验证码识别的免费 OCR
在做接口自动化以及爬虫的过程中,验证码一般是个很烦的存在,其实大厂们已经做好了一些 OCR 供使用,这里介绍一下百度 OCR 的使用方法。
注册并生成应用
1、注册一个百度智能云账号:http://ai.baidu.com/tech/ocr
2、创建一个自己的应用,分类随便选,名字随便起,重要的是需要这三个小东东:
App ID
Api Key
Secret Key
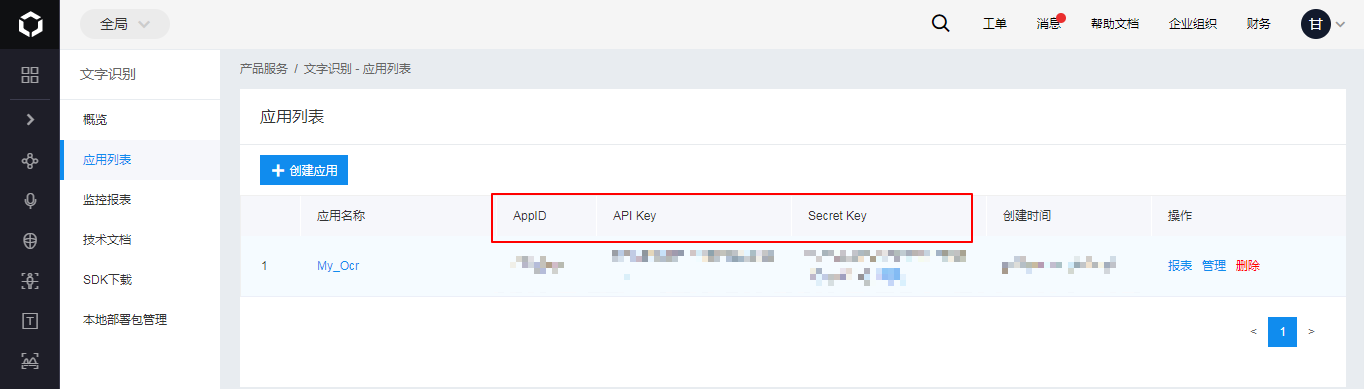
3、注册完成后,在“应用列表”内可以找到自己能使用的 API ,截止这篇博客时间为止,还是可以使用过的。高精度的版本是每天恶意免费使用 500 次,普通版本是 5000 次,对于做自动化来讲,是绝对够了。
使用 OCR
SDK 方式
代码其实不用自己写,百度提供好了技术文档,有 py,java,php 等等

地址:http://ai.baidu.com/docs#/OCR-Python-SDK/top
使用 sdk 的话,以 python 为例:直接 pip install baidu-aip 即可,就可以调用该模块
代码示例(图片在本地的形式):
#创建AipOcr
from aip import AipOcr """ 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key' client = AipOcr(APP_ID, API_KEY, SECRET_KEY) #文字识别高精度版本 """ 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read() image = get_file_content('example.jpg') """ 调用通用文字识别(高精度版) """
client.basicAccurate(image); """ 如果有可选参数 """
options = {}
options["detect_direction"] = "true"
options["probability"] = "true" """ 带参数调用通用文字识别(高精度版) """
client.basicAccurate(image, options)
代码示例(图片为 url 的形式):
#创建AipOcr
from aip import AipOcr """ 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key' client = AipOcr(APP_ID, API_KEY, SECRET_KEY) #文字识别高精度版本 """ 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read() image = get_file_content('example.jpg') """ 调用通用文字识别(含位置高精度版) """
client.accurate(image); """ 如果有可选参数 """
options = {}
options["recognize_granularity"] = "big"
options["detect_direction"] = "true"
options["vertexes_location"] = "true"
options["probability"] = "true" """ 带参数调用通用文字识别(含位置高精度版) """
client.accurate(image, options)
接口文档:https://ai.baidu.com/docs#/OCR-Python-SDK/top
API 方式
http://ai.baidu.com/docs#/OCR-API-AccurateBasic/top
如果你想在 jmeter/Postman 里面使用,当然也是可以的,这里的方式是将图片存到本地的方式,怎么通过 url 转还没发现。
主要是按通过鉴权,然后调用相关的 api 接口,就能返回验证码的数据,鉴权也是调用一个接口做关联即可。
接口文档如下:
接口描述
用户向服务请求识别某张图中的所有文字,相对于通用文字识别该产品精度更高,但是识别耗时会稍长。
请求说明
请求示例
HTTP 方法:POST
