hadoop/hbase/hive单机扩增slave
原来只有一台机器,hadoop,hbase,hive都安装在一台机器上,现在又申请到一台机器,领导说做成主备,
要重新配置吗?还是原来的不动,把新增的机器做成slave,原来的当作master?网上找找应该有这种配置操作,先试试看
原来搭单机hadoop,单机hadoop搭建
原来搭建单机hbase,单机hbase搭建
原来搭建单机zookeeper三个节点,单机伪zookeeper集群
1.申请到机器了,先把主机名改成slave
vim /etc/sysconfig/network
HOSTNAME=slave
2.添加2台机器信任关系
1),进入master机器的/root/.ssh目录,
检查该目录下是否有id_rsa和id_rsa.pub文件,
如果没有,执行ssh-keygen -t rsa 命令,生成私钥和公钥。
2)在主机master中添加自己的私钥:ssh-add id_rsa
注:很多介绍中都少了第二步,所以经常出现测试时不通过的情形。
ssh-add id_rsa
# 如果提示 could not open a connection to your authentication agent
终端做如下操作:
ssh-agent bash
ssh-add id_rsa
3)将主机master中的公钥id_rsa.pub拷贝到主机slave的.ssh目录下,authorized_keys文件中。
scp -r /root/.ssh/id_rsa.pub 192.168.1.197:/root/.ssh/authorized_keys
4)将主机slave 中的authorized_keys改为只有当前用户有读写权限:chmod 600 authorized_keys
5)在master中登录slave
>ssh 192.168.1.197 果然不需要密码直接登录了
将id_rsa.pub加入到授权的key中
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
就可以自己登录自己了:
> ssh master
6)在slave机器中生成私钥和公钥
进入slave机器的/root/.ssh目录,
检查该目录下是否有id_rsa和id_rsa.pub文件,
如果没有,执行ssh-keygen -t rsa 命令,生成私钥和公钥
7)在主机slave中添加自己的私钥:ssh-add id_rsa
注:很多介绍中都少了第二步,所以经常出现测试时不通过的情形。
ssh-add id_rsa
# 如果提示 could not open a connection to your authentication agent
终端做如下操作:
ssh-agent bash
ssh-add id_rsa
8)将主机slave中的公钥id_rsa.pub拷贝到主机master的.ssh目录下,authorized_keys文件中。
scp -r /root/.ssh/id_rsa.pub 192.168.1.166:/root/.ssh/authorized_keys
9)在slave主机上登录master
>ssh 192.168.1.166 果然不需要密码
3.将master上安装配置的hadoop拷贝到slave上一份
scp -r /hadoop root@ 192.168.1.197:/
修改slave:/hadoop/hadoop-2.8.4/etc/hadoop中相关配置文件
1)hadoop-env.sh 不改
2)yarn-env.sh 不改
3)修改 core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>hadoop tmp dir</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://slave:9000</value>
</property>
</configuration>
4)hdfs-site.xml 不改,但要创建
/root/hadoop/dfs/name
/root/hadoop/dfs/data
目录
5)修改mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>slave:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6)修改slaves
>vi slaves
master slave
4.master和slave配置
在master和slave上都配置hosts
>vi /etc/hosts 内容如下
192.168.1.166 master
192.168.1.197 slave
发现slave机器上的java版本跟master不同,把master上安装的java拷贝到slave上,配置下环境变量就OK
5.hadoop集群如何启动?
