Flask上下文源码分析(二)
前面第一篇主要记录了Flask框架,从http请求发起,到返回响应,发生在server和app直接的过程。
里面有说到,Flask框架有设计了两种上下文,即应用上下文和请求上下文
官方文档里是说先理解应用上下文比较好,不过我还是觉得反过来,从请求上下文开始记录比较合适,所以这篇先记录请求上下文。
什么是请求上下文
通俗点说,其实上下文就像一个容器,包含了很多你需要的信息
request和session都属于请求上下文
request 针对的是http请求作为对象
session针对的是更多是用户信息作为对象
上下文的结构
说到上下文这个概念的数据结构,这里需要先知道,他是运用了一个Stack的栈结构,也就说,有栈所拥有的特性,push,top,pop等
请求上下文 ----- RequestContext
当一个请求进来的时候,请求上下文环境是如何运作的呢?还是需要来看一下源码
上一篇有讲到,当一个请求从server传递过来的时候,他会调用Flask的__call__方法,所以这里还是回到wsgi_app那部分去讲
下面是当wsgi_app被调用的时候,最一开始的动作,这里的ctx是context的缩写
- class Flask(_PackageBoundObject):
- # 省略一部分代码
- def wsgi_app(self, environ, start_response):
- ctx = self.request_context(environ) #上下文变量ctx被赋值为request_context(environ)的值
- ctx.push() #
再来看下request_context是一个什么样的方法,看看源码
看他的返回值,他返回的其实是RequestContext类生成的一个实例对象,看字面意思就知道是一个请求上下文的实例对象了.
这里可以注意看下他的函数说明,他举了一个例子,非常简单,ctx先push,最后再pop,和用with的方法作用是一毛一样的
这其实就是一个请求到响应最简单的骨架,侧面反映了request的生命周期
- class Flask(_PackageBoundObject):
- #省略部分代码
- def request_context(self, environ):
- """ctx = app.request_context(environ)
- ctx.push()
- try:
- do_something_with(request)
- finally:
- ctx.pop()"""
- return RequestContext(self, environ)
继续往下层看,RequestContext是从ctx.py模块中引入的,所以去找RequestContext的定义
- class RequestContext(object):
- """The request context contains all request relevant information. It is
- created at the beginning of the request and pushed to the
- `_request_ctx_stack` and removed at the end of it. It will create the
- URL adapter and request object for the WSGI environment provided.
- Do not attempt to use this class directly, instead use
- :meth:`~flask.Flask.test_request_context` and
- :meth:`~flask.Flask.request_context` to create this object."""
- #省略部分说明
- def __init__(self, app, environ, request=None):
- self.app = app
- if request is None:
- request = app.request_class(environ)
- self.request = request
- self.url_adapter = app.create_url_adapter(self.request)
- self.flashes = None
- self.session = None
- #省略部分代码
- def push(self):
- top = _request_ctx_stack.top
- if top is not None and top.preserved:
- top.pop(top._preserved_exc)
- app_ctx = _app_ctx_stack.top
- if app_ctx is None or app_ctx.app != self.app:
- app_ctx = self.app.app_context()
- app_ctx.push()
- self._implicit_app_ctx_stack.append(app_ctx)
- else:
- self._implicit_app_ctx_stack.append(None)
- if hasattr(sys, 'exc_clear'):
- sys.exc_clear()
- _request_ctx_stack.push(self)