请求URL: https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic
URL参数:
| 参数 | 值 |
|---|---|
| access_token | 通过API Key和Secret Key获取的access_token,参考“Access Token获取” |
Header如下:
| 参数 | 值 |
|---|---|
| Content-Type | application/x-www-form-urlencoded |
Body中放置请求参数,参数详情如下:
请求参数
| 参数 | 是否必选 | 类型 | 可选值范围 | 说明 |
|---|---|---|---|---|
| image | true | string | - | 图像数据,base64编码后进行urlencode,要求base64编码和urlencode后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/jpeg/png/bmp格式 |
| detect_direction | false | string | true、false | 是否检测图像朝向,默认不检测,即:false。朝向是指输入图像是正常方向、逆时针旋转90/180/270度。可选值包括: - true:检测朝向; - false:不检测朝向。 |
| probability | false | string | true、false | 是否返回识别结果中每一行的置信度 |
请求代码示例
请参考通用文字识别(含位置信息版)的代码内容,并更换请求地址。
返回说明
返回参数
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| log_id | 是 | uint64 | 唯一的log id,用于问题定位 |
| direction | 否 | int32 | 图像方向,当detect_direction=true时存在。 - -1:未定义, - 0:正向, - 1: 逆时针90度, - 2:逆时针180度, - 3:逆时针270度 |
| words_result | 是 | array() | 识别结果数组 |
| words_result_num | 是 | uint32 | 识别结果数,表示words_result的元素个数 |
| +words | 否 | string | 识别结果字符串 |
| probability | 否 | float | 识别结果中每一行的置信度值,包含average:行置信度平均值,variance:行置信度方差,min:行置信度最小值 |
过程:
关于 api 的实现方式,我们用 jmeter 来举例子:
1、先调用鉴权接口,生成 access_token 关联到识别接口的 url 内;

2、识别接口的 header 要指定:
Content-Type=application/x-www-form-urlencoded
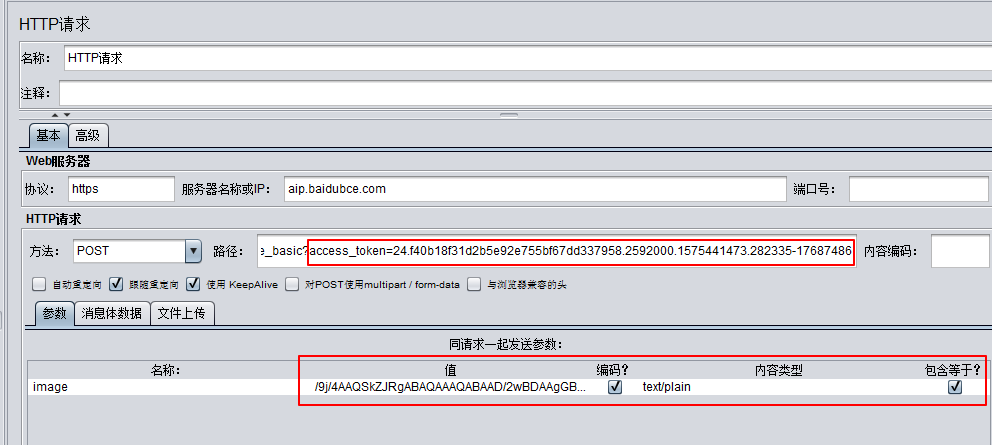
3、关于识别接口,需要的消息体的参数做以下转换:将图片转成 base 64 位编码;再将编码 urlencode
实现方式:
beansell 脚本——待补充
通过在线工具将图片上传(该步骤其实也可以 jmeter 实现,有时间找一个不坑的网站),生成 base64 位编码,如果生成的编码有头再将编码去掉头(有些网站在编码前面会加上 data:image/jpeg;base64, 这一部分是要去除的),再将剩余的部分放进 image 的 value 值里面,同时勾选上 "编码" ,这一步其实就是 urlencode 了,发送过去看返回结果:
{
"log_id": ,
"words_result": [
{
"words": "4F4T9"
}
],
"words_result_num":
}
发现确实返回了要的结果,大功告成
验证码识别的免费 OCR的更多相关文章
- ocr智能图文识别 tess4j 图文,验证码识别 分享及所遇到的问题
自己对tess4j的使用总结 1,tess4j 封装了 tesseract-ocr 的操作 可以用很简洁的几行代码就实现原本tesseract-ocr 复杂的实现逻辑 如果你也想了解tesseract ...