进入master:/hadoop/hadoop-2.8.4/sbin目录
>start-dfs.sh 启动HDFS 因为之前已经格式化了,不用再格式化
此命令会启动(master)本机上namenode 、datanode、secondarynamenode 和slave上的datanode
>start-yarn.sh 启动yarn集群 此命令会先启动本地(master)的resourcemanager,在远程到slave上启动nodemanager。
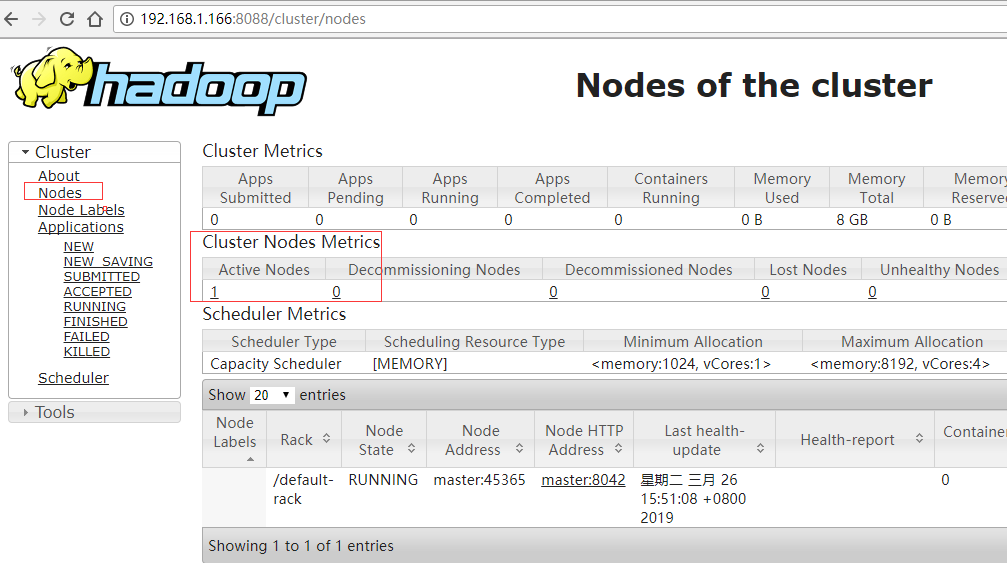
本以为启动成功了,浏览器访问,发现只有一个节点,是不是从节点slave没启动起来呢?
只能继续检查配置文件,一项项检查
1)hadoop-env.sh 不用改,只配置export JAVA_HOME
2)core-site.xml要修改,看错了,原来单机配置
单机配置:
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
集群配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
对应的slave要修改成:
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave:9000</value>
</property>
3)hdfs-site.xml 不修改
4)mapred-site.xml 修改 master / slave 对应主机上修改下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>slave:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5)yarn-site.xml master / slave 对应主机上修改下:
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改完,在master上
> stop-dfs.sh 停止HDFS
>stop-yarn.sh 停止yarn
再启动
> start-dfs.sh 启动HDFS
>start-yarn.sh 停止yarn
访问浏览器,发现还是只有一个存活节点,难道又失败了?
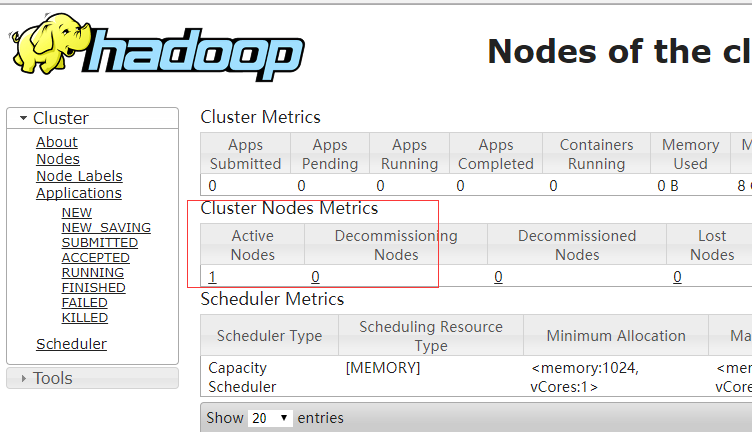
回头看了下启动日志:
start-dfs.sh 启动HDFS时,slave也启动了,并没有失败
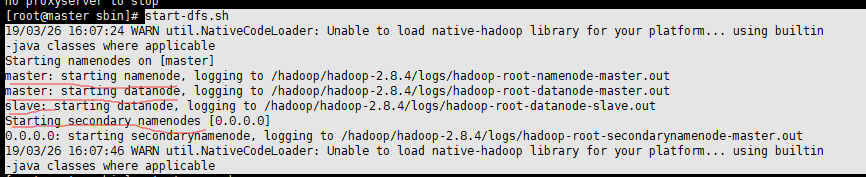
start-yarn.sh 启动yarn时,slave也启动了

为啥nodes节点只有一个呢?
