spark数据倾斜处理
spark数据倾斜处理
- 危害:
- 当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。
- 当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足使得任务失败,并进而引进整个应用失败。
表现:同一个stage的多个task执行时间不一致。
- 原因:
- 机器本身性能,导致速度不一致。
- 数据来源的问题:
- 从数据源直接读取。如读取HDFS,Kafka
- 读取上一个Stage的Shuffle数据
如何缓解/消除数据倾斜
kafka:取决于kafka topic中消息在partition是否分布均匀。随机partition没问题,其他没有分布均匀的情况需要另外处理。
hdfs: 使文件可切分或者保证各文件的数据量基本一致。
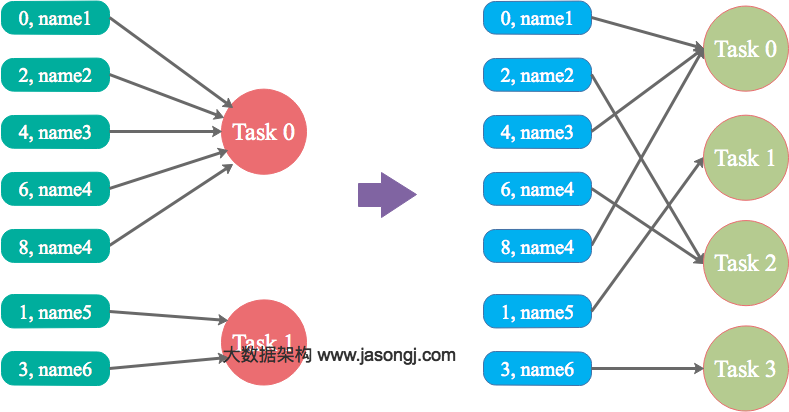
shuffle: 调整并行度分散同一个Task的不同Key。
Spark在做Shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的Key对应的数据被分配到了同一个Task上,造成该Task所处理的数据远大于其它Task,从而造成数据倾斜。
简单说,数据根据并行度做hashpartionter时,可能没分配均匀,此时可以通过调整并行度来改变。
优势
实现简单,可在需要Shuffle的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
劣势
适用场景少,只能将分配到同一Task的不同Key分散开,但对于同一Key倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
自定义Partitioner
原理:
使用自定义的Partitioner(默认为HashPartitioner),将原本被分配到同一个Task的不同Key分配到不同Task。
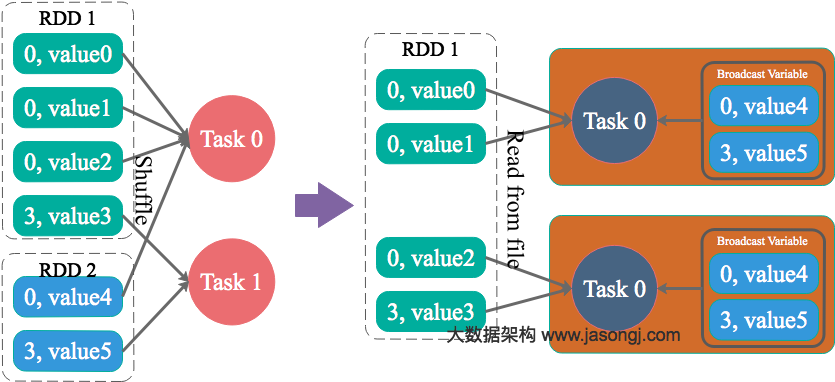
将Reduce side Join转变为Map side Join
原理:
通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle从而完全消除Shuffle带来的数据倾斜
为skew的key增加随机前/后缀
原理:
为数据量特别大的Key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的Task中,彻底解决数据倾斜问题。Join另一则的数据中,与倾斜Key对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。
大表随机添加N种随机前缀,小表扩大N倍
原理:
如果出现数据倾斜的Key比较多,上一种方法将这些大量的倾斜Key分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)
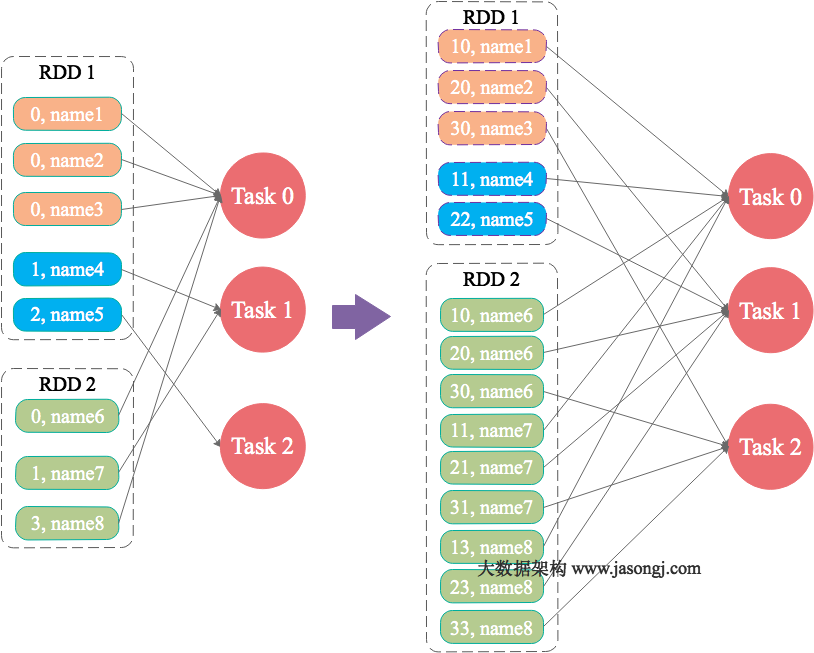
为什么小表要扩大?