- ocr智能图文识别 tess4j 图文,验证码识别
最近写爬虫采集数据,遇到网站登录需要验证码校验,想了想有两种解决办法 1,利用htmlunit,将验证码输入到swing中,并弹出一个输入框,手动输入验证码,这种实现方式,如果网站需要登录一次可以使用 ...
- Mac python Tesseract 验证码识别
Tesseract 简介 Tesseract(/'tesərækt/) 这个词的意思是"超立方体",指的是几何学里的四维标准方体,又称"正八胞体".不过这里要讲 ...
- windows下简单验证码识别——完美验证码识别系统
此文已由作者徐迪授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 讲到验证码识别,大家第一个可能想到tesseract.诚然,对于OCR而言,tesseract确实很强大,自带 ...
- 百度 验证码识别API 使用
先到百度云申请文字识别API ,会给你一个API KEY和一个SECRET KEY,免费,一天最多500次请求. try: temp_url = 'https://aip.baidubce.com/o ...
- captcha-killer burp验证码识别插件体验
0x01 使用背景 在渗透测试和src挖洞碰到验证码不可绕过时,就会需要对存在验证码的登录表单进行爆破,以前一直使用PKav HTTP Fuzzer和伏羲验证码识别来爆破,但是两者都有缺点PKav H ...
- 【爬虫系列】1. 无事,Python验证码识别入门
最近在导入某站数据(正经需求),看到他们的登录需要验证码, 本来并不想折腾的,然而Cookie有效期只有一天. 已经收到了几次夜间报警推送之后,实在忍不住. 得嘞,还是得研究下模拟登录. 于是,秃头了 ...
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- 利用开源程序(ImageMagick+tesseract-ocr)实现图像验证码识别
--------------------------------------------------低调的分割线-------------------------------------------- ...
随机推荐
- 关于Vue.use()详解
问题 相信很多人在用Vue使用别人的组件时,会用到 Vue.use() .例如:Vue.use(VueRouter).Vue.use(MintUI).但是用 axios时,就不需要用 Vue.use( ...
- 记一次用WireShark抓包摆脱Si服后台限制的过程
背景:闲着无聊找了个小众的手游,因为手游都是比较吃金的,所以就找了个Si服,鉴于小时候宝可梦的情怀,就TB买了个GM后台.谁知这玩意有限制,到了100级之后升级超级难,最多只能发送99999W点经验, ...
- excel_vlookup函数_python代码实现
python入门经典视频系列教程(免费,2K超清,送书) https://study.163.com/course/courseMain.htm?courseId=1006183019&sha ...
- angular自定义组件
https://cli.angular.io/ 打开终端创建header组件: ng g component components/header import { Component, OnInit ...
- 利用redis实现分布式事务锁,解决高并发环境下库存扣减
利用redis实现分布式事务锁,解决高并发环境下库存扣减 问题描述: 某电商平台,首发一款新品手机,每人限购2台,预计会有10W的并发,在该情况下,如果扣减库存,保证不会超卖 解决方案一 利用数据 ...
- 123457123457#1#-----com.threeapp.circlerunner01----儿童旋转跑酷游戏
com.threeapp.circlerunner01----儿童旋转跑酷游戏
- Spring Boot中一个Servlet主动断开连接的方法
主动断开连接,从而返回结果给客户端,并且能够继续执行剩余代码. 对于一个HttpServletResponse类型的对象response来说,执行如下代码: response.getWriter(). ...
- 如何调试Maven软件的源代码
和调试maven插件方法一样 修改maven源代码 打包模块apache-maven,生成apache-maven-x.x.x-bin.tar.gz 解压上面的压缩包,生成目录apache-maven ...
- gocheck框架
1. 引用包 : gocheck "gopkg.in/check.v1" 2. 自动化测试入口 :Test_run(t *testing.T) 3. 将自定义的测试用例集, ...
- 【VS2015软件报错】命名空间 system.windows 中不存在类型或命名空间名称 forms (是否缺少程序集引用 )错误
C#项目: 添加“using System.Windows.Forms;”之后提示“命名空间 system.windows 中不存在类型或命名空间名称 forms (是否缺少程序集引用 )”错误 详细 ...