python urllib应用
urlopen 爬取网页
爬取网页
read() 读取内容
read() , readline() ,readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
ret = request.urlopen("http://www.baidu.com")
print(ret.read()) #read() 读取网页
urlretrieve 写入文件
直接 将你要爬取得 网页 写到本地
import urllib.request
ret = urllib.request.urlretrieve("url地址","保存的路径地址")
urlcleanup 清除缓存
清除 request.urlretrieve 产生的缓存
print(request.urlcleanup())
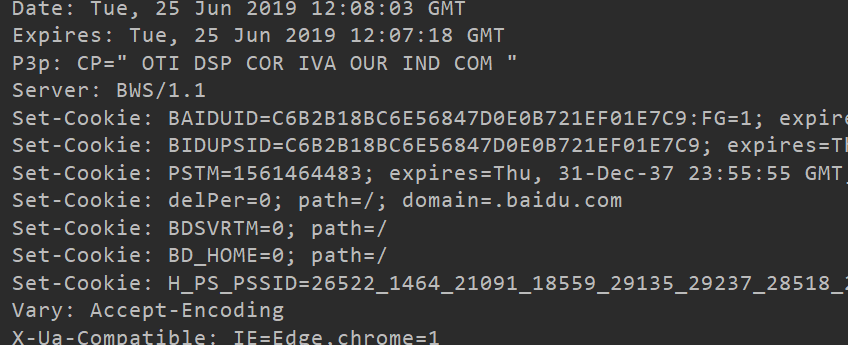
info 显示请求信息
info 返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息
ret = request.urlopen("http://www.baidu.com")
print(ret.info())
etcode 获取状态码
ret = request.urlopen("http://www.baidu.com")
print(ret.getcode()) # 返回200 就是 正常

geturl 获取当前正在爬取的网址
ret = request.urlopen("http://www.baidu.com")
print(ret.geturl)

超时设置
timeout 是以秒来计算的
ret = request.urlopen("http://www.baidu.com",timeout="设置你的超时时间")
print(ret.read())
模拟get 请求
from urllib import request
name = "python" # 你要搜索的 内容
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
print(ret.geturl())
解决中文问题 request.quote
from urllib import request
name = "春生" # 你要搜索的 内容
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
print(ret.geturl())

解决 request.quote
name = "春生" # 你要搜索的 内容
name = request.quote(name) # 解决中文问题
url = "http://www.baidu.com/s?wd=%s"%name
ret_url = request.Request(url) # 发送请求
ret = request.urlopen(url)
print(ret.read().decode("utf-8"))
模拟post 请求
from urllib import request, parse
url = "https://www.iqianyue.com/mypost"
mydata = parse.urlencode({
"name":"哈哈",
"pass":"123"
}).encode("utf-8")
ret_url = request.Request(url, mydata) # 发送请求
ret = request.urlopen(ret_url) # 爬取网页
print(ret.geturl()) # 打印当前爬取的url
print(ret.read().decode("utf-8"))
模拟浏览器 发送请求头
request.Request(url, headers=headers) 加上请求头 模拟浏览器
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("gbk"))
编码出现错误 报错 解决方式
出线的问题
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("utf-8"))

解决问题
decode("utf-8","ignore")
加上 "ignore" 就可以忽略掉
from urllib import request, parse
url = "http://www.xiaohuar.com/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
ret_url = request.Request(url, headers=headers) # 发送请求
ret = request.urlopen(ret_url)
print(ret.geturl())
print(ret.read().decode("utf-8","ignore"))

