hdfs存储与数据同步
两个hadoop集群之间同步数据
实例为dws的 store_wt_d表
一 文件拷贝
hadoop distcp -update -skipcrccheck hdfs://10.8.31.14:8020/user/hive/warehouse/dws.db/store_wt_d/ hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d/
-skipcrccheck 跳过检验
二 找到源地址对应的文件的数据库以及表的结构
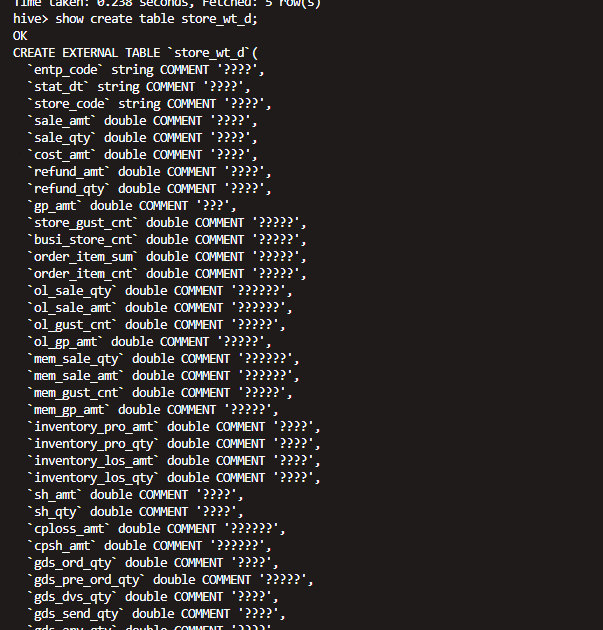
use dws
show create table store_wt_d;
三 在新的集群上面创建对应的库表
辅助刚刚那台语句 修改对应集群的存储地址
CREATE EXTERNAL TABLE `store_wt_d`(
`entp_code` string COMMENT '????',
`stat_dt` string COMMENT '????',
`store_code` string COMMENT '????',
`sale_amt` double COMMENT '????',
`sale_qty` double COMMENT '????',
`cost_amt` double COMMENT '????',
`refund_amt` double COMMENT '????',
`refund_qty` double COMMENT '????',
`gp_amt` double COMMENT '???',
`store_gust_cnt` double COMMENT '?????',
`busi_store_cnt` double COMMENT '?????',
`order_item_sum` double COMMENT '?????',
`order_item_cnt` double COMMENT '?????',
`ol_sale_qty` double COMMENT '??????',
`ol_sale_amt` double COMMENT '??????',
`ol_gust_cnt` double COMMENT '?????',
`ol_gp_amt` double COMMENT '?????',
`mem_sale_qty` double COMMENT '??????',
`mem_sale_amt` double COMMENT '??????',
`mem_gust_cnt` double COMMENT '?????',
`mem_gp_amt` double COMMENT '?????',
`inventory_pro_amt` double COMMENT '????',
`inventory_pro_qty` double COMMENT '????',
`inventory_los_amt` double COMMENT '????',
`inventory_los_qty` double COMMENT '????',
`sh_amt` double COMMENT '????',
`sh_qty` double COMMENT '????',
`cploss_amt` double COMMENT '??????',
`cpsh_amt` double COMMENT '??????',
`gds_ord_qty` double COMMENT '????',
`gds_pre_ord_qty` double COMMENT '?????',
`gds_dvs_qty` double COMMENT '????',
`gds_send_qty` double COMMENT '????',
`gds_arv_qty` double COMMENT '????',
`gds_arv_amt` double COMMENT '????',
`gds_take_qty` double COMMENT '????',
`rtn_bk_ps_qty` double COMMENT '??????',
`gds_need_qty` double COMMENT '????',
`stk_amt` double COMMENT '????',
