Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二、merge:通过键拼接列
类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来。
该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面。
merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
参数介绍:
left和right:两个不同的DataFrame;
how:连接方式,有inner、left、right、outer,默认为inner;
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
right_on:右侧DataFrame中用于连接键的列名;
left_index:使用左侧DataFrame中的行索引作为连接键;
right_index:使用右侧DataFrame中的行索引作为连接键;
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y');
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
indicator:显示合并数据中数据的来源情况
案例1
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1

random = np.random.RandomState(0)
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2
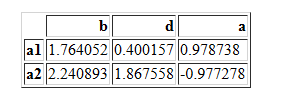
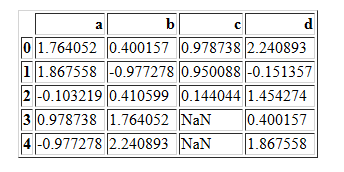
pd.merge(df1,df2)

pd.merge(df1,df2,how="outer")
案例2 默认按相同的列名键join
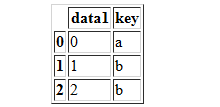
df3=pd.DataFrame({'key':['a','b','b'],'data1':range(3)})
df3
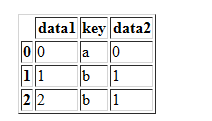
df4=pd.DataFrame({'key':['a','b','c'],'data2':range(3)})
df4

pd.merge(df3,df4)
案例三
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df1

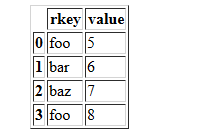
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
df2
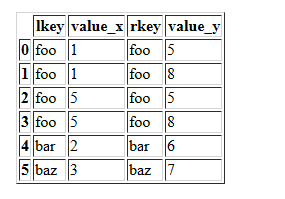
df1.merge(df2)

Merge df1 and df2 on the lkey and rkey columns. The value columns have the default suffixes, _x and _y,
df1.merge(df2,left_on="lkey",right_on="rkey")
>>> df1.merge(df2, left_on='lkey', right_on='rkey', suffixes=(False, False))
Traceback (most recent call last):
...
ValueError: columns overlap but no suffix specified:
Index(['value'], dtype='object')
Pandas中DataFrame数据合并、连接(concat、merge、join)之merge的更多相关文章
- Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一.concat:沿着一条轴,将多个对象堆叠到一起 concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, key ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- 将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy
将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy import pandas as pd from sqlalchemy import create_engine ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
- pandas中DataFrame的ix,loc,iloc索引方式的异同
pandas中DataFrame的ix,loc,iloc索引方式的异同 1.loc: 按照标签索引,范围包括start和end 2.iloc: 在位置上进行索引,不包括end 3.ix: 先在inde ...
- pandas中,dataframe 进行数据合并-pd.concat()
``# 通过数据框列向(左右)合并 a = pd.DataFrame(X_train) b = pd.DataFrame(y_train) # 合并数据框(合并前需要将数据设置成DataFrame格式 ...
随机推荐
- [bzoj1733][Usaco2005 feb]Secret Milking Machine 神秘的挤奶机_网络流
[Usaco2005 feb]Secret Milking Machine 神秘的挤奶机 题目大意:约翰正在制造一台新型的挤奶机,但他不希望别人知道.他希望尽可能久地隐藏这个秘密.他把挤奶机藏在他的农 ...
- Spring之一:IoC容器体系结构
温故而知心. Spring IoC概述 常说spring的控制反转(依赖反转),看看维基百科的解释: 如果合作对象的引用或依赖关系的管理要由具体对象来完成,会导致代码的高度耦合和可测试性降低,这对复杂 ...
- 小菜鸟之Phyhon
# print("输入成绩",end="") # src=input() # print("成绩",end=src)#成绩 # print( ...
- 走近kafka-文件存储
过期的数据才会被自动清除以释放磁盘空间.比如我们设置消息过期时间为2天,那么这2天内的所有消息都会被保存到集群中,数据只有超过了两天才会被清除. Kafka只维护在Partition中的offset值 ...
- c++学习笔记之函数重载和模板理解
1.函数重载: C++ 不允许变量重名,但是允许多个函数取相同的名字,只要参数表不同即可,这叫作函数的重载(其英文是 overload).重载就是装载多种东西的意思,即同一个事物能完成不同功能. 所谓 ...
- laravel框架之自帶登錄&註冊
//控制器層 <?php namespace App\Http\Controllers\admin; use App\Models\admin\Users; use Illuminate\Htt ...
- python私有化xx、_xx、__xx、__xx__、xx_的区别
xx:共有变量. _xx:私有化的属性或方法,from xxx import * 时无法导入,子类的对象和子类可以访问. __xx:避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到 ...
- 安装kubenetes-遇到的问题总结
# 5.修改docker的cgroup驱动(不需要操作)# kubelet# 看到最后一行:error: failed to run Kubelet: failed to create kubelet ...
- mpstat
mpstat--multiprocessor statistics,统计多处理器的信息 1.安装mpstat工具 [root@localhost ~]# yum install sysstat 2:展 ...
- golang(8):channel读写 & goroutine 通信
goroutine 1.进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位 B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独 ...