不懂RPC实现原理怎能实现架构梦
在支付系统的微服务架构中,基础服务的构建是重中之重, 本文重点分析如何使用Apache Thrift + Google Protocol Buffer来构建基础服务。
一、RPC vs Restful
在微服务中,使用什么协议来构建服务体系,一直是个热门话题。 争论的焦点集中在两个候选技术: (binary) RPC or Restful。
以Apache Thrift为代表的二进制RPC,支持多种语言(但不是所有语言),四层通讯协议,性能高,节省带宽。相对Restful协议,使用Thrifpt RPC,在同等硬件条件下,带宽使用率仅为前者的20%,性能却提升一个数量级。但是这种协议最大的问题在于,无法穿透防火墙。
以Spring Cloud为代表所支持的Restful 协议,优势在于能够穿透防火墙,使用方便,语言无关,基本上可以使用各种开发语言实现的系统,都可以接受Restful 的请求。 但性能和带宽占用上有劣势。
所以,业内对微服务的实现,基本是确定一个组织边界,在该边界内,使用RPC; 边界外,使用Restful。这个边界,可以是业务、部门,甚至是全公司。
二、 RPC技术选型
RPC技术选型上,原则也是选择自己熟悉的,或者公司内部内定的框架。 如果是新业务,则现在可选的框架其实也不多,却也足够让人纠结。
Apache Thrift
国外用的多,源于facebook,后捐献给Apache基金。是Apache的顶级项目 Apache Thrift。使用者包括facebook, Evernote, Uber, Pinterest等大型互联网公司。 而在开源界,Apache hadoop/hbase也在使用Thrift作为内部通讯协议。 这是目前最为成熟的框架,优点在于稳定、高性能。缺点在于它仅提供RPC服务,其他的功能,包括限流、熔断、服务治理等,都需要自己实现,或者使用第三方软件。
Dubbo
国内用的多,源于阿里公司。 性能上略逊于Apache Thrift,但自身集成了大量的微服务治理功能,使用起来相当方便。 Dubbo的问题在于,该系统目前已经很长时间没有维护更新了。 官网显示最近一次的更新也是8个月前。
Google Protobuf
和Apache Thrift类似,Google Protobuf也包括数据定义和服务定义两部分。问题是,Google Protobuf一直只有数据模型的实现,没有官方的RPC服务的实现。 直到2015年才推出gRPC,作为RPC服务的官方实现。但缺乏重量级的用户。
以上仅做定性比较。定量的对比,网上有不少资料,可自行查阅。 此外,还有一些不错的RPC框架,比如Zeroc ICE等,不在本文的比较范围。
Thrift 提供多种高性能的传输协议,但在数据定义上,不如Protobuf强大。
同等格式数据, Protobuf压缩率和序列化/反序列化性能都略高。
Protobuf支持对数据进行自定义标注,并可以通过API来访问这些标注,这使得Protobuf在数据操控上非常灵活。比如可以通过option来定义protobuf定义的属性和数据库列的映射关系,实现数据存取。
数据结构升级是常见的需求,Protobuf在支持数据向下兼容上做的非常不错。只要实现上处理得当,接口在升级时,老版本的用户不会受到影响。
而Protobuf的劣势在于其RPC服务的实现性能不佳(gRPC)。为此,Apache Thrift + Protobuf的RPC实现,成为不少公司的选择。
三、Apache Thrift + Protobuf
如上所述,利用Protobuf在灵活数据定义、高性能的序列化/反序列化、兼容性上的优势,以及Thrift在传输上的成熟实现,将两者结合起来使用,是不少互联网公司的选择。
服务定义:
service HelloService{
binary hello(1: binary hello_request);
}协议定义:
message HelloRequest{
optional string user_name = 1; //访问这个接口的用户
optional string password = 2; //访问这个接口的密码
optional string hello_word = 3; //其他参数;
}
message HelloResponse{
optional string hello_word = 1; //访问这个接口的用户
}想对于纯的thrift实现,这种方式虽然看起来繁琐,但其在可扩展性、可维护性和服务治理上,可以带来不少便利。
四、服务注册与发现
