Hadoop yarn工作流程详解
yarn是什么?
1、它是一个资源调度及提供作业运行的系统环境平台
资源:cpu、mem等
作业:map task、reduce Task
yarn产生背景?
它是从hadoop2.x版本才引入
1、hadoop1.x版本它是如何资源调度及作业运行机制原理
a、JobTracker(主节点)
(a):接受客户端的作业提交
(b):交给任务调度器安排任务的执行
(c):通知空闲的TaskTracker去处理
(d): 与TaskTracker保持心跳机制
b、TaskTracker(从节点)
(a):执行map task和reduce task
(b): 与JobTracker保持心跳机制
缺点:
1、单点故障问题
2、负载压力
3、只能运行mapreduce的程序
引入了yarn机制
1、减少负载压力
2、主备机制
3、支持不同的程序运行
yarn整体的架构?
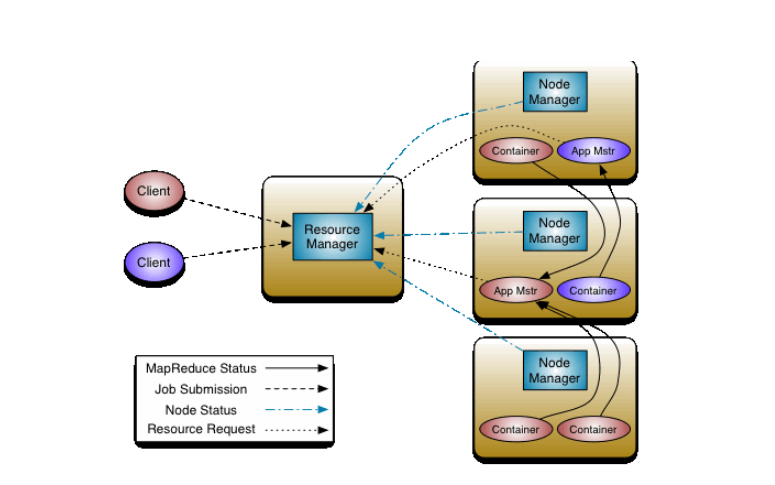
yarn主要的核心组件?
resourcemanager
作用:
(1)接受客户端提交作业
(2)启动一个app master去处理
资源分配
(3)监控nodemanager
nodemanager
作用:
(1)管理单个节点上的资源
(2)接受resourcemanager发送过来的指令
(3)接受app master发送过来的指令
(4) 启动Container
app master
(1)运行作业的主控者
(2)获取切片数据
(3)从resourcemanager审请运行作业资源
(4)监控作业运行的状态
Container:
它其实就是一个虚拟主机的抽象,分配cpu和内存,主要运行作业
app master
Container
Client
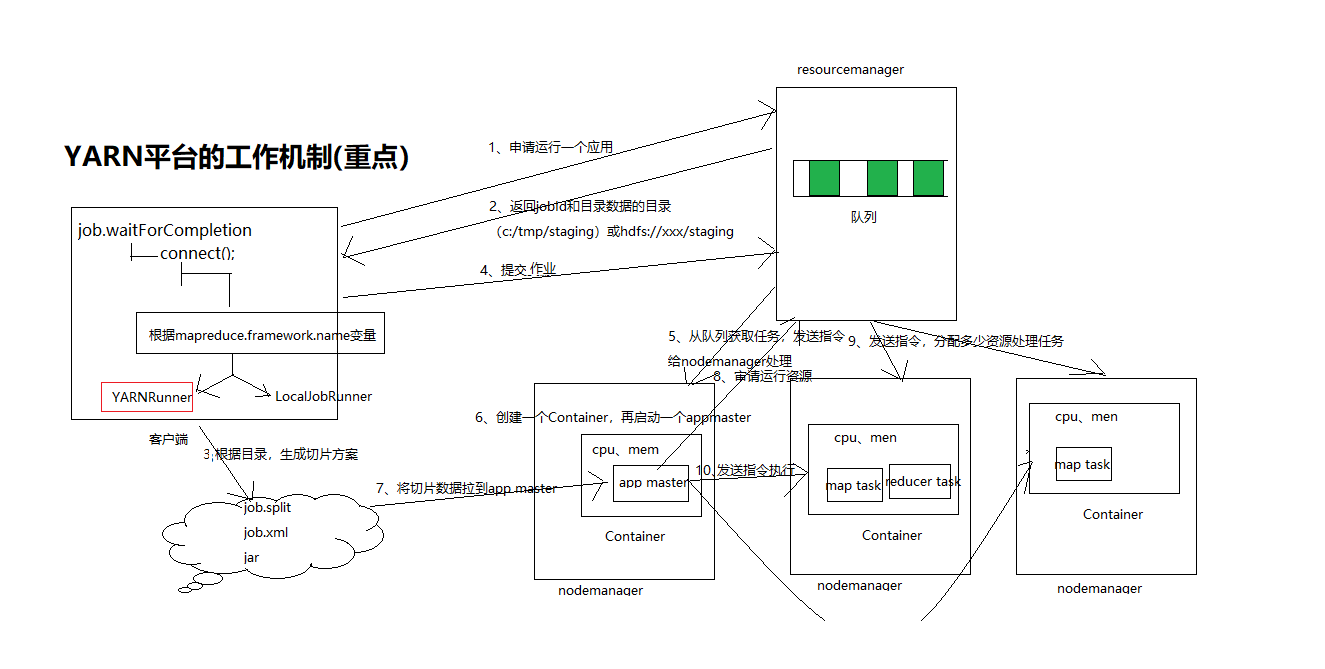
yarn的工作机制(重点)
1、连接运行器平台
根据mapreduce.framework.name变量配置
如果等于yarn:则创建YARNRunner对象
如果等于Local:则创建LocalJobRunner对象
2、如果是yarn平台,对resoucemanager提交作业审请
3、resourcemanager返回一个jobid和数据保存目录(hdfs://xxx/staging/xxx)
4、客户端根据返回数据保存目录路径,将job.split、job.xml、jar文件提交到hdfs://xxx/staging/xxx目录
5、提交数据资源之后,客户端对resouremanager提交任务运行
6、resourcemanager将任务存储任务队列
7、resourcemanager发送命令nodemanager处理从任务取出的任务
8、nodemanager往resourcemanageer审请我要创建一个app master
a、在nodemanager创建一个container,再启动app master
9、app master读取数据切片处理方案
10、app master往resourcemanager审请运行资源
11、resourcemanager往空闲的nodemanager主机发送指令,要创建Container
12、app master往nodemanger发送运行指令,container运行任务。
如下图:
是否可以直接从本地idea直接将程序运行到yarn平台?
以wordcount为例:
代码如下:
package com.gec.demo; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /*