注意一下__init__方法,他的第一个参数是app实例对象,所以在前面额app.py文件内,他的生成方法第一个参数是self,另外,还要传入environ参数
这样,回到wsgi_app的函数内部,我们其实已经有了ctx这个变量的值了
所以接下去的一步就是非常重要的ctx.push()了
首先会判断上下文栈的顶端是否有元素,如果是没元素的,就返回None
如果有元素,会弹出该元素
接着看最后一行,会进行_request_ctx_stack的push动作,参数是self,这里的self实际上就是上下文实例 ctx,也就是说,把上下文的内容进行压栈,放到栈顶了。
看到这里,又引入了一个新的对象 _request_ctx_stack,这其实是一个非常重要的概念,他就是上下文环境的数据结构,也就是栈结构
继续找这个对象来自哪里,发现他来自于同级目录的globals,打开后发现,原来所有的上下文环境的定义,都在这里,怪不得名字取成全局变量
- def _lookup_req_object(name):
- top = _request_ctx_stack.top
- if top is None:
- raise RuntimeError(_request_ctx_err_msg)
- return getattr(top, name)
- def _lookup_app_object(name):
- top = _app_ctx_stack.top
- if top is None:
- raise RuntimeError(_app_ctx_err_msg)
- return getattr(top, name)
- def _find_app():
- top = _app_ctx_stack.top
- if top is None:
- raise RuntimeError(_app_ctx_err_msg)
- return top.app
- # context locals
- _request_ctx_stack = LocalStack() #请求上下文的数据结构
- _app_ctx_stack = LocalStack() #引用上下文的数据结构
- current_app = LocalProxy(_find_app) #从这个开始的4个,都是全局变量,他们其实通过代理上下文来实现的
- request = LocalProxy(partial(_lookup_req_object, 'request'))
- session = LocalProxy(partial(_lookup_req_object, 'session'))
- g = LocalProxy(partial(_lookup_app_object, 'g'))
上下文的数据结构分析
看到 _request_ctx_stack是LocalStack的实例对象,那就去找LocalStack的源码了,他来自于werkzeug工具包里面的local模块
- class LocalStack(object):
- def __init__(self):
- self._local = Local()
- #中间省略部分代码
- def push(self, obj):
- """Pushes a new item to the stack"""
- rv = getattr(self._local, 'stack', None)
- if rv is None:
- self._local.stack = rv = []
- rv.append(obj)
- return rv
- #中间省略部分代码
- @property
- def top(self):
- """The topmost item on the stack. If the stack is empty,
- `None` is returned.
- """
- try:
- return self._local.stack[-1]
- except (AttributeError, IndexError):
- return None
其中最主要的三个方法是,__init__初始化方法, push压栈方法,以及top元素的访问方法
__init__初始化方法其实很简单,他把LocalStack的实例(也就是_request_ctx_stack)的_local属性,设置为了Local类的实例
所以这里需要先看一下Local类的定义,他和LocalStack在同一个模块内
- class Local(object):
- __slots__ = ('__storage__', '__ident_func__')
- def __init__(self):
- object.__setattr__(self, '__storage__', {})
- object.__setattr__(self, '__ident_func__', get_ident)
- def __call__(self, proxy):
- """Create a proxy for a name."""
- return LocalProxy(self, proxy)
- def __getattr__(self, name):
- try:
- return self.__storage__[self.__ident_func__()][name]
- except KeyError:
- raise AttributeError(name)
- def __setattr__(self, name, value):
- ident = self.__ident_func__()