Spring cloud提供了服务注册和发现功能,如果需要自己实现,可以考虑使用Apache Zookeeper作为注册表,使用Apache Curator 来管理Zookeeper的链接,它实现如下功能:
侦听注册表项的变化,一旦有更新,可以重新加载注册表。
管理到zookeeper的链接,如果出现问题,则进行重试。
Curator的重试策略是可配置的,提供如下策略:
BoundedExponentialBackoffRetry
ExponentialBackoffRetry
RetryForever
RetryNTimes
RetryOneTime
RetryUntilElapsed一般使用指数延迟策略,比如重试时间间隔为1s,2s, 4s, 8s……指数增加,避免把服务器打死。
对服务注册来说,注册表结构需要详细设计,一般注册表结构会按照如下方式组织:
机房区域-部门-服务类型-服务名称-服务器地址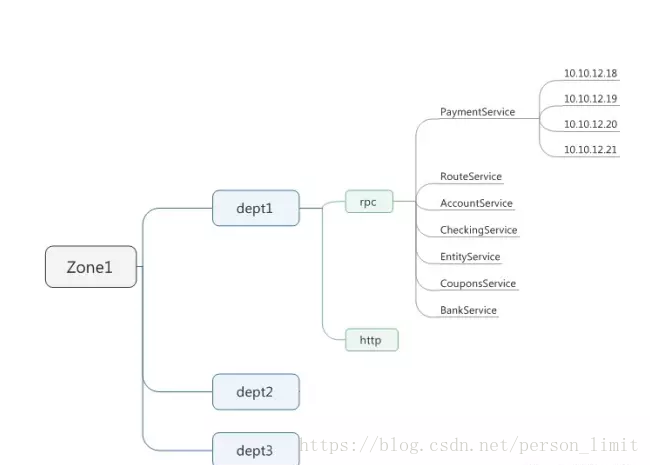
由于在zookeeper上的注册和发现有一定的延迟,所以在实现上也得注意,当服务启动成功后,才能注册到zookeeper上;当服务要下线或者重启前,需要先断开同zookeeper的连接,再停止服务。
五、连接池
RPC服务访问和数据库类似,建立链接是一个耗时的过程,连接池是服务调用的标配。目前还没有成熟的开源Apache Thrift链接池,一般互联网公司都会开发内部自用的链接池。自己实现可以基于JDBC链接池做改进,比如参考Apache commons DBCP链接池,使用Apache Pools来管理链接。 在接口设计上,连接池需要管理的是RPC 的Transport:
public interface TransportPool {
/**
* 获取一个transport
* @return
* @throws TException
*/
public TTransport getTransport() throws TException;}连接池实现的主要难点在于如何从多个服务器中选举出来为当前调用提供服务的连接。比如目前有10台机器在提供服务,上一次分配的是第4台服务器,本次应该分配哪一台?在实现上,需要收集每台机器的QOS以及当前的负担,分配一个最佳的连接。
六、API网关
随着公司业务的增长,RPC服务越来越多,这也为服务调用带来挑战。如果有一个应用需要调用多个服务,对这个应用来说,就需要维护和多个服务器之间的链接。服务的重启,都会对连接池以及客户端的访问带来影响。为此,在微服务中,广泛会使用到API网关。API网关可以认为是一系列服务集合的访问入口。从面向对象设计的角度看,它与外观模式类似,实现对所提供服务的封装。
网关作用
API网关本身不提供服务的具体实现,它根据请求,将服务分发到具体的实现上。 其主要作用:
API路由: 接受到请求时,将请求转发到具体实现的worker机器上。避免使用方建立大量的连接。
协议转换: 原API可能使用http或者其他的协议来实现的,统一封装为rpc协议。注意,这里的转换,是批量转换。也就是说,原来这一组的API是使用http实现的,现在要转换为RPC,于是引入网关来统一处理。对于单个服务的转换,还是单独开发一个Adapter服务来执行。
封装公共功能: 将微服务治理相关功能封装到网关上,简化微服务的开发,这包括熔断、限流、身份验证、监控、负载均衡、缓存等。
分流:通过控制API网关的分发策略,可以很容易实现访问的分流,这在灰度测试和AB测试时特别有用。
解耦合
RPC API网关在实现上,难点在于如何做到服务无关。我们知道使用Nginx实现HTTP的路由网关,可以实现和服务无关。而RPC网关由于实现上的不规范,很难实现和服务无关。统一使用thrift + protobuf 来开发RPC服务可以简化API网关的开发,避免为每个服务上线而带来的网关的调整,使得网关和具体的服务解耦合:
每个服务实现的worker机器将服务注册到zookeeper上;
API网关接收到zookeeper的变更,更新本地的路由表,记录服务和worker(连接池)的映射关系。
当请求被提交到网关上时,网关可以从rpc请求中提取出服务名称,之后根据这个名称,找到对应的worker机(连接池),调用该worker上的服务,接受到结果后,将结果返回给调用方。
权限和其他
Protobuf的一个重要特性是,数据的序列化和名称无关,只和属性类型、编号有关。 这种方式,间接实现了类的继承关系。如下所示,我们可以通过Person类来解析Girl和Boy的反序列化流:
message Person {
optional string user_name = 1;
optional string password = 2; }message Girl {
