深度学习-LeCun、Bengio和Hinton的联合综述
深度学习其实要入门也很简单,不要被深度学习、卷积神经网络CNN、循环神经网络RNN等某些“高大上”的专有名词所吓到或被忽悠,要相信大道至简,一个高中生只要愿意学也完全可以入门级了解并依赖一些成熟的Tensorflow、pytorch等框架去实现一些常用模型。有关《深度学习》的综述或翻译已有很多,在此不在赘述,深度学习是机器学习的一种,今天将从更广的视觉来分析。
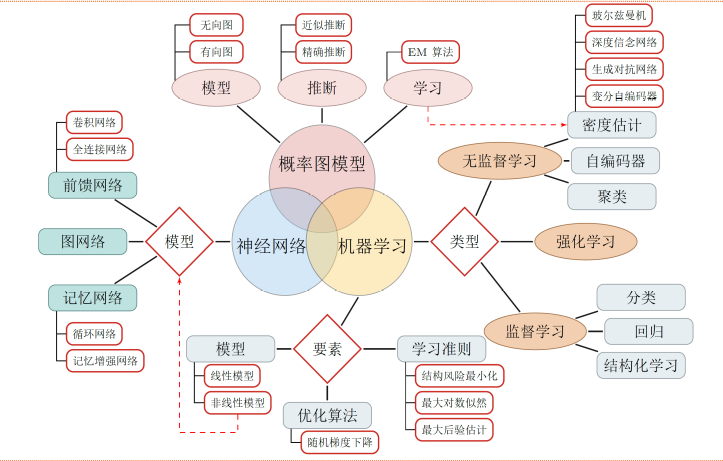
图1 深度学习是机器学习的子问题
1.机器学习
机器学习(Machine Learning, ML)是指利用机器(计算机)从有限的观测数据中通过训练学习到一般性的规律,并将这些规律应用到新的未观测样本上的方法,正如人类可以通过多次训练学习到骑自行车或者游泳的规律。传统的机器学习处理流程一般需要将数据表示为一组特征(Feature),特征的表示可以是连续的数值、离散的符号或者其他形式。如下图:
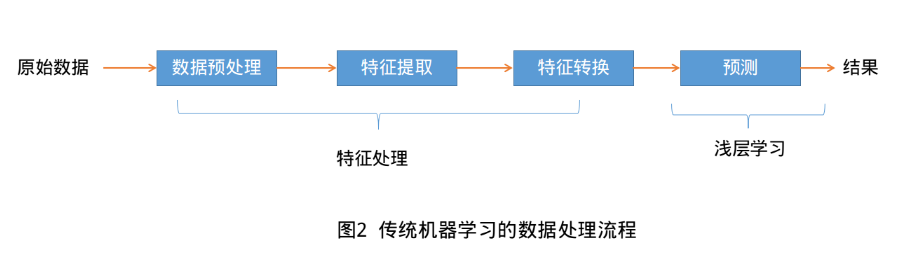
传统机器学习主要包括数据预处理-->特征处理(特征提取、转换和选择)-->机器算法学习训练(核心)-->预测。 传统的机器学习模型主要关注最后一步,即构建预测函数。但也遵从“二八定律”,前期的特征处理(又叫特征工程)需要大量的人工干预,需要结合具体问题专家领域背景的知识来从原始数据中进行特征转换加工,如特征升维和降维。常用的特征转换方法主要有主成分分析(Principal components analysis, PCA)、线性判别分析(Linear Discriminant Analysis)等。由于需要人类的经验来选取好的特征,很多模式识别问题变成来特征工程(Feature Engineering)问题。开发一个机器学习系统的主要工作量都消耗在来预处理、特征提取以及特征转换上,占用人工80%以上的精力。如何能自动化有效解决数据表示这个瓶颈成了众多科学家追求的目标。
2.表示学习
为了提高机器学习系统的准确率,我们就需要将原始输入数据信息转换为有效的特征,或者更一般成为表示(representation)。如果有一种算法可以自动的学习出有效的特征,并最终提高机器学习模型的性能,那么这种学习就叫做表示学习(Resprentation Learning). 那么如何学习学习到一个好的表示呢? 通常我们使用两种方式来表示特征:局部表示(Local Respresentation)和分布式表示(Distributed Respresentation).以文本分类中单词的表示为例,传统的局部表示就是One-hot编码,假设所有单词构成一个词表V,词表大小为|V|,则可以用一个|V|维的Ont-Hot向量来表示每个单词。第i个单词的One-hot向量中,第i维的值为1,其它都为0.如下图
红色: [0,0,0,0,0,1,0,…,0,0,0,0,0,0,0,0,0]
粉红色:[,0,0,0,0,0,0,…,0,0,0,0,0,0,0,1,0]
局部表示有两个很明显的不足就是:(1)One-hot编码维数很高,占用空间大,且难以扩展。如碰到新词,只能扩大词表维数。(2)不同单词相似度均为0,如上面例子中红色和粉红色语义上很接近,相似度却被计算为0.
