啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
一、Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
二、Hadoop发展历史
1)Lucene--Doug Cutting开创的开源软件,用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001年年底成为apache基金会的一个子项目
3)对于大数量的场景,Lucene面对与Google同样的困难
4)学习和模仿Google解决这些问题的办法 :微型版Nutch
5)可以说Google是hadoop的思想之源(Google在大数据方面的三篇论文)
GFS --->HDFS
Map-Reduce --->MR
BigTable --->Hbase
6)2003-2004年,Google公开了部分GFS和Mapreduce思想的细节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS和Mapreduce机制,使Nutch性能飙升
7)2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
8)名字来源于Doug Cutting儿子的玩具大象

9)Hadoop就此诞生并迅速发展,标志这云计算时代来临
三、Hadoop三大发行版本
1)Apache版本最原始(最基础)的版本,对于入门学习最好。
2)Cloudera在大型互联网企业中用的较多。
2.1)2008年成立的Cloudera是最早将Hadoop商用的公司,为合作伙伴提供Hadoop的商用解决方案,主要是包括支持、咨询服务、培训。
2.2)2009年Hadoop的创始人Doug Cutting也加盟Cloudera公司。Cloudera产品主要为CDH,Cloudera Manager,Cloudera Support
2.3)CDH是Cloudera的Hadoop发行版,完全开源,比Apache Hadoop在兼容性,安全性,稳定性上有所增强。
2.4)Cloudera Manager是集群的软件分发及管理监控平台,可以在几个小时内部署好一个Hadoop集群,并对集群的节点及服务进行实时监控。Cloudera Support即是对Hadoop的技术支持。
2.5)Cloudera的标价为每年每个节点4000美元。Cloudera开发并贡献了可实时处理大数据的Impala项目。
3)Hortonworks文档较好。
3.1)2011年成立的Hortonworks是雅虎与硅谷风投公司Benchmark Capital合资组建。
3.2)公司成立之初就吸纳了大约25名至30名专门研究Hadoop的雅虎工程师,上述工程师均在2005年开始协助雅虎开发Hadoop,贡献了Hadoop80%的代码。
3.3)雅虎工程副总裁、雅虎Hadoop开发团队负责人Eric Baldeschwieler出任Hortonworks的首席执行官。
3.4)Hortonworks的主打产品是Hortonworks Data Platform(HDP),也同样是100%开源的产品,HDP除常见的项目外还包括了Ambari,一款开源的安装和管理系统。
3.5)HCatalog,一个元数据管理系统,HCatalog现已集成到Facebook开源的Hive中。Hortonworks的Stinger开创性的极大的优化了Hive项目。Hortonworks为入门提供了一个非常好的,易于使用的沙盒。
3.6)Hortonworks开发了很多增强特性并提交至核心主干,这使得Apache Hadoop能够在包括Window Server和Windows Azure在内的microsoft Windows平台上本地运行。定价以集群为基础,每10个节点每年为12500美元。
四、Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
五、Hadoop组成
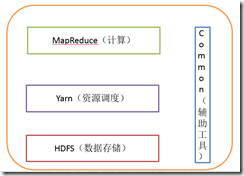
1)概述
1.1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
1.2)Hadoop MapReduce:一个分布式的离线并行计算框架。
1.3)Hadoop YARN:作业调度与集群资源管理的框架。
1.4)Hadoop Common:支持其他模块的工具模块。
2)HDFS架构概述
2.1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
1.2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
1.3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
3)YARN架构概述
3.1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
3.2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3.3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
3.4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
4)MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
4.1)Map阶段并行处理输入数据
4.2)Reduce阶段对Map结果进行汇总
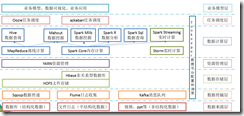
5)大数据技术生态体系
5.1)Sqoop:sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
5.2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
5.3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
5.3.1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
5.3.2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
5.3.3)支持通过Kafka服务器和消费机集群来分区消息。
5.3.4)支持Hadoop并行数据加载。
5.4)Storm:Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5.5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
5.6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。Oozie协调作业就是通过时间(频率)和有效数据触发当前的Oozie工作流程。
5.7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
5.8)Hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
5.10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
5.11)Mahout:Apache Mahout是个可扩展的机器学习和数据挖掘库,当前Mahout支持主要的4个用例:
推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。
聚集:收集文件并进行相关文件分组。
分类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确的归类。
频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现。
5.12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态的更多相关文章
- 啃掉Hadoop系列笔记(03)-Hadoop运行模式之本地模式
Hadoop的本地模式为Hadoop的默认模式,不需要启用单独进程,直接可以运行,测试和开发时使用. 在<啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建>中若环境搭建成功,则直 ...