`stk_qty` double COMMENT '????',
`ini_stk_qty` double COMMENT '??????',
`ini_stk_amt` double COMMENT '??????',
`fnl_stk_qty` double COMMENT '??????',
`fnl_stk_amt` double COMMENT '??????',
`iwh_as_qty` double COMMENT '????????',
`iwh_as_amt` double COMMENT '????????',
`iwh_as_gp_amt` double COMMENT '?????????',
`gds_arv_iwh_qty` double COMMENT '??????',
`gds_arv_iwh_amt` double COMMENT '??????',
`gds_arv_iwh_gp_amt` double COMMENT '???????',
`transfer_iwh_qty` double COMMENT '??????',
`transfer_iwh_amt` double COMMENT '??????',
`transfer_iwh_gp_amt` double COMMENT '???????',
`iwh_io_qty` double COMMENT '??????',
`iwh_io_amt` double COMMENT '??????',
`iwh_io_gp_amt` double COMMENT '???????',
`iwh_tot_sum_qty` double COMMENT '???????',
`iwh_tot_sum_amt` double COMMENT '???????',
`iwh_tot_sum_gp_amt` double COMMENT '????????',
`owh_as_qty` double COMMENT '????????',
`owh_as_amt` double COMMENT '????????',
`owh_as_gp_amt` double COMMENT '?????????',
`stk_bs_qty` double COMMENT '??????',
`stk_bs_amt` double COMMENT '??????',
`stk_bs_gp_amt` double COMMENT '???????',
`owh_pos_qty` double COMMENT '??????',
`owh_pos_amt` double COMMENT '??????',
`owh_pos_gp_amt` double COMMENT '???????',
`owh_rs_qty` double COMMENT '????????',
`owh_rs_amt` double COMMENT '????????',
`owh_rs_gp_amt` double COMMENT '?????????',
`transfer_owh_qty` double COMMENT '??????',
`transfer_owh_amt` double COMMENT '??????',
`transfer_owh_gp_amt` double COMMENT '???????',
`owh_ly_qty` double COMMENT '??????',
`owh_ly_amt` double COMMENT '??????',
`owh_ly_gp_amt` double COMMENT '???????',
`owh_sc_qty` double COMMENT '??????',
`owh_sc_amt` double COMMENT '??????',
`owh_sc_gp_amt` double COMMENT '???????',
`owh_tot_sum_qty` double COMMENT '???????',
`owh_tot_sum_amt` double COMMENT '???????',
`owh_tot_sum_gp_amt` double COMMENT '????????',
`pk_qty` double COMMENT '????',