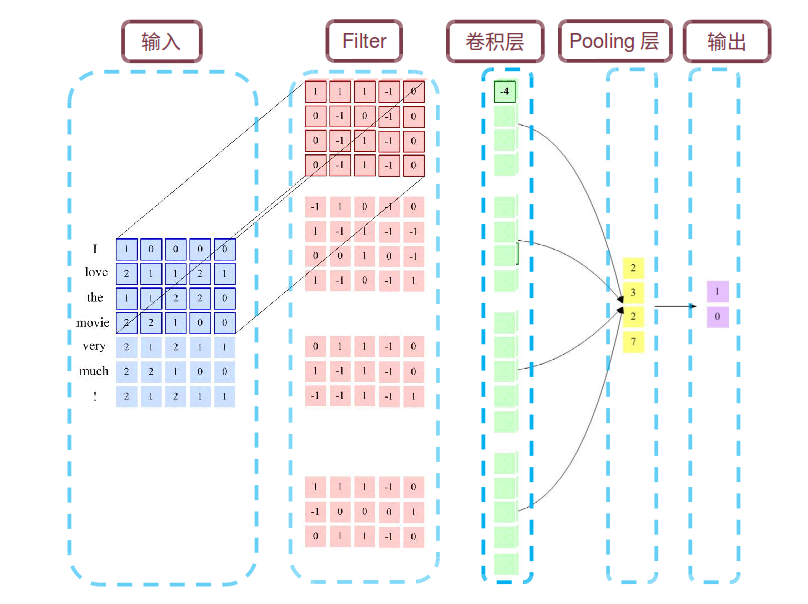
分布式表示是通过更低维的实数向量空间来表示,如文本中词向量Word2vec算法或颜色表示中的RGB表示法,将上万维的Ont-hot编码映射到一个非常低维的分布式表示空间R^d,d<<|V|.这这个低维空间中,每个特征不在是坐标轴上的点,而是分散中整个低维空间中,特征之间也可以有语义上的相似度。这个过程也称为嵌入(Embedding),所以文本中很多单词表示称为Word Embedding,词嵌入。
3. 深度学习
要学习到一种好的高层语义表示(分布式表示),通常需要从底层特征开始,经过多步非线性转换才能得到(从底层特征,到中层特征,再到高层特征)。这样我们就需要一种学习方法可以从数据中学习一个“深度模型”,也就是深度学习(Deep Learning, DL).深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。深度学习将原始的数据特征通过多步转换变成为更高层次、更抽象的表示。这些学习到的表示可以代替人工设计的特征,从而避免昂贵的耗费大量人力的“特征工程”。
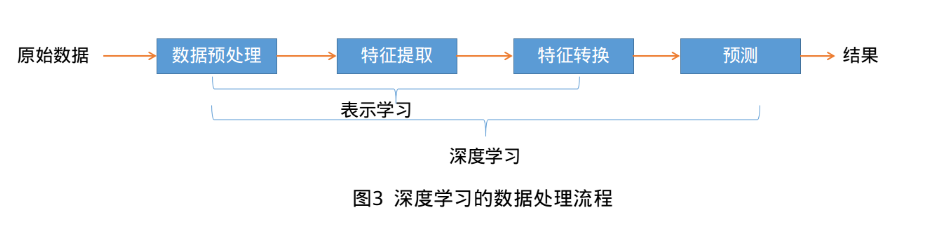
如何自动学习有效的数据表示成为机器学习中的关键问题。早期的表示方法,如特征抽取和特征选择,需要人工引入一些主观假设来进行学习,得到的表示不一定对后续的机器学习任务有效只能不断尝试。而深度学习是将表示学习和预测模型的学习进行端到端的学习,中间不需要人工干预。是的,深度学习核心原理说白了,就是这么简单————从原始数据经过一些简单的但非线性的模型转变成更高层次,更加抽象的表达。通过足够多的转换组合(深度),非常复杂的函数也可以被学习到。目前,深度学习主要以神经网络模型为基础,研究如何设计模型结构,如何有效地学习模型的参数,如何优化模型性能以及在不同任务上的应用等。
4. 深度学习的反思
深度神经网络揭示了很多自然信号具有复合结构的特点。高层特征可以通过低层特征组合得到。图像中,棱边经过局部组合可以构成基本图案,基本图案组合成部件,部件又构成物体。语音和文本也存在相似结构,由声音到语音,再到音素、音节、单词、句子、文章。下采样层可以保证新的特征层不敏感于前一层元素在位置和表现上的变化。
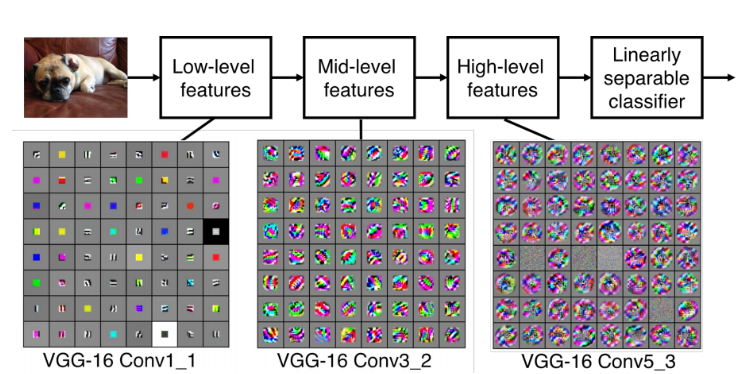
图4 深度模型表示学习