- Hadoop系列002-从Hadoop框架讨论大数据生态
本人微信公众号,欢迎扫码关注! 从Hadoop框架讨论大数据生态 1.Hadoop是什么 1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构 2)主要解决,海量数据的存储和海量数据的 ...
- Hadoop基础(二):从Hadoop框架讨论大数据生态
1 Hadoop是什么 2 Hadoop三大发行版本 Hadoop三大发行版本:Apache.Cloudera.Hortonworks. Apache版本最原始(最基础)的版本,对于入门学习最好. C ...
- 啃掉Hadoop系列笔记(04)-Hadoop运行模式之伪分布式模式
伪分布式模式等同于完全分布式,只是她只有一个节点. 一) HDFS上运行MapReduce 程序 (1)配置集群 (a)配置:hadoop-env.sh Linux系统中获取jdk的安装路径:
- 啃掉Hadoop系列笔记(02)-Hadoop运行环境搭建
一.新增一个普通用户bigdata
- Hadoop学习笔记01——Hadoop分布式文件系统
Hadoop有一个称为HDFS的分布式系统,全称为Hadoop Distributed Filesystem. HDFS有块(block)的概念,默认为64MB,HDFS上的文件被划分为块大小的多个分 ...
- [Hadoop] Hadoop学习笔记之Hadoop基础
1 Hadoop是什么? Google公司发表了两篇论文:一篇论文是“The Google File System”,介绍如何实现分布式地存储海量数据:另一篇论文是“Mapreduce:Simplif ...
- 【hadoop代码笔记】hadoop作业提交之汇总
一.概述 在本篇博文中,试图通过代码了解hadoop job执行的整个流程.即用户提交的mapreduce的jar文件.输入提交到hadoop的集群,并在集群中运行.重点在代码的角度描述整个流程,有些 ...
- [转帖]hadoop学习笔记:hadoop文件系统浅析
hadoop学习笔记:hadoop文件系统浅析 https://www.cnblogs.com/sharpxiajun/archive/2013/06/15/3137765.html 1.什么是分布式 ...
随机推荐
- Dungeon Master (POJ - 2251)(BFS)
转载请注明出处: 作者:Mercury_Lc 地址:https://blog.csdn.net/Mercury_Lc/article/details/82693907 题目链接 题解:三维的bfs,一 ...
- HDU 5867 Water problem ——(模拟,水题)
我发这题只是想说明:有时候确实需要用水题来找找自信的~ 代码如下: #include <stdio.h> #include <algorithm> #include <s ...
- 51nod 1165 整边直角三角形的数量(两种解法)
链接:http://www.51nod.com/Challenge/Problem.html#!#problemId=1165 直角三角形,三条边的长度都是整数.给出周长N,求符合条件的三角形数量. ...
- Teamviewer解决许可证授权的问题
提交商业用途表 https://www.teamviewer.com/zhCN/pricing/commercial-use/
- 【Python】模块学习之locust性能测试
背景 locust是一个python的第三方库,用于做性能测试,可使用多台机器同时对一台服务器进行压测,使用其中一台机器作为主节点,进行分布式管理 博主测试接口的时候一直是使用python脚本,后来有 ...
- Vue双向绑定的实现原理系列(一):Object.defineproperty
了解Object.defineProperty() github源码 Object.defineProperty()方法直接在一个对象上定义一个新属性,或者修改一个已经存在的属性, 并返回这个对象. ...
- spiderkeeper使用教程
安装包 pip install scrapy pip install scrapyd pip install scrapyd-client pip install spiderkeeper 进入到sc ...
- 2018-2019-20175329 实验三敏捷开发与XP实践《Java开发环境的熟悉》实验报告
2018-2019-20175329 实验三敏捷开发与XP实践<Java开发环境的熟悉>实验报告 实验要求 没有Linux基础的同学建议先学习<Linux基础入门(新版)>&l ...
- react-redux 的总结
第一步,我们将我们要使用的插件来先一步进行安装 create-react-app app // 在这里我们使用了 react 的脚手架来搭建的项目 cd app // 进入我们的项目 npm i - ...
- Mybatis框架学习1:入门
一框架介绍 1.Mybatis介绍 MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google c ...