python爬虫概述
爬虫的使用:爬虫用来对网络的数据信息进行爬取,通过URL的形式,将数据保存在数据库中并以文档形式或者报表形式进行展示。
爬虫可分为通用式爬虫或特定式爬虫,像我们经常用到的搜索引擎就属于通用式爬虫,如果针对某一特定主题或者新闻进行爬取,则属于特定式爬虫。
一般用到的第三方库有urllib、request、BeautifuiSoup。经常用到的框架为Scrapy和PySpider
爬虫的爬取步骤:
- 获取指定的url链接,获得链接网址上的所有代码信息。
- 通过python的正则表达式,将嵌套的HTML代码和数据进行分离。
- 获取数据后,保存在文档或者数据库中。方便后续的展示。
正常的网络传输大致分为Request(请求)和Response(响应)两类。
正常的HTTP请求一般分为get和post方法#
#使用urllib2编写最简单的爬虫代码
from urllib import request as urllib2
#在进行url请求时,应该添加User-Agent头进行识别
header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Window
s NT 6.1; Trident/5.0;"}
request = urllib2.Request("http://www.baidu.com",headers=header )
response = urllib2.urlopen(request)
html = response.read()
print (html)
我们爬取的数据可分为结构化和非结构化两种
- 结构化数据:XML\JSON格式文件
- 非结构化数据:文本、图片、HTML文件
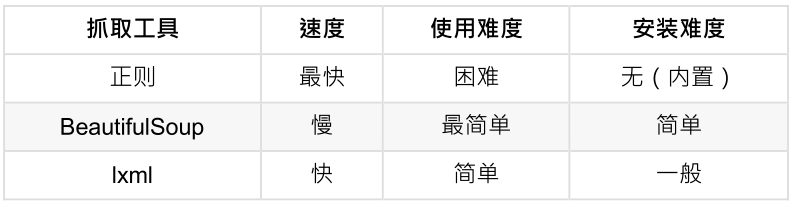
lxml VS BeautifulSoup
lxml为局部遍历,效率较高。而BeautifulSoup为全局遍历,基于HTML DOM的,性能较差。
#使用requests编写爬虫代码
import requests
r = requests.get("http://www.baidu.com")
print(r.status_code) #输出状态码
print(r.text) #输出返回文本
print(r.json) #输出json格式文件
print(r.url) #输出访问的url地址
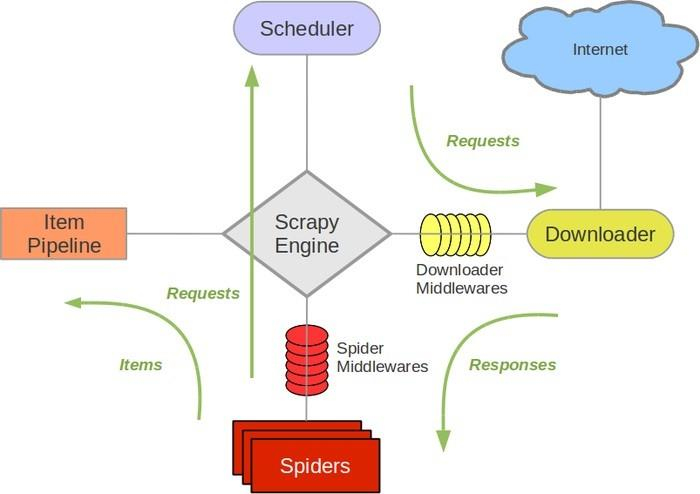
Scrapy架构图
Engine:负责其他组件的运转流程调度。
Scheduler:接收引擎发过来的request请求,并对其进行整理排列。当需要时返还。
Downloader:下载引擎所发送的Requests请求,并将获得的Response交给引擎,由Spider来处理。
Spider:负责从Response中提取Item中需要的数据,并将其他的URL提交给引擎,再转交给Scheduler。
Item PipeLine:负责处理Spider中的Item,并进行后期处理。
Downloader Middlewares:扩展下载功能组件
Spider Middlewares:扩展引擎和Spider通信的功能组件
Scrapy不支持分布式,Scrapy-redis提供了以redis为基础的组件
反爬虫策略:
- 动态设置User-Agent(浏览器识别)
- 禁用cookies
- 使用VPN和代理IP
反爬虫科普:https://segmentfault.com/a/1190000005840672
python爬虫概述的更多相关文章
- 【网络爬虫】【python】网络爬虫(一):python爬虫概述
python爬虫的实现方式: 1.简单点的urllib2 + regex,足够了,可以实现最基本的网页下载功能.实现思路就是前面java版爬虫差不多,把网页拉回来,再正则regex解析信息--总结起来 ...