optional string user_name = 1;
optional string password = 2;
optional string favorite_toys = 3; }message Boy {
optional string user_name = 1;
optional string password = 2;
optional int32 favorite_club_count = 3;
optional string favorite_sports = 4; }我们只要对服务的输入参数做合理的编排,将常用的属性使用固定的编号来表示,既可以使用通用的基础类来解析输入参数。比如我们要求所有输入的第一个和第二个元素必须是user_name和password,则我们就可以使用Person来解析这个输入,从而可以实现对服务的统一身份验证,并基于验证结果来实施QPS控制等工作。
七、熔断与限流
Netflix Hystrix提供不错的熔断和限流的实现,参考其在GitHub上的项目介绍。这里简单说下熔断和限流实现原理。
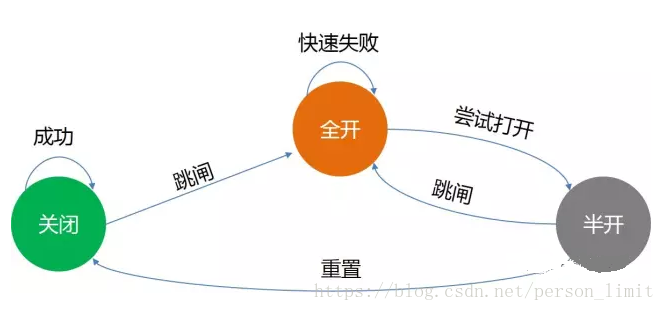
熔断一般采用电路熔断器模式(Circuit Breaker Patten)。当某个服务发生错误,每秒错误次数达到阈值时,不再响应请求,直接返回服务器忙的错误给调用方。 延迟一段时间后,尝试开放50%的访问,如果错误还是高,则继续熔断;否则恢复到正常情况。
限流指按照访问方、IP地址或者域名等方式对服务访问进行限制,一旦超过给定额度,则禁止其访问。 除了使用Hystrix,如果要自己实现,可以考虑使用使用Guava RateLimiter
八、服务演化
随着服务访问量的增加,服务的实现也会不断演化以提升性能。主要的方法有读写分离、缓存等。
读写分离
针对实体服务,读写分离是提升性能的第一步。 实现读写分离一般有以下几种方式:
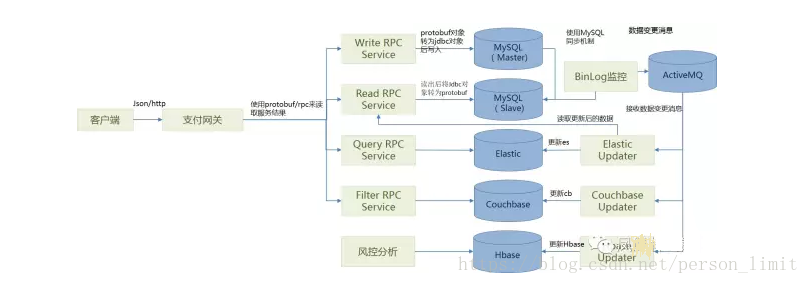
1、在同构数据库上使用主从复制的方式: 一般数据库,比如MySQL、HBase、Mongodb等,都提供主从复制功能。数据写入主库,读取、检索等操作都从从库上执行,实现读写分离。这种方式实现简单,无需额外开发数据同步程序。一般来说,对写入有事务要求的数据库,在读取上的性能会比较差。虽然可以通过增加从库的方式来sharding请求,但这也会导致成本增加。
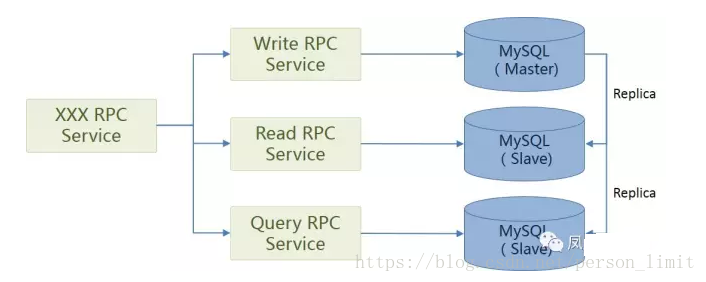
2、在异构数据库上进行读写分离。发挥不同数据库的优势,通过消息机制或者其他方式,将数据从主库同步到从库。 比如使用MySQL作为主库来写入,数据写入时投递消息到消息服务器,同步程序接收到消息后,将数据更新到读库中。可以使用Redis,Mongodb等内存数据库作为读库,用来支持根据ID来读取;使用Elastic作为从库,支持搜索。
3、微服务技术是程序员都离不开的话题,说到这里,也给大家推荐一个交流学习平台:架构交流群650385180,里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源,以下的课程体系图也是在群里获取。相信对于已经工作和遇到技术瓶颈的码友,在这里会有你需要的内容。
缓存使用
如果数据量大,使用从库也会导致从库成本非常高。对大部分数据来说,比如订单库,一般需要的只是一段时间,比如三个月内的数据。更长时间的数据访问量就非常低了。 这种情况下,没有必要将所有数据加载到成本高昂的读库中,即这时候,读库是缓存模式。 在缓存模式下,数据更新策略是一个大问题。
对于实时性要求不高的数据,可以考虑采用被动更新的策略。即数据加载到缓存的时候,设置过期时间。一般内存数据库,包括Redis,couchbase等,都支持这个特性。到过期时间后,数据将失效,再次被访问时,系统将触发从主库读写数据的流程。
对实时性要求高的数据,需要采用主动更新的策略,也就是接受Message后,立即更新缓存数据。
当然,在服务演化后,对原有服务的实现也会产生影响。 考虑到微服务的一个实现原则,即一个服务仅管一个存储库,原有的服务就被分裂成多个服务了。 为了保持使用方的稳定,原有服务被重新实现为服务网关,作为各个子服务的代理来提供服务。
以上是RPC与微服务的全部内容,以下是thrift + protobuf的实现规范的介绍。
附一、基础服务设计规范
基础服务是微服务的服务栈中最底层的模块, 基础服务直接和数据存储打交道,提供数据增删改查的基本操作。
附1.1 设计规范
文件规范
rpc接口文件名以 xxx_rpc_service.thrift 来命名; protobuf参数文件名以 xxx_service.proto 来命名。
