【Hadoop学习之十】MapReduce案例分析二-好友推荐
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop-3.1.1
最应该推荐的好友TopN,如何排名?
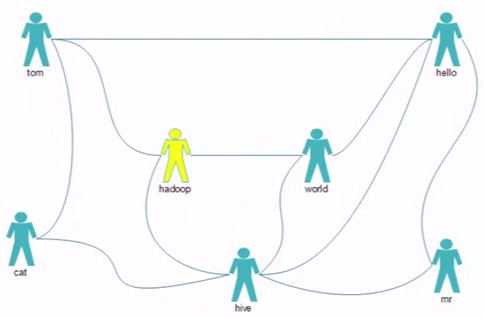

tom hello hadoop cat
world hadoop hello hive
cat tom hive
mr hive hello
hive cat hadoop world hello mr
hadoop tom hive world
hello tom world hive mr
package test.mr.fof; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class MyFOF { /**
* 最应该推荐的好友TopN,如何排名? * @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true);
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
conf.set("sleep", otherArgs[2]); Job job = Job.getInstance(conf,"FOF");
job.setJarByClass(MyFOF.class); //Map
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //Reduce
job.setReducerClass(FReducer.class); //HDFS 输入路径
Path input = new Path(otherArgs[0]);
FileInputFormat.addInputPath(job, input );
//HDFS 输出路径
Path output = new Path(otherArgs[1]);
if(output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);
}
FileOutputFormat.setOutputPath(job, output ); System.exit(job.waitForCompletion(true) ? 0 :1);
}
// tom hello hadoop cat
// world hadoop hello hive
// cat tom hive
// mr hive hello
// hive cat hadoop world hello mr
// hadoop tom hive world
// hello tom world hive mr }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.util.StringUtils; public class FMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ Text mkey= new Text();
IntWritable mval = new IntWritable(); @Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException { //value: 0-直接关系 1-间接关系
//tom hello hadoop cat : hello:hello 1
//hello tom world hive mr hello:hello 0 String[] strs = StringUtils.split(value.toString(), ' '); String user=strs[0];
String user01=null;
for(int i=1;i<strs.length;i++){
//与好友清单中好友属于直接关系
mkey.set(fof(strs[0],strs[i]));
mval.set(0);
context.write(mkey, mval); for (int j = i+1; j < strs.length; j++) {
Thread.sleep(context.getConfiguration().getInt("sleep", 0));
//好友列表内 成员之间是间接关系
mkey.set(fof(strs[i],strs[j]));
mval.set(1);
context.write(mkey, mval);
}
}
} public static String fof(String str1 , String str2){ if(str1.compareTo(str2) > 0){
//hello,hadoop
return str2+":"+str1;
}
//hadoop,hello
return str1+":"+str2;
} }
package test.mr.fof; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class FReducer extends Reducer<Text, IntWritable, Text, Text> { Text rval = new Text();
@Override
protected void reduce(Text key, Iterable<IntWritable> vals, Context context)
throws IOException, InterruptedException
{
//是简单的好友列表的差集吗?
//最应该推荐的好友TopN,如何排名? //hadoop:hello 1
//hadoop:hello 0
//hadoop:hello 1
//hadoop:hello 1
int sum=0;
int flg=0;
for (IntWritable v : vals)
{
//0为直接关系
if(v.get()==0){
//hadoop:hello 0
flg=1;
}
sum += v.get();
} //只有间接关系才会被输出
if(flg==0){
rval.set(sum+"");
context.write(key, rval);
}
}
}
【Hadoop学习之十】MapReduce案例分析二-好友推荐的更多相关文章
- MapReduce深度分析(二)
MapReduce深度分析(二) 五.JobTracker分析 JobTracker是hadoop的重要的后台守护进程之一,主要的功能是管理任务调度.管理TaskTracker.监控作业执行.运行作业 ...
- Hadoop学习笔记—20.网站日志分析项目案例(二)数据清洗
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:当前页面 网站日志分析项目案例 ...
- 【Hadoop学习之十三】MapReduce案例分析五-ItemCF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 推荐系统——协同过滤(Collab ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- [b0012] Hadoop 版hello word mapreduce wordcount 运行(二)
目的: 学习Hadoop mapreduce 开发环境eclipse windows下的搭建 环境: Winows 7 64 eclipse 直接连接hadoop运行的环境已经搭建好,结果输出到ecl ...
- 【第二课】kaggle案例分析二
Evernote Export 推荐系统比赛(常见比赛) 推荐系统分类 最能变现的机器学习应用 基于应用领域分类:电子商务推荐,社交好友推荐,搜索引擎推荐,信息内容推荐等 **基于设计思想:**基于协 ...
- 【Hadoop学习之十二】MapReduce案例分析四-TF-IDF
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 概念TF-IDF(term fre ...
- 【Hadoop学习之九】MapReduce案例分析一-天气
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 找出每个月气温最高的2天 1949 ...
随机推荐
- 在Java程序中读写windows共享文件夹
摘要 使用Java通过JCIFS框架读写共享文件夹,使用SMB协议,并支持域认证. 项目常常需要有访问共享文件夹的需求,例如读取共享文件夹存储的视频.照片和PPT等文件.那么如何使用Java读写Win ...
- oracle中实现当前月减少或增加N个月
add_months(last_day(trunc(sysdate)),N)N可以为正,表示增加:N可以为负,表示减少.
- xargs与管道的区别
一.直观感受 echo '--help' | cat echo的输出通过管道定向到cat的输入, 然后cat从其标准输入中读取待处理的文本内容, 输出结果: --help echo '--help' ...
- 如何使用CryptoJS配合Java进行AES加密和解密
注意 1. PKCS5Padding和PKCS7Padding是一样的 2. 加密时使用的key和iv要转换成base64格式 一.前端 1.函数 function encrypt (msg, key ...
- OpenWrt 路由系统上抓包
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/qianguozheng/article/details/32108093 前言: 做路由器开发,难免 ...
- RN NetInfo使用
代码: class NetInfoView extends Component { getNetInfo() { //如果是andorid的程序,需要在xml添加获取网络请求权限 NetInfo.fe ...
- OC分割输入验证码的视觉效果
效果图: 用到的类: UITextField+VerCodeTF.h #import <UIKit/UIKit.h> @protocol VerCodeTFDelegate <UIT ...
- 通过Tesseract实现简单的OCR
Tesseract 简介 Tesseract 的 OCR 引擎最先由 HP 实验室于 1985 年开始研发,至 1995 年时已经成为 OCR 业内最准确的三款识别引擎之一.然而,HP 不久便决定放弃 ...
- 主成分分析(PCA)原理详解
一.PCA简介 1. 相关背景 在许多领域的研究与应用中,往往需要对反映事物的多个变量进行大量的观测,收集大量数据以便进行分析寻找规律.多变量大样本无疑会为研究和应用提供了丰富的信息,但也在一定程度上 ...
- pycharm的安装和使用
python开发IDE: pycharm.eclipse 1.要专业版 2.不要汉化版 一.运算符 + - * ./ ** % // 判断某个东西是否在东西里面包含 in not ...