- storage = self.__storage__
- try:
- storage[ident][name] = value
- except KeyError:
- storage[ident] = {name: value}
Local类的实例对象,其实就是包含了2个属性
一个叫 __storage__ 的字典
另一个叫 __ident_func__ 的方法,他这个方法其实是get_ident,这个方法不多说,他是从_thread内置模块里面导入的,他的作用是返回线程号
这部分有点绕,因为在Local和LocalStack两个类里面来回穿梭
Local类的定义看完以后,回过去看LocalStack的push方法
- def push(self, obj):
- """Pushes a new item to the stack"""
- rv = getattr(self._local, 'stack', None)
- if rv is None:
- self._local.stack = rv = []
- rv.append(obj)
- return rv
他会先去取 LocalStack实例的_local属性,也就是Local()实例的stack属性, 如果没有这个属性,则返回None
如果是None的话,则开始建立上下文栈结构,返回值rv代表上下文的整体结构
_local的stack属性就是一个栈结构
这里的obj,其实是对应最一开头的RequestContext里面的push方法里的self,也就是,他在push的时候,传入的对象是上下文RequestContext的实例对象
这里要再看一下Local类的__setattr__方法了,看看他如何赋值
- def __setattr__(self, name, value):
- ident = self.__ident_func__()
- storage = self.__storage__
- try:
- storage[ident][name] = value
- except KeyError:
- storage[ident] = {name: value}
他其实是一个字典嵌套的形式,因为__storage__本身就是一个字典,而name和value又是一组键值
注意,value本身也是一个容器,是list
所以,他的内部形式实际上是 __storage__ ={{ident1:{name1:value1}},{ident2:{name2:value2}},{ident3:{name3:value3}}}
他的取值方式__getattr__ 就是__storage__[self.__ident_func__()][name]
这样每个线程对应的上下文栈都是自己本身,不会搞混。
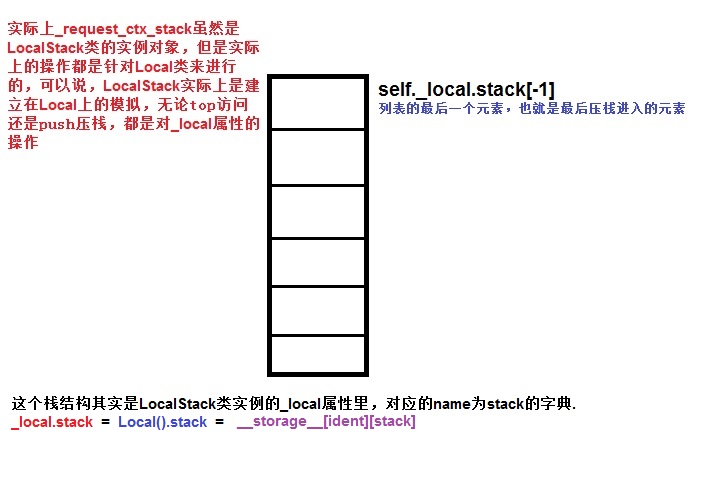
至此,当一个请求上下文环境被建立完之后,到储存到栈结构顶端的过程,就完成了。
这个时候,栈顶元素里面已经包含了大量的信息了,包括像这篇文章里面最重要的概念的request也包含在里面了
全局变量request
来看一下request的定义,他其实是栈顶元素的name属性,经过LocalProxy形成的一个代理
- request = LocalProxy(partial(_lookup_req_object, 'request'))
以上代码可以看成是 request = LocalProxy(_request_ctx_stack.top.request) = LocalProxy (_request_ctx_stack._local[stack][-1].request)
也就是栈顶元素内,name叫做request对象的值,而这个值,包含了很多的内容,包括像 HTTP请求头的信息,都包括在内,可以提供给全局使用
但是,这个request对象,早在RequestContext实例创建的时候,就被建立起来了
- def __init__(self, app, environ, request=None):
- self.app = app
- if request is None:
- request = app.request_class(environ)
- self.request = request
- self.url_adapter = app.create_url_adapter(self.request)
- self.flashes = None
- self.session = None
这个是RequestContext类的定义,他的实例有request=app.request_class属性
实例被压入上下文栈顶之后,只是通过LocalProxy形成了新的代理后的request,但是内容其实是前面创建的。
所以说,他才能够使用request这个属性来进行请求对象的访问
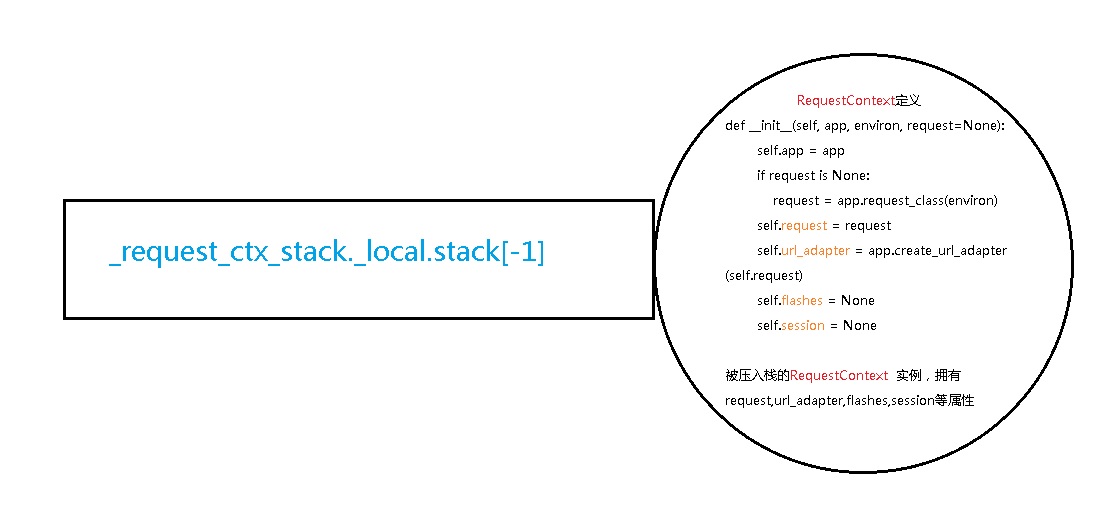
request来自于Request类
上面的request对象,是通过RequestContext的定义中
request = app.request_class(environ)建立起来的,而request_class = Request类,而Request类则是取自于werkzeuk的 wrappers模块
这个有空再研究了,主要还是和HTTP请求信息有关系的,比如header parse,ETAG,user Agent之类
- class Request(BaseRequest, AcceptMixin, ETagRequestMixin,