这两种文件全部使用UTF-8编码。
命名规范
服务名称以 “XXXXService” 的格式命名, XXXX是实体,必须是名词。以下是合理的接口名称。
OrderService
AccountService附1.2 方法设计
由于基础服务主要是解决数据读写问题,所以从使用的角度,对外提供的接口,可以参考数据库操作,标准化为增、删、改、查、统计等基本接口。接口采用 操作+实体来命名,如createOrder。 接口的输入输出参数采用 接口名+Request 和 接口名Response 的规范来命名。 这种方式使得接口易于使用和管理。
file: xxx_rpc_service.thrift
/**
* 这里是版权申明
**/
namespace java com.phoenix.service
/**
* 提供关于XXX实体的增删改查基本操作。
**/
service XXXRpcService {
/**
* 创建实体
* 输入参数:
* 1. createXXXRequest: 创建请求,支持创建多个实体;
* 输出参数
* createXXXResponse: 创建成功,返回创建实体的ID列表;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 必填的参数没有提供。
**/
binary createXXX(1: binary create_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
/**
* 更新实体
* 输入参数:
* 1. updateXXXRequest: 更新请求,支持同时更新多个实体;
* 输出参数
* updateXXXResponse: 更新成功,返回被更行的实体的ID列表;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 该实体在服务器端没有找到。
**/
binary updateXXX(1: binary update_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
/**
* 删除实体
* 输入参数:
* 1. removeXXXRequest: 删除请求,按照id来删除,支持一次删除多个实体;
* 输出参数
* removeXXXResponse: 删除成功,返回被删除的实体的ID列表;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 该实体在服务器端没有找到。
**/
binary removeXXX(1: binary remove_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
/**
* 根据ID获取实体
* 输入参数:
* 1. getXXXRequest: 获取请求,按照id来获取,支持一次获取多个实体;
* 输出参数
* getXXXResponse: 返回对应的实体列表;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 该实体在服务器端没有找到。
**/
binary getXXX(1: binary get_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
/**
* 查询实体
* 输入参数:
* 1. queryXXXRequest: 查询条件;
* 输出参数
* queryXXXResponse: 返回对应的实体列表;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 该实体在服务器端没有找到。
**/
binary queryXXX(1: binary query_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
/**
* 统计符合条件的实体的数量
* 输入参数:
* 1. countXXXRequest: 查询条件;
* 输出参数
* countXXXResponse: 返回对应的实体数量;
* 异常
* 1. userException:输入的参数有误;
* 2. systemExeption:服务器端出错导致无法创建;
* 3. notFoundException: 该实体在服务器端没有找到。
**/
binary countXXX(1: binary count_xxx_request) throws (1: Errors.UserException userException, 2: Errors.systemException, 3: Errors.notFoundException)