因为两个表的数据本来是可以join上,现在加上大表加上随机前缀,小表也需要加上同样的前缀才能join上。
优势
对大部分场景都适用,效果不错。
劣势
需要将一个数据集整体扩大N倍,会增加资源消耗。
总结
避免spark数据倾斜的办法,就是在了解其执行机制的基础上,尽可能的分散key。针对不同的情况,采取不同的策略。
参考文献
Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
spark数据倾斜处理的更多相关文章
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- Spark 数据倾斜
Spark 数据倾斜解决方案 2017年03月29日 17:09:58 阅读数:382 现象 当你的应用程序发生以下情况时你该考虑下数据倾斜的问题了: 绝大多数task都可以愉快的执行,总 ...
- spark 数据倾斜的一些表现
spark 数据倾斜的一些表现 https://yq.aliyun.com/articles/62541
- Spark数据倾斜解决方案(转)
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/skew/ Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 发表于 2017 ...
- 最详细10招Spark数据倾斜调优
最详细10招Spark数据倾斜调优 数据量大并不可怕,可怕的是数据倾斜 . 数据倾斜发生的现象 绝大多数 task 执行得都非常快,但个别 task 执行极慢. 数据倾斜发生的原理 在进行 shuff ...
- Spark数据倾斜及解决方案
一.场景 1.绝大多数task执行得都非常快,但个别task执行极慢.比如,总共有100个task,97个task都在1s之内执行完了,但是剩余的task却要一两分钟.这种情况很常见. 2.原本能够正 ...
- spark数据倾斜
数据倾斜的主要问题在于,某个分区数量很巨大,在做map运算的时候,将会发生别的分区task很快计算完成,但是某几个分区task的计算成为了系统的瓶颈,明显超过其他分区时间: 1.方案:Kafka的 ...
- Spark 数据倾斜调优
一.what is a shuffle? 1.1 shuffle简介 一个stage执行完后,下一个stage开始执行的每个task会从上一个stage执行的task所在的节点,通过网络传输获取tas ...
- Spark数据倾斜解决方案及shuffle原理
数据倾斜调优与shuffle调优 数据倾斜发生时的现象 1)个别task的执行速度明显慢于绝大多数task(常见情况) 2)spark作业突然报OOM异常(少见情况) 数据倾斜发生的原理 在进行shu ...
随机推荐
- 剑指offer17:输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
1 题目描述 输入两棵二叉树A,B,判断B是不是A的子结构.(ps:我们约定空树不是任意一个树的子结构) 2 思路和方法 (1)先在A中找和B的根节点相同的结点 (2)找到之后遍历对应位置的其他结点, ...
- getContextPath、getServletPath、getRequestURI、getRealPath、getRequestURL、getPathInfo();的区别
<% out.println("getContextPath: "+request.getContextPath()+"<br/>"); ou ...
- DVWA漏洞演练平台 - SQL注入
SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令,具体来说,它是利用现有应用程序将(恶意的)SQL命令注入到后台数据库引擎执 ...
- S4VM解析
S4VM解析 2018年08月03日 15:20:59 stringlife 阅读数 1233 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. ...
- eclipse导入maven空项目,eclipse导入时不识别maven项目
经常我们在网上下载的一些开源项目中,想要导入eclipse中,却发现eclipse不识别这个项目,这时候怎么办呢? 解决办法多种多样,我这里举例出最实用的2种: 1.在项目的根目录中加入.classp ...
- async/await 的引用
static async void Start() { string s = "ass"; Console.WriteLine(getMemory(s)+"Hello W ...
- luogu1313计算系数题解--二项式定理
题目链接 https://www.luogu.org/problemnew/show/P1313 分析 二项式定理 \((a+b)^n=\sum_{k=0}^{n}{C^k_n a^k b^{n-k} ...
- 前端必学TypeScript之第一弹,st基础类型!
TypeScript 是微软开发的 JavaScript 的超集,TypeScript兼容JavaScript,可以载入JavaScript代码然后运行.TypeScript与JavaScript相比 ...
- VirtualBox使用
热键:Right Ctrl 串口 端口编号: COM1 -> /dev/ttyS0 COM2 -> /dev/ttyS1 COM3 -> /dev/ttyS2 COM4 -> ...
- C#面向对象(抽象类、接口、构造函数、重载、静态方法和静态成员)
1.抽象类 抽象类关键词 abstract (抽象) override (重写) 在父集中用 abstract 表示抽象类,抽象方法,在子集中用 override 改写 抽 ...