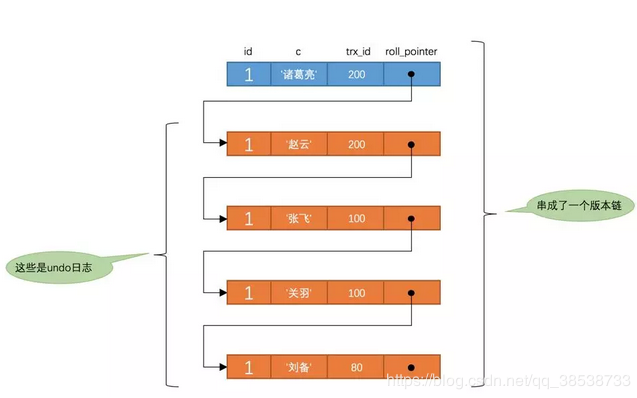
MySQL 事务 MVCC 版本链
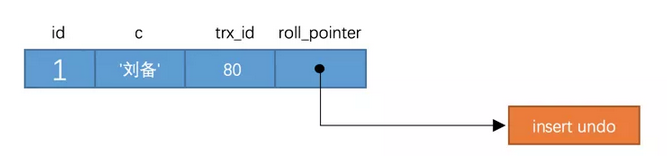
4)如果某个版本的数据对当前事务不可见的话,那就顺着版本链找到下一个版本的数据,继续按照上边的步骤判断可见性,依此类推,直到版本链中的最后一个版本,如果最后一个版本也不可见的话,那么就意味着该条记录对该事务不可见,查询结果就不包含该记录。


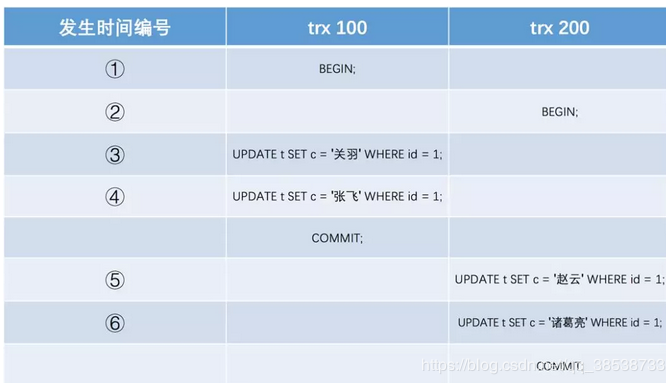
之后,我们把事务id为100的事务提交一下,就像这样:


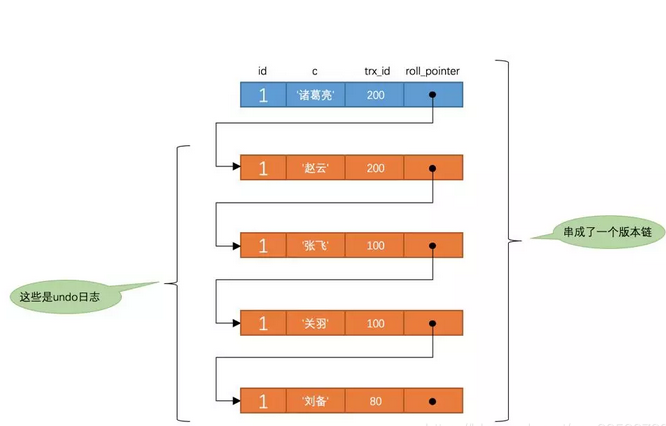
此刻,表t中id为1的记录的版本链就长这样:
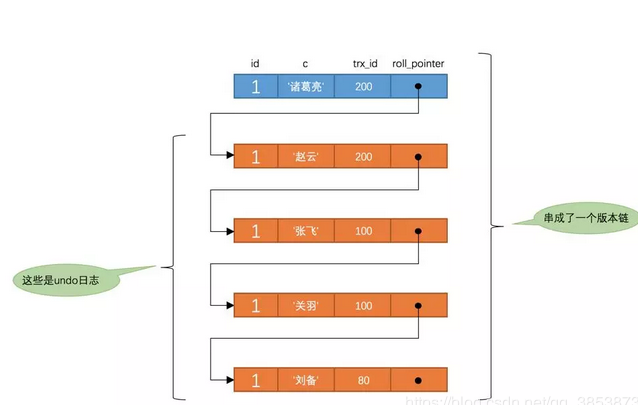

以此类推,如果之后事务id为200的记录也提交了,再此在使用READ COMMITTED隔离级别的事务中查询表t中id值为1的记录时,得到的结果就是'诸葛亮'了,具体流程我们就不分析了。总结一下就是:使用READ COMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。

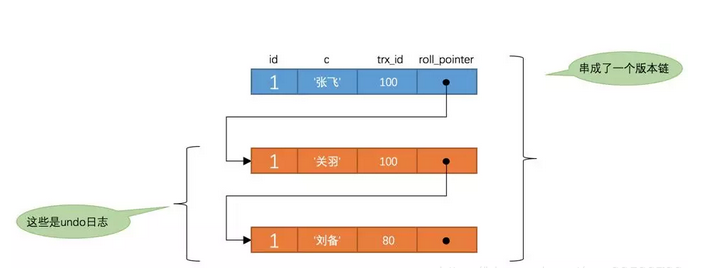
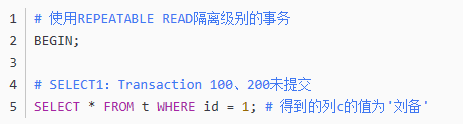