}附1.3 参数设计
每个方法的输入输出参数,采用protobuf来表示。
file: xxx_service.protobuf
/**
*
* 这里是版权申明
**/
option java_package = "com.phoenix.service";
import "entity.proto";
import "taglib.proto";
/**
* 创建实体的请求
*
**/
message CreateXXXRequest {
optional string user_name = 1; //访问这个接口的用户
optional string password = 2; //访问这个接口的密码
repeated XXXX xxx = 21; // 实体内容;
}
/**
* 创建实体的结果响应
*
**/
message CreateXXXResponse {
repeated int64 id = 11;//成功创建的实体的ID列表
}附1.4 异常设计
RPC接口也不需要太复杂的异常,一般是定义三类异常。
file errors.thrift
/**
* 由于调用方的原因引起的错误, 比如参数不符合规范、缺乏必要的参数,没有权限等。
* 这种异常一般是可以重试的。
*
**/
exception UserException {
1: required ErrorCode error_code;
2: optional string message;
}
/**
* 由于服务器端发生错误导致的,比如数据库无法连接。这也包括QPS超过限额的情况,这时候rateLimit返回分配给的QPS上限;
*
**/
exception systemException {
1: required ErrorCode error_code;
2: optional string message;
3: i32 rateLimit;
}
/**
* 根据给定的ID或者其他条件无法找到对象。
*
**/
exception systemException {
1: optional string identifier;
}附二、服务SDK
当然,RPC服务不应该直接提供给业务方使用,需要提供封装好的客户端。 一般来说,客户端除了提供访问服务端的代理外,还需要对常有功能进行封装,这包括服务发现、RPC连接池、重试机制、QPS控制。这里首先介绍服务SDK的设计。 直接使用Protobuf作为输入参数和输出参数,开发出来的代码很繁琐:
GetXXXRequest.Builder request = GetXXXRequest.newBuilder();
request.setUsername("username");
request.setPassword("password");
request.addId("123");
GetXXXResponse response = xxxService.getXXX(request.build());
if(response.xxx.size()==1)
XXX xxx = response.xxx.get(0);如上,有大量的重复性代码,使用起来不直观也不方便。 因而需要使用客户端SDK来做一层封装,供业务方调用:
class XXXService {
//根据ID获取对象
public XXX getXXX(String id){
GetXXXRequest.Builder request = GetXXXRequest.newBuilder();
request.setUsername("username");
request.setPassword("password");
request.addId("123");
GetXXXResponse response = xxxService.getXXX(request.build());
if(response.xxx.size()==1)
return response.xxx.get(0);
return null;
}
}对所有服务器端接口提供对应的客户端SDK,也是微服务架构最佳实践之一。以此封装完成后,调用方即可以像使用普通接口一样,无需了解实现细节。
不懂RPC实现原理怎能实现架构梦的更多相关文章
- 基于框架的RPC通信技术原理解析
RPC的由来 随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进. 单一应用架构 当网站流量很小时, ...