* 作用:体现mapreduce的map阶段的实现
* KEYIN:输入参数key的数据类型
* VALUEIN:输入参数value的数据类型
* KEYOUT,输出key的数据类型
* VALUEOUT:输出value的数据类型
*
* 输入:
* map(key,value)=偏移量,行内容
*
* 输出:
* map(key,value)=单词,1
*
* 数据类型:
* java数据类型:
* int-------------->IntWritable
* long------------->LongWritable
* String----------->Text
* 它都实现序列化处理
*
* */
public class WcMapTask extends Mapper<LongWritable, Text,Text, IntWritable>
{
/*
*根据拆分输入数据的键值对,调用此方法,有多少个键,就触发多少次map方法
* 参数一:输入数据的键值:行的偏移量
* 参数二:输入数据的键对应的value值:偏移量对应行内容
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line=value.toString(); String words[]=line.split(" "); for (String word : words) { context.write(new Text(word),new IntWritable(1));
} }
}
package com.gec.demo; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /*
* 此类:处理reducer阶段
* 汇总单词次数
* KEYIN:输入数据key的数据类型
* VALUEIN:输入数据value的数据类型
* KEYOUT:输出数据key的数据类型
* VALUEOUT:输出数据value的数据类型
*
*
* */
public class WcReduceTask extends Reducer<Text, IntWritable,Text,IntWritable>
{
/*
* 第一个参数:单词数据
* 第二个参数:集合数据类型汇总:单词的次数
*
* */
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count=0; for (IntWritable value : values) { count+=value.get();
} context.write(key,new IntWritable(count)); }
}
package com.gec.demo; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WcCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable sum=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0; for (IntWritable value : values) {
count+=value.get();
}
sum.set(count);
context.write(key,sum);
}
}
package com.gec.demo; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; /**
* Hello world!