查看master上进程:
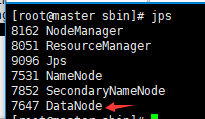
查看slave上进程:
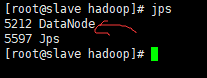
也有一个DataNode,为什么浏览器上只能看到一个节点呢?
hadoop/hbase/hive单机扩增slave的更多相关文章
- 【转载】全栈工程师-Hadoop, HBase, Hive, Spark
学习参考这篇文章: http://www.shareditor.com/blogshow/?blogId=96 机器学习.数据挖掘等各种大数据处理都离不开各种开源分布式系统, hadoop用于分布式存 ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南
hue下载地址:https://github.com/cloudera/hue hue学习文档地址:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-c ...
- hadoop,hbase,hive
linux上安装hadoop,然后安装hbase,然后安装zookeeper,最后安装hive.hbase安装在hdfs下.hive是纯逻辑表,hbase是物理表.hdfs是hadoop上的一个组件.
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- [转]云计算之hadoop、hive、hue、oozie、sqoop、hbase、zookeeper环境搭建及配置文件
云计算之hadoop.hive.hue.oozie.sqoop.hbase.zookeeper环境搭建及配置文件已经托管到githubhttps://github.com/sxyx2008/clou ...
随机推荐
- ubuntu下不能访问docker中的rabbitmq服务端口
主要原因是防火墙屏蔽了15672端口,宿主机就不能直接通过 ip:port的形式访问rabbitmq的管理界面了. 解决方法很简单: 设置防火墙规则,使外部主机能够访问虚拟机的15672端口. 启动i ...
- C# 字典、集合、列表的时间复杂度
List列表是顺序线性表,Add操作是O(1)或O(N),因为List是动态扩容的,在未扩容之前,其Add操作是O(1),而在扩容的时候,Add操作是O(N)的.其Contains方法,是按照线性检索 ...
- springboot2.0整合freemarker快速入门
目录 1. 快速入门 1.1 创建工程pom.xml文件如下 1.2 编辑application.yml 1.3 创建模型类 1.4 创建模板 1.5 创建controller 1.6 测试 2. F ...
- docker入门到放弃
1.容器简介 Docker是一个开源的应用容器引擎,使用Go语言开发,基于Linux内核的cgroup,namespace,Union FS等技术,对应用进程进行封装隔离,并且独立于宿主机与其他进程, ...
- Replication-Manager
MYSQL5.7下搭建Replication-Manager 环境说明 在主机1,主机2,主机3上安装MySQL服务端和客户端. 主机1 主机2 主机3 操作系统 CentOS7.4 CentOS7. ...
- JavaScript - 过滤敏感字符
目录 before 源码示例 before 本篇博客展示了如何是在前端对铭感字符及一些特殊的命令做过滤. 好处是,少发一次请求,减少服器校验压力. 源码示例 <!DOCTYPE html> ...
- T100——单据别的新增、修改设置
何为单据别,例如下图,新增的时候开窗选择单据别: 新增单据别: 1.首先在azzi600 系统分类码维护作业里面新增新的系统分类码(在系统分类码24下新增),如图: 2.在azzi910 作业基本数据 ...
- Codeforces 1238F. The Maximum Subtree
传送门 考虑构造一些区间使得树尽可能的 "大" 发现这棵树最多就是一条链加上链上出去的其他边连接的点 构造的区间大概长这样(图比较丑请谅解..$qwq$,图中每一个 "└ ...
- java lesson20homework
package com.xt.lesson20; /** * 简易自动提款机 1. 创建用户类User(包含卡号.姓名.密码.余额等属性),用户开卡时录入的姓名和密码(自动分配一个卡号.初始金额设置为 ...
- 序列化和反序列化在浏览器和 Web 服务器之间传递的数据、加密解密
js中数组不能传递到后台,需进行json序列化: var data = new Array(); data.push({para1:name,para2:answer}); string data = ...