`pk_amt` double COMMENT '????',
`pk_gp_amt` double COMMENT '?????',
`pk_tot_sum_qty` double COMMENT '???????',
`pk_tot_sum_amt` double COMMENT '???????',
`pk_tot_sum_gp_amt` double COMMENT '????????',
`stk_item_cnt` double COMMENT '?????',
`unsold_gds_cnt` double COMMENT '?????',
`trgt_sale_amt` double COMMENT '??????',
`trgt_gust_cnt` double COMMENT '?????',
`trgt_gp_amt` double COMMENT '?????',
`synctime` string COMMENT '????')
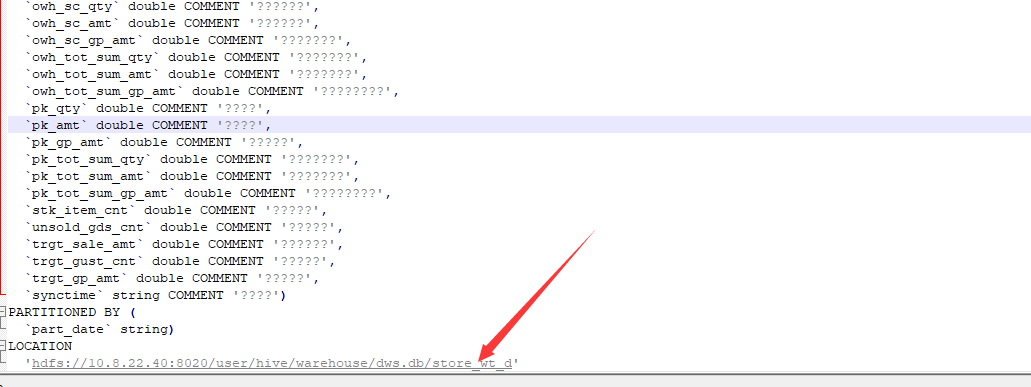
PARTITIONED BY (
`part_date` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
WITH SERDEPROPERTIES (
'field.delim'='-128',
'line.delim'='\n',
'serialization.format'='-128')
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://10.8.22.40:8020/user/hive/warehouse/dws.db/store_wt_d'
四 修复表
msck repair table store_wt_d;
五 查看表情况
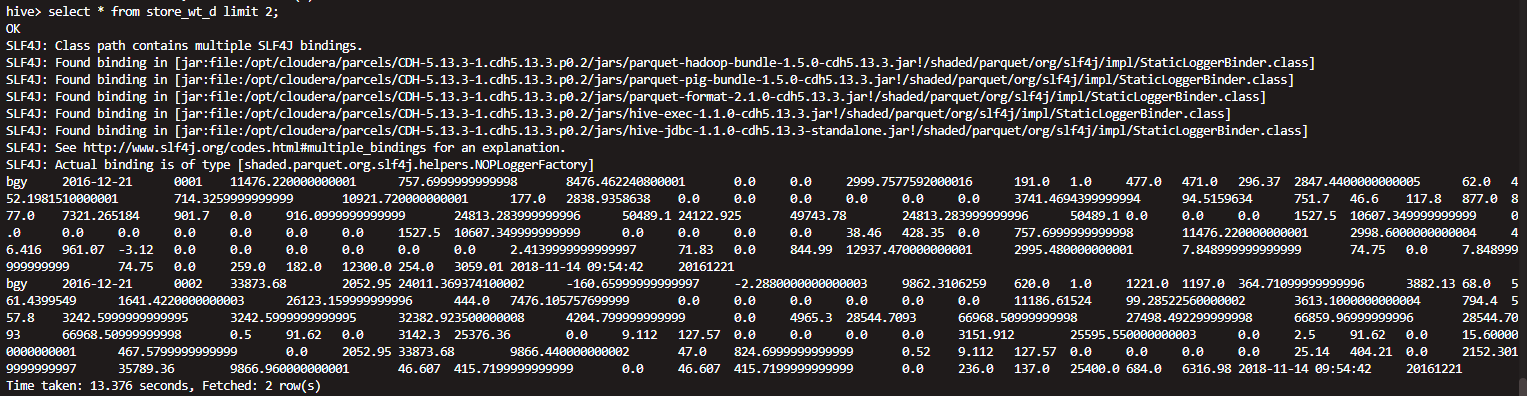
正常
hive--hdfs存储格式测试
hive默认的存储格式是text
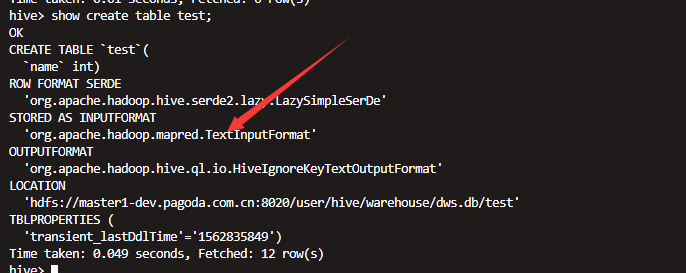
测试 如果一个parquet格式的hive表数据导入到一个text的表之后会有什么情况
创建外表,默认为text格式 但是导入的数据为parquet格式

查看数据发现是乱码
另外如果数据的存储格式是parquet 直接去hdfs上查看也会乱码

如果是text格式存储的
正常

不同格式的相同数据之间的存储对比
上面为parquet压缩的,后面的为没有压缩的(text格式的)
使用压缩
CREATE TABLE `store_wt_d2` STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY') as select * from store_wt_d
再次查看 发现确实量小了不少
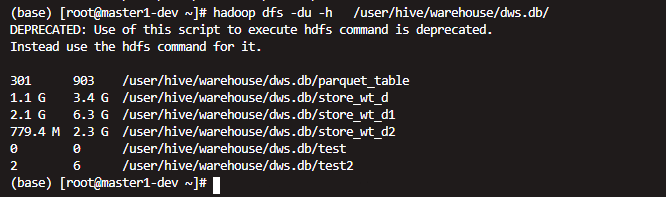
但是时间也明显更长了

创建parquet table :
create table mytable(a int,b int) STORED AS PARQUET;
创建带压缩的parquet table:
create table mytable(a int,b int) STORED AS PARQUET TBLPROPERTIES('parquet.compression'='SNAPPY');
如果原来创建表的时候没有指定压缩,后续可以通过修改表属性的方式添加压缩:
ALTER TABLE mytable SET TBLPROPERTIES ('parquet.compression'='SNAPPY');
或者在写入的时候set parquet.compression=SNAPPY;
不过只会影响后续入库的数据,原来的数据不会被压缩,需要重跑原来的数据。
采用压缩之后大概可以降低1/3的存储大小。
hdfs存储与数据同步的更多相关文章
- Windows下cwrsync客户端与rsync群辉存储客户端数据同步
cwRsync简介 cwRsync是Rsync在Windows上的实现版本,Rsync通过使用特定算法的文件传输技术,可以在网络上传输只修改了的文件. cwRsync主要用于Windows上的远程文件 ...
