[Kaggle] How to handle big data?
上一篇,[Kaggle] How to kaggle?【方法导论】
这里再做一点进阶学习。
写在前面
"行业特征" 的重要性
Ref: Kaggle2017—1百万美金的肺癌检测竞赛的难点哪儿
一、医学顶会 MICCAI
Medical image analysis是个非常有意义的研究方向,按道理属于Computer Vision,但由于没有像CV里面物体识别场景识别里标准化的数据库和评测方法,一直比较小众。
MICCAI是这个medical image analysis方向的顶会,目前并没有被deep learning统治,经常看到mean-shift以及其他比较基础的图片处理的算法,深度学习在这方面应该有很大潜力。CV里扎堆的优秀同学们不妨多看看这个方向,毕竟在某个疾病预测任务上能提升2%准确度比在Pascal VOC上费牛劲撸个0.5%提高有意义多了:)
二、CNN策略找cancer
Medical image analysis里面数据尤其宝贵,这次比赛放出来的数据以及这种公开比赛的模式应该能推动这个方向的发展。大致看了下比赛数据,
“a thousand low-dose CT images from high-risk patients in DICOM format. Each image contains a series with multiple axial slices of the chest cavity. Each image has a variable number of 2D slices, which can vary based on the machine taking the scan and patient.”,
虽然只有1000多张CT图,但是每张图是很多slice,所以算是个cubic representation,可能可以从deep learning for 3D或者deep learning for video recognition等方向看看有没有合适的方法可以借鉴。我不是这方面的专家,就留给各位见仁见智了,欢迎分享。
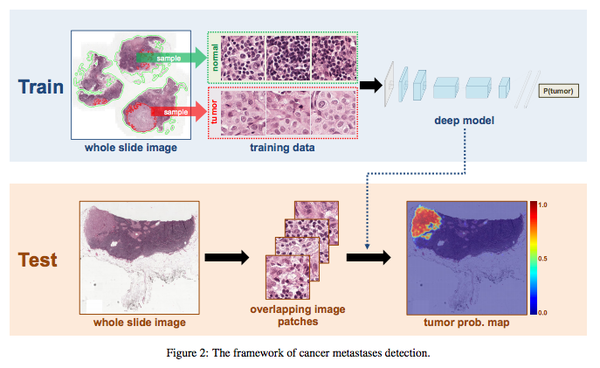
这里给大家提供一个cancer detection的相关工作作为参考。我CSAIL实验室前同事去年参加了个类似的比赛cancer metastasis detection:CAMELYON16 - Results,他和Harvard medical school的朋友利用类似于CNN+FCN的网络取得了第一名。同事去年毕业了现在正在用这个成果做Startup,叫PathAI | Welcome。论文也放出来了,感兴趣的朋友可以读读:https://people.csail.mit.edu/khosla/papers/arxiv2016_Wang.pdf。网络结构大致如下图,思路挺简单。
三、可解释性之"热力图"
另外,在医学图像分析诊断预测里面,非常重要一点是模型的可解释性。就是你得解释清楚你这个AI模型为什么work了,或者为什么在某些情形不work。这点其实比在benchmark上单纯提升分数更难。在Deep learning一股脑调参调结构提升分数的年代,network interpretability这个问题普遍被忽略了。而这个人命关天的medical image analysis方向,模型的可解释性肯定必不可少。再好的模型,解释不了为啥work,可能连FDA审核都过不了。
这里我安利一下我CVPR‘16上发表的一个工作:
这个工作提出了一个叫CAM (Class Activation Mapping)的方法,可以给任意一个CNN分类网络生成热力图(Class Activation Map),这个热力图可以高亮出图片里面跟CNN最后预测结果最相关的区域,所以这个CAM能解释网络模型到底是基于图片里面哪些部分作为证据进行了这次预测。比如说如下图,我们在caltech256上fine-tune了网络,然后对于每张图生成跟这张图所属类别的Class Activation Map,然后就可以高亮出图片里面跟类别最相关的区域。这里在训练过程中,网络并没有接收到任何bounding box的标定。所以一个在medical image analysis上直接扩展是,CNN分类网络预测出这张图里面有很大概率有cancer,这个高亮出来的区域很可能就是cancer区域,感兴趣的同学不妨试试看,很期待你们有新的发现。

四、行业知识的预处理
大家可能一开始的思维都是直接套用目前cv界的一些成果,这个领域我应该有一点点发言权,毕竟研究生阶段做的就是肺癌检测,算是小有心得,也开始参赛了(钱好多而且也想在毕业前证明三年没白干),我的建议是在考虑建模前,首先考虑下肺癌的影像学表现以及基本处理方法,大概1600个ct,如果不利用基本医学领域知识做预处理,再好的模型我还是持悲观态度。
继续补充,目前来看,这个赛题不太合理,已经有人在论坛里面说了,肺结节是肺癌的一种影像学表现形式,我们检测肺癌,
首先会去检测肺结节,但是现在赛题的label仅仅是有没有得癌症,这种量级的数据,模型是无法找到病灶的,
所以我们需要先做肺结节检测,一个ct包含200张图,真在起作用的可能只有五到六张,你一股脑丢给模型,它都不知道自己要干啥,搜索空间太大,这也就是我说的必须预处理。
五、一些结论
所谓套路
Ref: 参加kaggle竞赛是怎样一种体验?