深度学习模型有大量的参数,当模型参数远大于数据量时,容易产生过拟合,层次不够参数远小于数据量时,相当于求超定方程,可能无解或者有解但准确率很低,即欠拟合问题。在当年的数据量和计算能力局限下,深度学习与传统机器学习方法并没有太大的优势。在2006年加拿大多伦多大学教授、机器学习泰斗——Geoffrey Hinton和他的学生Ruslan从理论层面论证多隐层的人工神经网络具有优异的特征学习能力并提出“逐层初始化”有效克服训练上的难点,特别是2012年Hinton的学生Alex在ILSVRC(ImageNet Large Scale Visual Recognition Challenge, ImageNet大规模视觉识别竞赛, http://image-net.org/challenges/LSVRC/)上大比分桂冠后从真正开启深度学习在学术和工业界的浪潮。深度神经网络原理好像也并不复杂,那么为何发展了数十年是在2012年而不是其它时间爆发呢?
(1) 更大的数据集,如ImageNet
(2) 新的深度学习技术,如ReLU、Dropout等技术
(3) 新的计算硬件,如GPU,DCNN.
近些年随着各大互联网巨头的发力,相关大数据集的发布和深度学习框架的发展,未来必将不断加速,取得更大的辉煌。
未来发展方向:
(1) 为了减少参数,提高泛化能力,提出卷积神经网络CNN: 局部连接、权值共享、下采样(汇聚操作)来简化神经网络结构。ConvNet
(2) 为了解决信息过载,增加网络容量,提出循环神经网络RNN:注意力和记忆机制: LSTM,GRU,Attention Model
(3) NLP相对于CV方向,更注重于逻辑推理,更具学术性、挑战性,更难以工程落地。
常用的比较代表性和流行的深度学习框架:
(1) TensorFlow: 出身名门Google,将计算过程利用数据流图来表示,功能强大,更新改进快。
(2) PyTorch: 同样出身豪门FaceBook、NVIDIA、Twitter等公司开发维护,基于动态计算图。在需要动态改变神经网络结构的任务中优势明显。
(3) Keras:基于Tensorflow和Theano, 更高一层封装,简单粗暴有效,但不够灵活。
(4) Caffe:简单方便,所要实现的网络结构可在配置文件中指定,不需要编码。主要用于计算机视觉。
此外,还有蒙特利尔大学的Theano, 日本的Chainer,微软的CNTK,亚马逊和卡內基梅隆大学的MXNet和百度开发的PaddlePaddle等。
深度学习-LeCun、Bengio和Hinton的联合综述的更多相关文章
- Hinton“深度学习之父”和“神经网络先驱”,新论文Capsule将推翻自己积累了30年的学术成果时
Hinton“深度学习之父”和“神经网络先驱”,新论文Capsule将推翻自己积累了30年的学术成果时 在论文中,Capsule被Hinton大神定义为这样一组神经元:其活动向量所表示的是特定实体类型 ...