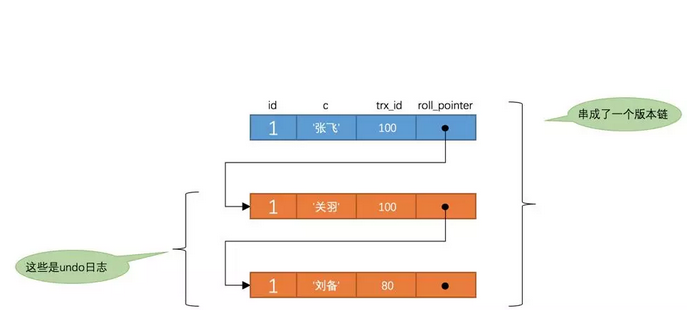
也就是说两次SELECT查询得到的结果是重复的,记录的列c值都是'刘备',这就是可重复读的含义。如果我们之后再把事务id为200的记录提交了,之后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个id为1的记录,得到的结果还是'刘备',具体执行过程大家可以自己分析一下。
---------------------
作者:wust_zwl
来源:CSDN
原文:https://blog.csdn.net/qq_38538733/article/details/88902979
版权声明:本文为博主原创文章,转载请附上博文链接!
MySQL 事务 MVCC 版本链的更多相关文章
- 《Mysql - 事务 MVCC》
一:前言 - 前面通过 <Mysql 事务 - 隔离> 的学习,知道了事务的实现,是根据 获取一致性视图 来实现的. 二:那么,什么时候会获取到一致性视图呢? - 例如:有三个事务,启动的 ...
- mysql事务原理及MVCC
mysql事务原理及MVCC 事务是数据库最为重要的机制之一,凡是使用过数据库的人,都了解数据库的事务机制,也对ACID四个 基本特性如数家珍.但是聊起事务或者ACID的底层实现原理,往往言之不详,不 ...
- 数据库篇:mysql事务原理之MVCC视图+锁
前言 数据库的事务特性 数据并发读写时遇到的一致性问题 mysql事务的隔离级别 MVCC的实现原理 锁和隔离级别 关注公众号,一起交流,微信搜一搜: 潜行前行 1 数据库的事务特性 原子性:同一个事 ...
- 温故知新-Mysql锁&事务&MVCC
文章目录 锁概述 锁分类 MyISAM 表锁 InnoDB 行锁 事务及其ACID属性 InnoDB 的行锁模式 注意 MVCC InnoDB 中的 MVCC 参考 你的鼓励也是我创作的动力 Post ...
- mysql的MVCC多版本并发控制机制
MVCC多版本并发控制机制 全英文名:Multi-Version Concurrency Control MVCC不会通过加锁互斥来保证隔离性,避免频繁的加锁互斥. 而在串行化隔离级别为了保证较高的隔 ...
- 面试官:什么是MySQL 事务与 MVCC 原理?
作者:小林coding 图解计算机基础网站:https://xiaolincoding.com/ 大家好,我是小林. 之前写过一篇 MySQL 的 MVCC 的工作原理,最近有读者在网站上学习的时候, ...
- 一文搞懂MySQL事务的隔离性如何实现|MVCC
关注公众号[程序员白泽],带你走进一个不一样的程序员/学生党 前言 MySQL有ACID四大特性,本文着重讲解MySQL不同事务之间的隔离性的概念,以及MySQL如何实现隔离性.下面先罗列一下MySQ ...
- 「MySQL高级篇」MySQL之MVCC实现原理&&事务隔离级别的实现
大家好,我是melo,一名大三后台练习生,死去的MVCC突然开始拷打我! 引言 MVCC,非常顺口的一个词,翻译起来却不是特别顺口:多版本并发控制. 其中多版本是指什么呢?一条记录的多个版本. 并发控 ...
- Mysql InnoDB多版本并发控制MVCC
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要事务隔离级别 mysql是一个客户端/服务断软件,对于同一个服务器来说,可以有多个客户端进行连接,每一个客户端进行连 ...
随机推荐
- PB笔记之第一行数据不能删除的解决方法
如果第一行数据不能删除,则单独写SQL进行删除 window lw_sheet //dw_1.event pfc_deleterow()long i String ls_manidInteger ls ...
- dg搭建后oracle_redo不存在
目的:在oracle 10.2.0.4 环境中,搭建oracle dg遇到 备库redo不存在的问题,另一位同事搭建oracle 11.2.0.4 dg在备库也遇到同样的问题,如下描述处理过程. 参考 ...
- shellexecute的使用和X64判断
bool RunConsoleAsAdmin(std::string appPath, std::string param, bool wait) { LOG_INFO << " ...
- javascript:void(0);的含义以及使用场景
一.含义: javascript:是伪协议,表示内容通过javascript执行. void(0)表示不作任何操作. 二.使用场景 1.href=”javascript:void(0);” 作用:为了 ...
- java对日开发常用语(词汇)总结
日语 英语 中文 备注 並び順(ならびじゅん) order by 排序 項目(こうもく) field 字段,域 ...
- php批量检测并去除BOM头的代码
开发中会遇到BOM头, 导致程序无法执行. 浏览器返回接口如下图: 去除BOM头解决方法:<?phpini_set('memory_limit','1024M'); function check ...
- VBA日期时间函数(十三)
VBScript日期和时间函数帮助开发人员将日期和时间从一种格式转换为另一种格式,或以适合特定条件的格式表示日期或时间值. 日期函数 编号 函数 描述 1 Date 一个函数,它返回当前的系统日期. ...
- oracle trunc函数用法
转自:https://www.e-learn.cn/content/qita/699481 /**************日期********************/ select trunc(sy ...
- (转)使用SDWebImage和YYImage下载高分辨率图,导致内存暴增的解决办法
http://blog.csdn.net/guojiezhi/article/details/52033796
- javascript_10-函数
函数 //定义函数 0-100 相加 function getSum() { var sum = 0; for (let i = 1; i <= 100; i++) { sum += i; } ...