- 芝麻软件: Python爬虫进阶之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- Python爬虫进阶一之爬虫框架概述
综述 爬虫入门之后,我们有两条路可以走. 一个是继续深入学习,以及关于设计模式的一些知识,强化Python相关知识,自己动手造轮子,继续为自己的爬虫增加分布式,多线程等功能扩展.另一条路便是学习一些优 ...
- Python爬虫之12306-分析请求总概述
python爬虫也学了一段时间了.也爬过不少网站,最后我想用12306抢票器这个项目做一个对之前的学习的效果成见也是一个目标(开始学爬虫的时候,看到说,会爬12306,就会爬80%的网站),本人纯自学 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 【Python】【爬虫】如何学习Python爬虫?
如何学习Python爬虫[入门篇]? 路人甲 1 年前 想写这么一篇文章,但是知乎社区爬虫大神很多,光是整理他们的答案就够我这篇文章的内容了.对于我个人来说我更喜欢那种非常实用的教程,这种教程对于想直 ...
- python爬虫的教程
来源:http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
随机推荐
- React组件:拖拽布局Dragact v0.1.6 发布
仓库地址:Dragact爽滑的拖拽组件 大家好,新年已经过去,大家又投入了繁忙的工作当中,由于我在国外,因此压根儿没有休息... 少说废话,上周一周的时间里,我陆陆续续的为Dragact组件进行了一系 ...
- java8 Date Localdatetime instant 相互转化(转) 及当天的最大/最小时间
Java 8中 java.util.Date 类新增了两个方法,分别是from(Instant instant)和toInstant()方法 // Obtains an instance of Dat ...
- django 模型层(orm)05
目录 配置测试脚本 django ORM基本操作 增删改查 Django 终端打印SQL语句 13条基本查询操作 双下滑线查询 表查询 建表 一对多字段数据的增删改查 多对多字段数据的增删改查 基于对 ...
- expect无交互操作
#!/usr/bin/expect set ip '192.168.4.5' set ' set timeout spawn ssh root@$ip expect { "yes/no&qu ...
- 学习shell(二)
条件分支: (条件表达式的中括号里面 空格不可以省略) = ] then echo '2 = 2'; else echo '2 != 2'; fi # 上面的代码不使用缩进, 并不会出错, 但不应该 ...
- 十大免费SSL证书:网站免费添加HTTPS加密
SSL证书,用于加密HTTP协议,也就是HTTPS.随着淘宝.百度等网站纷纷实现全站Https加密访问,搜索引擎对于Https更加友好,加上互联网上越来越多的人重视隐私安全,站长们给网站添加SSL证书 ...
- 支持快应用的http网络库-flyio
Fly.js 一个基于Promise的.强大的.支持多种JavaScript运行时的http请求库. 有了它,您可以使用一份http请求代码在浏览器.微信小程序.Weex.Node.React Nat ...
- navicat连接oracle报错
Navicat 连接 Oracle ORA-28547:connection to server failed, probable Oracle Net admin error Navicat for ...
- Spring Boot教程(三十八)使用MyBatis注解配置详解(1)
之前在Spring Boot中整合MyBatis时,采用了注解的配置方式,相信很多人还是比较喜欢这种优雅的方式的,也收到不少读者朋友的反馈和问题,主要集中于针对各种场景下注解如何使用,下面就对几种常见 ...
- 2018-2019-2 20165205 网络对抗技术 Exp7 网络欺诈防范
2018-2019-2 20165205 网络对抗技术 Exp7 网络欺诈防范 实验内容 本次实践的目标理解常用网络欺诈背后的原理,以提高防范意识,并提出具体防范方法.具体实践有 (1)简单应用SET ...