicode 存储到计算机中。
(有兴趣的读取可以转到 https://unicode-table.com/cn/ 查看 Unicode 包含的所有字符,以及各个国家的字符是如何分布的)
1、UTF-8
编码方式:
1、如果只有一个字节,那么最高的比特位为 0,这样可以兼容 ASCII;
2、如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
(对于常用的字符,它的 Unicode 编号范围是 0 ~ FFFF,用 1~3 个字节足以存储,只有及其罕见,或者只有少数地区使用的字符才需要 4~6个字节存储)
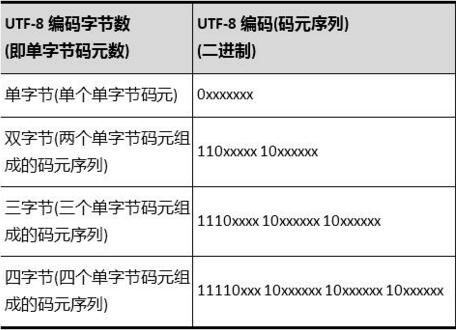
具体的表现形式为:
- 0xxxxxxx:单字节编码形式,这和 ASCII 编码完全一样,因此 UTF-8 是兼容 ASCII 的;
- 110xxxxx 10xxxxxx:双字节编码形式(第一个字节有两个连续的 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(第一个字节有三个连续的 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(第一个字节有四个连续的 1)
下面是具体的 Unicode 编号范围与对应的 UTF-8 二进制格式

单字节可编码的Unicode码点值范围十六进制为0x0000 ~ 0x007F,十进制为0 ~ 127;
双字节可编码的Unicode码点值范围十六进制为0x0080 ~ 0x07FF,十进制为128 ~ 2047;
三字节可编码的Unicode码点值范围十六进制为0x0800 ~ 0xFFFF,十进制为2048 ~ 65535;
四字节可编码的Unicode码点值范围十六进制为0x10000 ~ 0x1FFFFF,十进制为65536 ~ 2097151
上述的编号范围几个临界值(127、2047、65535、2097151)的计算方式:
对于单字节来说除了前缀码0,有效位数为7位,(2^7-1=127)
对于双字节来说除了前缀码110和10,有效位数为16-5=11位(2^11-1=2047)
剩下的三字节和四字节就是24-8=16位(2^16-1=65535)、32-11=21位(2^21-1=2097151)
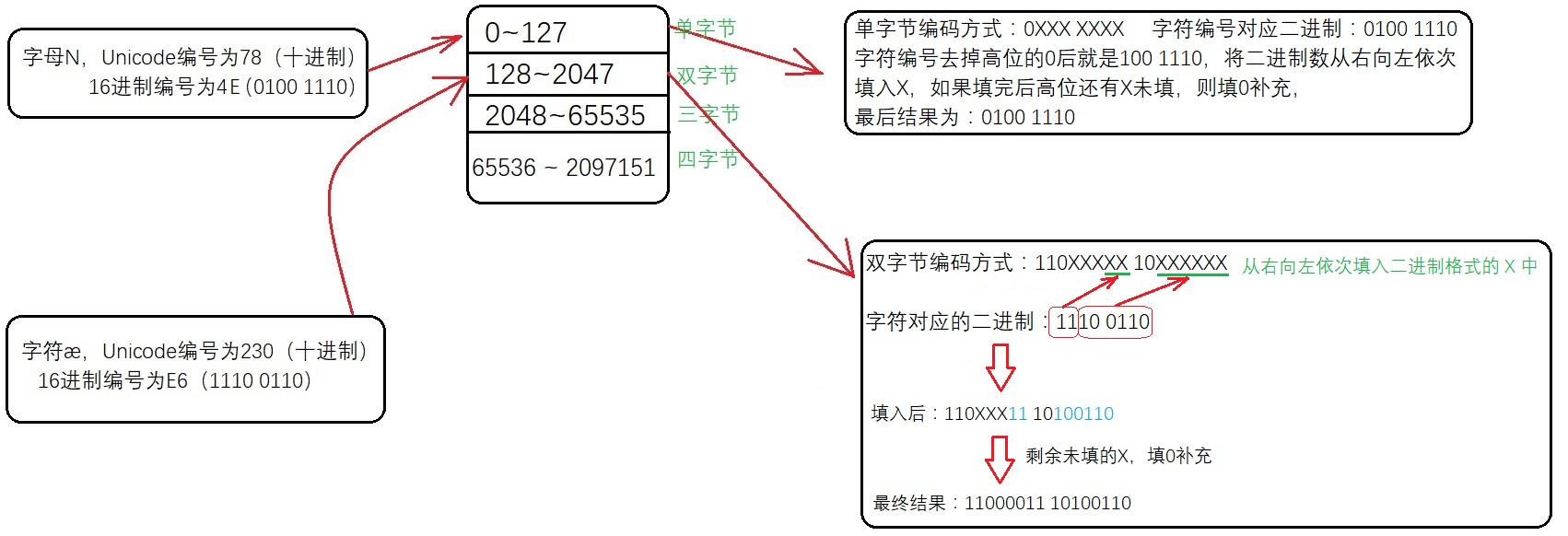
将一个字符的Unicode编号确定对应编码方式并按该编码方式存储的步骤如下:

以字母N为例,字母N的 Unicode编号为78(十进制),16进制编号为4E,78属于0~127这个范围,用单字节编码(相当于ASCII)
2、 UTF-16
编码方式:
1、对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
