yarn application ID 增长达到10000后

Job, Task, and Task Attempt IDs
In Hadoop 2, MapReduce job IDs are generated from YARN application IDs that arecreated by the YARN resource manager.
The format of an application ID is composedof the time that the resource manager (not the application) started and an incrementingcounter maintained by the resource manager to uniquely identify the application to that instance of the resource manager.
So the application with this ID:
appllcation_1410450250506_0003
is the third (0003; application IDs are 1 -based) application run by the resource manager,which started at the time represented by the timestamp 1410450250506.
The counter is formatted with leading zeros to make IDs sort nicely —in directory listings, for example.
However, when the counter reaches 10000, it is not reset, resulting in longer application IDs (which don’t sort so well). The corresponding job ID is created simply by replacing the application prefix of an application ID with a job prefix:
job_1410450250506_0003
Tasks belong to a job, and their IDs are formed by replacing the job prefix of a job ID with a task prefix and adding a suffix to identify the task within the job. For example:
task_1410450250506_0003_n_000003
is the fourth (000003; task IDs are 0-based) map (n) task of the job with ID job_1410450250506_0003. The task IDs arc created for a job when it is initialized, so they do not necessarily dictate the order in which the tasks will be executed. Tasks may be executed more than once, due to failure (see MTask FailurcM on page 193) or speculative execution (see speculative Execution" on page 204), so to identify different instances of a task execution, task attempts are given unique IDs. For example:
attenpt_1410450256506_0003_n_000003_0
is the first (0; attempt IDs are O-based) attempt at running task
task_141045O250506_O003_m_000003.
Task attempts arc allocated during the job run as needed, so their ordering represents the order in which they were created to run.
简而言之,就是当yarn application id超过了4位数的范围,也就是达到10000后,yarn直接做增加位数操作,来扩展id空间范围。同时官方承认,这会导致根据id排序结果出现偏差。
2018-01-02,实际截图补充:
按提交时间排序:
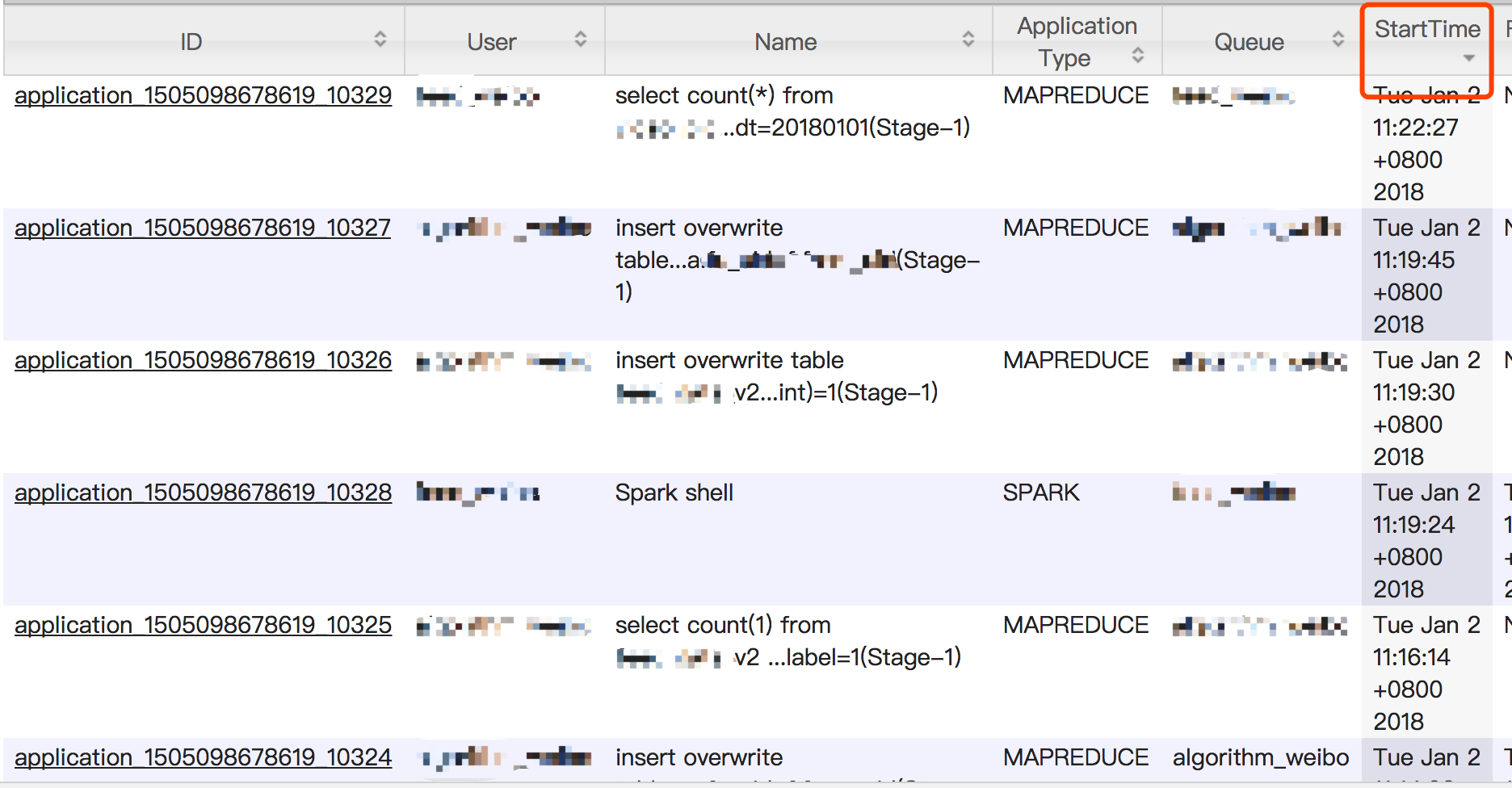
按照id排序:
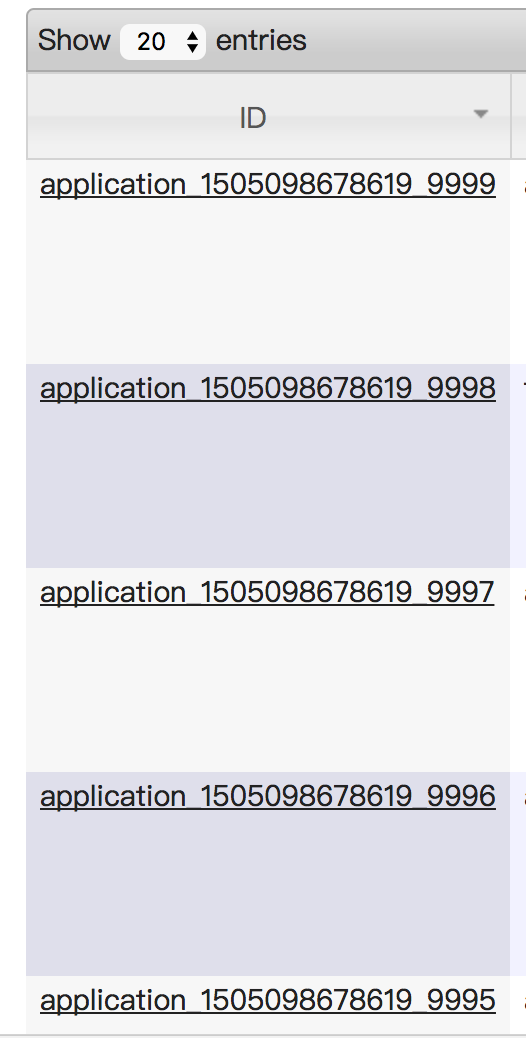
yarn application Id在到达10000后,会通过增加位数来扩展id空间容量,但这会导致页面按照ID进行排序结果出现偏差。
Hadoop: The Definitive Guide: Storage and Analysis at Internet Scale
yarn application ID 增长达到10000后的更多相关文章
- spark-shell启动报错:Yarn application has already ended! It might have been killed or unable to launch application master
spark-shell不支持yarn cluster,以yarn client方式启动 spark-shell --master=yarn --deploy-mode=client 启动日志,错误信息 ...
- yarn application -kill application_id yarn kill 超时任务脚本
需求:kill 掉yarn上超时的任务,实现不同队列不同超时时间的kill机制,并带有任务名的白名单功能 此为python脚本,可配置crontab使用 # _*_ coding=utf-8 _*_ ...