一、最常用策略
二、特征工程的重要性
(1) 都是一些常见的featuer处理方法(Hash, BOW, TFIDF, Categorization, Normalization),
(2) 加几个常见模型(RF, GBDT, LR),
(3) cross-validation调参数,
(4) 最后ensemble一下。
(5) 最好有很好的机器(主要是ram,以及tree-based model并行),这样就不用太担心online training的问题,大部分的lib也能用了。
预定哪一家酒店
Expedia比赛的挑战是你基于在Expedia提供的用户的搜索数据中的一些属性来预测他们会预定哪一个酒店。在我们编程之前需要花时间先理解问题和数据。
如果当你在研究比赛时想要学习更多内容,欢迎选择我们的课程dataquest来学习关于数据处理,统计学,机器学习,如何使用Spark工作等等。牛课程:https://www.dataquest.io/dashboard
Expedia比赛
一、数据集
- 数据集:Expedia Hotel Recommendations
- 数据集对应的网站按键,用户行为流程。
二、预测什么
hotel_cluster会被预定。根据描述总共大概有100个集群。in[1]:train["hotel_cluster"].value_counts() out[1]:
91 1043720
41 772743
48 754033
64 704734
65 670960
5 620194
...
53 134812
88 107784
27 105040
74 48355
三、训练、测试集的划分
"no bias" 查证
最为重要的就是,划分要保证 ”no bias“。
所以,要保证:测试的用户id是训练用户id的一个子集,用到了set。
test_ids = set(test.user_id.unique())
train_ids = set(train.user_id.unique()) # 确保test中的id是train中的子集
intersection_count = len(test_ids & train_ids)
intersection_count == len(test_ids) out:
True
随机抽取行
理想情况下,我们想要一个足够小的数据集可以让我们能够非常快的迭代不同的方法而且仍然能够代表整个训练数据集。
[Kaggle] How to handle big data?的更多相关文章
- [Dart] Capture and Handle Data Sequences with Streams in Dart
Streams represent a sequence of asynchronous events. Each event is either a data event, also called ...
- data cleaning
Cleaning data in Python Table of Contents Set up environments Data analysis packages in Python Cle ...
- [Machine Learning with Python] My First Data Preprocessing Pipeline with Titanic Dataset
The Dataset was acquired from https://www.kaggle.com/c/titanic For data preprocessing, I firstly def ...
- 【菜鸟学习jquery源码】数据缓存与data()
前言 最近比较烦,深圳的工作还没着落,论文不想弄,烦.....今天看了下jquery的数据缓存的代码,参考着Aaron的源码分析,自己有点理解了,和大家分享下.以后也打算把自己的jquery的学习心得 ...
- 转:jQuery.data
原文地址:http://www.it165.net/pro/html/201404/11922.html 内存泄露 首先看看什么是内存泄露,这里直接拿来Aaron中的这部分来说明什么是内存泄露,内存泄 ...
- Working with Data » Getting started with ASP.NET Core and Entity Framework Core using Visual Studio » 创建复杂数据模型
Creating a complex data model 创建复杂数据模型 8 of 9 people found this helpful The Contoso University sampl ...
- HDU 4286 Data Handler 双向链表/Splay
Data Handler Time Limit: 20 Sec Memory Limit: 256 MB 题目连接 http://acm.hdu.edu.cn/showproblem.php?pid= ...
- 读jQuery源码 jQuery.data
var rbrace = /(?:\{[\s\S]*\}|\[[\s\S]*\])$/, rmultiDash = /([A-Z])/g; function internalData( elem, n ...
- Kaggle Challenge简要介绍
https://en.wikipedia.org/wiki/Kaggle 以下内容,直接摘自维基百科,主要起到一个记录的作用,提醒自己有时间关注关注这个竞赛. Kaggle is a platform ...
随机推荐
- 在DjangoAdmin中使用KindEditor(上传图片)
一.下载 http://kindeditor.net/down.php 删除asp.asp.net.php.jsp.examples文件夹 拷贝到static目录下 二.配置 kindeditor目录 ...
- 利用 sendBeacon 发送统计信息
我们经常会在网站追踪用户的信息,比如记录用户的停留时间. window.addEventListener("unload", () => { // sendHTTP }); ...
- java——Servlet
类要实现Servlet接口: 主要功能,生成动态网页内容: HttpServlet重写doGet和doPost方法或者重写Service方法,完成对请求的响应: 如:get.post等请求的响应. - ...
- IDEA设置CodeGlance颜色
CodeGlance是IDEA的mini地图插件, 默认情况下, 其颜色和编辑框的颜色基本一致, 而安装CodeGlance就是为了方便滚动框的上下拖拉, 颜色一致的话会将这种CodeGlance比拖 ...
- P2402 奶牛隐藏 二分+网络流
floyd搞出两点间最短距离 二分判答案 // luogu-judger-enable-o2 #include<bits/stdc++.h> using namespace std; ty ...
- freemodbus收藏学习网址
https://www.cnblogs.com/axinno1/p/8521481.html https://blog.csdn.net/xukai871105/article/details/216 ...
- hive优化实战
2019年1月8日,付哥给了我一份公司以前的一份SQL优化方案文档.十分感谢.记录了许多在公司以前优化的案例. -------------------------------------------- ...
- Java对象间的关系
1 综述 在Java中对象与对象的关系总体分为四类,分别是:依赖.关联.聚合和组合. (1)依赖(Dependency)关系是类与类之间的联接.依赖关系表示一个类依赖于另一个类的定义,一般而言,依赖关 ...
- Spring中,请求参数处理
Spring中,Controller里,获取请求数据有多种情况 在使用@RequestParam的方式获取请求中的参数时, 如果没有设置required这个属性,或者主动设置为true,则意味着这个参 ...
- 小米oj 反向位整数(简单位运算)
反向位整数 序号:#30难度:一般时间限制:1000ms内存限制:10M 描述 输入32位无符号整数,输出它的反向位. 例,输入4626149(以二进制表示为00000000010001101001 ...