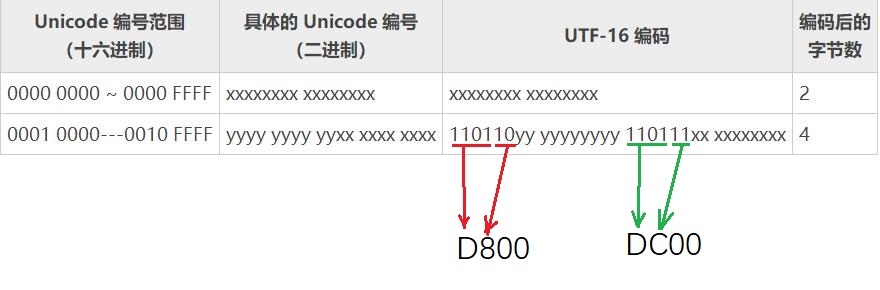
2、对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,
较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
3、UTF-32
编码方式:
始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。

对于上面这个字符来说对应的二进制为:0000 0000 1110 0110,经过UTF-32编码后仍然为0000 0000 1110 0110,只不过这里需要说明的是,转换成二进制后计算机存储的问题,计算机在存储器中排列字节有两种方式:
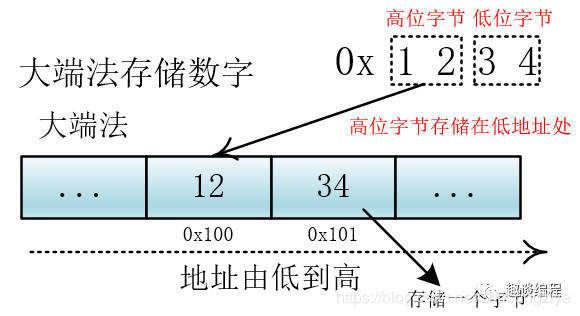
大端法和小端法,大端法就是将高位字节放到低地址处,比如 0x1234, 计算机用两个字节存储,一个是高位字节 0x12,一个是低位字节 0x34,它的存储方式为下:
(图片来源:https://blog.csdn.net/zhusongziye/article/details/84261211)
UTF-32 用四个字节表示,处理单元为四个字节(一次拿到四个字节进行处理),如果不分大小端的话,那么就会出现解读错误,比如我们一次要处理四个字节 12 34 56 78,这四个字节是表示
0x12 34 56 78 还是表示 0x78 56 34 12?不同的解释最终表示的值不一样。我们可以根据他们高低字节的存储位置来判断他们所代表的含义,所以在编码方式中有UTF-32BE(big endian) 和 UTF-32LE(littleendian),分别对应大端和小端,来正确地解释多个字节(这里是四个字节)的含义。
(Unicode规范中定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(ZERO WIDTH NO-BREAK SPACE),用FEFF表示,这正好是两个字节,而且FF比FE大1,
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大端方式;如果头两个字节是FF FE,就表示该文件采用小端方式)
对字符编码感兴趣的读者可以看下笨笨阿林写的刨根究底字符编码的系列文章:https://www.cnblogs.com/benbenalin/
编码方式之ASCII、ANSI、Unicode概述的更多相关文章
- 计算机编码方式详解(Unicode、UTF-8、UTF-16、ASCII)
整理这篇文章的动机是两个问题: 问题一: 使用Windows记事本的"另存为",可以在GBK.Unicode.Unicode big endian和UTF-8这几种编码方式间相互转 ...