- UserAgentMixin, AuthorizationMixin,
- CommonRequestDescriptorsMixin):
- """Full featured request object implementing the following mixins:
- - :class:`AcceptMixin` for accept header parsing
- - :class:`ETagRequestMixin` for etag and cache control handling
- - :class:`UserAgentMixin` for user agent introspection
- - :class:`AuthorizationMixin` for http auth handling
- - :class:`CommonRequestDescriptorsMixin` for common headers
- """
所以说,通过RequestContext上下文环境被压入栈的过程,flask将app和request进行了挂钩.
LocalProxy到底是一个什么东西
LocalProxy的源代码太长了,就不贴了,关键看下LocalProxy和Local及LocalProxy之间的关系
Local和LocalStack的__call__方法,都会将实例,转化成LocalProxy对象
- class LocalStack(object):
- #省略部分代码
- def __call__(self):
- def _lookup():
- rv = self.top
- if rv is None:
- raise RuntimeError('object unbound')
- return rv
- return LocalProxy(_lookup)
- class Local(object):
- #省略部分代码
- def __call__(self, proxy):
- """Create a proxy for a name."""
- return LocalProxy(self, proxy)
而LocalProxy最关键的就是一个_get_current_object方法,一个__getattr__的重写
- @implements_bool
- class LocalProxy(object):
- #省略部分代码
- __slots__ = ('__local', '__dict__', '__name__')
- def __init__(self, local, name=None):
- object.__setattr__(self, '_LocalProxy__local', local)
- object.__setattr__(self, '__name__', name)
- def _get_current_object(self):
- """Return the current object. This is useful if you want the real
- object behind the proxy at a time for performance reasons or because
- you want to pass the object into a different context.
- if not hasattr(self.__local, '__release_local__'):
- return self.__local()
- try:
- return getattr(self.__local, self.__name__)
- except AttributeError:
- raise RuntimeError('no object bound to %s' % self.__name__) """
- def __getattr__(self, name):
- if name == '__members__':
- return dir(self._get_current_object())
- return getattr(self._get_current_object(), name)
__getattr__方法和 _get_current_object方法联合一起,返回了真实对象的name属性,name就是你想要获取的信息.
这样,你就可以通过request.name 来进行request内部信息的访问了。
Flask上下文源码分析(二)的更多相关文章
- Flask上下文源码分析(一)
flask中的上下文分两种,application context和request context,即应用上下文和请求上下文. 从名字上看,可能会有误解,认为应用上下文是一个应用的全局变量,所有请 ...
- Flask框架 (四)—— 请求上下文源码分析、g对象、第三方插件(flask_session、flask_script、wtforms)、信号
Flask框架 (四)—— 请求上下文源码分析.g对象.第三方插件(flask_session.flask_script.wtforms).信号 目录 请求上下文源码分析.g对象.第三方插件(flas ...
- Flask系列10-- Flask请求上下文源码分析
总览 一.基础准备. 1. local类 对于一个类,实例化得到它的对象后,如果开启多个线程对它的属性进行操作,会发现数据时不安全的 import time from threading import ...