python urllib应用的更多相关文章
- python urllib模块的urlopen()的使用方法及实例
Python urllib 库提供了一个从指定的 URL 地址获取网页数据,然后对其进行分析处理,获取想要的数据. 一.urllib模块urlopen()函数: urlopen(url, data=N ...
- Python:urllib和urllib2的区别(转)
原文链接:http://www.cnblogs.com/yuxc/ 作为一个Python菜鸟,之前一直懵懂于urllib和urllib2,以为2是1的升级版.今天看到老外写的一篇<Python: ...
- Python urllib和urllib2模块学习(一)
(参考资料:现代魔法学院 http://www.nowamagic.net/academy/detail/1302803) Python标准库中有许多实用的工具类,但是在具体使用时,标准库文档上对使用 ...
- python urllib和urllib2 区别
python有一个基础的库叫httplib.httplib实现了HTTP和HTTPS的客户端协议,一般不直接使用,在python更高层的封装模块中(urllib,urllib2)使用了它的http实现 ...
- Python urllib urlretrieve函数解析
Python urllib urlretrieve函数解析 利用urllib.request.urlretrieve函数下载文件 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Ur ...
- python+urllib+beautifulSoup实现一个简单的爬虫
urllib是python3.x中提供的一系列操作的URL的库,它可以轻松的模拟用户使用浏览器访问网页. Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能 ...
- HTTP Header Injection in Python urllib
catalogue . Overview . The urllib Bug . Attack Scenarios . 其他场景 . 防护/缓解手段 1. Overview Python's built ...
- python urllib urllib2
区别 1) urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,用urllib时不可以伪装User Agent字符串等. 2) u ...
- python urllib基础学习
# -*- coding: utf-8 -*- # python:2.x __author__ = 'Administrator' #使用python创建一个简单的WEB客户端 import urll ...
- python urllib模块
1.urllib.urlopen(url[,data[,proxies]]) urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像 ...
随机推荐
- 算法习题---4-7RAID技术(UV509)
一:题目 (一)基础知识补充(RAID和奇偶校验) 磁盘管理—磁盘阵列(RAID)实例详解(本题目常用RAID 5技术实现) 奇偶校验(同行数据中同位上的1的个数,偶校验时:1的个数为偶数则校验结果为 ...
- Python - Django - Cookie 简单用法
home.html: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- LeetCode_242. Valid Anagram
242. Valid Anagram Easy Given two strings s and t , write a function to determine if t is an anagram ...
- 【大产品思路】Amazon
http://www.woshipm.com/it/2844056.html 强烈赞同,对复杂业务,分布团队和开发可以借鉴. “ 这种公司级“微服务(Microservice)”架构的好处在于,每个团 ...
- Linq中demo,用力看看吧
本文导读:LINQ to SQL全称基于关系数据的.NET语言集成查询,用于以对象形式管理关系数据,并提供了丰富的查询功能.Linq中where查询与SQL命令中的Where作用相似,都是起到范围限定 ...
- keepalived通过飘移ip实现高可用配置步骤
环境:两台虚拟机即可 centos7.3虚拟机A 10.0.3.46 centos7.3虚拟机B 10.0.3.110 对外开放的虚拟ip 10.0.3.96(这个ip只需要在keepalived里面 ...
- Python3 IO编程之文件读写
读写文件是最常见的IO操作.python内置了读写文件的函数,用法和C是兼容的. 读写文件前,我们先必须了解一个,在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序终结操作磁盘, ...
- 接口请求报错 504 Gateway Time-out
最近程序接口请求报了一个错误,如图 很明显的请求超时,以前也没出现过这个问题,突然就报了这个错,很懵. 百度之后网上说是nginx的问题,然后突然想起来,因为业务需要我在nginx里配了接口的转发. ...
- IOPS 测试工具 FIO
FIO是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎. fio-2.8下载: wget http://brick.kernel.dk/snaps/fio-2.8 ...
- 【GStreamer开发】GStreamer基础教程11——调试工具
目标 有时我们的应用并没有按照我们的预期来工作,并且在总线上获得的错误信息也没有足够的内容.这时我们该怎么办呢?幸运的时,GStreamer自身提供了大量的调试信息,通常这些信息会给出一些线索,指向出 ...