- 【Todo】【转载】深度学习&神经网络 科普及八卦 学习笔记 & GPU & SIMD
上一篇文章提到了数据挖掘.机器学习.深度学习的区别:http://www.cnblogs.com/charlesblc/p/6159355.html 深度学习具体的内容可以看这里: 参考了这篇文章:h ...
- 深度学习(DNN)的学习网站
近期决定对深度学习稍微学习一下,因此搜集了一些相关的网站和资料,特分享给大家. 首先,如果你对机器学习还不甚了解,最好先了解一下其相关的概念,推荐 Andrew Ng在斯坦福的机器学习教程 (中文翻译 ...
- 深度学习(Deep Learning)算法简介
http://www.cnblogs.com/ysjxw/archive/2011/10/08/2201782.html Comments from Xinwei: 最近的一个课题发展到与深度学习有联 ...
- (转)Deep Learning深度学习相关入门文章汇摘
from:http://farmingyard.diandian.com/post/2013-04-07/40049536511 来源:十一城 http://elevencitys.com/?p=18 ...
- 深度学习之父低调开源 CapsNet,欲取代 CNN
“卷积神经网络(CNN)的时代已经过去了!” ——Geoffrey Hinton 酝酿许久,深度学习之父Geoffrey Hinton在10月份发表了备受瞩目的Capsule Networks(Cap ...
- 深度学习中的Dropout
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃.注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络. ...
- 深度学习综述(LeCun、Bengio和Hinton)
原文摘要:深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示.这些方法在很多方面都带来了显著的改善,包含最先进的语音识别.视觉对象识别.对象检測和很多其他领域,比如药物发现和基 ...
- Nature重磅:Hinton、LeCun、Bengio三巨头权威科普深度学习
http://wallstreetcn.com/node/248376 借助深度学习,多处理层组成的计算模型可通过多层抽象来学习数据表征( representations).这些方法显著推动了语音识别 ...
随机推荐
- 009_linuxC++之_友元函数
(一)定义:友元函数是指某些虽然不是类成员却能够访问类的所有成员的函数.类授予它的友元特别的访问权.通常同一个开发者会出于技术和非技术的原因,控制类的友元和成员函数(否则当你想更新你的类时,还要征得其 ...
- Oracle 物理结构(二) 文件-口令文件
一.口令文件作用 1.口令文件基本介绍 Oracle数据库口令文件存放有超级用户的口令及其他特殊用户的用户名/口令. 口令文件在数据库创建时,自动创建,存放在$ORACLE_HOME/dbs. 此文件 ...
- rep stos ptr dword es:[edi]
今天读代码时,忽然跳出如下一条指令==>>汇编代码: rep stos dword ptr es:[edi] 在网上查了相关资料显示:/************************** ...
- Spring基础环境搭建所需要的jar包
红色标明的jar包.是spring框架开发的基础jar包. 必要jar包. spring-core-4.1.6.RELEASE.jar 框架核心jar包. spring-beans-4.1.6.REL ...
- linux 后台 运行
但是如果终端关闭的话,程序也会终止,那么就要涉及到linux的一个十分强大的命令:screen. 按照我个人的理解,这个命令就是能够在linux中创造出多个终端,在已有的窗口内部再创造更多的窗口,结合 ...
- JMeter压力测试及并发量计算-2
一个每天1000万PV的网站需要什么样的性能去支撑呢?继续上一篇,下面我们就来计算一下,前面我们已经搞到了一票数据,但是这些数据的意义还没有说.技术是为业务服务的,下面就来说说怎么让些数据变得有意义. ...
- nodeJS 项目如何运行
nodeJS 项目如何运行 一.总结 一句话总结: nodejs项目根目录中用node xx.js 或是 node xx运行 打开 window的 cmd 命令窗口,使用 cd 命令跳转到 nodeJ ...
- RabbitMQ交换器的类型
RabbitMQ常用的交换器类型有:fanout,direct,topic,headers fanout它会把所有发送到该交换器的消息路由到所有与该交换器绑定的队列中. direct它会把消息路由到哪 ...
- treeview所有节点递归解法及注意!!!!!!!!!!!!!!!!!
好吧 我把所有之前写的都删了,只为这一句话“所有变量切记小心在递归函数内部初始化”,包括:布尔,变量i,等等.至于为什么....递归就是调用自己,你初始化以后的变量,等再次调用的时候又回来了 bool ...
- 以太坊Geth通过私钥导入新地址到钱包步骤(3种方法)
一: 通过Geth客户端导入私钥: Open TextEdit Paste key into TextEdit without any extra characters or quotations S ...