- hadoop job -kill 和 yarn application -kill 区别
hadoop job -kill 调用的是CLI.java里面的job.killJob(); 这里会分几种情况,如果是能查询到状态是RUNNING的话,是直接向AppMaster发送kill请求的.Y ...
- Eclipse插件开发_异常_01_java.lang.RuntimeException: No application id has been found.
一.异常现象 在运行RCP程序时,出现 java.lang.RuntimeException: No application id has been found. at org.eclipse.equ ...
- yarn application命令介绍
yarn application 1.-list 列出所有 application 信息 示例:yarn application -list 2.-appStates <Stat ...
- Hibernate在oracle中ID增长的方式
引用链接:http://blog.csdn.net/w183705952/article/details/7367272 Hibernate在oracle中ID增长的方式 第一种:设置ID的增长策略是 ...
- 【深入浅出 Yarn 架构与实现】3-1 Yarn Application 流程与编写方法
本篇学习 Yarn Application 编写方法,将带你更清楚的了解一个任务是如何提交到 Yarn ,在运行中的交互和任务停止的过程.通过了解整个任务的运行流程,帮你更好的理解 Yarn 运作方式 ...
- eclipse 4 rcp: java.lang.RuntimeException: No application id has been found.
错误详情: java.lang.RuntimeException: No application id has been found. at org.eclipse.equinox.internal. ...
- [JAVA][RCP]Clean project之后报错:java.lang.RuntimeException: No application id has been found.
Clean了一下Project,然后就报了如下错误 !ENTRY com.release.nattable.well_analysis 2 0 2015-11-20 17:04:44.609 !MES ...
随机推荐
- 国内混合APP开发技术选型
http://www.sunzhongwei.com/weex-react-native-ionic-technology-selection 选谁? 企业级应用是要考虑性能和流畅度的, 如果只是做个 ...
- Windows下Kettle定时任务执行并发送错误信息邮件
Windows下Kettle定时任务执行并发送错误信息邮件 1.首先安装JDK 2.配置JDK环境 3.下载并解压PDI(kettle) 目前我用的是版本V7的,可以直接百度搜索下载社区版,企业版收费 ...
- 《Unix&Linux大学教程》学习笔记四:标准I/O 与 过滤器
1:标准IO Unix中的标准IO主要包括:标准输入.标准输出(正常输出).标准错误(异常信息) 2:重定向输出 内容 > 文件名 :将内容输出到文件,并且覆盖文件原来内容:文件不存在则新建 内 ...
- CentOS 6下 Oracle11gR2 设置开机自启动
[1] 更改/etc/oratab # This file is used by ORACLE utilities. It is created by root.sh # and updated by ...
- IntelliJ IDEA 2017.3/2018.1激活与汉化
本文以IntelliJ IDEA 2017.3以及2018.1为例进行讲解.(持续更新:2018年5月28日) 适用版本(其它版本未测试): IntelliJ IDEA 2017.2.6.2017.3 ...
- OpenCV 学习笔记 05 人脸检测和识别
本节将介绍 Haar 级联分类器,通过对比分析相邻图像区域来判断给定图像或子图像与已知对象是否匹配. 本章将考虑如何将多个 Haar 级联分类器构成一个层次结构,即一个分类器能识别整体区域(如人脸) ...
- x-pack
x-pack安装>官网安装步骤https://www.elastic.co/downloads/x-pack >x-pack简介X-Pack是一个Elastic Stack的扩展,将安全, ...
- Socket网络编程--聊天程序(2)
上一节简单如何通过Socket创建一个连接,然后进行通信.只是每个人只能说一句话.而且还是必须说完才会接收到信息,总之是很不方便的事情.所以这一小节我们将对上一次的程序进行修改,修改成每个人可以多说话 ...
- axios的初步使用
1.数据格式 [ { "title": "喵1", "href": "1", "url": &quo ...
- 省市区三级联动——思路、demo、示例
说明(2017-12-13 11:03:58): 1. 这个功能应该是注册的时候非常.常用的了,不过现在都是微信登录,手机端自动获取位置什么的,可能就网站还用用吧! 2. 这个东西的难点在于统计各地省 ...