- Fresco 源码分析(二) Fresco客户端与服务端交互(1) 解决遗留的Q1问题
4.2 Fresco客户端与服务端的交互(一) 解决Q1问题 从这篇博客开始,我们开始讨论客户端与服务端是如何交互的,这个交互的入口,我们从Q1问题入手(博客按照这样的问题入手,是因为当时我也是从这里 ...
- 框架-springmvc源码分析(二)
框架-springmvc源码分析(二) 参考: http://www.cnblogs.com/leftthen/p/5207787.html http://www.cnblogs.com/leftth ...
- Tomcat源码分析二:先看看Tomcat的整体架构
Tomcat源码分析二:先看看Tomcat的整体架构 Tomcat架构图 我们先来看一张比较经典的Tomcat架构图: 从这张图中,我们可以看出Tomcat中含有Server.Service.Conn ...
- 十、Spring之BeanFactory源码分析(二)
Spring之BeanFactory源码分析(二) 前言 在前面我们简单的分析了BeanFactory的结构,ListableBeanFactory,HierarchicalBeanFactory,A ...
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- 多线程之美8一 AbstractQueuedSynchronizer源码分析<二>
目录 AQS的源码分析 该篇主要分析AQS的ConditionObject,是AQS的内部类,实现等待通知机制. 1.条件队列 条件队列与AQS中的同步队列有所不同,结构图如下: 两者区别: 1.链表 ...
随机推荐
- 这个一个对ES6多个异步处理的并发继发思想的总结和理解
1.首先我们需要理解的是js中for循环.forEach循环.map循环的一些差异性,直接说了为后面说到的提供一些依据 1.1 for循环最基本,也是最容易理解的. 1.2 forEach和map用法 ...
- JS如何做2048(详细)
在做2048之前,我们首先要了解它的游戏规则,以及运行逻辑 首先,来看上半部分 除了标题外还有记录每次获得的分数,以及总分数,还有一个重新开始按钮,这个最大分数会保存下来. 来看页面内容 页面内容由1 ...
- PX4/Pixhawk uORB
PX4/Pixhawk的软件体系结构主要被分为四个层次 应用程序的API:这个接口提供给应用程序开发人员,此API旨在尽可能的精简.扁平及隐藏其复杂性 应用程序框架:这是为操作基础飞行控制的默认程序集 ...
- STM8 工程模版
在st官网下载STM8固件库 拷贝固件库到工程目录下 再创建两个目录 user:存放用户文件.自己编写的源文件 project:存放工程文件 拷贝stm8s_conf.h到user目录下 AIR 创建 ...
- py-1 语言介绍
一.编程与编程语言 1.编程的目的 计算机的发明,是为了用机器取代并解放人力.而编程的目的则是将人类的思想流程按照某种能够被计算机识别的表达方式传递给计算机,从而达到让计算机能够像人脑.电脑一样自动执 ...
- SpringBoot自定义servlet、注册自定义的servlet、过滤器、监听器、拦截器、切面、webmvcconfigureradapter过时问题
[转]https://www.cnblogs.com/NeverCtrl-C/p/8191920.html 1 servlet简介 servlet是一种用于开发动态web资源的技术 参考博客:serv ...
- 为LPC1549 LPCXpresso评估板开发基于mbed的项目
本文将主要介绍如何使用Visual Studio和VisualGDB为LPC1549 LPCXpresso开发板创建一个使用mbed框架的基础项目. LPC1549 LPCXpresso开发板载一个L ...
- P2882 [USACO07MAR]Face The Right Way [贪心+模拟]
题目描述 N头牛排成一列1<=N<=5000.每头牛或者向前或者向后.为了让所有牛都 面向前方,农夫每次可以将K头连续的牛转向1<=K<=N,求操作的最少 次数M和对应的最小K ...
- 第113题:路径总和II
一. 问题描述 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径. 说明: 叶子节点是指没有子节点的节点. 示例: 给定如下二叉树,以及目标和 sum = 22, 5 ...
- postgresql学习笔记--基础篇 - copy
1. psql 导入/导出数据 psql支持文件数据导入到数据库,也支持数据库表数据导出到文件中. COPY命令和\copy 命令都支持这两类操作,但两者有如下区别: COPY 命令是SQL命令,\c ...