*
*/
public class App
{
public static void main( String[] args ) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf=new Configuration();
// conf.set("fs.defaultFS","hdfs://hadoop-001:9000");
// conf.set("mapreduce.framework.name","yarn");
// conf.set("yarn.resourcemanager.hostname","hadoop-002");
conf.set("mapred.jar","D:\\JAVA\\projectsIDEA\\BigdataStudy\\mrwordcountbyyarn\\target\\wordcountbyyarn-1.0-SNAPSHOT.jar");
Job job=Job.getInstance(conf);
//设置Driver类
job.setJarByClass(App.class); //设置运行那个map task
job.setMapperClass(WcMapTask.class);
//设置运行那个reducer task
job.setReducerClass(WcReduceTask.class);
job.setCombinerClass(WcCombiner.class); //设置map task的输出key的数据类型
job.setMapOutputKeyClass(Text.class);
//设置map task的输出value的数据类型
job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //指定要处理的数据所在的位置
FileInputFormat.setInputPaths(job, "/wordcount/input/big.txt");
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output7"));
//向yarn集群提交这个job
boolean res = job.waitForCompletion(true);
System.exit(res?0:1); }
}
其中
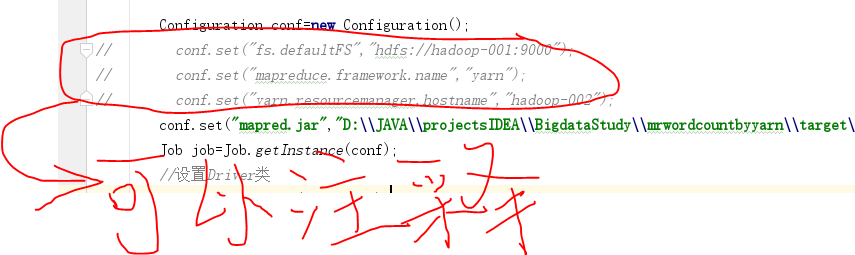
是因为在resource文件夹中直接添加配置文件
配置文件分别如下:
注意:这里的配置文件要和虚拟机中的配置文件一样,否则可能会出错,最好的做法是从虚拟机中直接copy出来
Hadoop yarn工作流程详解的更多相关文章
- git概念及工作流程详解
git概念及工作流程详解 既然我们已经把gitlab安装完毕[当然这是非必要条件],我们就可以使用git来管理自己的项目了,前文也多多少少提及到git的基本命令,本文就先简单对比下SVN与git的区别 ...
- Hadoop MapReduce八大步骤以及Yarn工作原理详解
Hadoop是市面上使用最多的大数据分布式文件存储系统和分布式处理系统, 其中分为两大块分别是hdfs和MapReduce, hdfs是分布式文件存储系统, 借鉴了Google的GFS论文. MapR ...
- K8s工作流程详解
在学习k8s工作流程之前,我们得再次认识一下上篇k8s架构与组件详解中提到的kube-controller-manager一个k8s中许多控制器的进程的集合. 比如Deployment 控制器(Dep ...