- 字符编码笔记:ASCII、Unicode、UTF-8、UTF-16、UCS、BOM、Endian
转载:http://witmax.cn/character-encoding-notes.html 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问 ...
- 字符编码笔记:ASCII,Unicode和UT…
字符编码笔记:ASCII,Unicode和UTF-8 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才 ...
- 字符编码笔记:ASCII,Unicode和UTF-8(转)
字符编码笔记:ASCII,Unicode和UTF-8 作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个 ...
- 字符编码简介:ASCII,Unicode,UTF-8,GB2312
字符编码简介:ASCII,Unicode,UTF-8,GB2312 1. ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和 1两种状态,因 ...
- [转帖]字符编码笔记:ASCII,Unicode 和 UTF-8
字符编码笔记:ASCII,Unicode 和 UTF-8 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html 转帖 ...
- 【转载】字符编码笔记:ASCII,Unicode和UTF-8
字符编码笔记:ASCII,Unicode和UTF-8 作者: 阮一峰 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直 ...
- 字符编码笔记:ASCII,Unicode 和 UTF-8(理解)
1.ASCII 码 美国制定的字符编码规则,对英语字符与二进制位之间的关系做了统一规定. 占一个字节,8 位,最多可表示 2^8 = 256 种状态(字符) 实际共有 128 个字符,只占用一个字节的 ...
- (转)字符编码笔记:ASCII,Unicode和UTF-8
字符编码笔记:ASCII,Unicode和UTF-8 访问地址:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
随机推荐
- iOS开发~防止navigation多次push一个页面
在点击push下一个页面时,因为各种原因,点一下cell或按钮没有响应,用户可能就多点几下,这时候会打开好几个一样的页面. 这是因为push后的页面有耗时操作或者刚好push到另一个页面时,另一个页面 ...
- spring bean 的作用域之间有什么区别
spring bean 的作用域之间有什么区别? spring容器中的bean可以分为五个范围.所有范围的名称都是说明的, 1.singleton:这种bean范围是默认的,这种范围确保不管接受到多个 ...
- IntelliJ IDEA 2017.3 配置Tomcat运行web项目教程(多图)
小白一枚,借鉴了好多人的博客,然后自己总结了一些图,尽量的详细.在配置的过程中,有许多疑问.如果读者看到后能给我解答的,请留言.Idea请各位自己安装好,还需要安装Maven和Tomcat,各自配置好 ...
- Vue学习手记03-路由跳转与路由嵌套
1.路由跳转 添加一个LearnVue.vue文件, 在router->index.js中 引入import Learn from '@/components/LearnVue' 在touter ...
- arcgis python 布局中所有元素平移
# Author: ESRI # Date: July 5, 2010 # Version: ArcGIS 10.0 # Purpose: This script will loop through ...
- LINUX增加SWAP分区---install_oracle
我们都知道在安装Linux系统时在分区时可以分配swap分区,而系统安装后(在运行中)如何建立或调整swap分区呢?在装完Linux系统之后,建立Swap分区有两种方法.1.新建磁盘分区作为swap分 ...
- 安装TensorFlow时出现ERROR: Cannot uninstall 'wrapt'问题的解决方案
pip install -U --ignore-installed wrapt enum34 simplejson netaddr pip install -i https://pypi.tuna.t ...
- 26Flutter 日期 和时间戳/格式化日期库/flutter异步/ 官方自带日期组件showDatePicker、时间组件showTimePicker以及国际化
/* 一.Flutter日期和时间戳 日期转换成时间戳 var now=newDateTime.now(); print(now.millisecondsSinceEpoch); //单位毫秒,13位 ...
- Javascript——概述 && 继承 && 复用 && 私有成员 && 构造函数
原文链接:A re-introduction to JavaScript (JS tutorial) Why a re-introduction? Because JavaScript is noto ...
- iReport报表生成html,pdf,xls,word工具类
package com.report; import java.io.ByteArrayOutputStream;import java.io.File;import java.io.InputStr ...