- RPC实现原理(HSF、dubbo) 从头开始(一)
前言 阔别了很久博客园,虽然看了以前写的很多东西感觉好幼稚,但是还是觉得应该把一些自己觉得有用的东西和大家分享.废话不多说,现在开始进入正题. 之前的六年工作经验,呆过了一些大公司,每个在大公司呆过的 ...
- 网络编程 -- RPC实现原理 -- 目录
-- 啦啦啦 -- 网络编程 -- RPC实现原理 -- NIO单线程 网络编程 -- RPC实现原理 -- NIO多线程 -- 迭代版本V1 网络编程 -- RPC实现原理 -- NIO多线程 -- ...
- 网络编程 -- RPC实现原理 -- NIO单线程
网络编程 -- RPC实现原理 -- 目录 啦啦啦 Class : Service package lime.pri.limeNio.optimize.socket; import java.io.B ...
- 网络编程 -- RPC实现原理 -- NIO多线程 -- 迭代版本V1
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V1——设置标识变量selectionKey.attach(true);只处理一次(会一直循环遍历selectionKeys,占用CPU资源). ( ...
- 网络编程 -- RPC实现原理 -- NIO多线程 -- 迭代版本V2
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V2——增加WriteQueue队列,存放selectionKey.addWriteEventToQueue()添加selectionKey并唤醒阻 ...
- 网络编程 -- RPC实现原理 -- Netty -- 迭代版本V1 -- 入门应用
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V1——Netty入门应用 Class : NIOServerBootStrap package lime.pri.limeNio.netty.ne ...
- 网络编程 -- RPC实现原理 -- Netty -- 迭代版本V2 -- 对象传输
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V2——Netty -- 使用序列化和反序列化在网络上传输对象:需要实现 java.io.Serializable 接口 只能传输( ByteBuf ...
- 网络编程 -- RPC实现原理 -- Netty -- 迭代版本V3 -- 编码解码
网络编程 -- RPC实现原理 -- 目录 啦啦啦 V2——Netty -- pipeline.addLast(io.netty.handler.codec.MessageToMessageCodec ...
随机推荐
- spark sql的agg函数,作用:在整体DataFrame不分组聚合
.agg(expers:column*) 返回dataframe类型 ,同数学计算求值 df.agg(max("age"), avg("salary")) df ...
- 【Redis】事务
在Redis中,事务是以multi/exec/discard进行的, 其中multi表示事务的开始, exec表示事务的执行,discard表示丢弃事务. > multi # 事务的开始 OK ...
- vue作用域 this
设计到异步 function 回调的.this指向 需要用内部代替this 如果是箭头符号写法 就不需要 this永远是当前vue实例
- [LeetCode] 709. To Lower Case_Easy
Implement function ToLowerCase() that has a string parameter str, and returns the same string in low ...
- Linux下利用Valgrind工具进行内存泄露检测和性能分析
from http://www.linuxidc.com/Linux/2012-06/63754.htm Valgrind通常用来成分析程序性能及程序中的内存泄露错误 一 Valgrind工具集简绍 ...
- Python基础(四) socket简单通讯
socket:我们通常听过的套接字: 服务端: 1.创建socket对象 2.bing 绑定ip及端口 3.对该端口进行监听 4.消息阻塞(等待客户端消息) 客户端: 1.创建socket对象 2.连 ...
- Pygame模块,功能表
Pygame有很多的模块,下面是一张一览表: 模块名 功能 pygame.cdrom 访问光驱 pygame.cursors 加载光标 pygame.display 访问显示设备 pygame.dra ...
- OBV15 案例2
BV
- Hibernate框架第一天
**框架和CRM项目的整体介绍** 1. 什么是CRM * CRM(Customer Relationship Management)客户关系管理,是利用相应的信息技术以及互联网技术来协调企业与顾客间 ...
- RSA加解密 公钥加密私钥解密 公加私解 && C++ 调用openssl库 的代码实例
前提:秘钥长度=1024 ============================================== 对一片(117字节)明文加密 ========================= ...