- SSL协议(HTTPS) 握手、工作流程详解(双向HTTPS流程)
原文地址:http://www.cnblogs.com/jifeng/archive/2010/11/30/1891779.html SSL协议的工作流程: 服务器认证阶段:1)客户端向服务器发送一个 ...
- Ansible工作流程详解
1:Ansible的使用者 ------>Ansible的使用者来源于多种维度,(1):CMDB(Configuration Management Database,配置管理数据库),CMDB存 ...
- SSL协议握手工作流程详解(双向HTTPS流程)
参考学习文档:http://www.cnblogs.com/jifeng/archive/2010/11/30/1891779.html SSL协议的工作流程: 服务器认证阶段: 1)客户端向服务器发 ...
- 看完你也能独立负责项目!产品经理做APP从头到尾的所有工作流程详解!
(一)项目启动前 从事产品的工作一年多,但自己一直苦于这样或者那样的困惑,很多人想要从事产品,或者老板自己创业要亲自承担产品一职,但他们对产品这个岗位的认识却不明晰,有的以为是纯粹的画原型,有的是以为 ...
- Spring MVC 工作流程详解
1.首先先来一张图 开始流程----------------> 1.用户发送请求到前端控制器,前端控制器会过滤用户的请求,例如我们在web.xml里面配置的内容: <!-- 配置Sprin ...
- hadoop应用开发技术详解
<大 数据技术丛书:Hadoop应用开发技术详解>共12章.第1-2章详细地介绍了Hadoop的生态系统.关键技术以及安装和配置:第3章是 MapReduce的使用入门,让读者了解整个开发 ...
随机推荐
- js编写轮播图,广告弹框
1.轮播图 js编写轮播图,需要用到setInterval(计时器):先给一个div,里面放轮播图的图片,将轮播图的图片明明为相同样式的:如:banner1.jpg,banner2.jpg,banne ...
- SQL注入之Sqli-labs系列第二十九关(基于WAF防护的单引号报错注入)
开始挑战第二十九关(Protection with WAF) 0x1查看源码 (1)login.php页面存在防护,只要检测到存在问题就跳转到hacked.php页面(其他信息看备注) 0x2 for ...
- 纯C:AES256
尼玛的WordPress把格式全搞乱了 aes256.h #ifndef _AES256_H_ #define _AES256_H_ #include <stdio.h> #include ...
- Gym -102007 :Benelux Algorithm Programming Contest (BAPC 18) (寒假自训第5场)
A .A Prize No One Can Win 题意:给定N,S,你要从N个数中选最多是数,使得任意两个之和不大于S. 思路:排序,然后贪心的选即可. #include<bits/stdc+ ...
- python函数完整语法和分类
函数初级 简介 # 函数是一系列代码的集合,用来完成某项特定的功能 优点 '''1. 避免代码的冗余2. 让程序代码结构更加清晰3. 让代码具有复用性,便于维护''' 函数四部分 '''1. 函数名: ...
- php基础-5
php的面相对象 <?php class Hello { public function say_hello() { echo "hello"; } } $say = ne ...
- 命令提示符操作及Java的特点
day1_3 命令提示符的操作 GUI 图形化方式(可视化) CLI 命令行方式 (编程方式) dir 列出当前目录下文件及文件夹 md 创建文件夹 rd 删除文件夹(只能删除空文件夹) cd 进入指 ...
- 算法(第4版) (Robert Sedgewick / Kevin Wayne 著)
第1章 基础 第2章 排序 第3章 查找 第4章 图 第5章 字符串 第1章 基础 public class Bag<T> : IEnumerable<T> { ]; ; pu ...
- Bow & Arrow 学习
using UnityEngine; using System.Collections; using System.Collections.Generic; using UnityEngine.UI; ...
- Tanks!Tutorial 学习
using UnityEngine; namespace Complete { public class CameraControl : MonoBehaviour { /// <summary ...