- 从 RAID 到 Hadoop Hdfs 『大数据存储的进化史』
我们都知道现在大数据存储用的基本都是 Hadoop Hdfs ,但在 Hadoop 诞生之前,我们都是如何存储大量数据的呢?这次我们不聊技术架构什么的,而是从技术演化的角度来看看 Hadoop Hdf ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- 美团DB数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- DB 数据同步到数据仓库的架构与实践
背景 在数据仓库建模中,未经任何加工处理的原始业务层数据,我们称之为ODS(Operational Data Store)数据.在互联网企业中,常见的ODS数据有业务日志数据(Log)和业务DB数据( ...
- 增量数据同步中间件DataLink分享(已开源)
项目介绍 名称: DataLink['deitə liŋk]译意: 数据链路,数据(自动)传输器语言: 纯java开发(JDK1.8+)定位: 满足各种异构数据源之间的实时增量同步,一个分布式.可扩展 ...
- HDFS中的数据块(Block)
我们在分布式存储原理总结中了解了分布式存储的三大特点: 数据分块,分布式的存储在多台机器上 数据块冗余存储在多台机器以提高数据块的高可用性 遵从主/从(master/slave)结构的分布式存储集群 ...
- 环境篇:数据同步工具DataX
环境篇:数据同步工具DataX 1 概述 https://github.com/alibaba/DataX DataX是什么? DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 ...
- 使用Observer实现HBase到Elasticsearch的数据同步
最近在公司做统一日志收集处理平台,技术选型肯定要选择elasticsearch,因为可以快速检索系统日志,日志问题排查及功业务链调用可以被快速检索,公司各个应用的日志有些字段比如说content是不需 ...
随机推荐
- python 通过 实例方法 名字的字符串调用方法
方式1 - 反射 hasattr 方法 判断当前实例中是否有着字符串能映射到的属性或者方法, 一般会在 getattr 之前作为判断防止报错 getattr 方法 获取到当前实例中传入字符串映射到的 ...
- presto安装
下载 presto-server-0.217 包 进入presto根目录,新建脚本deploy.sh mkdir etc cd etc #配置 cat >config.properties &l ...
- 如何写resultful接口
一.协议 API与客户端用户的通信协议,总是使用HTTPS协议,以确保交互数据的传输安全. 二.域名 应该尽量将API部署在专用域名之下: https://api.example.com 如果确定AP ...
- STS中不同包但相同类名引起的问题:A component required a bean of type 'javax.activation.DataSource' that could not be found
1. 问题输出: APPLICATION FAILED TO START*************************** Description: A component required a ...
- 李宏毅 Keras手写数字集识别(优化篇)
在之前的一章中我们讲到的keras手写数字集的识别中,所使用的loss function为‘mse’,即均方差.那我们如何才能知道所得出的结果是不是overfitting?我们通过运行结果中的trai ...
- 【转帖】Office的光荣历史(2)
Office的光荣历史(2) https://www.sohu.com/a/201411215_657550 2017-10-31 10:57 7.MS Office 2000 (Office 9.0 ...
- Excel 下来公式 内容却一样
首先我们打开我们电脑里面的excel2007的软件 我们随便输入一点输入,进行公式计算 我们在上边输入=A1+B1,就能算出这个的结果 我们把上边的公式算好了,点击下拉试试 我们发现虽 ...
- chrome xpath调试
- # Clion中编译多个cpp(实现单文件编译)
Clion中编译多个cpp(实现单文件编译) 在不做任何配置情况下,Clion工程下只能有一个main()函数,新建多个cpp会导致报main()函数重复定义的错误,所以默认情况下无法在一个工程下编译 ...
- 从入门到自闭之Python--MySQL数据库的操作命令
命令: mysqld install; 配置数据库 net start mysql;启动数据库 mysql -uroot -p; 以root权限启动数据库,-p之后输入密码 mysql -uroot ...