交替最小二乘ALS
https://www.cnblogs.com/hxsyl/p/5032691.html
http://www.cnblogs.com/skyEva/p/5570098.html
1. 基础回顾
矩阵的奇异值分解 SVD
(特别详细的总结,参考 http://blog.csdn.net/wangzhiqing3/article/details/7446444)
- 矩阵与向量相乘的结果与特征值,特征向量有关。
- 数值小的特征值对矩阵-向量相乘的结果贡献小
1)低秩近似
2)特征降维
相似度和距离度量
(参考 http://blog.sina.com.cn/s/blog_62b83291010127bf.html)
2. ALS 交替最小二乘(alternating least squares)
在机器学习中,ALS 指使用交替最小二乘求解的一个协同推荐算法。
- 它通过观察到的所有用户给商品的打分,来推断每个用户的喜好并向用户推荐适合的商品。
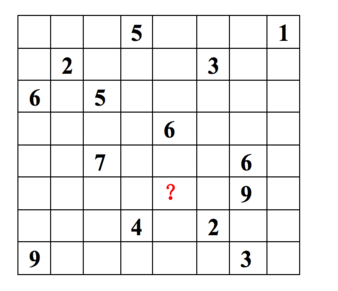
每一行代表一个用户(u1,u2,…,u8), 每一列代表一个商品(v1,v2,…,v8),用户的打分为1-9分。
这个矩阵只显示了观察到的打分,我们需要推测没有观察到的打分。
ALS的核心就是这样一个假设:打分矩阵是近似低秩的。
换句话说,就是一个m*n的打分矩阵可以由分解的两个小矩阵U(m*k)和V(k*n)的乘积来近似,即 A=UVT,k<=m,n 。这就是ALS的矩阵分解方法。
这样我们把系统的自由度从O(mn)降到了O((m+n)k)。
低维空间的选取。
这个低维空间要能够很好的区分事物,那么就需要一个明确的可量化目标,这就是重构误差。
在ALS中我们使用 F范数 来量化重构误差,就是每个元素重构误差的平方和。这里存在一个问题,我们只观察到部分打分,A中的大量未知元是我们想推断的,所以这个重构误差是包含未知数的。
解决方案很简单:只计算已知打分的重构误差。
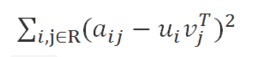
3. 协同过滤
协同过滤分析用户以及用户相关的产品的相关性,用以识别新的用户-产品相关性。
协同过滤系统需要的唯一信息是用户过去的行为信息,比如对产品的评价信息。
- 推荐系统依赖不同类型的输入数据,最方便的是高质量的显式反馈数据,它们包含用户对感兴趣商品明确的评价。例如,
Netflix收集的用户对电影评价的星星等级数据。 - 但是显式反馈数据不一定总是找得到,因此推荐系统可以从更丰富的隐式反馈信息中推测用户的偏好。 隐式反馈类型包括购买历史、浏览历史、搜索模式甚至鼠标动作。
4. 显示反馈模型
通过内积 rij = uiT vj 来预测,另外加入正则化参数 lamda 来预防 过拟合。
最小化重构误差:
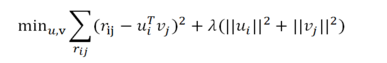
5. 隐式反馈模型
偏好:二元变量 ,它表示用户
u 对商品 v的偏好
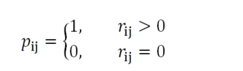
信任度:变量 ,它衡量了我们观察到
的信任度
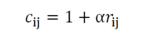
最小化损失函数:

6. 求解:最优化
1)显示和隐式的异同:
- 显示模型只基于观察到的值;隐式需要考虑不同的信任度,最优化时需要考虑所有可能的
u,v对
2) 交替最小二乘求解:
即固定 ui 求 vi+1 再固定 vi+1 求 ui+1
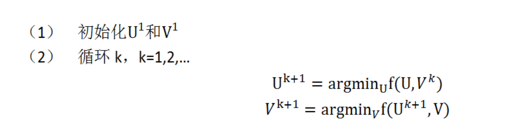
7. 例子
|
1
2
3
4
5
6
7
8
9
10
|
import org.apache.spark.mllib.recommendation._<br>//处理训练数据val data = sc.textFile("data/mllib/als/test.data")val ratings = data.map(_.split(',') match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble)})// 使用ALS训练推荐模型val rank = 10val numIterations = 10val model = ALS.train(ratings, rank, numIterations, 0.01) |
ALS算法实现于org.apache.spark.ml.recommendation.ALS.scala文件中- Rating也在recommendation里面
ALS是alternating least squares的缩写 , 意为交替最小二乘法;而ALS-WR是alternating-least-squares with weighted-λ -regularization的缩写,意为加权正则化交替最小二乘法。该方法常用于基于矩阵分解的推荐系统中。例如:将用户(user)对商品(item)的评分矩阵分解为两个矩阵:一个是用户对商品隐含特征的偏好矩阵,另一个是商品所包含的隐含特征的矩阵。在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户最商品推荐了。
由于评分数据中有大量的缺失项,传统的矩阵分解SVD(奇异值分解)不方便处理这个问题,而ALS能够很好的解决这个问题。对于R(m×n)的矩阵,ALS旨在找到两个低维矩阵X(m×k)和矩阵Y(n×k),来近似逼近R(m×n),即:

其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取k<<min(m, n), 也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
为了找到使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:

其中xu(1×k)表示示用户u的偏好的隐含特征向量,yi(1×k)表示商品i包含的隐含特征向量, rui表示用户u对商品i的评分, 向量xu和yi的内积xuTyi是用户u对商品i评分的近似。
损失函数一般需要加入正则化项来避免过拟合等问题,我们使用L2正则化,所以上面的公式改造为:

其中λ是正则化项的系数。
到这里,协同过滤就成功转化成了一个优化问题。由于变量xu和yi耦合到一起,这个问题并不好求解,所以我们引入了ALS,也就是说我们可以先固定Y(例如随机初始化X),然后利用公式(2)先求解X,然后固定X,再求解Y,如此交替往复直至收敛,即所谓的交替最小二乘法求解法。
具体求解方法说明如下:
- 先固定Y, 将损失函数L(X,Y)对xu求偏导,并令导数=0,得到:

- 同理固定X,可得:

其中ru(1×n)是R的第u行,ri(1×m)是R的第i列, I是k×k的单位矩阵。
- 迭代步骤:首先随机初始化Y,利用公式(3)更新得到X, 然后利用公式(4)更新Y, 直到均方根误差变RMSE化很小或者到达最大迭代次数。

上文提到的模型适用于解决有明确评分矩阵的应用场景,然而很多情况下,用户没有明确反馈对商品的偏好,也就是没有直接打分,我们只能通过用户的某些行为来推断他对商品的偏好。比如,在电视节目推荐的问题中,对电视节目收看的次数或者时长,这时我们可以推测次数越多,看得时间越长,用户的偏好程度越高,但是对于没有收看的节目,可能是由于用户不知道有该节目,或者没有途径获取该节目,我们不能确定的推测用户不喜欢该节目。ALS-WR通过置信度权重来解决这些问题:对于更确信用户偏好的项赋以较大的权重,对于没有反馈的项,赋以较小的权重。ALS-WR模型的形式化说明如下:
- ALS-WR的目标函数:
 其中α是置信度系数。
其中α是置信度系数。
- 求解方式还是最小二乘法:

其中Cu是n×n的对角矩阵,Ci是m×m的对角矩阵;Cuii = cui, Ciii = cii。
交替最小二乘ALS的更多相关文章
- 初识交替最小二乘ALS
ALS是alternating least squares的缩写 , 意为交替最小二乘法:而ALS-WR是alternating-least-squares with weighted-λ -regu ...
- Spark机器学习(10):ALS交替最小二乘算法
1. Alternating Least Square ALS(Alternating Least Square),交替最小二乘法.在机器学习中,特指使用最小二乘法的一种协同推荐算法.如下图所示,u表 ...
- SparkMLlib—协同过滤之交替最小二乘法ALS原理与实践
SparkMLlib-协同过滤之交替最小二乘法ALS原理与实践 一.Spark MLlib算法实现 1.1 显示反馈 1.1.1 基于RDD 1.1.2 基于DataFrame 1.2 隐式反馈 二. ...
- Apache Spark 2.2.0 中文文档 - SparkR (R on Spark) | ApacheCN
SparkR (R on Spark) 概述 SparkDataFrame 启动: SparkSession 从 RStudio 来启动 创建 SparkDataFrames 从本地的 data fr ...
- 文章翻译:Recommending items to more than a billion people(面向十亿级用户的推荐系统)
Web上数据的增长使得在完整的数据集上使用许多机器学习算法变得更加困难.特别是对于个性化推荐问题,数据采样通常不是一种选择,需要对分布式算法设计进行创新,以便我们能够扩展到这些不断增长的数据集. 协同 ...
- MLlib1.6指南笔记
MLlib1.6指南笔记 http://spark.apache.org/docs/latest/mllib-guide.html spark.mllib RDD之上的原始API spark.ml M ...
- 协同过滤 CF & ALS 及在Spark上的实现
使用Spark进行ALS编程的例子可以看:http://www.cnblogs.com/charlesblc/p/6165201.html ALS:alternating least squares ...
- Spark MLlib回归算法------线性回归、逻辑回归、SVM和ALS
Spark MLlib回归算法------线性回归.逻辑回归.SVM和ALS 1.线性回归: (1)模型的建立: 回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多 ...
- Spark Mllib里的协调过滤的概念和实现步骤、LS、ALS的原理、ALS算法优化过程的推导、隐式反馈和ALS-WR算法
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 (广泛采用) 协调过滤的概念 在现今的推荐技术和算法中,最被大家广泛认可和 ...
随机推荐
- 如何进行Django单元测试
如何进行Django单元测试 Django的单元测试使用python的unittest模块,这个模块使用基于类的方法来定义测试.类名为django.test.TestCase,继承于python的un ...
- 移动端rem布局(阿里)
该方案使用相当简单,把下面这段已压缩过的 原生JS(源码已在文章底部更新,2017/5/3) 放到 HTML 的 head 标签中即可(注:不要手动设置viewport,该方案自动帮你设置) < ...
- (4.7)mysql备份还原——深入解析二进制日志(3)binlog的三种日志记录模式详解
关键词:binlog模式,binlog,二进制日志,binlog日志 目录概述 0.binlog概述 查看binlog日志参数设置: show variables like '%log_bin%'; ...
- 20170728 Celery项目 后台处理SQL SERVER的一个异常
-- 1. 感觉是访问DB 失败了,失败原因不明确 -- 2. 考虑解决问题的解决办法,后台记录异常,并重新发送任务. 具体如何来实现
- 由于找不到 MSVCR100.dll,无法继续执行代码
由于找不到 MSVCR100.dll,无法继续执行代码.重新安装程序可能会解决此问题 360软件管家中找到 进行安装即可
- 小程序编辑器vscode
安装中文版 1)打开vscode工具: 2)使用快捷键组合[Ctrl+Shift+p],在搜索框中输入“configure display language”,点击确定后: 3)如图所示 =>安 ...
- Python笔记:调用函数,带扩号和和不带括号的区别
调用函数,如果带括号,那么是调用函数运行后的结果, 调用函数不带括号,调用的是函数本身 例如: def cun (a,b): return a+b print(cun) : 调用函数,打印的是函数 p ...
- Python 全栈开发十 socket网络编程
一.客户端(client)服务端(sever)架构 在计算机中有很多常见的C/S架构,例如我们的浏览器是客户端.而百度网站和其他的网站就是服务端:视频软件是客户端,提供视频的腾讯.优酷.爱奇艺就是服务 ...
- 第一天 Linux基础篇
课程介绍 1.认识Linux的不同版本 2.以及应用领域 3.文件和目录 4.Linux命令概述 5.Linux命令-文件 6.Linux命令-系统管理-磁盘管理 认识Linux 什么是操作系统 生 ...
- 用Partimage创建或恢复分区备份
1 Preliminary Note Partimage is part of the system rescue CD found on http://www.sysresccd.org which ...